Migra desde IBM Netezza
En este documento, se proporciona una orientación de alto nivel sobre cómo migrar de Netezza a BigQuery. Describe las diferencias fundamentales de arquitectura entre Netezza y BigQuery. Además describe las capacidades adicionales que ofrece BigQuery. También se muestra cómo puedes reconsiderar tu modelo de datos existente y extraer, transformar y cargar (ETL) procesos para maximizar los beneficios de BigQuery.
Este documento está dirigido a arquitectos empresariales, DBA, desarrolladores de aplicaciones y profesionales de seguridad de TI que desean migrar de Netezza a BigQuery y resolver desafíos técnicos en el proceso de migración. En este documento, se proporcionan detalles sobre las siguientes fases del proceso de migración:
- Exportar datos
- Transfiere datos
- Aprovecha las herramientas de terceros
También puedes usar la traducción de SQL por lotes para migrar tus secuencias de comandos de SQL de forma masiva o la traducción de SQL interactiva para traducir consultas ad hoc. SQL de IBM Netezza/NZPLSQL es compatible con ambas herramientas en la vista previa.
Comparación de arquitecturas
Netezza es un sistema potente que puede ayudarte a almacenar y analizar grandes cantidades de datos. Sin embargo, un sistema como Netezza requiere grandes inversiones en hardware, mantenimiento y licencias. Esto puede ser difícil de escalar debido a los desafíos en la administración de nodos, el volumen de datos por fuente y el costo de los archivados. Con Netezza, la capacidad de almacenamiento y procesamiento están limitadas por los dispositivos de hardware. Cuando se alcanza el uso máximo, el proceso de extensión de la capacidad del dispositivo es aumentado y, a veces, no es posible.
Con BigQuery, no tienes que administrar la infraestructura ni necesitas un administrador de base de datos. BigQuery es un almacén de datos sin servidores, completamente administrado y a escala de petabytes que puede analizar miles de millones de filas, sin un índice, en decenas de segundos. Debido a que BigQuery comparte la infraestructura de Google, puede paralelizar cada consulta y ejecutarla en decenas de miles de servidores de manera simultánea. Las siguientes tecnologías principales diferencian BigQuery:
- Almacenamiento en columnas. Los datos se almacenan en columnas en lugar de filas, lo que permite lograr una proporción de compresión y capacidad de procesamiento de análisis muy altas.
- Arquitectura de árbol. Las consultas se despachan y los resultados se agregan en miles de máquinas en pocos segundos.
