이 튜토리얼에서는 다변량 시계열 모델(ARIMA_PLUS_XREG)을 만들어 epa_historical_air_quality 데이터 세트에서 다음 샘플 테이블을 사용하여 시계열 예측을 수행하는 방법을 알아봅니다.
epa_historical_air_quality.pm25_nonfrm_daily_summary샘플 테이블epa_historical_air_quality.wind_daily_summary샘플 테이블epa_historical_air_quality.temperature_daily_summary샘플 테이블
epa_historical_air_quality 데이터 세트에는 여러 미국 도시에서 수집된 일일 PM 2.5, 기온, 풍속 정보가 포함됩니다.
목표
이 튜토리얼에서는 다음을 사용합니다.
CREATE MODEL문: 시계열 모델을 만듭니다.ML.ARIMA_EVALUATE함수: 모델의 ARIMA 관련 평가 정보를 검사합니다.ML.ARIMA_COEFFICIENTS함수: 모델 계수를 검사합니다.ML.FORECAST함수: 일일 PM 2.5를 예측합니다.ML.EVALUATE함수: 실제 데이터가 있는 모델을 평가합니다.ML.EXPLAIN_FORECAST함수: 예측 결과를 설명하는 데 사용할 수 있는 시계열의 다양한 구성요소 (예: 계절성, 트렌드, 특성 기여 분석)를 검색합니다.
비용
이 튜토리얼에서는 다음을 포함하여 Google Cloud의 청구 가능한 구성요소가 사용됩니다.
- BigQuery
- BigQuery ML
BigQuery 비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지를 참조하세요.
BigQuery ML 비용에 대한 자세한 내용은 BigQuery ML 가격 책정을 참조하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- BigQuery는 새 프로젝트에서 자동으로 사용 설정됩니다.
기존 프로젝트에서 BigQuery를 활성화하려면 다음으로 이동합니다.
Enable the BigQuery API.
1단계: 데이터 세트 만들기
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.
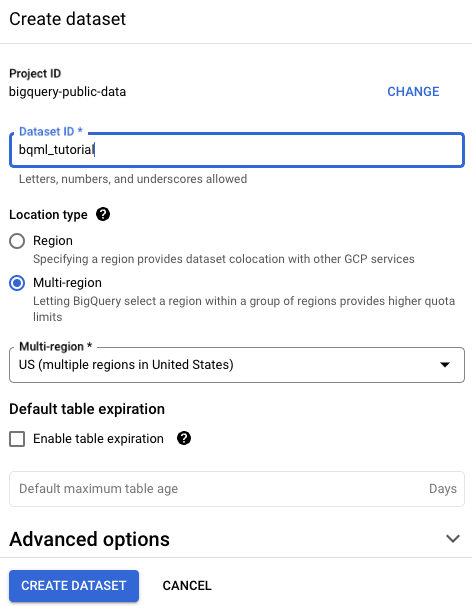
데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.
2단계: 추가 특성으로 시계열 테이블 만들기
PM2.5, 온도, 풍속 데이터는 별도의 테이블에 있습니다.
다음 쿼리를 단순화하기 위해 다음 열을 가진 테이블을 조인하여 새 테이블 bqml_tutorial.seattle_air_quality_daily를 만들 수 있습니다.
- date: 관측 날짜
- PM2.5: 일일 평균 PM2.5 값
- wind_speed: 각 날짜의 평균 풍속
- temperature: 일일 최고 기온
새 테이블에는 2009년 8월 11일부터 2022년 1월 31일까지의 일일 데이터가 포함됩니다.
다음 GoogleSQL 쿼리에서 FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary 절은 epa_historical_air_quality 데이터 세트에서 *_daily_summary 테이블을 쿼리한다는 것을 나타냅니다. 이러한 테이블은 파티션을 나눈 테이블입니다.
#standardSQL CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date)
쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다.
3단계(선택사항): 예측하려는 시계열 시각화
모델을 만들기 전에 입력 시계열의 모양을 확인하는 것이 좋습니다. Looker Studio를 사용하여 이를 수행할 수 있습니다.
