벡터 검색은 시맨틱 검색과 키워드 검색(토큰 기반 검색이라고도 함)을 모두 결합하는 정보 검색(IR)에서 인기 있는 아키텍처 패턴인 하이브리드 검색을 지원합니다. 개발자가 하이브리드 검색을 사용하면 두 가지 방식 중 가장 좋은 점을 활용하여 검색 품질을 효과적으로 높일 수 있습니다.
이 페이지에서는 하이브리드 검색, 시맨틱 검색, 토큰 기반 검색의 개념을 설명하고 토큰 기반 검색 및 하이브리드 검색을 설정하는 방법의 예시를 보여줍니다.
하이브리드 검색이 중요한 이유
벡터 검색 개요의 설명대로 벡터 검색을 사용하는 시맨틱 검색은 쿼리를 사용하여 시맨틱 유사성이 있는 항목을 찾을 수 있습니다.
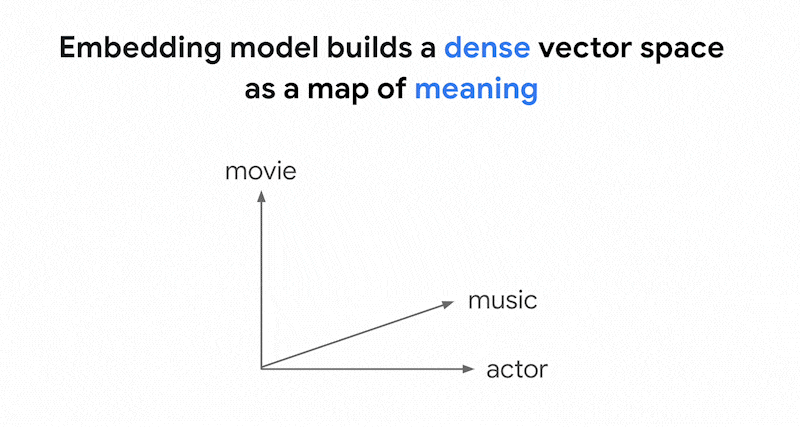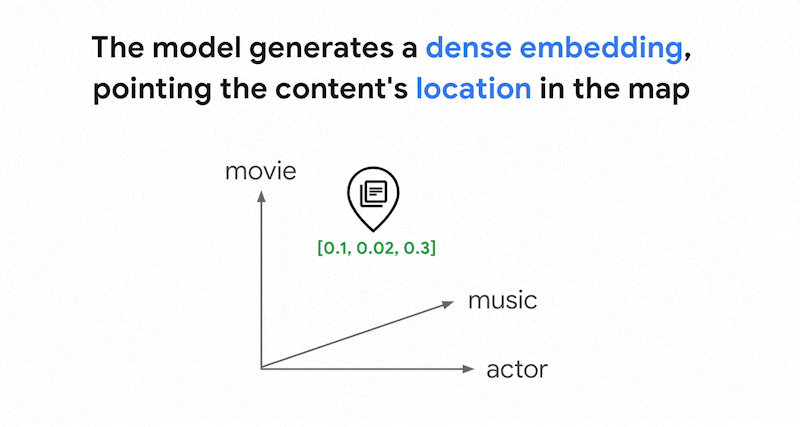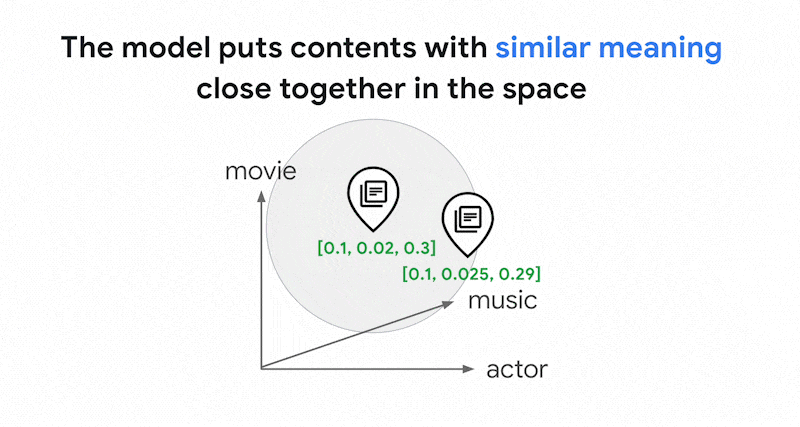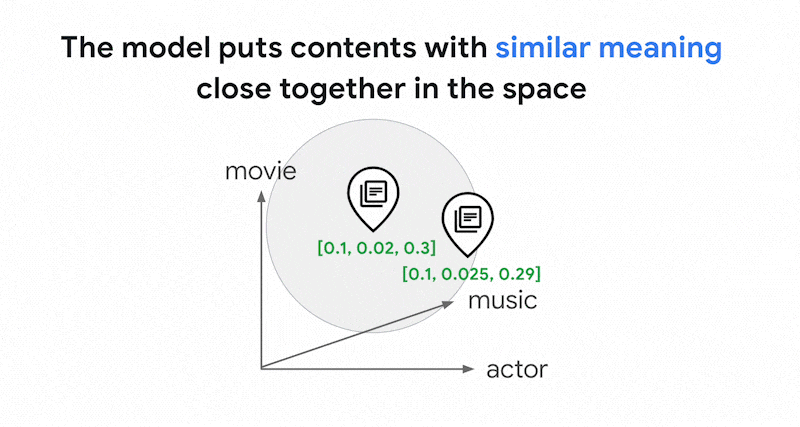
Vertex AI 임베딩과 같은 임베딩 모델은 콘텐츠 의미 지도로 벡터 공간을 빌드합니다. 각 텍스트 또는 멀티모달 임베딩은 지도에서 몇몇 콘텐츠의 의미를 나타내는 위치입니다. 간단한 예시로, 임베딩 모델이 영화에 10%, 음악에 2%, 배우에 30%를 논의하는 텍스트를 가져오면 이 텍스트를 임베딩 [0.1, 0.02,
0.3]으로 나타낼 수 있습니다. 벡터 검색을 사용하면 근처에 있는 다른 임베딩을 빠르게 찾을 수 있습니다. 콘텐츠 의미별로 검색하는 것을 시맨틱 검색이라고 합니다.
임베딩 및 벡터 검색을 사용하는 시맨틱 검색을 통해 IT 시스템을 경험 많은 사서나 상점 직원만큼 스마트하게 만들 수 있습니다. 임베딩은 다양한 비즈니스 데이터를 의미와 연결하는 데 사용될 수 있습니다(예: 쿼리 및 검색 결과, 텍스트 및 이미지, 사용자 활동 및 추천 제품, 영어 텍스트 및 일본어 텍스트 또는 센서 데이터 및 알림 조건). 이 기능을 사용하면 임베딩 사용 사례가 다양해집니다.