Arquitectura de Netezza
Netezza es un dispositivo acelerado por hardware que viene con una capa de abstracción de datos de software. La capa de abstracción de datos administra la distribución de datos en el dispositivo y optimiza las consultas con la distribución del procesamiento de datos entre las CPU y los FPGA subyacentes.
Los modelos Netezza TwinFin y Striper alcanzaron su fin de asistencia en junio de 2019.
En el siguiente diagrama, se ilustran las capas de abstracción de datos en Netezza:
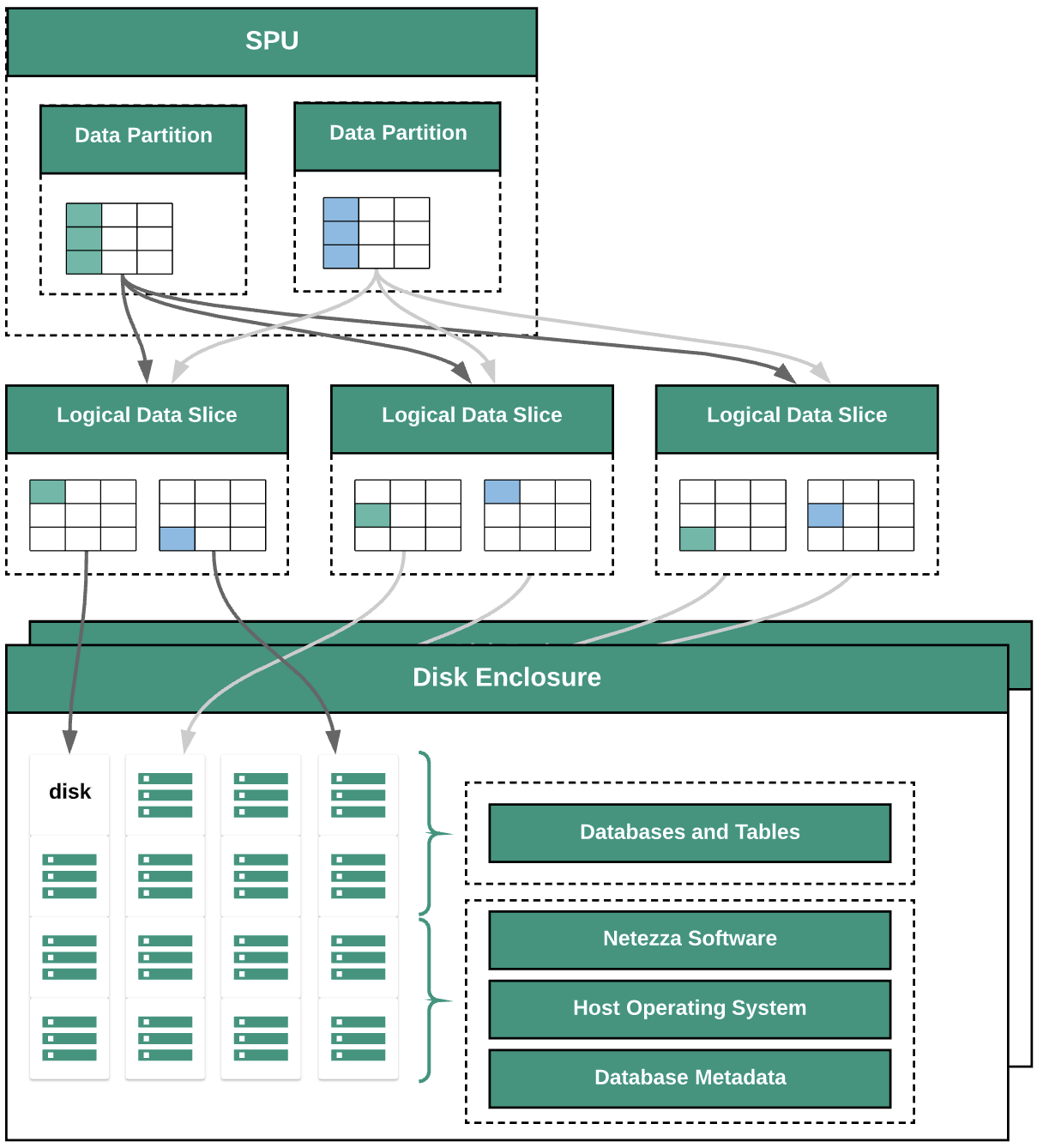
En el diagrama, se muestran las siguientes capas de abstracción de datos:
- Almacenamiento del disco. El espacio físico dentro del dispositivo en el que están activados los discos.
- Discos. Las unidades físicas dentro de los soportes del disco almacenan las bases de datos y las tablas.
- Segmentos de datos. Representación lógica de los datos que se guardan en un disco.
Los datos se distribuyen en las porciones de datos con una clave de distribución. Puedes supervisar el estado de los segmentos de datos mediante los comandos de
nzds. - Particiones de datos. Representación lógica de una porción de datos que administra una unidad de procesamiento de fragmentos (SPU) específica. Cada SPU es propietario de una o más particiones de datos que contienen los datos del usuario que la SPU es responsable de procesar durante las consultas.
Todos los componentes del sistema están conectados por una estructura de red. El dispositivo Netezza ejecuta un protocolo personalizado basado en direcciones IP.
Arquitectura de BigQuery
BigQuery es un almacén de datos empresarial completamente administrado que te ayuda a administrar y analizar tus datos con funciones integradas como el aprendizaje automático, el análisis geoespacial y la inteligencia empresarial. Para obtener más información, consulta ¿Qué es BigQuery?
BigQuery maneja el almacenamiento y el procesamiento para proporcionar almacenamiento de datos duradero y respuestas de alto rendimiento a consultas de estadísticas. Para obtener más información, consulta Explicación de BigQuery.
Para obtener información sobre los precios de BigQuery, consulta Comprende el escalamiento rápido y los precios simples de BigQuery.
Antes de la migración
Para garantizar una migración exitosa al almacén de datos, comienza a planificar tu estrategia de migración al comienzo del cronograma del proyecto. Para obtener información sobre cómo planificar el trabajo de migración de forma sistemática, consulta Qué y cómo migrar: el framework de migración.