다음 GoogleSQL 쿼리에서 FROM bqml_tutorial.seattle_air_quality_daily 절은 방금 만든 bqml_tutorial 데이터 세트에서 seattle_air_quality_daily 테이블을 쿼리 중임을 나타냅니다.
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`
실행을 클릭합니다.
쿼리가 실행된 다음 출력은 다음 스크린샷과 비슷합니다. 스크린샷에서는 이 시계열에 데이터 포인트가 3,960개 있는 것을 확인할 수 있습니다. 데이터 탐색 버튼을 클릭한 후 Looker Studio로 탐색을 클릭합니다. Looker Studio가 새 탭에서 열립니다. 새 탭에서 다음 단계를 완료합니다.
차트 패널에서 시계열 차트를 선택합니다.
차트 패널 아래의 설정 패널에서 측정항목 섹션으로 이동합니다. pm25, temperature, and wind_speed 필드를 추가한 후 기본 측정항목인 레코드 수를 삭제합니다. 커스텀 기간(예: 2019년 1월 1일부터 2021년 12월 31일까지)을 설정해 시계열을 줄일 수도 있습니다. 다음 그림을 참조하세요.
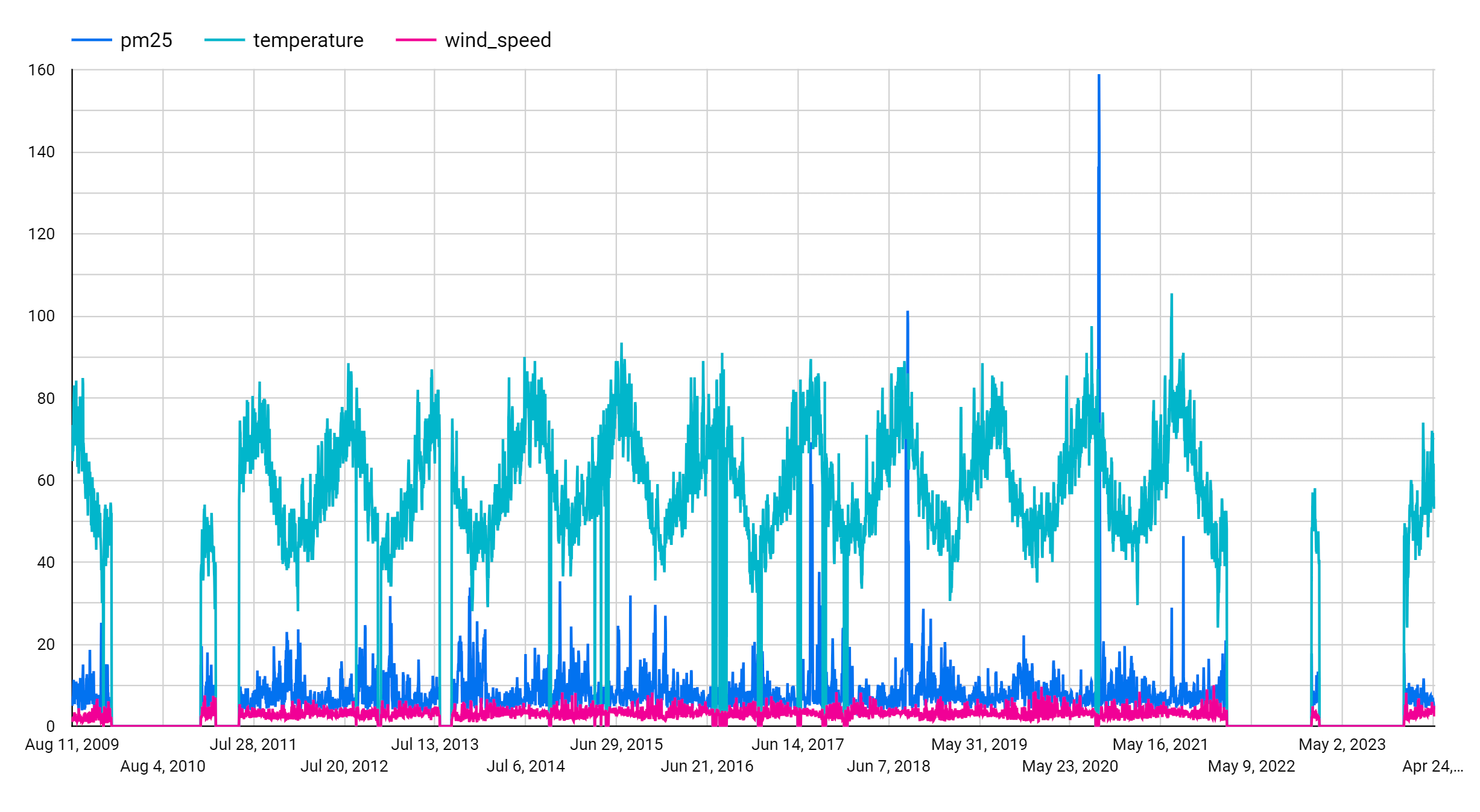
이 단계를 완료하면 다음 그래프가 표시됩니다. 이 그래프는 입력 시계열에 주별 계절성 패턴이 포함된 것을 보여줍니다.
