Introdução ao BigQuery Omni
Com o BigQuery Omni, é possível executar análises do BigQuery nos dados armazenados no Amazon Simple Storage Service (Amazon S3) ou no Armazenamento de Blobs do Azure usando tabelas do BigLake.
Diversas organizações armazenam dados em várias nuvens públicas. Muitas vezes, esses dados acabam ficando isolados, já que é difícil extrair insights de todos eles. Você quer analisar dados com uma ferramenta de várias nuvens que seja barata, rápida e não gere mais sobrecarga da governança de dados descentralizada. Com o BigQuery Omni, esses atritos são reduzidos com uma interface unificada.
Para executar a análise do BigQuery nos seus dados externos, primeiro você precisa se conectar ao Amazon S3 ou ao Armazenamento de Blobs. Para consultar dados externos, crie uma tabela do BigLake com referência aos dados do Amazon S3 ou do Armazenamento de Blobs.
Também é possível mover dados entre nuvens usando a transferência entre nuvens ou consultá-los entre nuvens usando junções entre nuvens. O BigQuery Omni é uma solução de análise entre nuvens com a capacidade de analisar dados onde eles estão e a flexibilidade de replicar dados quando necessário. Para mais informações, consulte Carregar dados com transferência entre nuvens e Junções entre nuvens.
Arquitetura
A arquitetura do BigQuery separa a computação do armazenamento, o que permite escalonar horizontalmente o BigQuery conforme necessário para lidar com cargas de trabalho muito grandes. O BigQuery Omni estende essa arquitetura com a execução do mecanismo de consulta do BigQuery em outras nuvens. Assim, você não precisa mover fisicamente os dados para o armazenamento do BigQuery. O processamento acontece no local em que os dados já estão.
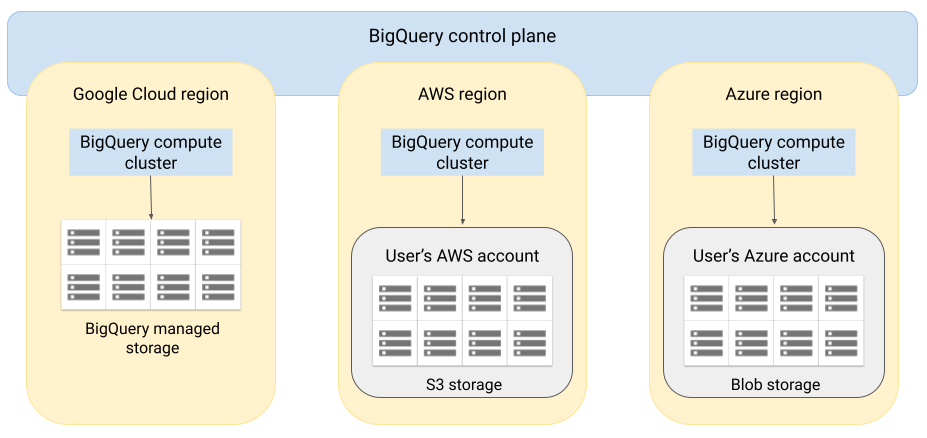
Os resultados da consulta podem ser retornados ao Google Cloud por uma conexão segura. Por exemplo, para serem exibidos no console do Google Cloud. Outra possibilidade é gravar os resultados diretamente em buckets do Amazon S3 ou do Armazenamento de Blobs. Nesse caso, não haverá movimentação entre nuvens dos resultados da consulta.
O BigQuery Omni usa papéis padrão do IAM da AWS ou principais do Azure Active Directory para acessar os dados na sua assinatura. Você delega o acesso de leitura ou gravação ao BigQuery Omni e pode revogar quando quiser.
Fluxo de dados ao consultar dados
A imagem a seguir descreve como os dados são movidos entre o Google Cloud e a AWS ou o Azure para as seguintes consultas:
- Instrução
SELECT - Instrução
CREATE EXTERNAL TABLE

- O plano de controle do BigQuery recebe de você os jobs de consulta por meio do console do Google Cloud, da ferramenta de linha de comando bq, de um método de API ou de uma biblioteca de cliente.
- O plano de controle do BigQuery envia jobs de consulta para processamento no plano de dados do BigQuery na AWS ou no Azure.
- O plano de dados do BigQuery recebe consultas do plano de controle por uma conexão VPN.
