Bermigrasi dari IBM Netezza
Dokumen ini memberikan panduan tingkat tinggi tentang cara bermigrasi dari Netezza ke BigQuery. Artikel ini menjelaskan perbedaan arsitektur dasar antara Netezza dan BigQuery serta menjelaskan kemampuan tambahan yang ditawarkan BigQuery. Dasbor ini juga menunjukkan cara memikirkan kembali model data yang ada serta proses ekstraksi, transformasi, dan pemuatan (ETL) untuk memaksimalkan manfaat BigQuery.
Dokumen ini ditujukan untuk arsitek perusahaan, DBA, developer aplikasi, dan profesional keamanan IT yang ingin bermigrasi dari Netezza ke BigQuery dan mengatasi tantangan teknis dalam proses migrasi. Dokumen ini memberikan detail tentang fase proses migrasi berikut:
- Mengekspor data
- Menyerap data
- Memanfaatkan alat pihak ketiga
Anda juga dapat menggunakan batch SQL batch untuk memigrasikan skrip SQL secara massal, atau terjemahan SQL interaktif untuk menerjemahkan kueri ad hoc. IBM Netezza SQL/NZPLSQL didukung oleh kedua alat di pratinjau.
Perbandingan arsitektur
Netezza adalah sistem canggih yang dapat membantu Anda menyimpan dan menganalisis data dalam jumlah besar. Namun, sistem seperti Netezza memerlukan investasi besar dalam hardware, pemeliharaan, dan lisensi. Ini bisa jadi sulit untuk diskalakan karena tantangan dalam pengelolaan node, volume data per sumber, dan biaya pengarsipan. Dengan Netezza, kapasitas penyimpanan dan pemrosesan dibatasi oleh peralatan hardware. Saat penggunaan maksimum tercapai, proses memperluas kapasitas alat akan rumit dan terkadang tidak mungkin dilakukan.
Dengan BigQuery, Anda tidak perlu mengelola infrastruktur, dan tidak memerlukan administrator database. BigQuery adalah data warehouse serverless yang terkelola sepenuhnya, berskala petabyte, dan dapat memindai miliaran baris tanpa indeks, dalam puluhan detik. Karena berbagi infrastruktur Google, BigQuery dapat memparalelkan setiap kueri dan menjalankannya di puluhan ribu server secara bersamaan. Teknologi inti berikut membedakan BigQuery:
- Penyimpanan kolumnar. Data disimpan dalam kolom, bukan baris, yang memungkinkan Anda mencapai rasio kompresi yang sangat tinggi dan throughput pemindaian.
- Arsitektur hierarki. Kueri akan dikirim dan hasilnya akan digabungkan ke ribuan mesin dalam beberapa detik.
Arsitektur Netezza
Netezza adalah alat dengan akselerasi hardware yang dilengkapi dengan lapisan abstraksi data software. Lapisan abstraksi data mengelola distribusi data dalam alat dan mengoptimalkan kueri dengan mendistribusikan pemrosesan data di antara CPU dan FPGA yang mendasarinya.
Model Netezza TwinFin dan Striper mencapai akhir dukungannya pada Juni 2019.