Planificación de la capacidad de BigQuery
La capacidad de procesamiento de Analytics en BigQuery se mide en ranuras. Una ranura de BigQuery es la unidad de procesamiento patentada de Google, la RAM y la capacidad de procesamiento de la red que se requiere para ejecutar consultas de SQL. BigQuery calcula de manera automática cuántas ranuras se requieren para cada consulta, según su tamaño y complejidad.
Para ejecutar consultas en BigQuery, elige uno de los siguientes modelos de precios:
- Bajo demanda. El modelo de precios predeterminado, en el que se te cobra por la cantidad de bytes que procesa cada consulta.
- Precios basados en la capacidad. Adquieres
ranuras, que son CPU virtuales. Cuando compras ranuras, adquieres una capacidad de procesamiento dedicada que puedes usar para ejecutar consultas. Las ranuras están disponibles en los siguientes planes de compromiso:
- Anual. Te comprometes a 365 días.
- Tres años. Te comprometes a 365*3 días.
Una ranura de BigQuery comparte algunas similitudes con las SPU de Netezza, como la CPU, la memoria y el procesamiento de datos; sin embargo, no representan la misma unidad de medida. Las SPU de Netezza tienen una asignación fija a los componentes de hardware subyacentes, mientras que la ranura de BigQuery representa una CPU virtual que se usa para ejecutar consultas. Para ayudar con la estimación de ranuras, recomendamos configurar la supervisión de BigQuery mediante Cloud Monitoring y analizar los registros de auditoría con BigQuery. Para visualizar el uso de ranuras de BigQuery, también puedes usar herramientas como Looker Studio o Looker. Supervisar y analizar el uso de ranuras con regularidad te ayuda a estimar la cantidad total de ranuras que necesita la organización a medida que creces en Google Cloud.
Por ejemplo, supongamos que primero reservas 2,000 ranuras de BigQuery para ejecutar 50 consultas de complejidad media de forma simultánea. Si las consultas tardan más de unas horas en ejecutarse y los paneles muestran un uso alto de ranuras, es posible que las consultas no estén optimizadas o que necesites ranuras adicionales de BigQuery para ayudar a las cargas de trabajo. Para comprar ranuras tú mismo en compromisos anuales o de tres años, puedes crear reservas de BigQuery con la consola de Google Cloud o la herramienta de línea de comandos de bq. Si firmaste un acuerdo físico para adquirir el plan basado en la capacidad, tu plan puede ser diferente a lo que se describió en esta página.
Para obtener información sobre cómo controlar los costos de almacenamiento y de procesamiento de consultas en BigQuery, consulta Optimiza las cargas de trabajo.
Seguridad en Google Cloud
En las siguientes secciones, se describen los controles de seguridad comunes de Netezza y cómo puedes ayudar a proteger tu almacén de datos en un entorno de Google Cloud .
Administración de identidades y accesos
La base de datos de Netezza contiene un conjunto de capacidades de control de acceso del sistema completamente integradas que permiten a los usuarios acceder a los recursos para los cuales están autorizados.
El acceso a Netezza se controla a través de la red al dispositivo de Netezza mediante la administración de las cuentas de usuario de Linux que pueden acceder al sistema operativo. El acceso a la base de datos, los objetos y las tareas de Netezza se administra mediante las cuentas de usuario de la base de datos de Netezza que pueden establecer conexiones SQL con el sistema.
BigQuery usa el servicio Identity and Access Management (IAM) de Google para administrar el acceso a los recursos. Los tipos de recursos disponibles en BigQuery son organizaciones, proyectos, conjuntos de datos, tablas y vistas. En la jerarquía de políticas de IAM, los conjuntos de datos son recursos secundarios de los proyectos. Una tabla hereda los permisos del conjunto de datos que la contiene.
Para otorgar acceso a un recurso, debes asignar una o más roles a un usuario, un grupo o una cuenta de servicio. Los roles de organización y proyecto controlan el acceso para ejecutar trabajos o administrar el proyecto, mientras que los roles de conjunto de datos controlan el acceso para ver o modificar los datos dentro de un proyecto.
IAM proporciona los siguientes tipos de roles:
- Roles predefinidos. Para admitir casos de uso comunes y patrones de control de acceso.
- Roles básicos. Incluye los roles de propietario, editor y visualizador. Los roles básicos proporcionan acceso detallado a un servicio específico y los administra Google Cloud.
- Los roles personalizados proporcionan acceso detallado según una lista de permisos especificada por el usuario.
Cuando asignas roles predefinidos y básicos a un usuario, los permisos otorgados son una unión de los permisos de cada rol individual.
