管理分区和聚类建议
本文档介绍了分区和聚类 Recommender 的工作原理、如何查看建议和数据分析,以及如何应用分区和聚类建议
Recommender 的工作原理
BigQuery 分区和聚类 Recommender 会生成分区或聚类建议以优化 BigQuery 表。Recommender 会基于 BigQuery 表分析工作流,并提供建议,以便您使用表分区或表聚类更好地优化工作流和查询费用。
如需详细了解 Recommender 服务,请参阅 Recommender 概览。
分区和聚类 Recommender 会使用项目过去 30 天内的工作负载执行数据来分析每个 BigQuery 表,以获取欠佳分区和聚类配置。Recommender 还会使用机器学习来预测可以使用不同分区或聚类配置优化工作负载执行的程度。如果 Recommender 发现对表进行分区或聚类可显著节省费用,则 Recommender 会生成建议。分区和聚类 Recommender 会生成以下类型的建议:
| 现有表类型 | 建议子类型 | 建议示例 |
|---|---|---|
| 非分区、非聚类 | 分区 | “通过按 DAY 对 column_C 进行分区,每月可节省约 64 个小时的槽时间” |
| 非分区、非聚类 | 集群 | “通过对 column_C 进行聚类,每月可节省约 64 个小时的槽时间” |
| 分区、非聚类 | 集群 | “通过对 column_C 进行聚类,每月可节省约 64 个小时的槽时间” |
每条建议由三部分组成:
- 对特定表进行分区或聚类的指导
- 要对其进行分区或聚类的表中的特定列
- 预计每月节省的应用建议的费用
为了计算工作负载可能节省的费用,Recommender 假定过去 30 天内的历史执行工作负载数据代表未来的工作负载。
Recommender API 还会以数据分析的形式返回表工作负载信息。数据分析是帮助您了解项目的工作负载的发现结果,提供了有关分区或聚类建议如何优化工作负载费用的更多背景信息。
限制
分区和聚类 Recommender 不支持使用旧版 SQL 的 BigQuery 表。生成建议时,Recommender 会在其分析中排除所有旧版 SQL 查询。此外,对使用旧版 SQL 的 BigQuery 表应用分区建议会中断该表中的所有旧版 SQL 工作流。
在应用分区建议之前,请将旧版 SQL 工作流迁移到 GoogleSQL。
BigQuery 不支持原地更改表的分区方案。您只能更改表的副本的分区。如需了解详情,请参阅应用分区建议。
位置
分区和聚类 Recommender 可在以下处理位置使用:
| 区域说明 | 区域名称 | 详情 | |
|---|---|---|---|
| 亚太地区 | |||
| 德里 | asia-south2 |
||
| 香港 | asia-east2 |
||
| 雅加达 | asia-southeast2 |
||
| 孟买 | asia-south1 |
||
| 大阪 | asia-northeast2 |
||
| 首尔 | asia-northeast3 |
||
| 新加坡 | asia-southeast1 |
||
| 悉尼 | australia-southeast1 |
||
| 台湾 | asia-east1 |
||
| 东京 | asia-northeast1 |
||
| 欧洲 | |||
| 比利时 | europe-west1 |
|
|
| 柏林 | europe-west10 |
|
|
| 欧盟多区域 | eu |
||
| 法兰克福 | europe-west3 |
||
| 伦敦 | europe-west2 |
|
|
| 荷兰 | europe-west4 |
|
|
| 苏黎世 | europe-west6 |
|
|
| 美洲 | |||
| 艾奥瓦 | us-central1 |
|
|
| 拉斯维加斯 | us-west4 |
||
| 洛杉矶 | us-west2 |
||
| 蒙特利尔 | northamerica-northeast1 |
|
|
| 北弗吉尼亚 | us-east4 |
||
| 俄勒冈 | us-west1 |
|
|
| 盐湖城 | us-west3 |
||
| 圣保罗 | southamerica-east1 |
|
|
| 多伦多 | northamerica-northeast2 |
|
|
| 美国多区域 | us |
||
准备工作
所需权限
如需获得访问分区和聚类建议所需的权限,请让您的管理员为您授予 BigQuery Partitioning Clustering Recommender Viewer (roles/recommender.bigqueryPartitionClusterViewer) IAM 角色。如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
此预定义角色可提供访问分区和聚类建议所需的权限。如需查看所需的确切权限,请展开所需权限部分:
所需权限
如需访问分区和聚类建议,您需要拥有以下权限:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