시맨틱 검색을 키워드 기반 검색과 결합하는 이유
시맨틱 검색은 검색 증강 생성(RAG)과 같은 정보 검색 애플리케이션에 대한 모든 요구사항을 충족하지는 않습니다. 시맨틱 검색은 임베딩 모델이 이해할 수 있는 데이터만 찾을 수 있습니다. 예를 들어 임의의 제품 번호나 SKU가 포함된 쿼리 또는 데이터 세트, 최근에 추가된 새로운 제품 이름, 기업 독점 코드네임은 임베딩 모델의 학습 데이터 세트에 포함되지 않으므로 시맨틱 검색에서 검색되지 않습니다. 이를 '도메인 외부' 데이터라고 합니다.
이 경우 시맨틱 검색을 키워드 기반(토큰 기반이라고도 함) 검색과 결합하여 하이브리드 검색을 형성해야 합니다. 하이브리드 검색을 사용하면 시맨틱 검색과 토큰 기반 검색을 모두 활용하여 검색 품질을 높일 수 있습니다.
가장 인기 있는 하이브리드 검색 시스템 중 하나는 Google 검색입니다. 이 서비스는 토큰 기반 키워드 검색 알고리즘 외에도 2015년에 RankBrain 모델을 사용하는 시맨틱 검색을 통합했습니다. 하이브리드 검색을 도입함으로써 Google 검색은 의미별 검색과 키워드별 검색이라는 두 가지 요구사항을 해결하여 검색 품질을 크게 개선할 수 있었습니다.
과거에는 하이브리드 검색엔진 빌드가 복잡한 태스크였습니다. Google 검색과 마찬가지로 두 가지 종류의 검색엔진(시맨틱 검색 및 토큰 기반 검색)을 빌드 및 운영하고, 검색 결과를 병합하고 순위를 지정해야 합니다. 벡터 검색의 하이브리드 검색 지원을 사용하면 비즈니스 요구사항에 맞게 맞춤설정된 단일 벡터 검색 색인을 사용하여 자체 하이브리드 검색 시스템을 빌드할 수 있습니다.