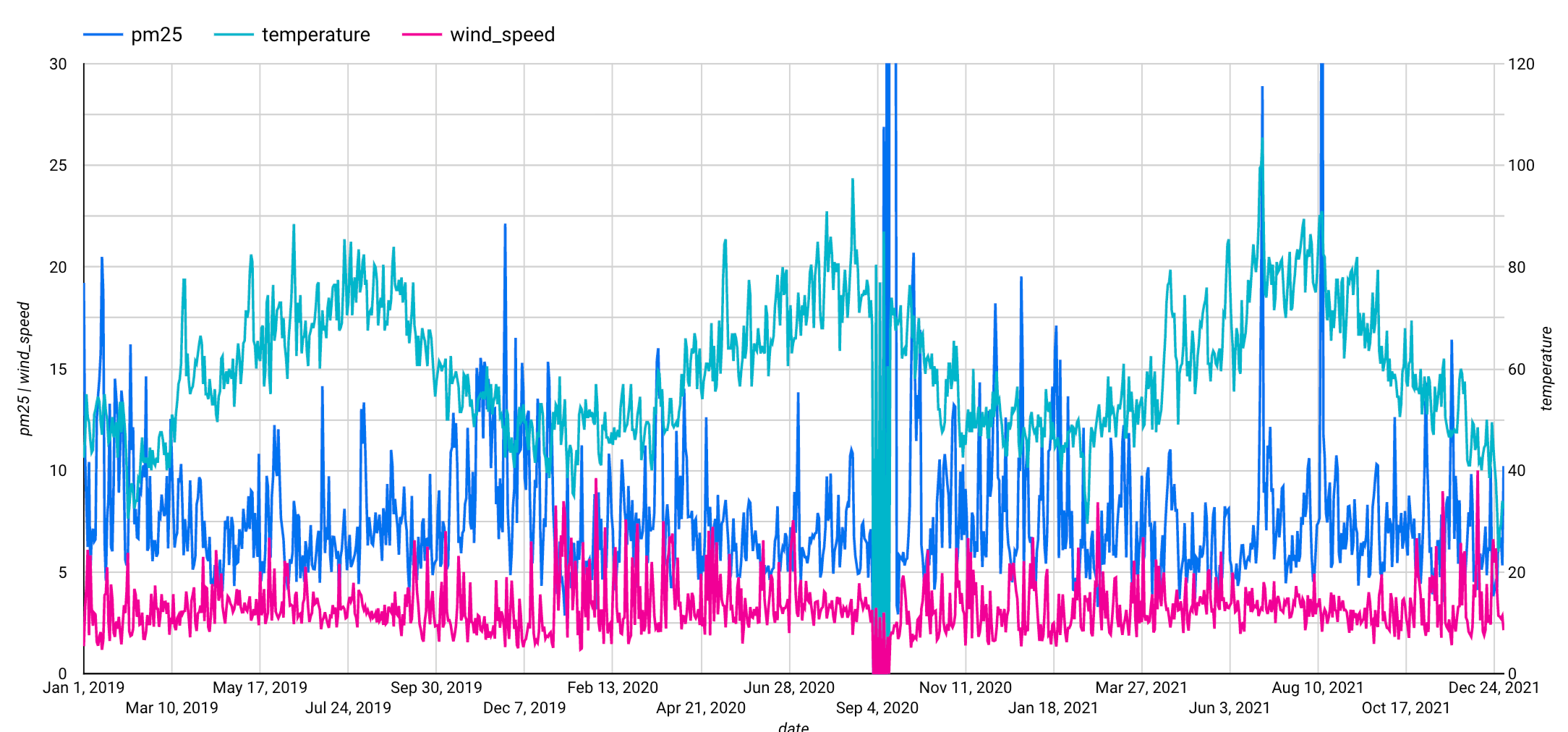
4단계: 시계열 모델 만들기
이제 위의 공기질 데이터를 사용해서 시계열 모델을 만듭니다.
