벡터 검색 대화형 데모를 통해 최신 벡터 검색 기술을 사용해 보세요. 이 데모에서는 실제 데이터 세트를 활용하여 실용적인 예시를 제공합니다. 벡터 검색이 어떻게 작동하는지 배우고, 의미 검색과 하이브리드 검색 방법을 탐구하고, 순위를 다시 매기는 것이 결과를 어떻게 향상시키는지 살펴볼 수 있습니다. 동물, 식물, 전자상거래 제품, 기타 품목에 대한 간단한 설명을 제출하면 벡터 검색에서 가장 관련성이 높은 일치 항목을 찾을 수 있습니다!
사용해 보기
데모에서 여러 옵션으로 실험하여 벡터 검색을 빠르게 시작하고 벡터 검색 기술의 기본 사항을 이해하세요.
안내에 따라 다음을 실행하세요.
쿼리 텍스트 입력란에서 쿼리하려는 항목을 설명합니다(예:
vintage 1970s pinball machine). 또는 쿼리 생성을 클릭하여 설명을 자동으로 생성합니다.제출을 클릭합니다.
데모에서 수행할 수 있는 작업에 대한 자세한 내용은 사용자 인터페이스를 참조하세요.
사용자 인터페이스
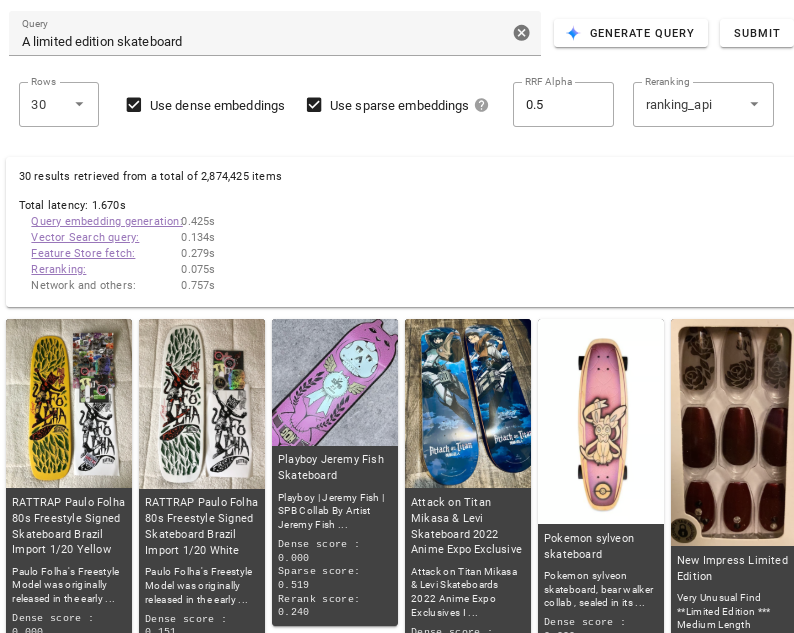
이 섹션에서는 UI에서 벡터 검색으로 반환되는 결과를 제어하기 위해 사용할 수 있는 설정과 결과 순위가 지정되는 방법을 설명합니다.
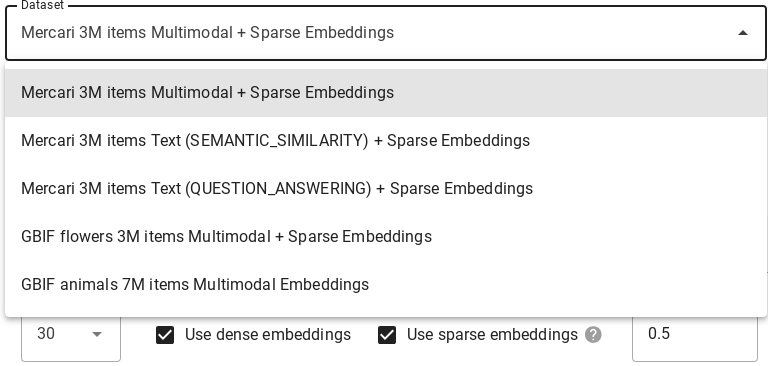
데이터 세트
데이터 세트 드롭다운을 사용하여 벡터 검색으로 쿼리를 실행할 데이터 세트를 선택합니다. 각 데이터 세트에 대한 세부정보는 데이터 세트를 참조하세요.
쿼리
검색어 필드에 벡터 검색으로 찾으려는 항목을 지정하는 하나 이상의 키워드 또는 설명을 추가합니다. 또는 쿼리 생성을 클릭하여 설명을 자동으로 생성합니다.

수정
일부 옵션을 사용하여 벡터 검색이 반환하는 결과를 수정할 수 있습니다.