토큰 기반 검색 작동 방식
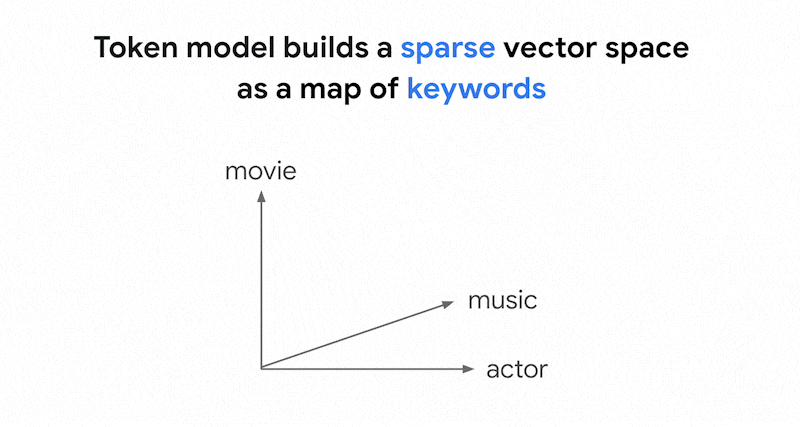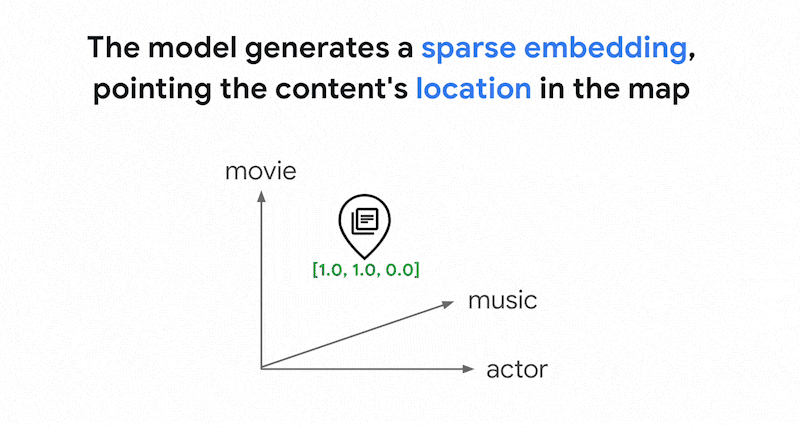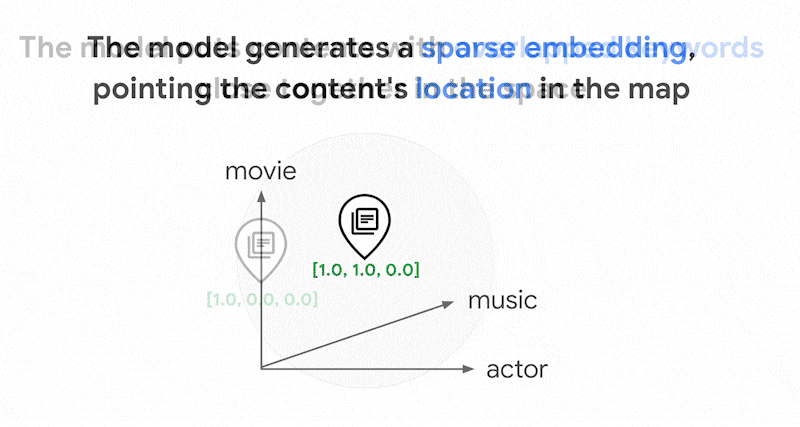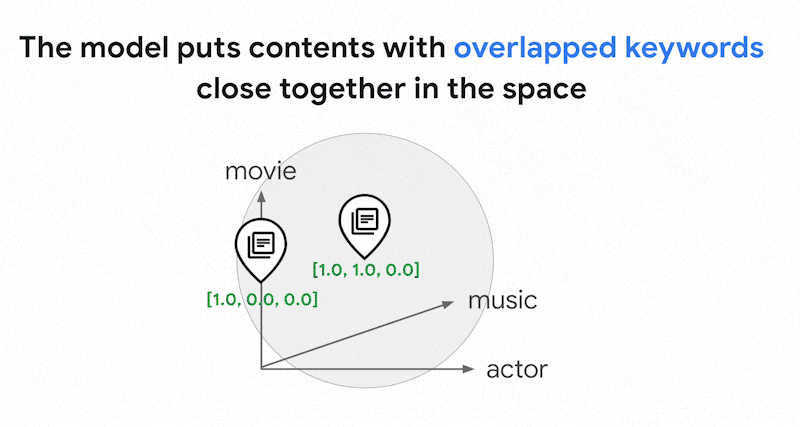
벡터 검색의 토큰 기반 검색은 어떻게 작동하나요? 텍스트를 토큰으로 분할한(예: 단어 또는 서브 워드) 후 TF-IDF, BM25 또는 SPLADE와 같은 널리 사용되는 희소 임베딩 알고리즘을 사용하여 텍스트용 희소 임베딩을 생성할 수 있습니다.
