Migração do Snowflake para o BigQuery: vista geral
Este documento mostra como migrar os seus dados do Snowflake para o BigQuery.
Para ver uma estrutura geral para migrar de outros armazéns de dados para o BigQuery, consulte o artigo Vista geral: migre armazéns de dados para o BigQuery.
Vista geral da migração do Snowflake para o BigQuery
Para uma migração do Snowflake, recomendamos que configure uma arquitetura de migração que afete minimamente as operações existentes. O exemplo seguinte mostra uma arquitetura em que pode reutilizar as suas ferramentas e processos existentes enquanto transfere outras cargas de trabalho para o BigQuery.
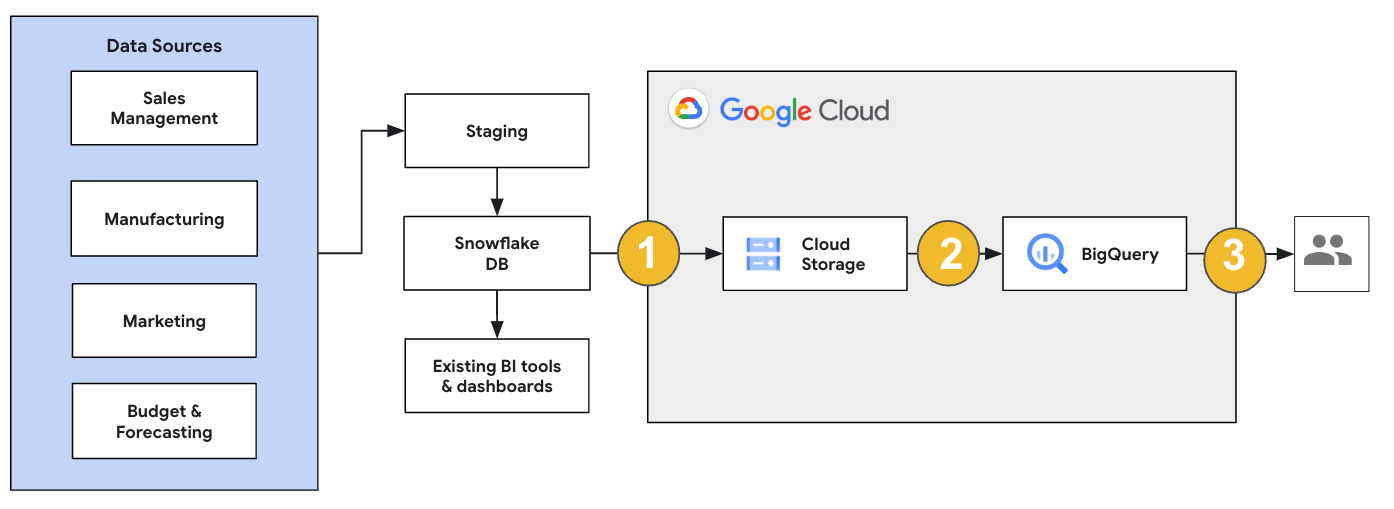
Também pode validar relatórios e painéis de controlo em relação a versões anteriores. Para mais informações, consulte o artigo Migrar armazéns de dados para o BigQuery: verifique e valide.
Migre cargas de trabalho individuais
Ao planear a migração do Snowflake, recomendamos que migre as seguintes cargas de trabalho individualmente pela seguinte ordem:
Migrar esquema
Comece por replicar os esquemas necessários do seu ambiente do Snowflake no BigQuery. Recomendamos que use o serviço de migração do BigQuery para migrar o seu esquema. O serviço de migração do BigQuery suporta uma vasta gama de padrões de design de modelos de dados, como o esquema em estrela ou o esquema em floco de neve, o que elimina a necessidade de atualizar os seus pipelines de dados a montante para um novo esquema. O Serviço de migração do BigQuery também oferece migração de esquemas automatizada, incluindo capacidades de extração e tradução de esquemas, para simplificar o seu processo de migração.
Migre consultas SQL
Para migrar as suas consultas SQL, o Serviço de migração do BigQuery oferece várias funcionalidades de tradução de SQL para automatizar a conversão das suas consultas SQL do Snowflake para SQL do GoogleSQL, como o tradutor de SQL em lote para traduzir consultas em massa, o tradutor de SQL interativo para traduzir consultas individuais e a API de tradução de SQL. Estes serviços de tradução também incluem funcionalidade melhorada pelo Gemini para simplificar ainda mais o processo de migração de consultas SQL.
