Introdução ao BigQuery Omni
Com o BigQuery Omni, pode executar estatísticas do BigQuery em dados armazenados no Amazon Simple Storage Service (Amazon S3) ou no Azure Blob Storage através de tabelas do BigLake.
Muitas organizações armazenam dados em várias nuvens públicas. Muitas vezes, estes dados acabam por ser isolados, porque é difícil obter estatísticas em todos os dados. Quer poder analisar os dados com uma ferramenta de dados multinuvem que seja barata, rápida e não crie custos adicionais de gestão de dados descentralizada. Ao usar o BigQuery Omni, reduzimos estas dificuldades com uma interface unificada.
Para executar a análise do BigQuery nos seus dados externos, tem de estabelecer ligação ao Amazon S3 ou ao Blob Storage. Se quiser consultar dados externos, tem de criar uma tabela do BigLake que faça referência a dados do Amazon S3 ou do Blob Storage.
Ferramentas do BigQuery Omni
Pode usar as seguintes ferramentas do BigQuery Omni para executar a análise do BigQuery nos seus dados externos:
- Junções entre nuvens: execute uma consulta diretamente a partir de uma região do BigQuery que possa juntar dados de uma região do BigQuery Omni.
- Vistas materializadas entre nuvens: use réplicas de vistas materializadas para replicar continuamente dados de regiões do BigQuery Omni. Suporta filtragem de dados.
- Transferência entre nuvens com
SELECT: execute uma consulta com a declaraçãoCREATE TABLE AS SELECTouINSERT INTO SELECTnuma região do BigQuery Omni e mova o resultado para uma região do BigQuery. - Transferência entre nuvens com
LOAD: UseLOAD DATAdeclarações para carregar dados diretamente do Amazon Simple Storage Service (Amazon S3) ou do Armazenamento de blobs do Azure para o BigQuery
A tabela seguinte descreve as principais funcionalidades e capacidades de cada ferramenta entre nuvens:
| Junções entre nuvens | Vista materializada entre nuvens | Transferência entre nuvens através do SELECT |
Transferência entre nuvens através do LOAD |
|
|---|---|---|---|---|
| Utilização sugerida | Consultar dados externos para utilização única, onde pode juntar tabelas locais ou juntar dados entre duas regiões diferentes do BigQuery Omni, por exemplo, entre regiões do AWS e do Azure Blob Storage. Use junções entre nuvens se os dados não forem grandes e se o armazenamento em cache não for um requisito essencial | Configurar consultas repetidas ou agendadas para transferir continuamente dados externos de forma incremental, em que o armazenamento em cache é um requisito fundamental. Por exemplo, para manter um painel de controlo | Consultar dados externos para utilização única, de uma região do BigQuery Omni para uma região do BigQuery, onde os controlos manuais, como o armazenamento em cache e a otimização de consultas, são um requisito fundamental, e se estiver a usar consultas complexas que não são suportadas por junções entre nuvens ou vistas materializadas entre nuvens | Migre grandes conjuntos de dados tal como estão, sem necessidade de filtragem, usando consultas agendadas para mover dados não processados |
| Suporta a filtragem antes de mover os dados | Sim. Aplicam-se limites a determinados operadores de consulta. Para mais informações, consulte o artigo Limitações de junção entre nuvens | Sim. Aplicam-se limites a determinados operadores de consulta, como funções de agregação e o operador UNION |
Sim. Sem limites nos operadores de consulta | Não |
| Limitações de tamanho da transferência | 60 GB por transferência (cada subconsulta para uma região remota produz uma transferência) | Sem limite | 60 GB por transferência (cada subconsulta para uma região remota produz uma transferência) | Sem limite |
| Compressão de transferência de dados | Compressão de fios | Colunar | Compressão de fios | Compressão de fios |
| A colocar em cache | Não suportado | Suportado com tabelas com cache ativada com vistas materializadas | Não suportado | Não suportado |
| Preços de saída | Custo de saída e intercontinental da AWS | Custo de saída e intercontinental da AWS | Custo de saída e intercontinental da AWS | Custo de saída e intercontinental da AWS |
| Calcule a utilização para a transferência de dados | Usa slots na região de armazenamento de blobs do AWS ou Azure de origem (reserva ou a pedido) | Não foi utilizado | Usa slots na região de armazenamento de blobs do AWS ou Azure de origem (reserva ou a pedido) | Não foi utilizado |
| Calcular a utilização para filtragem | Usa slots na região de armazenamento de blobs do AWS ou Azure de origem (reserva ou a pedido) | Usa slots na região de armazenamento de blobs do AWS ou Azure de origem (reserva ou a pedido) para calcular vistas materializadas locais e metadados | Usa slots na região de armazenamento de blobs do AWS ou Azure de origem (reserva ou a pedido) | Não foi utilizado |
| Transferência incremental | Não suportado | Suportado para visualizações materializadas não agregadas | Não suportado | Não suportado |
Também pode considerar as seguintes alternativas para transferir dados do Amazon Simple Storage Service (Amazon S3) ou do Azure Blob Storage para Google Cloud:
- Serviço de transferência de armazenamento: transfira dados entre o armazenamento de objetos e de ficheiros no Google Cloud e no Amazon Simple Storage Service (Amazon S3) ou no Azure Blob Storage.
