Vector Search mendukung penelusuran campuran, yakni pola arsitektur populer dalam pengambilan informasi (IR) yang menggabungkan penelusuran semantik dan penelusuran kata kunci (juga disebut penelusuran berbasis token). Dengan penelusuran campuran, developer dapat memanfaatkan keunggulan dari kedua pendekatan, sehingga secara efektif memberikan kualitas penelusuran yang lebih tinggi.
Halaman ini menjelaskan konsep penelusuran campuran, penelusuran semantik, dan penelusuran berbasis token, serta menyertakan contoh cara menyiapkan penelusuran berbasis token dan penelusuran campuran:
- Mengapa penelusuran hibrida penting?
- Contoh: Cara menggunakan penelusuran berbasis token
- Contoh: Cara menggunakan penelusuran campuran
- Mulai menggunakan penelusuran campuran
- Konsep tambahan
Mengapa penelusuran hybrid penting?
Seperti yang dijelaskan dalam Ringkasan Vector Search, penelusuran semantik dengan Vector Search dapat menemukan item dengan kesamaan semantik menggunakan kueri.
Model embedding seperti Vertex AI
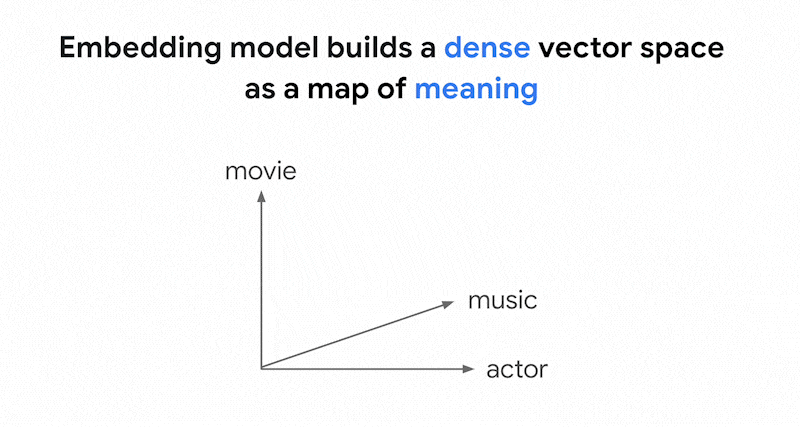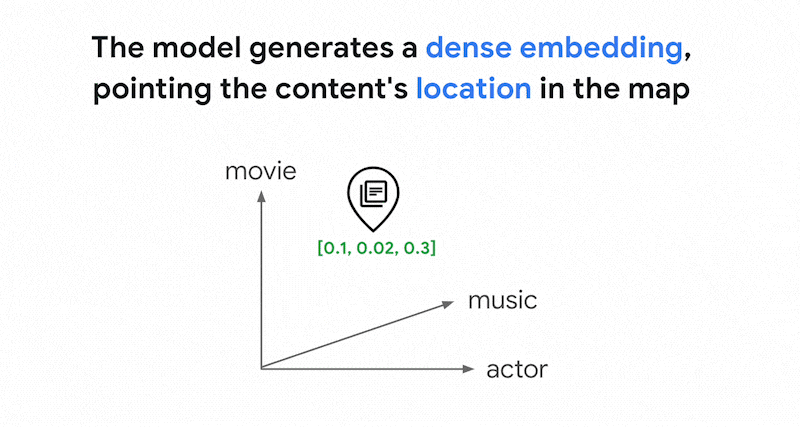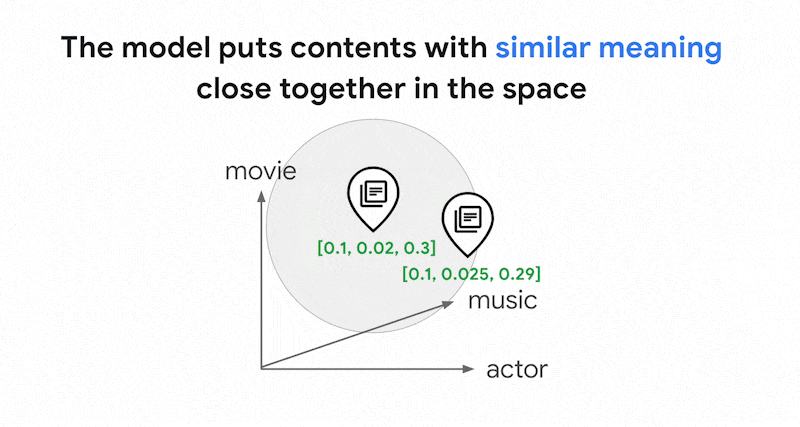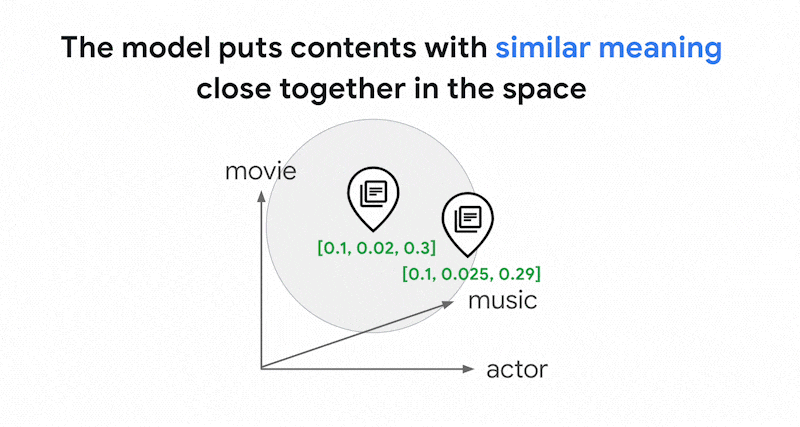
Embeddings membangun ruang vektor sebagai
peta makna konten. Setiap embedding multimodal atau teks adalah lokasi dalam peta yang merepresentasikan makna beberapa konten. Sebagai contoh sederhana, saat model embedding mengambil teks yang membahas film sebesar 10%, musik sebesar 2%, dan aktor sebesar 30%, model tersebut dapat merepresentasikan teks ini dengan embedding [0.1, 0.02,
0.3]. Dengan Vector Search, Anda dapat dengan cepat menemukan embedding lain di sekitarnya. Penelusuran berdasarkan makna konten ini disebut penelusuran semantik.
Penelusuran semantik dengan embedding dan penelusuran vektor dapat membantu membuat sistem IT menjadi secerdas pustakawan atau staf toko yang berpengalaman. Embedding dapat digunakan untuk mengaitkan berbagai data bisnis dengan artinya; misalnya, kueri dan hasil penelusuran; teks dan gambar; aktivitas pengguna dan produk yang direkomendasikan; teks dalam bahasa Inggris dan teks dalam bahasa Jepang; atau data sensor dan kondisi pemberitahuan. Dengan kemampuan ini, ada berbagai kasus penggunaan untuk embedding.