如需详细了解 BigQuery 中的 IAM 角色和权限,请参阅 IAM 简介。
查看建议
本部分介绍如何使用 Google Cloud 控制台、Google Cloud CLI 或 Recommender API 查看分区和集群建议和分析洞见。
从下列选项中选择一项:
控制台
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击建议。
“建议”标签页列出了您的项目可用的所有建议。
在降低 BigQuery 工作负载费用面板中,点击查看全部。
费用建议表列出了为当前项目生成的所有建议。例如,以下屏幕截图显示 Recommender 分析了
example_table表,然后建议对example_column列进行聚类以节省大致的字节数和槽数。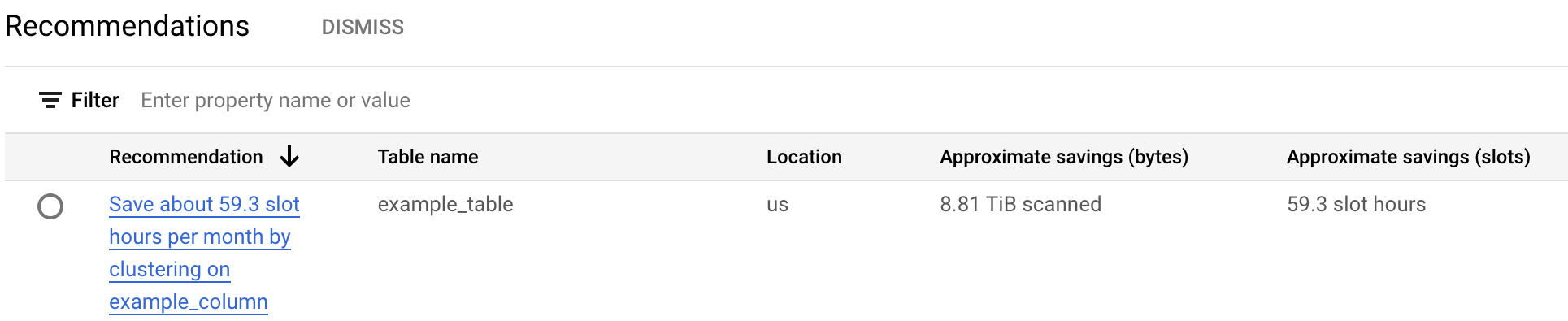
如需详细了解表数据分析和建议,请点击具体的建议。
gcloud
如需查看特定项目的分区或聚类建议,请使用 gcloud recommender recommendations list 命令:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
请替换以下内容:
PROJECT_NAME:包含 BigQuery 表的项目的名称REGION_NAME:项目所在的区域FORMAT_TYPE:支持的 gcloud CLI 输出格式,例如 JSON
| 属性 | 针对子类型的相关性 | 说明 |
|---|---|---|
recommenderSubtype |
分区或聚类 | 表示建议类型。 |
content.overview.partitionColumn |
分区 | 建议的分区列名称。 |
content.overview.partitionTimeUnit |
分区 | 建议的分区时间单位。例如,DAY 表示建议在建议的列上具有每日分区。 |
content.overview.clusterColumns |
集群 | 建议的聚类列名称。 |
- 如需详细了解 Recommender 响应中的其他字段,请参阅 REST 资源:
projects.locations.recommendersrecommendation。 - 如需详细了解如何使用 Recommender API,请参阅使用 API - 建议。
如需使用 gcloud CLI 查看表数据分析,请使用 gcloud recommender insights list 命令:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
请替换以下内容:
PROJECT_NAME:包含 BigQuery 表的项目的名称REGION_NAME:项目所在的区域FORMAT_TYPE:支持的 gcloud CLI 输出格式,例如 JSON
| 属性 | 针对子类型的相关性 | 说明 |
|---|---|---|
content.existingPartitionColumn |
集群 | 现有分区列(如果有) |
content.tableSizeTb |
全部 | 表的大小(以 TB 为单位) |
content.bytesReadMonthly |
全部 | 每月从表中读取的字节数 |
content.slotMsConsumedMonthly |
全部 | 表上运行的工作负载每月使用的槽毫秒数 |
content.queryJobsCountMonthly |
全部 | 表上运行的作业的每月计数 |
- 如需详细了解数据分析响应中的其他字段,请参阅 REST 资源:
projects.locations.insightTypes.insights。 - 如需详细了解如何使用数据分析,请参阅使用 API - 数据分析。
REST API
如需查看特定项目的分区或聚类建议,请使用 REST API。您必须在每个命令中提供一个身份验证令牌,该令牌可使用 gcloud CLI 获取。如需详细了解如何获取身份验证令牌,请参阅获取 ID 令牌的方法。
您可以使用 curl list 请求查看针对特定项目的所有建议:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
请替换以下内容:
GCLOUD_AUTH_TOKEN:有效 gcloud CLI 访问令牌的名称PROJECT_NAME:包含 BigQuery 表的项目的名称
| 属性 | 针对子类型的相关性 | 说明 |
|---|---|---|
recommenderSubtype |
分区或聚类 | 表示建议类型。 |
content.overview.partitionColumn |
分区 | 建议的分区列名称。 |
content.overview.partitionTimeUnit |
分区 | 建议的分区时间单位。例如,DAY 表示建议在建议的列上具有每日分区。 |
content.overview.clusterColumns |
集群 | 建议的聚类列名称。 |
- 如需详细了解 Recommender 响应中的其他字段,请参阅 REST 资源:
projects.locations.recommendersrecommendation。 - 如需详细了解如何使用 Recommender API,请参阅使用 API - 建议。