À medida que traduz as suas consultas SQL, reveja cuidadosamente as consultas traduzidas para verificar se os tipos de dados e as estruturas das tabelas são processados corretamente. Para tal, recomendamos que crie uma grande variedade de exemplos de testes com diferentes cenários e dados. Em seguida, execute estes exemplos de teste no BigQuery para comparar os resultados com os resultados originais do Snowflake. Se existirem diferenças, analise e corrija as consultas convertidas.
Migre dados
Existem várias formas de configurar o pipeline de migração de dados para transferir os seus dados para o BigQuery. Geralmente, estes pipelines seguem o mesmo padrão:
Extraia os dados da sua origem: copie os ficheiros extraídos da sua origem para o armazenamento de preparação no seu ambiente no local. Para mais informações, consulte o artigo Migrar armazéns de dados para o BigQuery: extrair os dados de origem.
Transfira dados para um contentor de preparação do Cloud Storage: depois de terminar a extração de dados da sua origem, transfira-os para um contentor temporário no Cloud Storage. Consoante a quantidade de dados que está a transferir e a largura de banda da rede disponível, tem várias opções.
É importante verificar se a localização do conjunto de dados do BigQuery e da origem de dados externa, ou do contentor do Cloud Storage, estão na mesma região.
Carregue dados do contentor do Cloud Storage para o BigQuery: os seus dados estão agora num contentor do Cloud Storage. Existem várias opções para carregar os dados para o BigQuery. Essas opções dependem da quantidade de dados que têm de ser transformados. Em alternativa, pode transformar os dados no BigQuery seguindo a abordagem ELT.
Quando importa os seus dados em massa a partir de um ficheiro JSON, um ficheiro Avro ou um ficheiro CSV, o BigQuery deteta automaticamente o esquema, pelo que não precisa de o pré-definir. Para obter uma vista geral detalhada do processo de migração do esquema para cargas de trabalho de EDW, consulte o artigo Processo de migração de esquemas e dados.
Para ver uma lista de ferramentas que suportam uma migração de dados do Snowflake, consulte o artigo Ferramentas de migração.
Para ver exemplos completos de configuração de um pipeline de migração de dados do Snowflake, consulte os exemplos de pipeline de migração do Snowflake.
Otimize o esquema e as consultas
Após a migração do esquema, pode testar o desempenho e fazer otimizações com base nos resultados. Por exemplo, pode introduzir a partição para tornar os seus dados mais eficientes de gerir e consultar. A partição de tabelas permite-lhe melhorar o desempenho das consultas e o controlo de custos através da partição por tempo de carregamento, data/hora ou intervalo de números inteiros. Para mais informações, consulte o artigo Introdução às tabelas particionadas.
As tabelas agrupadas são outra otimização do esquema. Pode agrupar as tabelas para organizar os dados das tabelas com base no conteúdo do esquema da tabela, melhorando o desempenho das consultas que usam cláusulas de filtro ou consultas que agregam dados. Para mais informações, consulte o artigo Introdução às tabelas agrupadas.
Tipos de dados, propriedades e formatos de ficheiros suportados
O Snowflake e o BigQuery suportam a maioria dos mesmos tipos de dados, embora, por vezes, usem nomes diferentes. Para ver uma lista completa dos tipos de dados suportados no Snowflake e no BigQuery, consulte Tipos de dados. Também pode usar ferramentas de tradução de SQL, como o tradutor de SQL interativo, a API de tradução de SQL ou o tradutor de SQL em lote, para traduzir diferentes dialetos de SQL para GoogleSQL.
Para mais informações sobre os tipos de dados suportados no BigQuery, consulte os tipos de dados do GoogleSQL.
O Snowflake pode exportar dados nos seguintes formatos de ficheiros. Pode carregar os seguintes formatos diretamente para o BigQuery:
- Carregar dados CSV a partir do Cloud Storage.
- Carregar dados Parquet do Cloud Storage.
- Carregar dados JSON do Cloud Storage.
- Consultar dados do Apache Iceberg.
Ferramentas de migração
A lista seguinte descreve as ferramentas que pode usar para migrar dados do Snowflake para o BigQuery. Para ver exemplos de como estas ferramentas podem ser usadas em conjunto numa pipeline de migração do Snowflake, consulte o artigo Exemplos de pipeline de migração do Snowflake.