Mengapa penelusuran semantik digabungkan dengan penelusuran berbasis kata kunci?
Penelusuran semantik tidak mencakup semua kemungkinan persyaratan untuk aplikasi pengambilan informasi, seperti Retrieval-Augmented Generation (RAG). Penelusuran semantik hanya dapat menemukan data yang dapat dipahami oleh model penyematan. Misalnya, kueri atau set data dengan nomor produk atau SKU arbitrer, nama produk baru yang baru ditambahkan, dan nama kode eksklusif perusahaan tidak berfungsi dengan penelusuran semantik karena tidak disertakan dalam set data pelatihan model embedding. Data ini disebut data "di luar domain".
Dalam kasus seperti itu, Anda perlu menggabungkan penelusuran semantik dengan penelusuran berbasis kata kunci (juga disebut berbasis token) untuk membentuk penelusuran campuran. Dengan penelusuran campuran, Anda dapat memanfaatkan penelusuran semantik dan berbasis token untuk mencapai kualitas penelusuran yang lebih tinggi.
Salah satu sistem penelusuran campuran yang paling populer adalah Google Penelusuran. Layanan ini menggabungkan penelusuran semantik pada tahun 2015 dengan model RankBrain, selain algoritma penelusuran kata kunci berbasis token. Dengan diperkenalkannya penelusuran campuran, Google Penelusuran dapat meningkatkan kualitas penelusuran secara signifikan dengan memenuhi dua persyaratan: penelusuran berdasarkan makna dan penelusuran berdasarkan kata kunci.
Sebelumnya, membuat mesin telusur campuran adalah tugas yang rumit. Sama seperti Google Penelusuran, Anda harus membangun dan mengoperasikan dua jenis mesin telusur yang berbeda (penelusuran semantik dan penelusuran berbasis token) serta menggabungkan dan memberi peringkat hasil dari keduanya. Dengan dukungan penelusuran hybrid di Vector Search, Anda dapat membangun sistem penelusuran hybrid sendiri dengan satu indeks Vector Search, yang disesuaikan dengan persyaratan bisnis Anda.