Seguridad a nivel de la fila
La seguridad de varios niveles es un modelo de seguridad abstracto, que Netezza usa para definir reglas con el objetivo de controlar el acceso de los usuarios a las tablas seguras (filas) (RST). Una tabla segura para filas es una tabla de base de datos con etiquetas de seguridad en las filas con el objetivo de filtrar a los usuarios que no tienen los privilegios adecuados. Los resultados que se muestran en las consultas difieren según los privilegios del usuario que realiza la consulta.
Para lograr la seguridad a nivel de las filas en BigQuery, puedes usar las vistas autorizadas y las políticas de acceso a nivel de fila. Para obtener más información sobre cómo diseñar y, además, implementar estas políticas, consulta Introducción a la seguridad a nivel de fila de BigQuery.
Encriptación de datos
Los dispositivos Netezza usan unidades de autoencriptación (SED) para mejorar la seguridad y protección de los datos almacenados en el dispositivo. Las SED encriptan los datos cuando se escriben en el disco. Cada disco tiene una clave de encriptación de disco (DEK) que se configura en la fábrica y se almacena en el disco. El disco usa la DEK para encriptar datos a medida que se escriben y, luego, desencriptar los datos cuando se leen desde el disco. La operación del disco, y su encriptación y desencriptación son transparentes para los usuarios que leen y escriben datos. Este modo de encriptación y desencriptación predeterminado se conoce como modo de borrado seguro.
En el modo de borrado seguro, no necesitas una clave de autenticación o contraseña para desencriptar y leer datos. Las SED ofrecen capacidades mejoradas para una eliminación segura y rápida de situaciones en las que los discos se deben reutilizar o devolver por motivos de asistencia o garantía.
Netezza usa encriptación simétrica. Si los datos están encriptados a nivel de campo, la siguiente función de desencriptación puede ayudarte a leer y exportar datos:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
Todos los datos almacenados en BigQuery se encriptan en reposo. Si deseas controlar la encriptación por tu cuenta, puedes usar las claves de encriptación administradas por el cliente (CMEK) para BigQuery. Con CMEK, en lugar de que Google administre las claves de encriptación de claves que protegen tus datos, tú las controlas y las administras en Cloud Key Management Service. Para obtener más información, consulta Encriptación en reposo.
Comparativas de rendimiento
Para llevar a cabo un seguimiento del progreso y la mejora durante el proceso de migración, es importante establecer un rendimiento de referencia para el entorno de Netezza del estado actual. Para establecer el modelo de referencia, elige un conjunto de consultas representativas, que se capturan de las aplicaciones de consumo (como Tableau o Cognos).
| Entorno | Netezza | BigQuery |
|---|---|---|
| Tamaño de los datos | tamaño TB | - |
| Consulta 1: nombre (análisis completo de la tabla) | mm:ss.ms | - |
| Consulta 2: nombre | mm:ss.ms | - |
| Consulta 3: nombre | mm:ss.ms | - |
| Total | mm:ss.ms | - |
Configuración básica del proyecto
Antes de aprovisionar recursos de almacenamiento para la migración de datos, debes completar la configuración de tu proyecto.
- Para configurar proyectos y habilitar IAM a nivel de proyecto, consulta Google Cloud Framework de arquitectura bien diseñada.
- Si deseas diseñar recursos básicos con el objetivo de que tu implementación en la nube esté lista para empresas, consulta Diseño de la zona de destino en Google Cloud.
- Para obtener información sobre la administración de datos y los controles que necesitas cuando migras tu almacén de datos local a BigQuery, consulta Descripción general de la seguridad y administración de datos.
Conectividad de red
Se requiere una conexión de red confiable y segura entre el centro de datos local (en el que se ejecuta la instancia de Netezza) y el entorno de Google Cloud. Para obtener información sobre cómo proteger tu conexión, consulta Introducción a la administración de datos en BigQuery. Cuando subes extractos de datos, el ancho de banda de la red puede ser un factor limitante. Si deseas obtener información para cumplir con tus requisitos de transferencia de datos, consulta Aumenta el ancho de banda de red.
Propiedades y tipos de datos admitidos
Los tipos de datos de Netezza difieren de los de BigQuery. Para obtener información sobre los tipos de datos de BigQuery, consulta Tipos de datos. Para obtener una comparación detallada entre los tipos de datos de Netezza y BigQuery, consulta la guía de traducción de SQL de IBM Netezza.