Diagram berikut mengilustrasikan lapisan abstraksi data dalam Netezza:
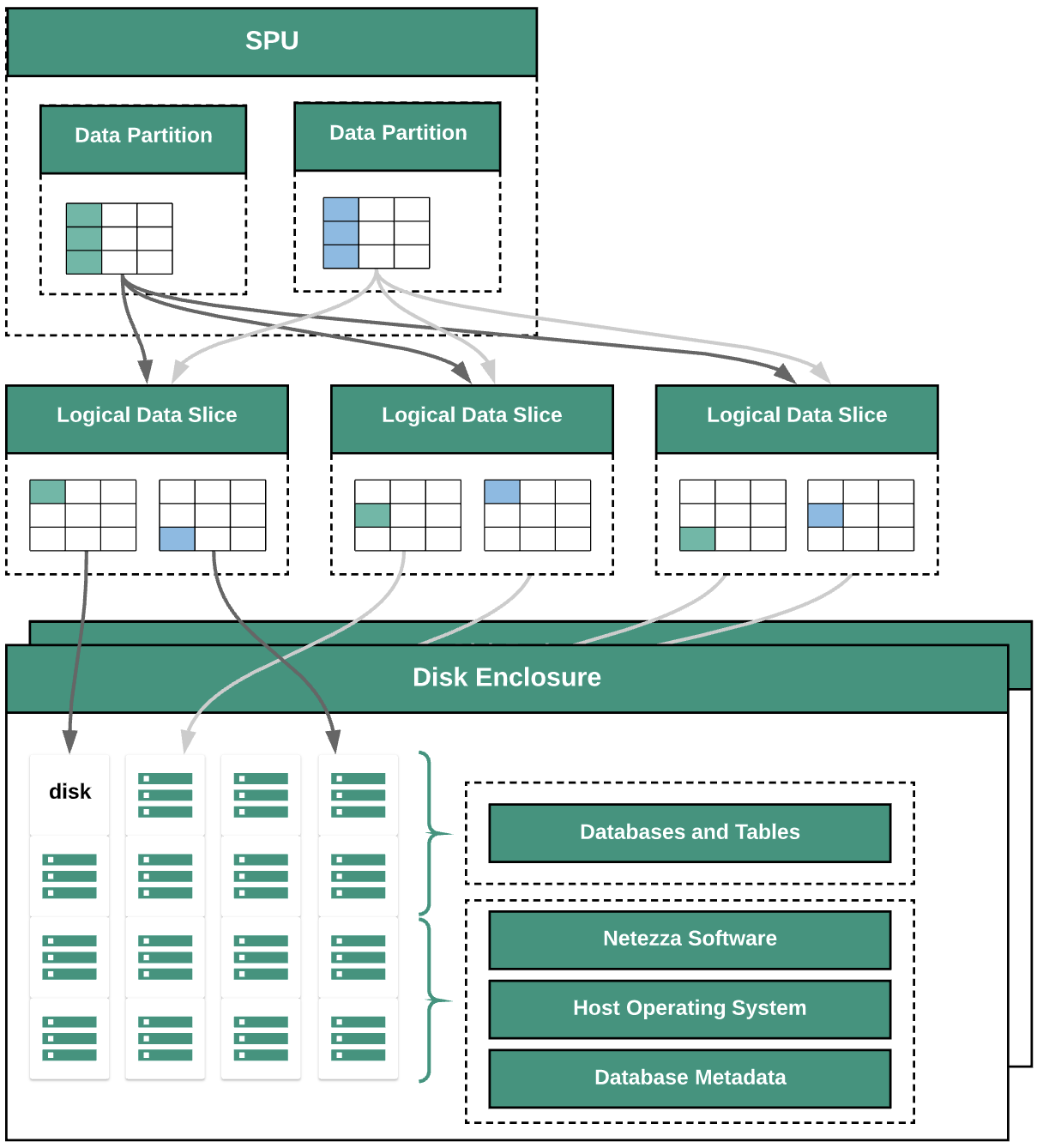
Diagram menampilkan lapisan abstraksi data berikut:
- Penutup disk. Ruang fisik di dalam alat tempat disk dipasang.
- Disk. Drive fisik dalam penutup disk menyimpan database dan tabel.
- Irisan data. Representasi logis dari data yang disimpan di disk.
Data didistribusikan di seluruh irisan data menggunakan kunci distribusi. Anda dapat
memantau status irisan data menggunakan perintah
nzds. - Partisi data. Representasi logis dari irisan data yang dikelola oleh Unit Pemrosesan Cuplikan (SPU) tertentu. Setiap SPU memiliki satu atau beberapa partisi data yang berisi data pengguna yang menjadi tanggung jawab SPU untuk diproses selama kueri.
Semua komponen sistem terhubung oleh fabric jaringan. Alat Netezza menjalankan protokol yang disesuaikan berdasarkan alamat IP.