다음 GoogleSQL 쿼리는 pm25를 예측하는 데 사용되는 모델을 만듭니다.
CREATE MODEL 절은 bqml_tutorial.seattle_pm25_xreg_model이라는 모델을 만들고 학습시킵니다.
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', time_series_data_col = 'pm25') AS SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
OPTIONS(model_type='ARIMA_PLUS_XREG', time_series_timestamp_col='date', ...) 절은 외부 회귀 모델을 사용하여 ARIMA를 만들고 있음을 나타냅니다. 기본적으로 auto_arima=TRUE이므로 auto.ARIMA 알고리즘이 ARIMA_PLUS_XREG 모델에서 초매개변수를 자동으로 조정합니다. 이 알고리즘은 후보 모델 십여 개를 접합하고 Akaike 정보 기준(AIC)가 가장 낮은 최적 후보를 선택합니다.
또한 기본값이 data_frequency='AUTO_FREQUENCY'이므로 학습 프로세스가 입력 시계열의 데이터 빈도를 자동으로 추론합니다.
CREATE MODEL 쿼리를 실행하여 모델을 만들고 학습시킵니다.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 위의 GoogleSQL 쿼리를 입력합니다.
실행을 클릭합니다.
이 쿼리는 완료하는 데 약 20초가 소요되며 이후에는 모델(
seattle_pm25_xreg_model)이 탐색 패널에 표시됩니다. 이 쿼리에서는CREATE MODEL문을 사용하여 모델을 만들므로 쿼리 결과가 표시되지 않습니다.
5단계: 모든 평가된 모델의 평가 측정항목 검사
모델을 만든 후에는 ML.ARIMA_EVALUATE 함수를 사용하여 자동 초매개변수 조정 과정 중에 평가된 모든 후보 모델의 평가 측정항목을 확인할 수 있습니다.
다음 GoogleSQL 쿼리에서 FROM 절은 bqml_tutorial.seattle_pm25_xreg_model 모델에 대해 ML.ARIMA_EVALUATE 함수를 사용합니다. 기본적으로 이 쿼리는 모든 후보 모델의 평가 측정항목을 반환합니다.
ML.ARIMA_EVALUATE 쿼리를 실행하려면 다음 단계를 수행합니다.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
실행을 클릭합니다.
쿼리가 완료되면 쿼리 텍스트 영역 아래의 결과 탭을 클릭합니다. 결과는 다음 스크린샷과 비슷하게 표시됩니다.

결과에 다음 열이 포함됩니다.