- Serviço de transferência de dados do BigQuery: configure a transferência de dados automatizada para o BigQuery numa base agendada e gerida. Suporta várias origens e é adequado para a migração de dados. O Serviço de transferência de dados do BigQuery não suporta a filtragem.
Arquitetura
A arquitetura do BigQuery separa a computação do armazenamento, o que permite ao BigQuery ser dimensionado conforme necessário para processar cargas de trabalho muito grandes. O BigQuery Omni expande esta arquitetura executando o motor de consultas do BigQuery noutras nuvens. Como resultado, não tem de mover fisicamente os dados para o armazenamento do BigQuery. O processamento ocorre onde esses dados já se encontram.
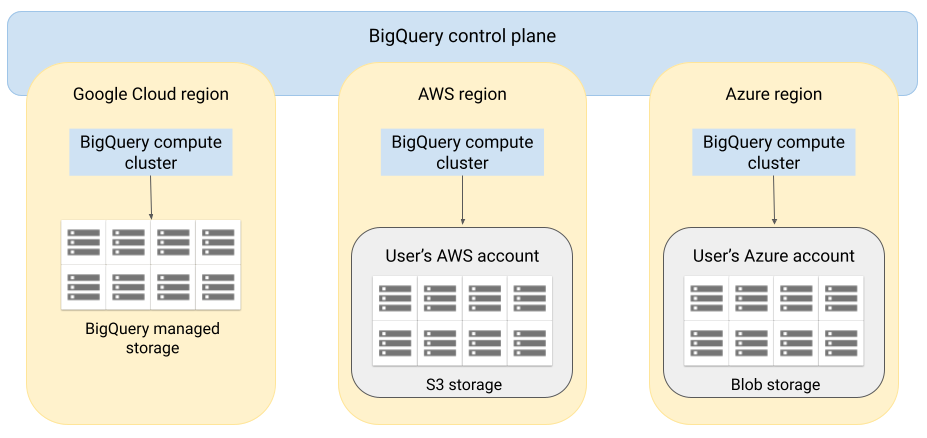
Os resultados da consulta podem ser devolvidos Google Cloud através de uma ligação segura, por exemplo, para serem apresentados na Google Cloud consola. Em alternativa, pode escrever os resultados diretamente em contentores do Amazon S3 ou no Blob Storage. Nesse caso, não existe movimento entre nuvens dos resultados da consulta.
O BigQuery Omni usa funções de IAM do AWS padrão ou principais do Azure Active Directory para aceder aos dados na sua subscrição. Delega o acesso de leitura ou escrita ao BigQuery Omni e pode revogar o acesso em qualquer altura.
Fluxo de dados ao consultar dados
A imagem seguinte descreve como os dados se movem entre o Google Cloud e a AWS ou o Azure para as seguintes consultas:
SELECTdeclaraçãoCREATE EXTERNAL TABLEdeclaração

- O plano de controlo do BigQuery recebe tarefas de consulta suas através da Google Cloud consola, da ferramenta de linhas de comando bq, de um método de API ou de uma biblioteca de cliente.
- O plano de controlo do BigQuery envia tarefas de consulta para tratamento ao plano de dados do BigQuery na AWS ou no Azure.
- O plano de dados do BigQuery recebe a consulta do plano de controlo através de uma ligação VPN.
- O plano de dados do BigQuery lê os dados das tabelas do seu contentor do Amazon S3 ou do Blob Storage.
- O plano de dados do BigQuery executa a tarefa de consulta nos dados da tabela. O processamento dos dados de tabelas ocorre na região da AWS ou do Azure especificada.
- O resultado da consulta é transmitido do plano de dados para o plano de controlo através da ligação VPN.
- O plano de controlo do BigQuery recebe os resultados da tarefa de consulta para apresentação em resposta à tarefa de consulta. Estes dados são armazenados durante um período máximo de 24 horas.
- O resultado da consulta é-lhe devolvido.