Arsitektur BigQuery
BigQuery adalah data warehouse perusahaan yang terkelola sepenuhnya yang membantu Anda mengelola dan menganalisis data dengan fitur bawaan seperti machine learning, analisis geospasial, dan business intelligence. Untuk mengetahui informasi selengkapnya, lihat Apa yang dimaksud dengan BigQuery?.
BigQuery menangani penyimpanan dan komputasi untuk memberikan penyimpanan data yang tahan lama dan respons berperforma tinggi terhadap kueri analisis. Untuk mengetahui informasi selengkapnya, baca Penjelasan BigQuery.
Untuk mendapatkan informasi tentang harga BigQuery, baca Memahami penskalaan cepat dan harga sederhana BigQuery.
Pra-migrasi
Untuk memastikan keberhasilan migrasi data warehouse, mulailah merencanakan strategi migrasi lebih awal dari linimasa project Anda. Untuk informasi tentang cara merencanakan pekerjaan migrasi Anda secara sistematis, lihat Apa dan cara melakukan migrasi: Framework migrasi.
Perencanaan kapasitas BigQuery
Throughput analisis di BigQuery diukur dalam slot. Slot BigQuery adalah unit milik Google untuk komputasi, RAM, dan throughput jaringan yang diperlukan untuk menjalankan kueri SQL. BigQuery secara otomatis menghitung berapa banyak slot yang diperlukan oleh setiap kueri, tergantung pada ukuran dan kompleksitas kueri.
Untuk menjalankan kueri di BigQuery, pilih salah satu model harga berikut:
- Sesuai permintaan. Model harga default, yang mengenakan biaya terhadap Anda untuk jumlah byte yang diproses oleh setiap kueri.
- Harga berdasarkan kapasitas. Anda membeli
slot, yang merupakan CPU virtual. Saat membeli slot, Anda membeli kapasitas
pemrosesan khusus yang dapat digunakan untuk menjalankan kueri. Slot tersedia dalam
paket komitmen berikut:
- Tahunan. Anda berkomitmen untuk 365 hari.
- Tiga tahun. Anda berkomitmen untuk 365*3 hari.
Slot BigQuery memiliki beberapa kesamaan dengan SPU Netezza, seperti CPU, memori, dan pemrosesan data; namun, mereka tidak mewakili satuan pengukuran yang sama. SPU Netezza memiliki pemetaan tetap ke komponen hardware yang mendasarinya, sedangkan slot BigQuery mewakili CPU virtual yang digunakan untuk menjalankan kueri. Untuk membantu estimasi slot, sebaiknya siapkan pemantauan BigQuery menggunakan Cloud Monitoring dan menganalisis log audit Anda menggunakan BigQuery. Untuk memvisualisasikan penggunaan slot BigQuery, Anda juga dapat menggunakan alat seperti Looker Studio atau Looker. Memantau dan menganalisis penggunaan slot secara rutin membantu Anda memperkirakan jumlah total slot yang dibutuhkan organisasi saat Anda berkembang di Google Cloud.
Misalnya, anggaplah Anda awalnya mencadangkan 2.000 slot BigQuery untuk menjalankan 50 kueri dengan kompleksitas sedang secara bersamaan. Jika kueri terus dijalankan selama lebih dari beberapa jam dan dasbor Anda menunjukkan penggunaan slot yang tinggi, kueri Anda mungkin tidak akan dioptimalkan atau Anda mungkin memerlukan slot BigQuery tambahan untuk membantu mendukung beban kerja Anda. Untuk membeli slot sendiri dalam komitmen tahunan atau tiga tahun, Anda dapat membuat reservasi BigQuery menggunakan Google Cloud konsol atau alat command line bq. Jika Anda menandatangani perjanjian offline untuk pembelian berbasis kapasitas, paket Anda mungkin berbeda dari detail yang dijelaskan di sini.
Untuk mendapatkan informasi tentang cara mengontrol biaya penyimpanan dan pemrosesan kueri di BigQuery, lihat Mengoptimalkan beban kerja.
Keamanan di Google Cloud
Bagian berikut menjelaskan kontrol keamanan Netezza yang umum dan cara yang dapat Anda lakukan untuk melindungi data warehouse di lingkungan Google Cloud .