如需使用 REST API 查看表数据分析,请运行以下命令:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
替换以下内容:
GCLOUD_AUTH_TOKEN:有效 gcloud CLI 访问令牌的名称PROJECT_NAME:包含 BigQuery 表的项目的名称
| 属性 | 针对子类型的相关性 | 说明 |
|---|---|---|
content.existingPartitionColumn |
集群 | 现有分区列(如果有) |
content.tableSizeTb |
全部 | 表的大小(以 TB 为单位) |
content.bytesReadMonthly |
全部 | 每月从表中读取的字节数 |
content.slotMsConsumedMonthly |
全部 | 表上运行的工作负载每月使用的槽毫秒数 |
content.queryJobsCountMonthly |
全部 | 表上运行的作业的每月计数 |
- 如需详细了解数据分析响应中的其他字段,请参阅 REST 资源:
projects.locations.insightTypes.insights。 - 如需详细了解如何使用数据分析,请参阅使用 API - 数据分析。
应用聚类建议
如需应用聚类建议,请执行以下操作之一:
将聚类直接应用于原始表
您可以将聚类建议直接应用于现有 BigQuery 表。此方法比将建议应用于复制的表更快,但不会保留备份表。
请按照以下步骤将新的聚类规范应用于未分区表或分区表。
在 bq 工具中,更新表的聚簇规范以匹配新聚簇:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
请替换以下内容:
CLUSTER_COLUMN:要对其进行聚簇的列,例如mycolumnDATASET:包含表的数据集的名称,例如mydatasetORIGINAL_TABLE:原始表的名称,例如mytable
您还可以调用
tables.update或tables.patchAPI 方法来修改聚类规范。如需根据新的聚类规范对所有行进行聚类,请运行以下
UPDATE语句:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
将聚类应用于复制的表
将聚类建议应用于 BigQuery 表时,您可以先复制原始表,然后再将建议应用于复制的表。此方法可确保在您需要回滚聚类配置的更改时保留原始数据。
您可以使用此方法将聚类建议应用于未分区表和分区表。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,使用
LIKE运算符创建一个包含原始表的元数据(包括聚类规范)的空表:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
请替换以下内容:
DATASET:包含表的数据集的名称,例如mydatasetCOPIED_TABLE:复制的表的名称,例如copy_mytableORIGINAL_TABLE:原始表的名称,例如mytable
在 Google Cloud 控制台中,打开 Cloud Shell Editor。
在 Cloud Shell Editor 中,使用
bq update命令更新复制的表的聚类规范以匹配建议的聚类:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
将
CLUSTER_COLUMN替换为您要对其进行聚类的列,例如mycolumn。您还可以调用
tables.update或tables.patchAPI 方法来修改聚类规范。在查询编辑器中,使用原始表的分区和聚类配置(如果存在任何分区或聚簇)检索表架构。您可以通过查看原始表的
INFORMATION_SCHEMA.TABLES视图来检索架构:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'DATASET.ORIGINAL_TABLE;'
输出是 ORIGINAL_TABLE 的完整数据定义语言 (DDL) 语句,包括
PARTITION BY子句。如需详细了解 DDL 输出中的参数,请参阅CREATE TABLE语句。DDL 输出指示原始表的分区类型:
分区类型 输出示例 未分区 缺少 PARTITION BY子句。按表列分区 PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)按注入时间分区 PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)将数据注入到复制的表中。您使用的过程基于分区类型。
- 如果原始表未分区或按表列分区,请将原始表中的数据注入到复制的表中:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
如果原始表按注入时间分区,请按照以下步骤操作:
使用
INFORMATION_SCHEMA.COLUMNS视图检索列列表,以形成数据注入表达式:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