행을 클릭하고 벡터 검색으로 반환하려는 최대 검색 결과 수를 선택합니다.
벡터 검색이 시맨틱 유사성이 있는 결과를 반환하도록 하려면 밀집 임베딩 사용을 선택합니다.
벡터 검색이 쿼리의 텍스트 구문에 따라 결과를 반환하도록 하려면 희소 임베딩 사용을 선택합니다. 사용 가능한 모든 데이터 세트에서 희소 임베딩 모델이 지원되지는 않습니다.
벡터 검색이 하이브리드 검색을 사용하도록 하려면 밀집 임베딩 사용과 희소 임베딩 사용을 모두 선택합니다. 모든 데이터 세트가 이 모델을 지원하지는 않습니다. 하이브리드 검색은 밀집 임베딩과 희소 임베딩의 요소를 조합하여 검색 결과의 품질을 향상시킬 수 있습니다. 자세한 내용은 하이브리드 검색 정보를 참조하세요.
RRF 알파 필드에 0.0~1.0 사이를 입력하여 RRF 순위 효과를 지정합니다.
검색 결과의 순위를 다시 지정하려면 순위 드롭다운에서 ranking_api를 선택하거나 없음을 선택하여 순위 재지정을 사용 중지합니다.
측정항목
쿼리 실행 후에는 여러 검색 단계에 걸린 시간을 세분화하는 지연 시간 측정항목이 제공됩니다.

쿼리 프로세스
쿼리가 처리되면 다음이 발생합니다.
쿼리 임베딩 생성: 지정된 쿼리 텍스트에 대해 임베딩이 생성됩니다.
벡터 검색 쿼리: 벡터 검색 색인을 사용하여 쿼리가 실행됩니다.
Vertex AI Feature Store 가져오기: Vertex AI Feature Store는 벡터 검색에서 반환된 항목 ID 목록을 사용하여 항목 이름, 설명, 이미지 URL과 같은 특성을 가져오는 데 사용됩니다.
순위 재지정: 검색된 항목은 순위 재지정 API를 통해 저장됩니다. 이 API는 쿼리 텍스트, 항목 이름, 항목 설명을 사용하여 관련 점수를 계산합니다.
임베딩
멀티모달: 항목 이미지를 기반으로 작동하는 멀티모달 시맨틱 검색입니다. 자세한 내용은 멀티모달 검색이란: "비전을 갖춘 LLM"으로 비즈니스를 변화시키는 방식을 참조하세요.
텍스트(시맨틱 유사성): 시맨틱 유사성 기반의 항목 이름 및 설명에 대한 텍스트 시맨틱 검색입니다. 자세한 내용은 텍스트용 Vertex AI 임베딩: 간편해진 LLM 그라운딩을 참조하세요.
텍스트(질의-응답): 항목 이름 및 설명에 대한 텍스트 시맨틱 검색입니다. QUESTION_ANSWERING 태스크 유형을 사용하여 검색 품질이 향상됩니다. Q&A 유형의 애플리케이션에 적합합니다. 태스크 유형 임베딩에 대한 자세한 내용은 Vertex AI 임베딩 및 태스크 유형으로 생성형 AI 사용 사례 개선을 참조하세요.
희소(하이브리드 검색): TF-IDF 알고리즘으로 생성된 항목 이름 및 설명에 대한 키워드(토큰 기반) 검색입니다. 자세한 내용은 하이브리드 검색 정보를 참조하세요.
데이터 세트
대화형 데모에는 쿼리를 실행할 수 있는 여러 데이터 세트가 포함되어 있습니다. 데이터 세트는 임베딩 모델, 희소 임베딩 지원, 임베딩 측정기준, 저장된 항목 수에 따라 서로 다릅니다.
| 데이터 세트 | 임베딩 모델 | 희소 임베딩 모델 | 임베딩 측정기준 | 항목 수 |
|---|---|---|---|---|
| Mercari 멀티모달 + 희소 임베딩 | 멀티모달 임베딩 | TF-IDF (항목 이름 및 설명) |
1408 | 최대 3백만 |
| Mercari 텍스트(시맨틱 유사성) + 희소 임베딩 | text-embedding-005 (태스크 유형: SEMANTIC_SIMILARITY) |
TF-IDF (항목 이름 및 설명) |
768 | 최대 3백만 |
| Mercari 텍스트(질의 응답) + 희소 임베딩 | text-embedding-005 (태스크 유형: QUESTION_ANSWERING) |
TF-IDF (항목 이름 및 설명) |
768 | 최대 3백만 |
| GBIF 꽃 멀티모달 + 희소 임베딩 | 멀티모달 임베딩 | TF-IDF (항목 이름 및 설명) |
1408 | 최대 330만 |
| GBIF 동물 멀티모달 임베딩 | 멀티모달 임베딩 | 해당 사항 없음 | 1408 | 최대 7백만 |
다음 단계
이제 데모에 익숙해졌으므로 벡터 검색 사용 방법을 심층 분석할 수 있습니다.
빠른 시작: 예시 데이터 세트를 사용하여 30분 이내에 색인을 만들고 배포합니다.
시작하기 전에: 임베딩 준비를 위해 수행할 작업을 살펴보고 색인을 배포할 엔드포인트 종류를 결정합니다.