- Comando
COPY INTO <location>: use este comando no Snowflake para extrair dados de uma tabela do Snowflake diretamente para um contentor do Cloud Storage especificado. Para um exemplo completo, consulte o artigo Snowflake para BigQuery (snowflake2bq) no GitHub. - Apache Sqoop: Para extrair dados do Snowflake para o HDFS ou o Cloud Storage, envie tarefas do Hadoop com o controlador JDBC do Sqoop e do Snowflake. O Sqoop é executado num ambiente do Dataproc.
- JDBC do Snowflake: use este controlador com a maioria das ferramentas ou aplicações de cliente que suportam JDBC.
Pode usar as seguintes ferramentas genéricas para migrar dados do Snowflake para o BigQuery:
- O conector do Serviço de transferência de dados do BigQuery para o Snowflake Pré-visualização: Faça uma transferência em lote automatizada de dados do Cloud Storage para o BigQuery.
- A CLI do Google Cloud: copie os ficheiros do Snowflake transferidos para o Cloud Storage com esta ferramenta de linha de comandos.
- Ferramenta de linhas de comando bq: interaja com o BigQuery através desta ferramenta de linhas de comando. Os exemplos de utilização comuns incluem a criação de esquemas de tabelas do BigQuery, o carregamento de dados do Cloud Storage em tabelas e a execução de consultas.
- Bibliotecas cliente do Cloud Storage: copie os ficheiros do Snowflake transferidos para o Cloud Storage com uma ferramenta personalizada que usa as bibliotecas cliente do Cloud Storage.
- Bibliotecas de cliente do BigQuery: interaja com o BigQuery com uma ferramenta personalizada criada com base na biblioteca de cliente do BigQuery.
- Agendador de consultas do BigQuery: agende consultas SQL recorrentes com esta funcionalidade integrada do BigQuery.
- Cloud Composer: use este ambiente Apache Airflow totalmente gerido para orquestrar tarefas de carregamento e transformações do BigQuery.
Para mais informações sobre o carregamento de dados para o BigQuery, consulte o artigo Carregar dados para o BigQuery.
Exemplos de pipeline de migração do Snowflake
As secções seguintes mostram exemplos de como migrar os seus dados do Snowflake para o BigQuery através de três processos diferentes: ELT, ETL e ferramentas de parceiros.
Extraia, carregue e transforme
Pode configurar um processo de extração, carregamento e transformação (ELT) com dois métodos:
- Use um pipeline para extrair dados do Snowflake e carregar os dados para o BigQuery
- Extraia dados do Snowflake através de outros Google Cloud produtos.
Use um pipeline para extrair dados do Snowflake
Para extrair dados do Snowflake e carregá-los diretamente no Cloud Storage, use a ferramenta snowflake2bq.
Em seguida, pode carregar os seus dados do Cloud Storage para o BigQuery usando uma das seguintes ferramentas:
- O conector do Serviço de transferência de dados do BigQuery para o Cloud Storage
- O comando
LOADcom a ferramenta de linhas de comando bq - Bibliotecas de cliente da API BigQuery
Outras ferramentas para extrair dados do Snowflake
Também pode usar as seguintes ferramentas para extrair dados do Snowflake:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Conetor do Apache Spark BigQuery
- Conetor do Snowflake para o Apache Spark
- Conetor do Hadoop BigQuery
- O controlador JDBC do Snowflake e do Sqoop para extrair dados do Snowflake para o Cloud Storage:
Outras ferramentas para carregar dados para o BigQuery
Também pode usar as seguintes ferramentas para carregar dados para o BigQuery:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep by Trifacta
Extraia, transforme e carregue
Se quiser transformar os seus dados antes de os carregar para o BigQuery, considere as seguintes ferramentas:
- Dataflow
- Clone o código do modelo JDBC para BigQuery e modifique o modelo para adicionar transformações do Apache Beam.
- Cloud Data Fusion
- Crie um pipeline reutilizável e transforme os seus dados através de plug-ins do CDAP.
- Dataproc
- Transforme os seus dados através do Spark SQL ou de código personalizado em qualquer uma das linguagens Spark suportadas, como Scala, Java, Python ou R.
Ferramentas de parceiros para a migração
Existem vários fornecedores especializados na área de migração de EDW. Para ver uma lista dos principais parceiros e das respetivas soluções, consulte o artigo Parceiros do BigQuery.
Tutorial de exportação do Snowflake
O tutorial seguinte mostra uma exportação de dados de amostra do Snowflake para o
BigQuery que usa o comando COPY INTO <location> Snowflake.