희소 임베딩을 간단히 설명하면 텍스트에 각 단어나 서브 워드가 나타나는 횟수를 나타내는 벡터라고 할 수 있습니다. 일반적인 희소 임베딩은 텍스트의 시맨틱스를 고려하지 않습니다.

텍스트에 사용되는 단어는 수천 개에 달할 수 있습니다. 따라서 이 임베딩은 일반적으로 수만 개의 측정기준을 보유하며, 그중 0이 아닌 값을 갖는 측정기준은 몇 개에 불과합니다. 이러한 이유로 '희소' 임베딩이라고 합니다. 대부분의 값은 0입니다. 이 희소 임베딩 공간은 책의 색인과 마찬가지로 키워드 지도로 작동합니다.
이 희소 임베딩 공간에서는 쿼리 임베딩 이웃을 살펴봐 유사한 임베딩을 찾을 수 있습니다. 이러한 임베딩은 텍스트에 사용된 키워드 분포 면에서 유사합니다.
이는 희소 임베딩을 사용하는 토큰 기반 검색의 기본 메커니즘입니다. 벡터 검색의 하이브리드 검색을 사용하면 밀집 임베딩과 희소 임베딩 모두 단일 벡터 색인에 혼합하고 밀집 임베딩, 희소 임베딩 또는 둘 다를 사용하여 쿼리를 실행할 수 있습니다. 그 결과 시맨틱 검색과 토큰 기반 검색 결과가 결합됩니다.
또한 하이브리드 검색은 역색인 설계가 적용된 토큰 기반 검색엔진에 비해 쿼리 지연 시간이 짧습니다. 시맨틱 검색을 위한 벡터 검색과 마찬가지로 밀집 또는 희소 임베딩이 있는 각 쿼리는 항목이 수백만 개 또는 수십억 개가 있더라도 밀리초 이내에 완료됩니다.
예시: 토큰 기반 검색 사용 방법
토큰 기반 검색을 사용하는 방법을 설명하기 위해 다음 섹션에는 벡터 검색에서 희소 임베딩을 생성하고 이를 사용하여 색인을 빌드하는 코드 예시를 보여줍니다.
이 샘플 코드를 사용해 보려면 시멘틱 검색 및 키워드 검색 결합: Vertex AI 벡터 검색을 사용한 하이브리드 검색 튜토리얼 노트북을 사용합니다.
첫 번째 단계는 입력 데이터 형식 및 구조에 설명된 데이터 형식을 기반으로 희소 임베딩 색인을 빌드할 데이터 파일을 준비하는 것입니다.
JSON에서 데이터 파일은 다음과 같습니다.
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
항목마다 values 및 dimensions 속성이 있는 sparse_embedding 속성이 있어야 합니다. 희소 임베딩에는 0이 아닌 값이 몇 개 있는 수천 개의 측정기준이 있습니다. 이 데이터 형식은 공간에서의 위치와 함께 0이 아닌 값만 포함하므로 효율적으로 작동합니다.
샘플 데이터 세트 준비
샘플 데이터 세트로 Google 브랜드 상품 행이 약 200개 있는 Google Merch Shop 데이터 세트를 사용합니다.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
TF-IDF 벡터라이저 준비
이 데이터 세트를 사용하여 텍스트에서 희소 임베딩을 생성하는 모델인 벡터라이저를 학습합니다. 이 예시에서는 TF-IDF 알고리즘을 사용하는 기본 벡터라이저인 scikit-learn의 TfidfVectorizer를 사용합니다.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
corpus 변수는 'Google Sticker' 또는 'Chrome Dino Pin'과 같은 항목 이름 200개 목록을 보유합니다. 그런 다음 코드에서 fit_transform() 함수를 호출하여 벡터라이저에 전달합니다. 그러면 벡터라이저가 희소 임베딩을 생성할 준비가 됩니다.