Comparación de SQL
SQL de datos de Netezza consta de DDL, DML y el lenguaje de control de datos (DCL) solo de Netezza, que son diferentes de GoogleSQL. GoogleSQL cumple con el estándar de SQL 2011 y tiene extensiones que admiten consultas de datos anidados y repetidos. Si usas SQL heredado de BigQuery, consulta Funciones y operadores de SQL heredado. Para obtener una comparación detallada entre Netezza y BigQuery SQL y las funciones, consulta la guía de traducción de IBM Netezza SQL.
Para ayudarte con la migración de tu código SQL, usa la traducción de SQL por lotes a fin de migrar tu código SQL de forma masiva o la traducción SQL interactiva para trasladar consultas ad hoc.
Comparación de funciones
Es importante comprender cómo se asignan las funciones de Netezza a las funciones de BigQuery. Por ejemplo, la función Months_Between de Netezza genera un decimal, mientras que la función DateDiff de BigQuery genera un número entero. Por lo tanto, debes usar una función de UDF personalizada para generar el tipo de datos correcto. Para obtener una comparación detallada entre las funciones de Netezza SQL y GoogleSQL, consulta la guía de traducción de IBM Netezza SQL.
Migración de datos
Para migrar datos de Netezza a BigQuery, debes exportar datos fuera de Netezza, transferirlos y almacenarlos en etapa intermedia en Google Cloud. Luego, cargas los datos en BigQuery. En esta sección, se proporciona una descripción general de alto nivel del proceso de migración de datos. Para obtener una descripción detallada del proceso de migración de datos, consulta Proceso de migración de datos y esquemas. Para obtener una comparación detallada entre los tipos de datos compatibles con Netezza y BigQuery, consulta la guía de traducción de SQL de IBM Netezza.
Exporta datos fuera de Netezza
Para explorar los datos de las tablas de la base de datos de Netezza, te recomendamos que los exportes a una tabla externa en el formato CSV. Para obtener más información, consulta Descarga datos en un sistema de cliente remoto. También puedes leer datos con sistemas de terceros, como Informatica (o ETL personalizado) con conectores JDBC/ODBC para producir archivos CSV.
Netezza solo admite la exportación de archivos planos sin comprimir (CSV) para cada tabla.
Sin embargo, si exportas tablas grandes, el CSV sin comprimir puede volverse muy grande. Si es posible, considera convertir el CSV en un formato compatible con el esquema como Parquet, Avro o ORC, lo que da como resultado archivos de exportación más pequeños con mayor confiabilidad. Si CSV es el único formato disponible, te recomendamos que comprimas los archivos de exportación para reducir el tamaño del archivo antes de subirlo a Google Cloud.
Reducir el tamaño del archivo ayuda a que la carga sea más rápida y aumenta la confiabilidad de la transferencia. Si transfieres archivos a Cloud Storage, puedes usar la marca --gzip-local en un comando gcloud storage cp, que comprime los archivos antes de subirlos.
Transferencia y etapa de pruebas de datos
Después de la exportación de datos, es necesario transferirlos y almacenarlos en etapa intermedia enGoogle Cloud. Existen varias opciones para transferir los datos, según la cantidad que transfieras y el ancho de banda de red disponible. Para obtener más información, consulta Descripción general de transferencia de datos y esquemas.
Cuando usas Google Cloud CLI, puedes automatizar y paralelizar la transferencia de archivos a Cloud Storage. Limita los tamaños de archivo a 4 TB (sin comprimir) para acelerar la carga en BigQuery. Sin embargo, debes exportar el esquema con anticipación. Esta es una buena oportunidad para optimizar BigQuery con la partición y el agrupamiento en clústeres.
Usa gcloud storage bucket create para crear los buckets de etapa de pruebas para el almacenamiento de los datos exportados y usa gcloud storage cp para transferir los archivos de exportación de datos a los buckets de Cloud Storage.
La CLI de gcloud realiza automáticamente la operación de copia con una combinación de varios subprocesos y varios procesamientos.
Carga datos en BigQuery
Después de almacenar los datos en etapa intermedia en Google Cloud, hay varias opciones para cargarlos en BigQuery. Para obtener más información, consulta Carga el esquema y los datos en BigQuery.
Herramientas y asistencia para socios
Puedes obtener asistencia para socios en tu recorrido de migración. Para ayudar con la migración de código SQL, usa la traducción de SQL por lotes con el objetivo de migrar tu código de SQL de forma masiva.