输出是一个以英文逗号分隔的列名称列表。
将原始表中的数据注入到复制的表中:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
将
COLUMN_NAMES替换为上一步中输出的列列表(以英文逗号分隔),例如col1, col2, col3。
现在,您已有一个与原始表包含相同数据的聚类复制表。在接下来的步骤中,您需要将原始表替换为新聚簇的表。
- 如果原始表未分区或按表列分区,请将原始表中的数据注入到复制的表中:
将原始表重命名为备份表:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
将
BACKUP_TABLE替换为备份表的名称,例如backup_mytable。将复制的表重命名为原始表:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
原始表现在会根据聚类建议进行聚类。
- 访问权限和权限,例如 IAM 权限、行级访问权限或列级访问权限。
- 表工件,例如表克隆、表快照或搜索索引。
- 任何正在进行的表进程(例如复制表时运行的任何具体化视图或任何作业)的状态。
- 能够使用时间旅行访问历史表数据。
- 与原始表关联的任何元数据,例如
table_option_list或column_option_list。 如需了解详情,请参阅数据定义语言语句。
如果出现任何问题,您必须手动将受影响的制品迁移到新表。
查看聚类表后,您可以视需要使用以下命令删除备份表:DROP TABLE DATASET.BACKUP_TABLE
在具体化视图中应用聚类
您可以创建表的具体化视图来存储应用了建议的原始表中的数据。使用具体化视图应用建议可确保聚类数据通过自动刷新保持最新。在查询、维护和存储具体化视图时,您需要考虑一些价格注意事项。如需了解如何创建聚类具体化视图,请参阅聚类具体化视图。应用分区建议
如需应用分区建议,您必须将其应用于原始表的副本。BigQuery 不支持就地更改表的分区方案,例如将未分区表更改为分区表、更改表的分区方案或创建与基表具有不同分区方案的具体化视图。您只能更改表的副本的分区。
将分区建议应用于复制的表
将分区建议应用于 BigQuery 表时,您必须先复制原始表,然后再将建议应用于复制的表。此方法可确保在您需要回滚分区时保留原始数据。
以下过程使用了一个示例建议,按分区时间单位 DAY 对表进行分区。
使用分区建议创建复制的表:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
请替换以下内容:
DATASET:包含表的数据集的名称,例如mydatasetCOPIED_TABLE:复制的表的名称,例如copy_mytablePARTITION_COLUMN:要对其进行分区的列,例如mycolumn
如需详细了解如何创建分区表,请参阅创建分区表。
将原始表重命名为备份表:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO DATASET.BACKUP_TABLE
将
BACKUP_TABLE替换为备份表的名称,例如backup_mytable。将复制的表重命名为原始表:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO DATASET.ORIGINAL_TABLE
原始表现在会根据分区建议进行分区。
- 访问权限和权限,例如 IAM 权限、行级访问权限或列级访问权限。
- 表工件,例如表克隆、表快照或搜索索引。
- 任何正在进行的表进程(例如复制表时运行的任何具体化视图或任何作业)的状态。
- 能够使用时间旅行访问历史表数据。
- 与原始表关联的任何元数据,例如
table_option_list或column_option_list。 如需了解详情,请参阅数据定义语言语句。 - 能够使用旧版 SQL 将查询结果写入分区表中。分区表不完全支持使用旧版 SQL。一种解决方案是在应用分区建议之前将旧版 SQL 工作流迁移到 GoogleSQL。
如果出现任何问题,您必须手动将受影响的制品迁移到新表。
查看分区表后,您可以视需要使用以下命令删除备份表:DROP TABLE DATASET.BACKUP_TABLE
价格
将建议应用于表时,可能会产生以下费用:
- 处理费用。应用建议时,您需要对 BigQuery 项目执行数据定义语言 (DDL) 或数据操纵语言 (DML) 查询。
- 存储费用。 如果您使用复制表方法,则需要为复制的(或备份)表使用额外的存储空间。
您需要根据与项目关联的结算账号支付标准处理和存储费用。如需了解详情,请参阅 BigQuery 价格。
问题排查
问题:特定表未显示任何建议。
对于符合以下条件的表,可能不会显示分区建议:
- 该表小于 100GB。
- 该表已进行过分区或聚类。
对于符合以下条件的表,可能不会显示聚类建议:
- 该表小于 10 GB。
- 该表已进行聚类。
在以下情况下,系统可能会抑制分区和聚类建议:
- 该表因数据操纵语言 (DML) 操作而产生较高的写入费用。
- 该表在过去 30 天内没有被读取。
- 估算的每月节省微不足道(每小时节省少于 1 个槽)。