TF-IDF 벡터라이저는 데이터 세트의 고유한 단어(예: 'Shirts' 또는 'Dino')에 사소한 단어 (예: 'The', 'a' 또는 'of')보다 더 높은 가중치를 부여하려고 시도하고 지정된 문서에서 이러한 고유한 단어가 사용된 횟수를 계산합니다. 희소 임베딩의 각 값은 개수를 기반으로 각 단어의 빈도를 나타냅니다. TF-IDF에 대한 자세한 내용은 TF-IDF 및 TfidfVectorizer 작동 방식을 참조하세요.
이 예시에서는 편의상 기본 단어 수준 토큰화 및 TF-IDF 벡터화를 사용합니다. 프로덕션 개발에서는 요구사항에 따라 희소 임베딩을 생성할 수 있도록 다른 토큰화 및 벡터화 옵션을 선택할 수 있습니다. 토크나이저의 경우 대부분 서브 워드 토크나이저가 단어 수준 토큰화보다 성능이 우수하며 많이 사용됩니다. 벡터라이저의 경우 BM25가 TF-IDF의 개선된 버전으로 널리 사용됩니다. SPLADE는 희소 임베딩에 대한 일부 시맨틱스를 사용하는 또 다른 인기 있는 벡터화 알고리즘입니다.
희소 임베딩 가져오기
벡터 검색에서 벡터라이저를 더 쉽게 사용할 수 있도록 래퍼 함수인 get_sparse_embedding()을 정의합니다.
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
이 함수는 'text' 파라미터를 벡터라이저에 전달하여 희소 임베딩을 생성합니다. 그런 다음 벡터 검색 희소 색인을 빌드할 수 있도록 앞서 언급한 {"values": ...., "dimensions": ...} 형식으로 변환합니다.
이 함수를 테스트할 수 있습니다.
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
그러면 다음과 같은 희소 임베딩이 출력됩니다.
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
입력 데이터 파일 만들기
이 예시에서는 200개 항목 모두에 대해 희소 임베딩을 생성합니다.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
이 코드는 항목마다 다음과 같은 줄을 생성합니다.
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
그런 다음 줄을 JSONL 파일 'items.json'으로 저장하고 Cloud Storage 버킷에 업로드합니다.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gcloud storage cp items.json $BUCKET_URI
벡터 검색에서 희소 임베딩 색인 만들기
다음으로 벡터 검색에서 희소 임베딩 색인을 빌드하고 배포합니다. 이 절차는 벡터 검색 빠른 시작에 설명된 절차와 동일합니다.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
색인을 사용하려면 색인 엔드포인트를 만들어야 합니다. 색인 쿼리 요청을 수락하는 서버 인스턴스 역할을 합니다.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
색인 엔드포인트에서 배포된 고유 색인 ID를 지정하여 색인을 배포합니다.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
배포가 완료되면 테스트 쿼리를 실행할 수 있습니다.
희소 임베딩 색인을 사용하여 쿼리 실행
희소 임베딩 색인을 사용하여 쿼리를 실행하려면 다음 예시와 같이 쿼리 텍스트의 희소 임베딩을 캡슐화하는 HybridQuery 객체를 만들어야 합니다.
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
이 예시 코드에서는 쿼리에 'Kids'라는 텍스트를 사용합니다. 이제 HybridQuery 객체로 쿼리를 실행합니다.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
다음과 같은 출력이 표시됩니다.
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
항목 200개 중 'Kids' 키워드가 있는 항목 이름이 결과에 포함됩니다.
예시: 하이브리드 검색 사용 방법
이 예시에서는 토큰 기반 검색을 시맨틱 검색과 결합하여 벡터 검색에서 하이브리드 검색을 만듭니다.
하이브리드 색인을 만드는 방법
하이브리드 색인을 빌드하려면 항목마다 'embedding'(밀집 임베딩의 경우) 및 'sparse_embedding'이 모두 있어야 합니다.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
get_dense_embedding() 함수는 측정기준 768개가 있는 텍스트 임베딩을 생성할 수 있도록 Vertex AI Embedding API를 사용합니다. 이렇게 하면 다음 형식으로 밀집 임베딩과 희소 임베딩 모두 생성됩니다.