- O plano de dados do BigQuery lê os dados da tabela do bucket do Amazon S3 ou do Armazenamento de Blobs.
- O plano de dados do BigQuery executa o job de consulta nos dados da tabela. O processamento dos dados da tabela ocorre na região especificada da AWS ou do Azure.
- O resultado da consulta é transmitido do plano de dados para o plano de controle pela conexão VPN.
- O plano de controle do BigQuery recebe os resultados do job de consulta para a exibição em resposta a ele. Esses dados são armazenados por até 24 horas.
- O resultado é retornado para você.
Para mais informações, consulte Consultar dados do Amazon S3 e Dados do Armazenamento de Blobs.
Fluxo de dados ao exportar dados
A imagem a seguir descreve como os dados são migrados entre o Google Cloud e a AWS
ou Azure durante uma instrução EXPORT DATA.

- O plano de controle do BigQuery recebe de você os jobs de consulta de exportação por meio do console do Google Cloud, da ferramenta de linha de comando bq, de um método de API ou de uma biblioteca de cliente. A consulta contém o caminho do destino para o resultado da consulta no bucket do Amazon S3 ou no Armazenamento de Blobs.
- O plano de controle do BigQuery envia jobs de consulta de exportação para processamento no plano de dados do BigQuery (na AWS ou no Azure).
- O plano de dados do BigQuery recebe a consulta de exportação do plano de controle pela conexão VPN.
- O plano de dados do BigQuery lê os dados da tabela do bucket do Amazon S3 ou do Armazenamento de Blobs.
- O plano de dados do BigQuery executa o job de consulta nos dados da tabela. O processamento de dados de tabela ocorre na região selecionada da AWS ou do Azure.
- O BigQuery grava o resultado da consulta no caminho de destino especificado no bucket do Amazon S3 ou no Armazenamento de Blobs.
Para mais informações, consulte Exportar resultados de consulta para o Amazon S3 e Armazenamento de Blobs.
Vantagens
Desempenho. É possível extrair insights mais rapidamente, já que os dados não são copiados nas nuvens e as consultas são executadas na mesma região em que os dados residem.
Custo. Você economiza em custos de transferência de dados de saída porque os dados não são movidos. Não há cobranças extras na sua conta da AWS nem do Azure relacionadas à análise do BigQuery Omni, porque as consultas são executadas em clusters gerenciados pelo Google. Você paga somente pela execução das consultas, de acordo com o modelo de preços do BigQuery.
Segurança e governança de dados. Você gerencia os dados na assinatura da AWS ou do Azure. Não é necessário mover ou copiar os dados brutos da nuvem pública. Toda a computação é feita no serviço multilocatário do BigQuery, que é executado na mesma região dos dados.
Arquitetura sem servidor. Assim como o restante do BigQuery, o BigQuery Omni é uma oferta sem servidor. O Google implanta e gerencia os clusters que executam o BigQuery Omni. Você não precisa provisionar recursos nem gerenciar clusters.
Gerenciamento mais fácil. O BigQuery Omni tem uma interface de gerenciamento unificada por meio do Google Cloud. O BigQuery Omni pode usar sua conta do Google Cloud e projetos do BigQuery. É possível criar uma consulta GoogleSQL no console do Google Cloud para consultar dados na AWS ou no Azure e conferir os resultados exibidos no console do Google Cloud.
Transferência entre nuvens. É possível carregar dados de buckets do S3 e do Armazenamento de Blobs para tabelas padrão do BigQuery. Para mais informações, consulte Transferir dados do Amazon S3 e Dados do Armazenamento de Blobs para o BigQuery.
Armazenamento em cache de metadados para desempenho
É possível usar metadados em cache para melhorar o desempenho da consulta em tabelas do BigLake que referenciam dados do Amazon S3. Isso é muito útil nos casos em que você está trabalhando com um grande número de arquivos ou quando os dados são particionados no Hive.