Para um processo detalhado passo a passo que inclui exemplos de código, consulte a Google Cloud ferramenta de serviços profissionais do Snowflake para o BigQuery
Prepare-se para a exportação
Pode preparar os dados da Snowflake para uma exportação extraindo-os para um contentor do Cloud Storage ou do Amazon Simple Storage Service (Amazon S3) com os seguintes passos:
Cloud Storage
Este tutorial prepara o ficheiro no formato PARQUET.
Use declarações SQL do Snowflake para criar uma especificação de formato de ficheiro com nome.
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
Substitua
NAMED_FILE_FORMATpor um nome para o formato de ficheiro. Por exemplo,my_parquet_unload_format.Crie uma integração com o comando
CREATE STORAGE INTEGRATIONcreate storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
Substitua o seguinte:
INTEGRATION_NAME: um nome para a integração de armazenamento. Por exemplo,gcs_intBUCKET_NAME: o caminho para o contentor do Cloud Storage. Por exemplo,gcs://mybucket/extract/
Obtenha a conta de serviço do Cloud Storage para o Snowflake com o comando
DESCRIBE INTEGRATION.desc storage integration INTEGRATION_NAME;
O resultado é semelhante ao seguinte:
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
Conceda à conta de serviço indicada como
STORAGE_GCP_SERVICE_ACCOUNTacesso de leitura e escrita ao contentor especificado no comando de integração de armazenamento. Neste exemplo, conceda à conta de serviçoservice-account-id@acesso de leitura e escrita ao contentor<var>UNLOAD_BUCKET</var>.Crie uma fase do Cloud Storage externa que faça referência à integração que criou anteriormente.
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
Substitua o seguinte:
STAGE_NAME: um nome para o objeto de preparação do Cloud Storage. Por exemplo,my_ext_unload_stage
Amazon S3
O exemplo seguinte mostra como mover dados de uma tabela do Snowflake para um contentor do Amazon S3:
No Snowflake, configure um objeto de integração de armazenamento para permitir que o Snowflake escreva num contentor do Amazon S3 referenciado numa fase de armazenamento na nuvem externo.
Este passo envolve a configuração das autorizações de acesso ao contentor do Amazon S3, a criação da função do IAM dos Amazon Web Services (AWS) e a criação de uma integração de armazenamento no Snowflake com o comando
CREATE STORAGE INTEGRATION:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
Substitua o seguinte:
INTEGRATION_NAME: um nome para a integração de armazenamento. Por exemplo,s3_intBUCKET_NAME: o caminho para o contentor do Amazon S3 para carregar ficheiros. Por exemplo,s3://unload/files/
Obtenha o utilizador do IAM da AWS com o comando
DESCRIBE INTEGRATION.desc integration INTEGRATION_NAME;
O resultado é semelhante ao seguinte:
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ Crie uma função que tenha o privilégio
CREATE STAGEpara o esquema e o privilégioUSAGEpara a integração de armazenamento:CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
Substitua
ROLE_NAMEpor um nome para a função. Por exemplo,myrole.Conceda autorizações ao utilizador do IAM do AWS para aceder ao contentor do Amazon S3 e criar um palco externo com o comando
CREATE STAGE:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
Substitua o seguinte:
STAGE_NAME: um nome para o objeto de preparação do Cloud Storage. Por exemplo,my_ext_unload_stage
Exporte dados do Snowflake
Depois de preparar os dados, pode movê-los para o Google Cloud.
Use o comando COPY INTO para copiar dados da tabela da base de dados Snowflake para um contentor do Cloud Storage ou do Amazon S3, especificando o objeto de preparação externo, STAGE_NAME.
copy into @STAGE_NAME/d1 from TABLE_NAME;
Substitua TABLE_NAME pelo nome da tabela da base de dados do Snowflake.
Como resultado deste comando, os dados da tabela são copiados para o objeto de preparação, que está associado ao bucket do Cloud Storage ou do Amazon S3. O ficheiro inclui o prefixo d1.
Outros métodos de exportação
Para usar o armazenamento de blobs do Azure para as suas exportações de dados, siga os passos detalhados no artigo Carregar para o Microsoft Azure. Em seguida, transfira os ficheiros exportados para o Cloud Storage através do Storage Transfer Service.
Preços
Ao planear a migração do Snowflake, considere o custo de transferir dados, armazenar dados e usar serviços no BigQuery. Para mais informações, consulte a secção Preços.
Podem existir custos de saída para mover dados do Snowflake ou da AWS. Também podem existir custos adicionais quando transfere dados entre regiões ou entre diferentes fornecedores de nuvem.
O que se segue?
- Após a migração, desempenho e otimização.