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
나머지 프로세스는 예시: 토큰 기반 검색 사용 방법과 동일합니다. JSONL 파일을 Cloud Storage 버킷에 업로드하고 이 파일로 벡터 검색 색인을 만들고 색인을 색인 엔드포인트에 배포합니다.
하이브리드 쿼리 실행
하이브리드 색인을 배포하면 하이브리드 쿼리를 실행할 수 있습니다.
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
쿼리 텍스트 'Kids'의 경우 단어에 대해 밀집 임베딩과 희소 임베딩을 모두 생성하고 HybridQuery 객체로 캡슐화합니다. 이전 HybridQuery와의 차이점은 dense_embedding 및 rrf_ranking_alpha라는 두 가지 추가 파라미터입니다.
이번에는 각 항목의 거리를 출력합니다.
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
각 neighbor 객체에는 쿼리와 밀집 임베딩이 있는 항목 간의 거리가 있는 distance 속성과 희소 임베딩과의 거리가 있는 sparse_distance 속성이 있습니다. 이러한 값은 거리가 역전된 값이므로 값이 클수록 거리가 짧습니다.
HybridQuery를 사용하여 쿼리를 실행하면 다음과 같은 결과가 표시됩니다.
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
'Kids' 키워드가 포함된 토큰 기반 검색 결과 외에도 시맨틱 검색 결과도 포함됩니다. 예를 들어 'Google White Classic Youth Tee'가 포함되는 이유는 임베딩 모델이 'Youth'와 'Kids'가 의미상 유사하다는 것을 알고 있기 때문입니다.
하이브리드 검색은 토큰 기반 검색 결과와 시맨틱 검색 결과를 병합하기 위해 상호 순위 융합(RRF)을 사용합니다. RRF 및 rrf_ranking_alpha 파라미터를 지정하는 방법에 대한 자세한 내용은 상호 순위 융합이란 무엇인가요?를 참조하세요.
순위 재지정
RRF는 시맨틱 및 토큰 기반 검색 결과의 순위를 병합하는 방법을 제공합니다. 많은 프로덕션 정보 검색 또는 추천자 시스템에서 결과는 추가 정밀도 순위 알고리즘(재순위화라고 함)을 거칩니다. 밀리초 수준의 빠른 검색을 벡터 검색과 결합하고 결과에 대한 정밀한 재순위화를 사용하면 더 높은 검색 품질이나 추천 성능을 제공하는 다단계 시스템을 빌드할 수 있습니다.
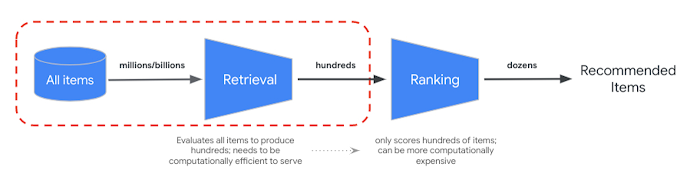
Vertex AI Ranking API는 선행 학습된 모델을 사용하여 검색어 텍스트와 검색 결과 텍스트 간의 일반적인 관련성을 기반으로 순위를 구현하는 방법을 제공합니다. TensorFlow Ranking에서는 다양한 비즈니스 요구사항에 맞게 맞춤설정할 수 있는 고급 재순위화를 위한 순위 지정 학습(LTR) 모델을 설계하고 학습시키는 방법도 소개합니다.
하이브리드 검색 사용
다음 리소스를 사용하면 벡터 검색에서 하이브리드 검색을 사용할 수 있습니다.
하이브리드 검색 리소스
- 시맨틱 및 키워드 검색 결합: Vertex AI 벡터 검색을 사용한 하이브리드 검색 튜토리얼: 하이브리드 검색을 시작하기 위한 샘플 노트북
- 입력 데이터 형식 및 구조: 희소 임베딩 색인을 빌드하기 위한 입력 데이터 형식
- 공개 색인을 쿼리하여 최근접 이웃 가져오기: 하이브리드 검색으로 쿼리를 실행하는 방법
- 상호 순위 융합이 콩도르세 및 개별 순위 학습 방법보다 우수함: RRF 알고리즘 논의
벡터 검색 리소스
추가 개념
다음 섹션에서는 TF-IDF 및 TfidVectorizer, 상호 순위 융합, 알파 파라미터를 자세히 설명합니다.