Os metadados incluem nomes de arquivos, informações de particionamento e metadados físicos de arquivos, como contagens de linhas. Você pode escolher se quer ativar o armazenamento em cache de metadados em uma tabela. As consultas com um grande número de arquivos e os filtros de partição do Hive são mais beneficiados com o armazenamento em cache de metadados.Se você não ativar o armazenamento em cache de metadados, as consultas na tabela precisarão ler a fonte de dados externa para receber os metadados do objeto. A leitura desses dados aumenta a latência da consulta. Listar milhões de arquivos da fonte de dados externa pode levar vários minutos. Se você ativar o armazenamento em cache de metadados, as consultas podem evitar a listagem de arquivos da fonte de dados externa e podem particionar e remover arquivos mais rapidamente.
Há duas propriedades que controlam esse recurso:
- A inatividade máxima especifica quando as consultas usam metadados armazenados em cache.
- O modo de cache de metadados especifica como os metadados são coletados.
Quando o armazenamento em cache de metadados está ativado, você especifica o intervalo máximo de inatividade dos metadados que é aceitável para operações na tabela. Por exemplo, se você especificar um intervalo de uma hora, as operações na tabela usarão metadados em cache se eles tiverem sido atualizados na última hora. Se os metadados armazenados em cache forem mais antigos que isso, a operação voltará à recuperação de metadados do Amazon S3. É possível especificar um intervalo de inatividade entre 30 minutos e 7 dias.
É possível atualizar o cache de maneira automática ou manual:
- Para atualizações automáticas, o cache é atualizado em um intervalo definido pelo sistema, geralmente entre 30 e 60 minutos. A atualização automática do cache é uma boa abordagem quando os arquivos no Amazon S3 são adicionados, excluídos ou modificados em intervalos aleatórios. Se você precisar controlar o tempo da atualização, por exemplo, para acioná-la no final de um job extract-transform-load, use a atualização manual.
No caso de atualizações manuais, execute o procedimento do sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEpara atualizar o cache de metadados de acordo com uma programação que atenda aos seus requisitos. A atualização manual do cache é uma boa abordagem quando os arquivos no Amazon S3 são adicionados, excluídos ou modificados em intervalos conhecidos, como a saída de um pipeline.Se você emitir várias atualizações manuais simultâneas, apenas uma vai ser bem-sucedida.
O cache de metadados expira após sete dias se não for atualizado.
As atualizações de cache manuais e automáticas são executadas com
a prioridade de consulta INTERACTIVE.
Se você optar por usar atualizações automáticas, recomendamos que crie uma
reserva e, em seguida, crie umuma tarefaBACKGROUND tipo de job
para o projeto que executa os jobs de atualização do cache de metadados. Isso impede que os
jobs de atualização compitam com as consultas do usuário por recursos e
podem falhar se não houver recursos suficientes disponíveis.
Pense em como os valores do intervalo de inatividade e do modo de armazenamento em cache de metadados vão interagir antes de serem definidos. Confira estes exemplos:
- Se você estiver atualizando manualmente o cache de metadados de uma tabela e definir o intervalo de inatividade como dois dias, será necessário executar o procedimento do sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEa cada dois dias ou menos se quiser operações na tabela para usar metadados em cache. - Se você estiver atualizando automaticamente o cache de metadados de uma tabela e definir o intervalo de inatividade como 30 minutos, é possível que algumas das operações na tabela sejam lidas pelo Amazon S3 se a atualização dos metadados de cache levar mais tempo do que a janela normal de 30 a 60 minutos.
Para encontrar informações sobre jobs de atualização de metadados, consulte a
visualização INFORMATION_SCHEMA.JOBS,
como mostrado no exemplo a seguir:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Para mais informações, consulte Armazenamento em cache de metadados.
Tabelas ativadas em cache com visualizações materializadas
É possível usar visualizações materializadas em tabelas ativadas em cache de metadados do Amazon Simple Storage Service (Amazon S3) para melhorar o desempenho e a eficiência ao consultar dados estruturados armazenados no Amazon S3. Essas visualizações materializadas funcionam como visualizações materializadas em tabelas de armazenamento gerenciadas pelo BigQuery, incluindo os benefícios da atualização automática e do ajuste inteligente.
Para disponibilizar os dados do Amazon S3 em uma visualização materializada em uma região compatível do BigQuery para mesclagens, crie uma réplica da visualização materializada. Só é possível criar réplicas de visualizações materializadas em visualizações materializadas autorizadas.