Cara kerja penelusuran berbasis token
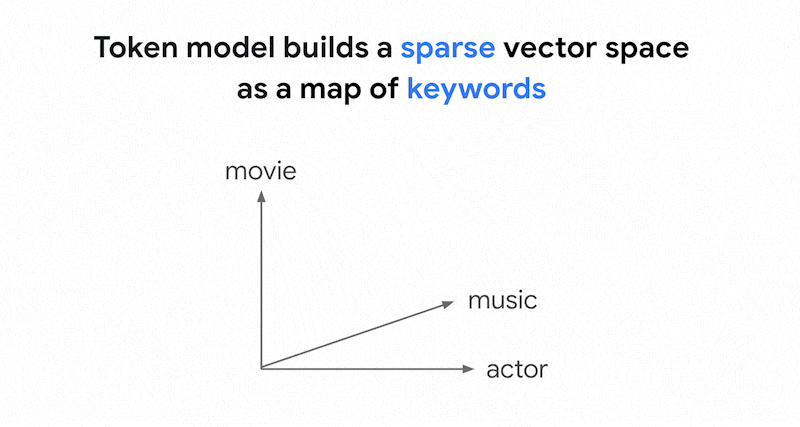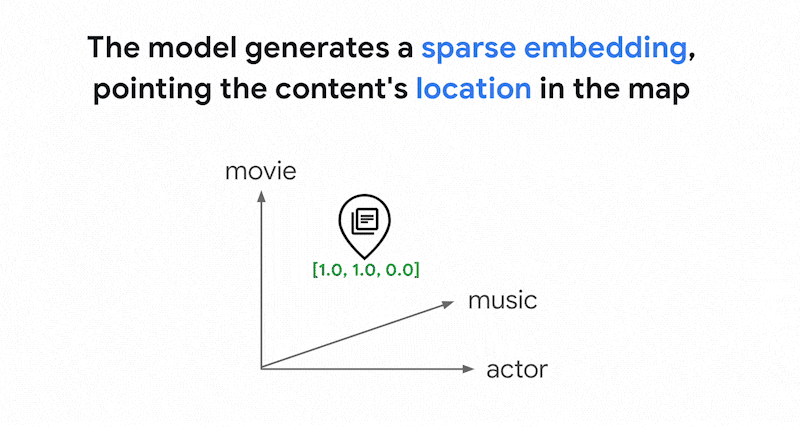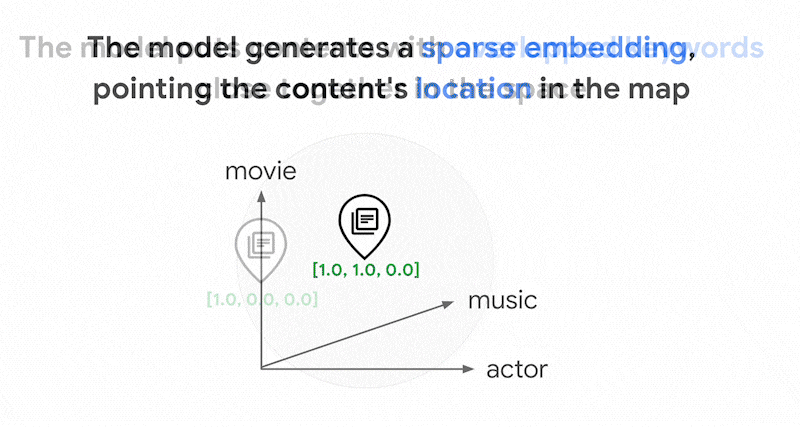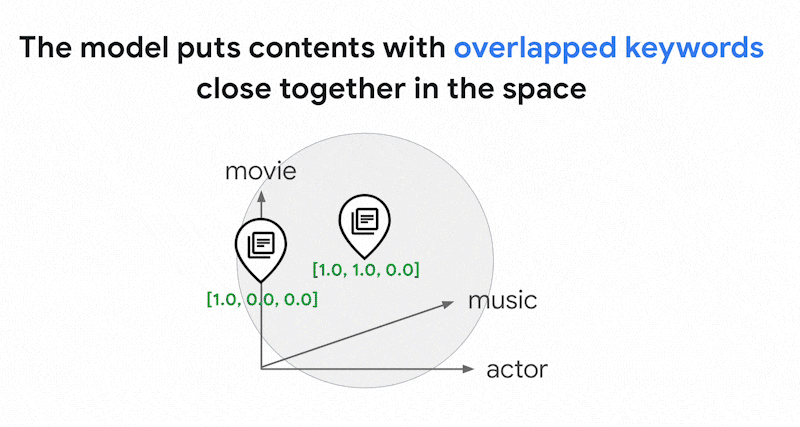
Bagaimana cara kerja penelusuran berbasis token di Penelusuran Vektor? Setelah memisahkan teks menjadi token (seperti kata atau sub-kata), Anda dapat menggunakan algoritma penyematan jarang yang populer seperti TF-IDF, BM25, atau SPLADE untuk menghasilkan penyematan jarang untuk teks.