non_seasonal_pnon_seasonal_dnon_seasonal_qhas_driftlog_likelihoodAICvarianceseasonal_periodshas_holiday_effecthas_spikes_and_dipshas_step_changeserror_message
다음 열 4개(
non_seasonal_{p,d,q}및has_drift)는 학습 파이프라인에서 ARIMA 모델을 정의합니다. 그 다음 측정항목 3개(log_likelihood,AIC,variance)는 ARIMA 모델 접합 프로세스와 관련된 측정항목입니다.auto.ARIMA알고리즘은 먼저 KPSS 테스트를 사용하여non_seasonal_d의 최적 값이 1인지 확인합니다.non_seasonal_d가 1이면 auto.ARIMA가 서로 다른 후보 ARIMA 모델 42개를 병렬로 학습시킵니다.non_seasonal_d가 1이 아니면 auto.ARIMA가 서로 다른 후보 모델 21개를 학습시킵니다. 이 예시에서는 42개 후보 모델이 모두 유효합니다. 따라서 출력에 42개 행이 포함되고, 각 행은 후보 ARIMA 모델과 연결되어 있습니다. 일부 시계열의 경우에는 반대로 적용할 수 없거나 비고정적이기 때문에 일부 후보 모델이 유효하지 않습니다. 이렇게 유효하지 않은 모델이 출력에서 제외되어, 출력에 42개 미만의 행이 포함됩니다. 이러한 후보 모델은 AIC에 따라 오름차순으로 정렬됩니다. 첫 번째 행의 모델은 AIC가 가장 낮으며 최적 모델로 간주됩니다. 이 최적 모델은 최종 모델로 저장되며 다음 단계와 같이ML.FORECAST,ML.EVALUATE,ML.ARIMA_COEFFICIENTS를 호출할 때 사용됩니다.seasonal_periods열은 입력 시계열 내 계절 패턴 정보입니다. 이 열은 ARIMA 모델링과 관계가 없으므로 모든 출력 행에서 동일한 값을 갖습니다. 위 2단계에 설명한 것처럼 예상 범위 내에 있는 주별 패턴을 보고합니다.has_holiday_effect,has_spikes_and_dips,has_step_changes열은decompose_time_series=TRUE인 경우에만 채워집니다. 이는 ARIMA 모델링과 관련 없는 입력 시계열 내 휴일 효과, 급증, 하락, 단계 변화와 관련됩니다. 따라서 실패한 모델을 제외하고 모든 출력 행에서 동일한 값을 갖습니다.error_message열에서는auto.ARIMA접합 프로세스 중에 발생할 수 있는 오류를 보여줍니다. 선택한non_seasonal_p,non_seasonal_d,non_seasonal_q,has_drift열에서 시계열을 안정화하지 못하는 것이 원인일 수도 있습니다. 모든 후보 모델의 가능한 오류 메시지를 검색하려면show_all_candidate_models=true를 설정합니다.
6단계: 모델 계수 검사
ML.ARIMA_COEFFICIENTS 함수는 ARIMA_PLUS 모델 bqml_tutorial.seattle_pm25_xreg_model의 모델 계수를 검색합니다. ML.ARIMA_COEFFICIENTS는 모델만 입력으로 사용합니다.
ML.ARIMA_COEFFICIENTS 쿼리 실행:
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`)
실행을 클릭합니다.
다음과 같은 결과가 표시됩니다.
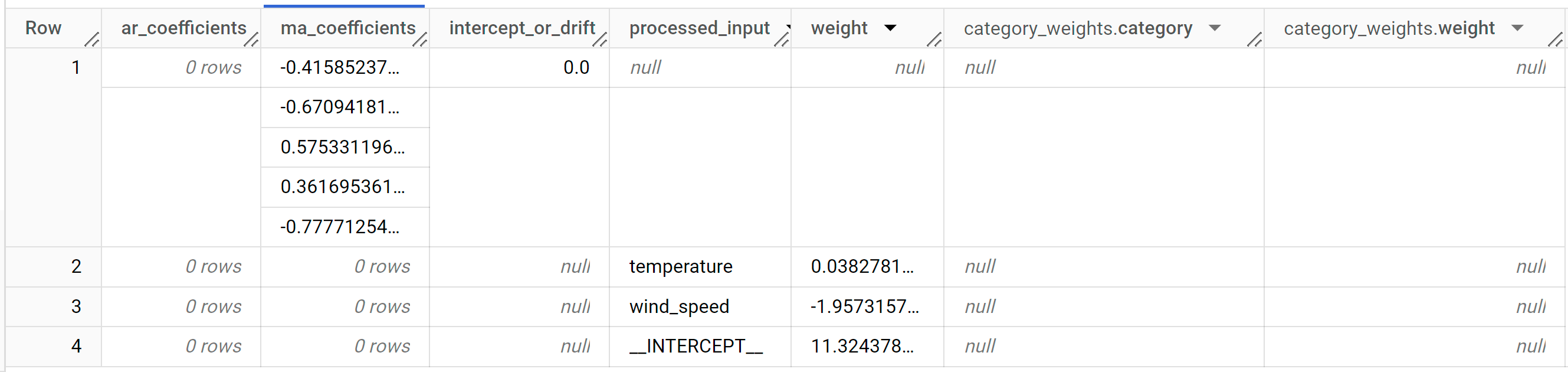
결과에 다음 열이 포함됩니다.