Para mais informações, consulte os artigos Consultar dados do Amazon S3 e Dados do armazenamento de blobs.
Fluxo de dados ao exportar dados
A imagem seguinte descreve como os dados se movem entre o Google Cloud e a AWS
ou o Azure durante uma declaração EXPORT DATA.

- O plano de controlo do BigQuery recebe tarefas de consulta de exportação suas através da Google Cloud consola, da ferramenta de linha de comandos bq, de um método de API ou de uma biblioteca de cliente. A consulta contém o caminho de destino do resultado da consulta no seu contentor do Amazon S3 ou armazenamento de blobs.
- O plano de controlo do BigQuery envia tarefas de consulta de exportação para processamento para o plano de dados do BigQuery (na AWS ou no Azure).
- O plano de dados do BigQuery recebe a consulta de exportação do plano de controlo através da ligação VPN.
- O plano de dados do BigQuery lê os dados das tabelas do seu contentor do Amazon S3 ou do Blob Storage.
- O plano de dados do BigQuery executa a tarefa de consulta nos dados da tabela. O processamento dos dados de tabelas ocorre na região da AWS ou do Azure especificada.
- O BigQuery escreve o resultado da consulta no caminho de destino especificado no seu contentor do Amazon S3 ou armazenamento de blobs.
Para mais informações, consulte os artigos Exporte resultados de consultas para o Amazon S3 e Armazenamento de blobs.
Vantagens
Desempenho. Pode obter estatísticas mais rapidamente, porque os dados não são copiados entre nuvens, e as consultas são executadas na mesma região onde os seus dados estão localizados.
Custo. Poupe nos custos de transferência de dados de saída porque os dados não são movidos. Não existem cobranças adicionais na sua conta da AWS ou do Azure relacionadas com a análise do BigQuery Omni, porque as consultas são executadas em clusters geridos pela Google. A faturação é feita apenas pela execução das consultas, através do modelo de preços do BigQuery.
Segurança e governação de dados. Faz a gestão dos dados na sua própria subscrição do AWS ou Azure. Não precisa de mover nem copiar os dados não processados para fora da nuvem pública. Todos os cálculos ocorrem no serviço multi-inquilino do BigQuery, que é executado na mesma região que os seus dados.
Arquitetura sem servidor. Tal como o resto do BigQuery, o BigQuery Omni é uma oferta sem servidor. A Google implementa e gere os clusters que executam o BigQuery Omni. Não precisa de aprovisionar recursos nem gerir clusters.
Facilidade de gestão. O BigQuery Omni oferece uma interface de gestão unificada através do Google Cloud. O BigQuery Omni pode usar a sua conta e projetos do BigQuery existentes. Google Cloud Pode escrever uma consulta GoogleSQL na Google Cloud consola para consultar dados no AWS ou Azure e ver os resultados apresentados na Google Cloud consola.
Transferência entre nuvens. Pode carregar dados em tabelas padrão do BigQuery a partir de contentores do S3 e do armazenamento de blobs. Para mais informações, consulte os artigos Transfira dados do Amazon S3 e Transfira dados do Blob Storage para o BigQuery.
Colocação em cache de metadados para desempenho
Pode usar metadados em cache para melhorar o desempenho das consultas em tabelas do BigLake que referenciam dados do Amazon S3. É especialmente útil nos casos em que está a trabalhar com um grande número de ficheiros ou se os dados estiverem particionados no Apache Hive.
O BigQuery usa o CMETA como um sistema de metadados distribuído para processar tabelas grandes de forma eficiente. O CMETA fornece metadados detalhados ao nível da coluna e do bloco, acessíveis através de tabelas do sistema. Este sistema ajuda a melhorar o desempenho das consultas otimizando o acesso e o processamento de dados. Para acelerar ainda mais o desempenho das consultas em tabelas grandes, o BigQuery mantém uma cache de metadados. As tarefas de atualização de CMETA mantêm esta cache atualizada.Os metadados incluem nomes de ficheiros, informações de partição e metadados físicos de ficheiros, como a contagem de linhas. Pode optar por ativar ou não a colocação em cache de metadados numa tabela. As consultas com um grande número de ficheiros e com filtros de partição do Apache Hive beneficiam mais da colocação em cache de metadados.
Se não ativar a colocação em cache de metadados, as consultas na tabela têm de ler a origem de dados externa para obter os metadados de objetos. A leitura destes dados aumenta a latência da consulta. A listagem de milhões de ficheiros da origem de dados externa pode demorar vários minutos. Se ativar a colocação em cache de metadados, as consultas podem evitar a apresentação de ficheiros da origem de dados externa e podem particionar e reduzir ficheiros mais rapidamente.