Pengelolaan akses dan identitas
Database Netezza berisi kumpulan kemampuan kontrol akses sistem yang terintegrasi sepenuhnya yang memungkinkan pengguna mengakses resource yang mereka miliki izinnya.
Akses ke Netezza dikontrol melalui jaringan ke alat Netezza dengan mengelola akun pengguna Linux yang dapat login ke sistem operasi. Akses ke database, objek, dan tugas Netezza dikelola menggunakan akun pengguna database Netezza yang dapat membuat koneksi SQL ke sistem.
BigQuery menggunakan layanan Identity and Access Management (IAM) Google untuk mengelola akses ke resource. Jenis resource yang tersedia di BigQuery adalah organisasi, project, set data, tabel, dan tampilan. Dalam hierarki kebijakan IAM, set data adalah resource turunan dari project. Tabel mewarisi izin dari set data yang memuatnya.
Untuk memberikan akses ke resource, Anda menetapkan satu atau beberapa peran ke pengguna, grup, atau akun layanan. Peran organisasi dan project mengontrol akses untuk menjalankan tugas atau mengelola project, sedangkan peran set data mengontrol akses untuk melihat atau mengubah data di dalam project.
IAM menyediakan jenis peran berikut:
- Peran bawaan. Untuk mendukung kasus penggunaan umum dan pola kontrol akses.
- Peran dasar. Meliputi peran Pemilik, Editor, dan Pelihat. Peran dasar memberikan akses terperinci untuk layanan tertentu dan dikelola oleh Google Cloud.
- Peran khusus. Memberikan akses terperinci sesuai dengan daftar izin yang ditentukan pengguna.
Saat Anda menetapkan peran dasar dan yang telah ditetapkan kepada pengguna, izin yang diberikan merupakan gabungan izin dari setiap peran individual.
Keamanan tingkat baris
Keamanan multi-level adalah model keamanan abstrak, yang digunakan Netezza untuk menentukan aturan guna mengontrol akses pengguna ke tabel aman baris (RST). Tabel aman baris adalah tabel database dengan label keamanan di baris untuk memfilter pengguna yang tidak memiliki hak istimewa yang sesuai. Hasil yang ditampilkan pada kueri berbeda berdasarkan hak istimewa pengguna yang membuat kueri.
Untuk mencapai keamanan tingkat baris di BigQuery, Anda dapat menggunakan tampilan diberi otorisasi dan kebijakan akses tingkat baris. Untuk mengetahui informasi selengkapnya tentang cara mendesain dan menerapkan kebijakan ini, lihat Pengantar keamanan tingkat baris BigQuery.
Enkripsi data
Peralatan Netezza menggunakan drive enkripsi mandiri (SED) untuk peningkatan keamanan dan perlindungan data yang disimpan di alat. SED mengenkripsi data saat ditulis ke disk. Setiap disk memiliki kunci enkripsi disk (DEK) yang disetel di pabrik dan disimpan di disk. Disk menggunakan DEK untuk mengenkripsi data saat menulis, lalu mendekripsi data saat dibaca dari disk. Pengoperasian disk, serta enkripsi dan dekripsinya, bersifat transparan bagi pengguna yang membaca dan menulis data. Mode enkripsi dan dekripsi default ini disebut sebagai mode penghapusan aman.
Dalam mode penghapusan aman, Anda tidak memerlukan kunci autentikasi atau sandi untuk mendekripsi dan membaca data. SED menawarkan kemampuan yang lebih baik untuk penghapusan yang mudah dan cepat ketika disk harus dialihfungsikan atau ditampilkan karena alasan dukungan atau garansi.