ar_coefficientsma_coefficientsintercept_or_driftprocessed_inputweightcategory_weights.categorycategory_weights.weight
ar_coefficients는 ARIMA 모델의 자동 회귀(AR) 부분의 모델 계수를 보여줍니다. 이와 비슷하게ma_coefficients는 이동 평균(MA) 부분의 모델 계수를 보여줍니다. 두 가지 모두 길이가 각각non_seasonal_p및non_seasonal_q에 해당하는 배열입니다.ML.ARIMA_EVALUATE의 출력에서 최상위 행에 표시되는 최적 모델은non_seasonal_p0 및non_seasonal_q5를 포함합니다. 따라서ar_coefficients는 빈 배열이고ma_coefficients는 길이가 5인 배열입니다.intercept_or_drift는 ARIMA 모델의 상수 항입니다.processed_input및 해당weight와category_weights열은 선형 회귀 모델에서 각 특성 및 절편에 대한 가중치를 보여줍니다. 숫자 특성인 경우 가중치는weight열에 있습니다. 범주형 특성인 경우에는category_weights가STRUCT의ARRAY이며STRUCT에는 범주의 이름과 가중치가 포함됩니다.
7단계: 모델을 사용하여 시계열 예측
ML.FORECAST 함수는 모델 bqml_tutorial.seattle_pm25_xreg_model 및 미래의 특성 값을 사용하여 예측 구간과 함께 미래 시계열 값을 예측합니다.
다음 GoogleSQL 쿼리에서 STRUCT(30 AS horizon, 0.8 AS confidence_level) 절은 쿼리가 30개의 미래 시점을 예측하고 80% 신뢰 수준의 예측 구간을 생성함을 나타냅니다. ML.FORECAST는 모델, 미래의 특성 값, 몇 가지 선택적 인수를 사용합니다.
ML.FORECAST 쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))
실행을 클릭합니다.
다음과 같은 결과가 표시됩니다.
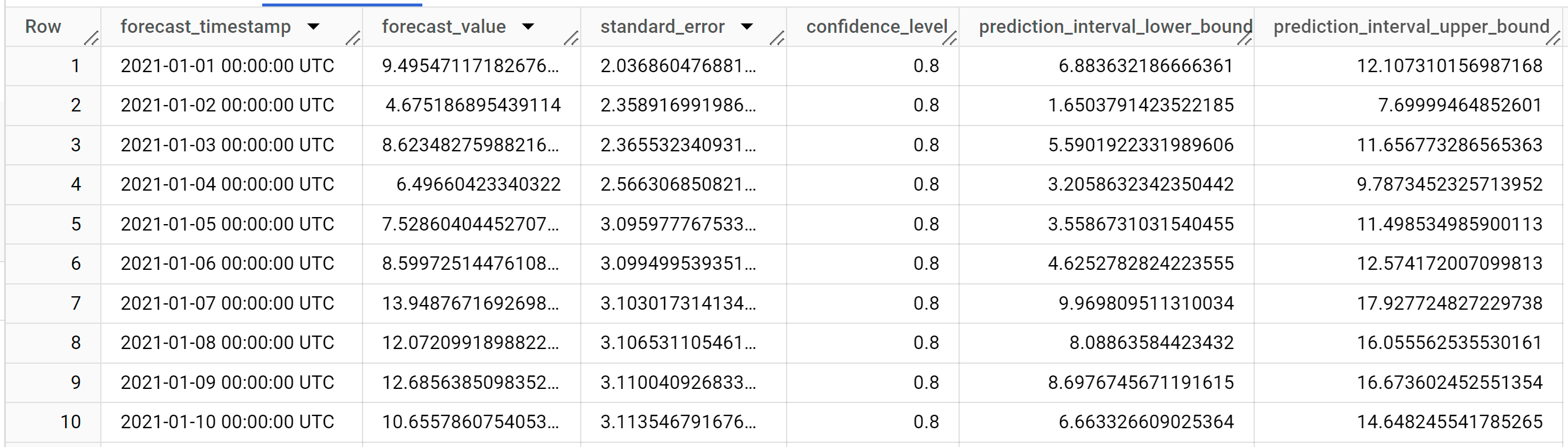
결과에 다음 열이 포함됩니다.