A colocação em cache de metadados também se integra com o controlo de versões de objetos do Cloud Storage. Quando a cache é preenchida ou atualizada, captura metadados com base na versão em direto dos objetos do Cloud Storage nesse momento. Como resultado, as consultas com a cache de metadados ativada leem os dados correspondentes à versão específica do objeto em cache, mesmo que versões mais recentes fiquem ativas no Cloud Storage. O acesso a dados de quaisquer versões de objetos atualizadas posteriormente no Cloud Storage requer uma atualização da cache de metadados.
Existem duas propriedades que controlam esta funcionalidade:
- O tempo máximo de desatualização especifica quando as consultas usam metadados em cache.
- O modo de cache de metadados especifica como os metadados são recolhidos.
Quando tem a colocação em cache de metadados ativada, especifica o intervalo máximo de obsolescência dos metadados que é aceitável para operações na tabela. Por exemplo, se especificar um intervalo de 1 hora, as operações na tabela usam metadados em cache se tiverem sido atualizados na última hora. Se os metadados em cache forem mais antigos, a operação recorre à obtenção de metadados do Amazon S3. Pode especificar um intervalo de desatualização entre 30 minutos e 7 dias.
Quando ativa o armazenamento em cache de metadados para tabelas de objetos ou do BigLake, o BigQuery aciona tarefas de atualização da geração de metadados. Pode optar por atualizar a cache de forma automática ou manual:
- Para as atualizações automáticas, a cache é atualizada a um intervalo definido pelo sistema, normalmente entre 30 e 60 minutos. A atualização automática da cache é uma boa abordagem se os ficheiros no Amazon S3 forem adicionados, eliminados ou modificados em intervalos aleatórios. Se precisar de controlar a sincronização da atualização, por exemplo, para acionar a atualização no final de uma tarefa de extração, transformação e carregamento, use a atualização manual.
Para atualizações manuais, executa o procedimento do sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEpara atualizar a cache de metadados de acordo com uma programação que cumpra os seus requisitos. A atualização manual da cache é uma boa abordagem se os ficheiros no Amazon S3 forem adicionados, eliminados ou modificados a intervalos conhecidos, por exemplo, como resultado de um pipeline.Se emitir várias atualizações manuais em simultâneo, apenas uma é bem-sucedida.
A cache de metadados expira após 7 dias se não for atualizada.
As atualizações manuais e automáticas da cache são executadas com a prioridade de consulta INTERACTIVE.
Use reservas do BACKGROUND
Se optar por usar atualizações automáticas, recomendamos que crie uma reserva e, em seguida, crie uma atribuição com um BACKGROUNDtipo de tarefa para o projeto que executa as tarefas de atualização da cache de metadados. Com as reservas BACKGROUND, as tarefas de atualização usam um conjunto de recursos dedicado que impede que as tarefas de atualização concorram com as consultas dos utilizadores e impede que as tarefas falhem potencialmente se não houver recursos suficientes disponíveis para as mesmas.
Embora a utilização de um conjunto de intervalos partilhado não incorra em custos adicionais, a utilização de reservas BACKGROUND oferece um desempenho mais consistente através da atribuição de um conjunto de recursos dedicado e melhora a fiabilidade das tarefas de atualização e a eficiência geral das consultas no BigQuery.
Deve considerar a forma como os valores do intervalo de desatualização e do modo de colocação em cache de metadados interagem antes de os definir. Considere os seguintes exemplos:
- Se estiver a atualizar manualmente a cache de metadados de uma tabela e definir o intervalo de desatualização para 2 dias, tem de executar o procedimento do sistema
BQ.REFRESH_EXTERNAL_METADATA_CACHEa cada 2 dias ou menos se quiser que as operações na tabela usem metadados em cache. - Se estiver a atualizar automaticamente a cache de metadados de uma tabela e definir o intervalo de desatualização como 30 minutos, é possível que algumas das suas operações na tabela possam ler a partir do Amazon S3 se a atualização da cache de metadados demorar mais do que a janela habitual de 30 a 60 minutos.
Para encontrar informações sobre tarefas de atualização de metadados, consulte a vista INFORMATION_SCHEMA.JOBS, conforme mostrado no exemplo seguinte:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Para mais informações, consulte o artigo Colocação em cache de metadados.
Tabelas com cache ativada e vistas materializadas
Pode usar vistas materializadas em tabelas com a cache de metadados do Amazon Simple Storage Service (Amazon S3) ativada para melhorar o desempenho e a eficiência ao consultar dados estruturados armazenados no Amazon S3. Estas vistas materializadas funcionam como vistas materializadas sobre tabelas de armazenamento geridas pelo BigQuery, incluindo as vantagens da atualização automática e da ajustamento inteligente.