TF-IDF 및 TfidfVectorizer 작동 방식
fit_transform() 함수는 TF-IDF 알고리즘의 두 가지 중요 프로세스를 실행합니다.
맞춤: 벡터라이저는 어휘의 각 용어에 대한 역문서 빈도(IDF)를 계산합니다. IDF는 전체 코퍼스에서 특정 용어가 얼마나 중요한지 나타냅니다. 희귀한 용어는 IDF 점수가 더 높습니다.
IDF(t) = log_e(Total number of documents / Number of documents containing term t)변환:
- 토큰화: 문서를 개별 용어(단어 또는 문구)로 분류합니다.
용어 빈도(TF) 계산: 다음을 사용하여 각 문서에서 각 용어가 나타나는 빈도를 계산합니다.
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)TF-IDF 계산: 각 용어의 TF를 사전 계산된 IDF와 결합하여 TF-IDF 점수를 만듭니다. 이 점수는 전체 코퍼스에 비해 특정 문서에서 용어의 중요성을 나타냅니다.
TF-IDF(t, d) = TF(t, d) * IDF(t)TF-IDF 벡터라이저는 사소한 단어(예: 'The', 'a' 또는 'of')에 비해 데이터 세트의 고유한 단어('Shirts' 또는 'Dino')에 더 높은 가중치를 부여하고 지정된 문서에서 이러한 고유한 단어가 사용된 횟수를 계산합니다. 희소 임베딩의 각 값은 개수를 기반으로 각 단어의 빈도를 나타냅니다.
상호 순위 융합이란 무엇인가요?
하이브리드 검색은 토큰 기반 검색 결과와 시맨틱 검색 결과를 병합하기 위해 상호 순위 융합(RRF)을 사용합니다. RRF는 항목 순위 목록 여러 개를 단일 통합 순위로 결합하는 알고리즘입니다. 특히 하이브리드 검색 시스템과 대규모 언어 모델에서 다양한 소스 또는 검색 방법의 검색 결과를 병합하는 데 많이 사용되는 기법입니다.
벡터 검색의 하이브리드 검색의 경우 밀집 거리와 희소 거리는 서로 다른 공간에서 측정되므로 서로 직접 비교할 수 없습니다. 따라서 RRF는 서로 다른 공간 2개에서 결과를 병합하고 순위를 지정하는 데 효과적입니다.
RRF 작동 방식은 다음과 같습니다.
- 상호 순위: 순위 목록 항목마다 상호 순위를 계산합니다. 즉, 목록에서 항목 위치(순위)를 역으로 취합니다. 예를 들어 1위인 항목은 상호 순위 1/1 = 1을, 2위인 항목은 1/2 = 0.5를 받습니다.
- 상호 순위 합계: 모든 순위 목록에서 각 항목의 상호 순위를 합산합니다. 이렇게 하면 각 항목의 최종 점수가 계산됩니다.
- 최종 점수순으로 정렬: 최종 점수순으로 항목을 내림차순으로 정렬합니다. 점수가 가장 높은 항목이 가장 관련성이 높거나 중요한 것으로 간주됩니다.
즉, 밀집 결과와 희소 결과 모두에서 순위가 더 높은 항목을 목록 상단으로 가져옵니다. 따라서 'Google Blue Kids Sunglasses' 항목이 밀집 및 희소 검색 결과 모두에서 순위가 높으므로 상단에 표시됩니다. 'Google White Classic Youth Tee'와 같은 항목은 밀집 검색 결과에서만 순위가 지정되므로 순위가 낮습니다.
알파 파라미터 동작 방식
하이브리드 검색을 사용하는 방법의 예시에서는 HybridQuery 객체를 만들 때 파라미터 rrf_ranking_alpha를 0.5로 설정합니다. rrf_ranking_alpha에 다음 값을 사용하여 밀집 및 희소 검색 결과의 순위에 가중치를 지정할 수 있습니다.
1또는 지정되지 않음: 하이브리드 검색은 밀집 검색 결과만 사용하고 희소 검색 결과를 무시합니다.0: 하이브리드 검색은 희소 검색 결과만 사용하고 밀집 검색 결과를 무시합니다.0~1: 하이브리드 검색은 밀집 및 희소 검색의 결과 모두를 값으로 지정된 가중치와 함께 병합합니다. 0.5는 동일한 가중치로 병합됨을 의미합니다.