forecast_timestampforecast_valuestandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_upper_bound
출력 행은
forecast_timestamp의 시간 순서로 정렬됩니다. 시계열 예측에서 하한 및 상한으로 캡처되는 예측 구간은forecast_value만큼 중요합니다.forecast_value는 예측 구간의 중간 포인트입니다. 예측 구간은standard_error및confidence_level에 따라 달라집니다.
8단계: 실제 데이터로 예측 정확성 평가
실제 데이터로 예측 정확성을 평가하려면 모델, bqml_tutorial.seattle_pm25_xreg_model 및 실제 데이터 테이블에서 ML.EVALUATE 함수를 사용하면 됩니다.
ML.EVALUATE 쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
두 번째 매개변수는 미래의 특성이 포함된 실제 데이터이며 실제 데이터를 비교할 미래 값을 예측하는 데 사용됩니다. 세 번째 매개변수는 이 함수에 대한 매개변수 구조체입니다.
실행을 클릭합니다.
다음과 같은 결과가 표시됩니다.

9단계: 예측 결과 설명
시계열이 예측되는 방식을 이해하기 위해 ML.EXPLAIN_FORECAST 함수는 모델 bqml_tutorial.seattle_pm25_xreg_model사용하여 예측 구간과 함께 미래 시계열 값을 예측하며 동시에 시계열의 모든 개별 구성요소를 반환합니다.
ML.FORECAST 함수와 마찬가지로 STRUCT(30 AS horizon, 0.8 AS confidence_level) 절은 쿼리가 미래 시점 30개를 예측하고 80% 신뢰도로 예측 구간을 생성함을 나타냅니다. ML.EXPLAIN_FORECAST 함수는 모델, 미래 특성 값, 몇 가지 선택적 인수를 입력으로 사용합니다.
ML.EXPLAIN_FORECAST 쿼리를 실행하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 새 쿼리 작성 버튼을 클릭합니다.
쿼리 편집기 텍스트 영역에 다음 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ))
실행을 클릭합니다.
이 쿼리는 완료되는 데 1초도 걸리지 않습니다. 다음과 같은 결과가 표시됩니다.
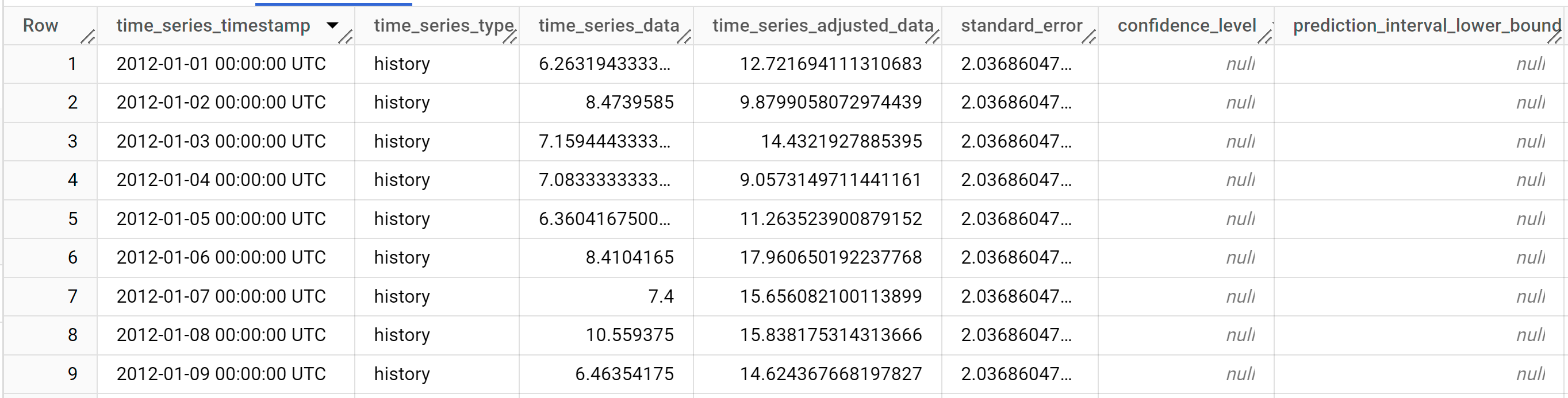