Muchos Google Cloud socios también ofrecen servicios de migración de almacenes de datos. Para obtener una lista de socios y sus soluciones proporcionadas, consulta Trabaja con un socio con experiencia en BigQuery.
Después de la migración
Una vez que se complete la migración de datos, puedes empezar a optimizar el uso deGoogle Cloud para resolver las necesidades empresariales. Esto podría incluir el uso de las herramientas de exploración y visualización deGoogle Cloudcon el objetivo de obtener estadísticas para las partes interesadas de la empresa, optimizar las consultas de bajo rendimiento o desarrollar un programa para ayudar en la adopción de los usuarios.
Conéctate a las APIs de BigQuery a través de Internet
En el siguiente diagrama, se muestra cómo una aplicación externa puede conectarse a BigQuery con la API:
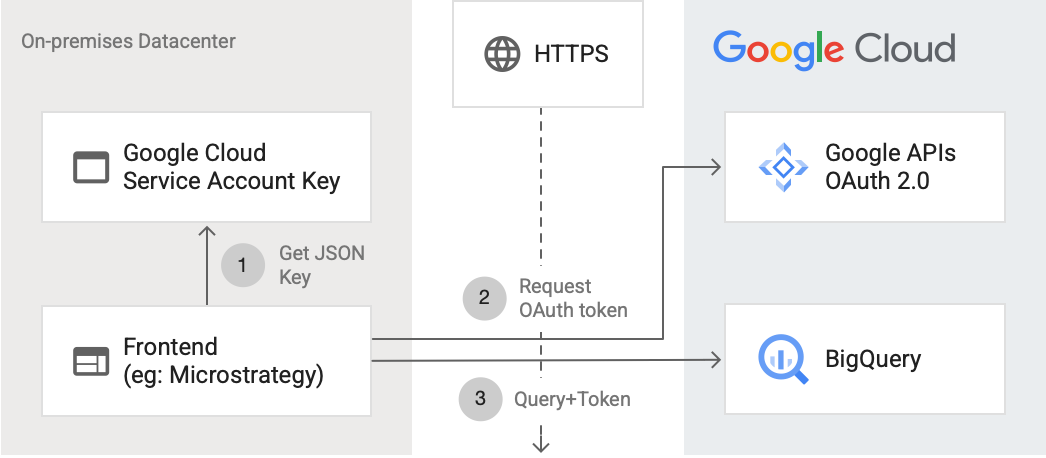
En el diagrama, se muestran los siguientes pasos:
- En Google Cloud, se crea una cuenta de servicio con permisos de IAM. La clave de la cuenta de servicio se genera en formato JSON y se copia en el servidor de frontend (por ejemplo, MicroStrategy).
- El frontend lee la clave y solicita un token de OAuth de las APIs de Google en HTTPS.
- Luego, el frontend envía solicitudes de BigQuery junto con el token a BigQuery.
Para obtener más información, consulta Autoriza solicitudes a la API.
Optimiza para BigQuery
GoogleSQL admite el cumplimiento del estándar de SQL 2011 y tiene extensiones que admiten consultas de datos anidados y repetidos. Optimizar las consultas para BigQuery es fundamental para mejorar el rendimiento y el tiempo de respuesta.
Reemplaza la función Months_Between en BigQuery por UDF
Netezza trata los días en un mes como 31. La siguiente UDF personalizada vuelve a crear la función de Netezza con mucha precisión, a la que puedes llamar desde tus consultas:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
Migra procedimientos almacenados en Netezza
Si usas procedimientos almacenados Netezza en cargas de trabajo de ETL para construir tablas de hechos, debes migrar estos procedimientos almacenados a consultas de SQL compatibles con BigQuery. Netezza usa el lenguaje de programación NZPLSQL para trabajar con procedimientos almacenados. NZPLSQL se basa en el lenguaje PL/pgSQL de Postgres. Para obtener más información, consulta la guía de traducción de SQL de IBM Netezza.
UDF personalizada para emular Netezza ASCII
La siguiente UDF personalizada para BigQuery corrige los errores de codificación en las columnas:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
¿Qué sigue?
- Aprende a optimizar las cargas de trabajo para la optimización del rendimiento general y la reducción de costos.
- Aprende a optimizar el almacenamiento en BigQuery.
- Consulta la guía de traducción de SQL de IBM Netezza.