Para disponibilizar os dados do Amazon S3 numa visualização materializada numa região do BigQuery suportada para junções, crie uma réplica da visualização materializada. Só pode criar réplicas de vistas materializadas sobre vistas materializadas autorizadas.
Limitações
Além das limitações para tabelas BigLake, aplicam-se as seguintes limitações ao BigQuery Omni, que inclui tabelas BigLake baseadas em dados do Amazon S3 e do Blob Storage:
- Trabalhar com dados em qualquer uma das regiões do BigQuery Omni não é suportado pelas edições Standard e Enterprise Plus. Para mais informações sobre as edições, consulte o artigo Introdução às edições do BigQuery.
- As vistas
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGEePARTITIONSINFORMATION_SCHEMAnão estão disponíveis para tabelas BigLake baseadas em dados do Amazon S3 e Blob Storage. - As vistas materializadas não são suportadas para o Blob Storage.
- As UDFs de JavaScript não são suportadas.
As seguintes declarações SQL não são suportadas:
- Declarações do BigQuery ML.
- Declarações de linguagem de definição de dados (LDD)
que requerem dados geridos no BigQuery. Por
exemplo,
CREATE EXTERNAL TABLE,CREATE SCHEMAouCREATE RESERVATIONsão suportados, masCREATE TABLEnão é. - Instruções de linguagem de manipulação de dados (DML).
Aplicam-se as seguintes limitações à consulta e leitura de tabelas temporárias de destino:
- A consulta de tabelas temporárias de destino com a declaração
SELECTnão é suportada.
- A consulta de tabelas temporárias de destino com a declaração
As consultas agendadas só são suportadas através do método da API ou da CLI. A opção tabela de destino está desativada para consultas. Apenas são permitidas consultas
EXPORT DATA.A API BigQuery Storage não está disponível nas regiões do BigQuery Omni.
Se a sua consulta usar a cláusula
ORDER BYe tiver um tamanho do resultado superior a 256 MB, a consulta falha. Para resolver este problema, reduza o tamanho do resultado ou remova a cláusulaORDER BYda consulta. Para mais informações acerca das quotas do BigQuery Omni, consulte o artigo Quotas e limites.A utilização de chaves de encriptação geridas pelo cliente (CMEK) com conjuntos de dados e tabelas externas não é suportada.
Preços
Para informações sobre preços e ofertas por tempo limitado no BigQuery Omni, consulte os preços do BigQuery Omni.
Quotas e limites
Para informações sobre as quotas do BigQuery Omni, consulte o artigo Quotas e limites.
Se o resultado da consulta for superior a 20 GiB, considere exportar os resultados para o Amazon S3 ou o Blob Storage. Para saber mais acerca das quotas da API BigQuery Connection, consulte o artigo API BigQuery Connection.
Localizações
O BigQuery Omni processa as consultas na mesma localização que o conjunto de dados que contém as tabelas que está a consultar. Depois de criar o conjunto de dados, não é possível alterar a localização. Os seus dados residem na sua conta da AWS ou do Azure. As regiões do BigQuery Omni suportam reservas da Enterprise Edition e preços de computação a pedido (análise). Para mais informações acerca das edições, consulte o artigo Introdução às edições do BigQuery.
| Descrição da região | Nome da região | Região do BigQuery colocada | |
|---|---|---|---|
| AWS | |||
| AWS – Leste dos EUA (Virgínia do Norte) | aws-us-east-1 |
us-east4 |
|
| AWS – Oeste dos EUA (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS - Ásia-Pacífico (Seul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS – Ásia-Pacífico (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europe (Ireland) | aws-eu-west-1 |
europe-west1 |
|
| AWS – Europa (Frankfurt) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure – Leste dos EUA 2 | azure-eastus2 |
us-east4 |
|
O que se segue?
- Saiba como associar ao Amazon S3 e ao armazenamento de blobs.
- Saiba como criar tabelas do BigLake no Amazon S3 e no Blob Storage.
- Saiba como consultar tabelas do BigLake no Amazon S3 e no armazenamento de blobs.
- Saiba como juntar tabelas do Amazon S3 e do armazenamento de blobs do BigLake com Google Cloud tabelas através de junções entre nuvens.
- Saiba como exportar resultados de consultas para o Amazon S3 e o armazenamento de blobs.
- Saiba como transferir dados do Amazon S3 e do armazenamento de blobs para o BigQuery.
- Saiba como configurar o perímetro do VPC Service Controls.
- Saiba como especificar a sua localização