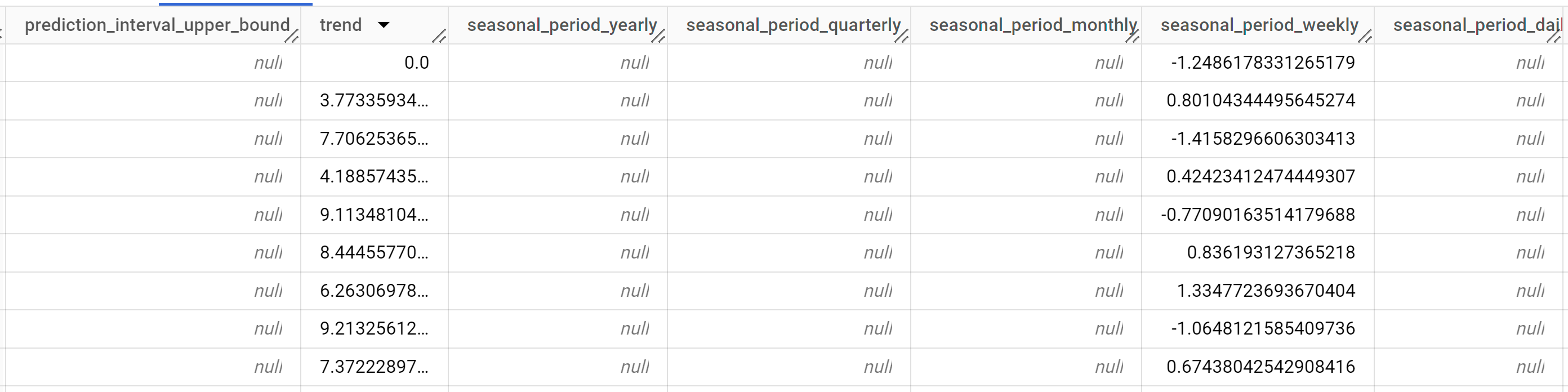
결과에 다음 열이 포함됩니다.
time_series_timestamptime_series_typetime_series_datatime_series_adjusted_datastandard_errorconfidence_levelprediction_interval_lower_boundprediction_interval_lower_boundtrendseasonal_period_yearlyseasonal_period_quarterlyseasonal_period_monthlyseasonal_period_weeklyseasonal_period_dailyholiday_effectspikes_and_dipsstep_changesresidualattribution_temperatureattribution_wind_speedattribution___INTERCEPT__
출력 행은
time_series_timestamp의 시간 순서로 정렬됩니다. 서로 다른 구성요소는 출력 열로 나열됩니다. 자세한 내용은ML.EXPLAIN_FORECAST을 참조하세요.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- 만든 프로젝트를 삭제할 수 있습니다.
- 또는 프로젝트를 유지하고 데이터 세트를 삭제할 수 있습니다.
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
창의 오른쪽에 있는 데이터 세트 삭제를 클릭합니다. 데이터 세트, 테이블, 모든 데이터가 삭제됩니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하여 삭제 명령어를 확인한 후 삭제를 클릭합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- NYC 도심 자전거 운행 데이터의 단일 쿼리를 사용하여 여러 시계열을 예측하는 방법을 알아보세요.
- ARIMA_PLUS를 가속화하여 몇 시간 내에 시계열 100만 개 예측을 사용 설정하는 방법을 알아보세요.
- 머신러닝 단기집중과정을 참조하여 머신러닝을 알아보세요.
- BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- Google Cloud 콘솔에 대한 자세한 내용은 Google Cloud 콘솔 사용을 참조하세요.