Limitações
Além das limitações para tabelas do BigLake, as limitações a seguir são aplicáveis ao BigQuery Omni, que inclui tabelas do BigLake com base nos dados do Amazon S3 e do Armazenamento de Blobs:
- Não é possível trabalhar com dados em qualquer uma das regiões do BigQuery Omni usando as edições Standard e Enterprise Plus. Para mais informações sobre edições, consulte Introdução às edições do BigQuery.
- As visualizações
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGE,PARTITIONSeINFORMATION_SCHEMAnão estão disponíveis para tabelas do BigLake baseadas nos dados do Amazon S3 e do Armazenamento de Blobs. - As visualizações materializadas não são compatíveis com o Armazenamento de Blobs.
- UDFs em JavaScript não são compatíveis.
Estas instruções SQL não são compatíveis:
- Instruções do BigQuery ML.
- Instruções da linguagem de definição de dados (DDL, na sigla em inglês)
que exigem dados gerenciados no BigQuery. Por
exemplo,
CREATE EXTERNAL TABLE,CREATE SCHEMAouCREATE RESERVATIONsão compatíveis, masCREATE MATERIALIZED VIEWnão é. - Instruções da linguagem de manipulação de dados (DML).
As limitações a seguir se aplicam à consulta e leitura de tabelas temporárias de destino (visualização):
- Não é possível consultar tabelas temporárias de destino com a instrução
SELECT. - Não é possível usar a API BigQuery Storage Read para ler dados de tabelas temporárias de destino.
- Ao usar o driver ODBC,
não há suporte para leituras de alta capacidade (opção
EnableHTAPI).
- Não é possível consultar tabelas temporárias de destino com a instrução
As consultas programadas são compatíveis apenas com a API ou a CLI. A opção tabela de destino está desativada para consultas. Só consultas
EXPORT DATAsão permitidas.A API BigQuery Storage não está disponível nas regiões do BigQuery Omni.
Se a consulta usar a cláusula
ORDER BYe tiver um tamanho de resultado maior que 256 MB, ela falhará. Para resolver isso, reduza o tamanho do resultado ou remova a cláusulaORDER BYda consulta. Para mais informações sobre as cotas do BigQuery Omni, consulte Cotas e limites.Não é possível usar chaves de criptografia gerenciadas pelo cliente (CMEK, na sigla em inglês) com conjuntos de dados e tabelas externas.
Preços
Para informações sobre preços e ofertas por tempo limitado no BigQuery Omni, consulte Preços do BigQuery Omni.
Cotas e limites
Para informações sobre cotas do BigQuery Omni, consulte Cotas e limites.
Se o resultado da consulta for maior que 20 GiB, exporte os resultados para o Amazon S3 ou o Blob Storage. Para saber mais sobre as cotas da API BigQuery Connection, consulte API BigQuery Connection.
Locais
O BigQuery processa consultas no mesmo local do conjunto de dados que contém as tabelas que você está consultando. Depois que você cria o conjunto de dados, o local não pode ser alterado. Os dados residem na sua conta da AWS ou do Azure. As regiões do BigQuery Omni são compatíveis com reservas da edição Enterprise e preços de computação (análise) sob demanda. Para mais informações sobre edições, consulte Introdução às edições do BigQuery.| Descrição da região | Nome da região | Região colocalizada do BigQuery | |
|---|---|---|---|
| AWS | |||
| AWS - US East (N. Virginia) | aws-us-east-1 |
us-east4 |
|
| AWS - Oeste dos EUA (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS – Ásia-Pacífico (Seul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS: Ásia-Pacífico (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europa (Irlanda) | aws-eu-west-1 |
europe-west1 |
|
| AWS: Europa (Frankfurt) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - East US 2 | azure-eastus2 |
us-east4 |
|
A seguir
- Saiba como se conectar ao Amazon S3 e ao Armazenamento de Blobs.
- Saiba como criar tabelas do BigLake no Amazon S3 e no Blob Storage.
- Saiba como consultar tabelas do BigLake no Amazon S3 e no Blob Storage.
- Saiba como mesclar tabelas do BigLake do Amazon S3 e do Armazenamento de Blobs com as do Google Cloud usando junções entre nuvens.
- Saiba como exportar os resultados da consulta para o Amazon S3 e o Armazenamento de Blobs.
- Saiba como transferir dados do Amazon S3 e do Armazenamento de Blobs para o BigQuery.
- Saiba como configurar o perímetro do VPC Service Controls.
- Saiba como especificar seu local.