Netezza menggunakan enkripsi simetris; jika data Anda dienkripsi di tingkat kolom, fungsi dekripsi berikut dapat membantu Anda membaca dan mengekspor data:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Semua data yang disimpan dalam BigQuery dienkripsi dalam penyimpanan. Jika ingin mengontrol enkripsi sendiri, Anda dapat menggunakan kunci enkripsi yang dikelola pelanggan (CMEK) untuk BigQuery. Dengan CMEK, alih-alih Google yang mengelola kunci enkripsi kunci yang melindungi data Anda, Andalah yang mengontrol dan mengelola kunci enkripsi kunci di Cloud Key Management Service. Untuk mengetahui informasi selengkapnya, lihat Enkripsi dalam penyimpanan.
Pembandingan performa
Untuk melacak progres dan peningkatan selama proses migrasi, penting untuk menetapkan performa dasar bagi lingkungan Netezza status saat ini. Untuk menetapkan dasar pengukuran, pilih sekumpulan kueri representasional, yang diambil dari aplikasi yang memakai (seperti Tableau atau Cognos).
| Lingkungan | Netezza | BigQuery |
|---|---|---|
| Ukuran data | ukuran TB | - |
| Kueri 1: nama (pemindaian tabel lengkap) | mm:dd.md | - |
| Kueri 2: nama | mm:dd.md | - |
| Kueri 3: nama | mm:dd.md | - |
| Total | mm:dd.md | - |
Penyiapan proyek dasar
Sebelum menyediakan resource penyimpanan untuk migrasi data, Anda harus menyelesaikan penyiapan project.
- Untuk menyiapkan project dan mengaktifkan IAM di level project, lihat Google Cloud Framework dengan Arsitektur yang Baik.
- Untuk mendesain resource dasar agar deployment cloud Anda siap digunakan perusahaan, lihat Desain zona landing di Google Cloud.
- Untuk mempelajari tata kelola data dan kontrol yang Anda perlukan saat memigrasikan data warehouse lokal ke BigQuery, lihat Ringkasan keamanan dan tata kelola data.
Konektivitas jaringan
Koneksi jaringan yang andal dan aman diperlukan antara pusat data lokal (tempat instance Netezza berjalan) dan lingkungan Google Cloud. Untuk mengetahui informasi tentang cara membantu mengamankan koneksi, lihat Pengantar tata kelola data di BigQuery. Saat Anda mengupload ekstrak data, bandwidth jaringan dapat menjadi faktor pembatas. Untuk mengetahui informasi tentang cara memenuhi persyaratan transfer data Anda, lihat Meningkatkan bandwidth jaringan.
Jenis dan properti data yang didukung
Jenis data Netezza berbeda dengan jenis data BigQuery. Untuk mengetahui informasi tentang jenis data BigQuery, lihat Jenis data. Untuk mengetahui perbandingan mendetail antara jenis data Netezza dan BigQuery, lihat Panduan terjemahan SQL IBM Netezza.
Perbandingan SQL
SQL data Netezza terdiri dari DDL, DML, dan Bahasa Kontrol Data (DCL) khusus Netezza, yang berbeda dari GoogleSQL. GoogleSQL sesuai dengan standar SQL 2011 dan memiliki ekstensi yang mendukung kueri data bertingkat dan berulang. Jika Anda menggunakan BigQuery SQL lama, lihat Fungsi dan Operator SQL Lama. Untuk mengetahui perbandingan mendetail antara fungsi dan Netezza serta BigQuery SQL, lihat Panduan terjemahan SQL IBM Netezza.
Untuk membantu migrasi kode SQL Anda, gunakan terjemahan SQL batch untuk memigrasikan kode SQL secara massal, atau terjemahan SQL interaktif untuk menerjemahkan kueri ad hoc.
Perbandingan fungsi
Penting untuk memahami cara fungsi Netezza dipetakan ke
fungsi BigQuery. Misalnya, fungsi Months_Between Netezza
menghasilkan desimal, sedangkan fungsi DateDiff
BigQuery menghasilkan bilangan bulat. Oleh karena itu, Anda harus menggunakan
fungsi UDF kustom untuk menghasilkan jenis data
yang benar. Untuk perbandingan mendetail antara fungsi Netezza SQL dan
GoogleSQL, lihat
Panduan terjemahan SQL IBM Netezza.
Migrasi data
Untuk memigrasikan data dari Netezza ke BigQuery, ekspor data dari Netezza, transfer dan lakukan staging data secara bertahap di Google Cloud, lalu muat data ke BigQuery. Bagian ini memberikan ringkasan umum tentang proses migrasi data. Untuk deskripsi mendetail tentang proses migrasi data, lihat Proses migrasi skema dan data. Untuk perbandingan mendetail antara jenis data yang didukung Netezza dan BigQuery, lihat Panduan terjemahan SQL IBM Netezza.
Ekspor data dari Netezza
Untuk menjelajahi data dari tabel database Netezza, sebaiknya Anda mengekspor ke tabel eksternal dalam format CSV. Untuk mengetahui informasi selengkapnya, lihat Menghapus muatan data ke sistem klien jarak jauh. Anda juga dapat membaca data menggunakan sistem pihak ketiga seperti Informatica (atau ETL kustom) menggunakan konektor JDBC/ODBC untuk menghasilkan file CSV.
Netezza hanya mendukung ekspor file datar (CSV) yang tidak dikompresi untuk setiap tabel.
Namun, jika Anda mengekspor tabel berukuran besar, CSV yang tidak dikompresi dapat menjadi sangat
besar. Jika memungkinkan, pertimbangkan untuk mengonversi CSV ke format berbasis skema seperti
Parquet, Avro, atau ORC, yang menghasilkan file ekspor yang lebih kecil dengan keandalan
yang lebih tinggi. Jika CSV adalah satu-satunya format yang tersedia, sebaiknya lakukan kompresi
file ekspor untuk mengurangi ukuran file sebelum menguploadnya ke Google Cloud.
Mengurangi ukuran file membantu mempercepat upload dan meningkatkan
keandalan transfer. Jika mentransfer file ke Cloud Storage, Anda dapat
menggunakan flag --gzip-local dalam
perintah gcloud storage cp, yang
mengompresi file sebelum menguploadnya.
Transfer data dan staging
Setelah diekspor, data perlu ditransfer dan di-staging di Google Cloud. Ada beberapa opsi untuk mentransfer data, bergantung pada jumlah data yang Anda transfer dan bandwidth jaringan yang tersedia. Untuk mengetahui informasi selengkapnya, lihat Ringkasan transfer data dan skema.
Saat menggunakan Google Cloud CLI, Anda dapat mengotomatiskan dan memparalelkan transfer file ke Cloud Storage. Batasi ukuran file menjadi 4 TB (tidak dikompresi) agar dapat dimuat lebih cepat ke BigQuery. Namun, Anda harus mengekspor skema tersebut terlebih dahulu. Ini adalah kesempatan bagus untuk mengoptimalkan BigQuery menggunakan partisi dan pengelompokan.
Gunakan gcloud storage bucket create
untuk membuat bucket staging untuk menyimpan data yang diekspor, dan gunakan
gcloud storage cp untuk mentransfer
file ekspor data ke bucket Cloud Storage.
gcloud CLI secara otomatis melakukan operasi penyalinan menggunakan kombinasi multithreading dan multipemrosesan.
Memuat data ke BigQuery
Setelah data di-staging di Google Cloud, ada beberapa opsi untuk memuat data ke BigQuery. Untuk mengetahui informasi selengkapnya, lihat Memuat skema dan data ke BigQuery.
Alat dan dukungan partner
Anda bisa mendapatkan dukungan partner dalam perjalanan migrasi Anda. Untuk membantu migrasi kode SQL, gunakan terjemahan SQL batch untuk memigrasikan kode SQL secara massal.
Banyak Google Cloud partner juga menawarkan layanan migrasi data warehouse. Untuk daftar partner dan solusi yang mereka berikan, lihat Bekerja sama dengan partner yang memiliki keahlian BigQuery.
Pascamigrasi
Setelah migrasi data selesai, Anda dapat mulai mengoptimalkan penggunaan Google Cloud untuk memenuhi kebutuhan bisnis. Hal ini dapat mencakup penggunaan alat eksplorasi dan visualisasiGoogle Clouduntuk mendapatkan insight bagi pemangku kepentingan bisnis, mengoptimalkan kueri berperforma buruk, atau mengembangkan program untuk membantu adopsi pengguna.
Menghubungkan ke BigQuery API melalui internet
Diagram berikut menunjukkan cara aplikasi eksternal dapat terhubung ke BigQuery menggunakan API:
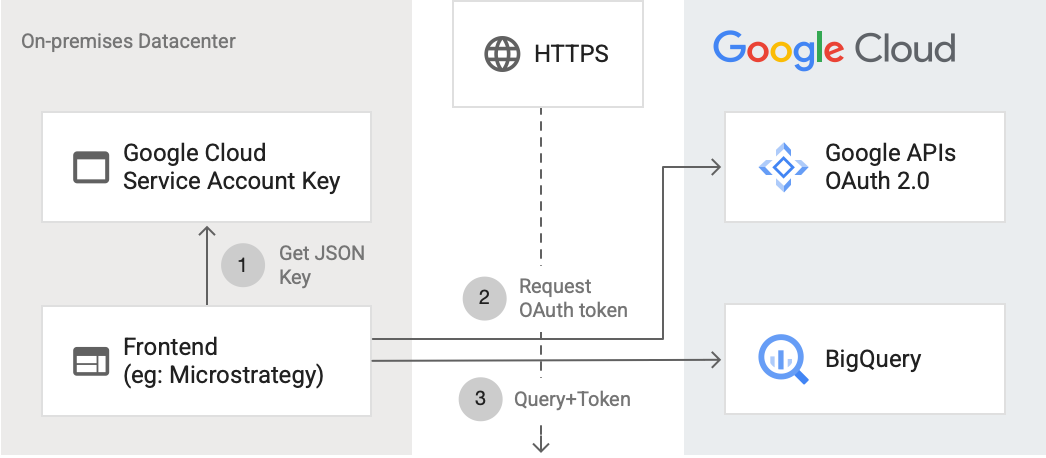
Diagram menunjukkan langkah-langkah berikut:
- Di Google Cloud, akun layanan dibuat dengan izin IAM. Kunci akun layanan dibuat dalam format JSON dan disalin ke server frontend (misalnya, MicroStrategy).
- Frontend membaca kunci dan meminta token OAuth dari Google API di HTTPS.
- Kemudian, frontend mengirimkan permintaan BigQuery beserta token tersebut ke BigQuery.
Untuk mengetahui informasi selengkapnya, lihat Mengizinkan permintaan API.
Mengoptimalkan untuk BigQuery
GoogleSQL mendukung kepatuhan terhadap standar SQL 2011 dan memiliki ekstensi yang mendukung pembuatan kueri data bertingkat dan berulang. Mengoptimalkan kueri untuk BigQuery sangat penting dalam meningkatkan performa dan waktu respons.
Mengganti fungsi Months_Between di BigQuery dengan UDF
Netezza memperlakukan hari dalam sebulan sebagai 31. UDF kustom berikut membuat ulang fungsi Netezza dengan akurasi dekat, yang dapat Anda panggil dari kueri:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Memigrasikan prosedur tersimpan Netezza
Jika menggunakan prosedur tersimpan Netezza di beban kerja ETL untuk membuat tabel fakta, Anda harus memigrasikan prosedur tersimpan ini ke kueri SQL yang kompatibel dengan BigQuery. Netezza menggunakan bahasa skrip NZPLSQL untuk bekerja dengan prosedur yang tersimpan. NZPLSQL didasarkan pada bahasa Postgres PL/pgSQL. Untuk mengetahui informasi selengkapnya, lihat Panduan terjemahan SQL IBM Netezza.
UDF kustom untuk mengemulasi Netezza ASCII
UDF kustom untuk BigQuery berikut memperbaiki error encoding di kolom:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
Langkah berikutnya
- Pelajari cara Mengoptimalkan workload untuk pengoptimalan performa dan pengurangan biaya secara keseluruhan.
- Pelajari cara Mengoptimalkan penyimpanan di BigQuery.
- Lihat panduan terjemahan SQL IBM Netezza.