Penjelasan sederhana tentang embedding jarang adalah bahwa embedding tersebut merupakan vektor yang merepresentasikan berapa kali setiap kata atau sub-kata muncul dalam teks. Embedding jarang yang umum tidak memperhitungkan semantik teks.

Ada ribuan kata berbeda yang dapat digunakan dalam teks. Oleh karena itu, embedding ini biasanya memiliki puluhan ribu dimensi, dengan hanya beberapa dimensi di dalamnya yang memiliki nilai bukan nol. Itulah sebabnya embedding ini disebut embedding "renggang". Sebagian besar nilainya adalah nol. Ruang penyematan jarang ini berfungsi sebagai peta kata kunci, mirip dengan indeks buku.
Dalam ruang embedding renggang ini, Anda dapat menemukan embedding serupa dengan melihat lingkungan embedding kueri. Embedding ini serupa dalam hal distribusi kata kunci yang digunakan dalam teksnya.
Ini adalah mekanisme dasar penelusuran berbasis token dengan embedding renggang. Dengan penelusuran campuran di Vector Search, Anda dapat menggabungkan embedding padat dan renggang ke dalam satu indeks vektor dan menjalankan kueri dengan embedding padat, embedding renggang, atau keduanya. Hasilnya adalah kombinasi hasil penelusuran semantik dan penelusuran berbasis token.
Penelusuran campuran juga memberikan latensi kueri yang lebih rendah dibandingkan dengan mesin telusur berbasis token dengan desain indeks terbalik. Sama seperti penelusuran vektor untuk penelusuran semantik, setiap kueri dengan embedding padat atau jarang selesai dalam beberapa milidetik, bahkan dengan jutaan atau miliaran item.
Contoh: Cara menggunakan penelusuran berbasis token
Untuk menjelaskan cara menggunakan penelusuran berbasis token, bagian berikut menyertakan contoh kode yang menghasilkan embedding renggang dan membuat indeks dengannya di Vector Search.
Untuk mencoba kode contoh ini, gunakan notebook: Combining Semantic & Keyword Search: A Hybrid Search Tutorial with Vertex AI Vector Search.
Langkah pertama adalah menyiapkan file data untuk membuat indeks untuk sematan jarang, berdasarkan format data yang dijelaskan dalam Format dan struktur data input.
Dalam JSON, file data akan terlihat seperti ini:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
Setiap item harus memiliki properti sparse_embedding yang memiliki properti values dan
dimensions. Embedding renggang memiliki ribuan dimensi dengan beberapa nilai bukan nol. Format data ini berfungsi secara efisien karena hanya berisi nilai bukan nol dengan posisinya dalam ruang.
Menyiapkan contoh set data
Sebagai contoh set data, kita akan menggunakan set data Google Merch Shop, yang memiliki sekitar 200 baris barang bermerek Google.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
Menyiapkan vectorizer TF-IDF
Dengan set data ini, kita akan melatih vectorizer, yaitu model yang menghasilkan embedding renggang dari teks. Contoh ini menggunakan TfidfVectorizer di scikit-learn, yang merupakan vectorizer dasar yang menggunakan algoritma TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
Variabel corpus menyimpan daftar 200 nama item, seperti "Stiker Google" atau "Pin Dinosaurus Chrome". Kemudian, kode meneruskannya ke vektorisasi dengan
memanggil fungsi fit_transform(). Dengan demikian, vectorizer siap
membuat embedding renggang.
Vectorizer TF-IDF mencoba memberikan bobot yang lebih tinggi pada kata-kata khas dalam set data (seperti "Kemeja" atau "Dino") dibandingkan dengan kata-kata sepele (seperti "The", "a", atau "of"), dan menghitung berapa kali kata-kata khas tersebut digunakan dalam dokumen yang ditentukan. Setiap nilai sematan jarang mewakili frekuensi setiap kata berdasarkan jumlahnya. Untuk mengetahui informasi selengkapnya tentang TF-IDF, lihat Bagaimana cara kerja TF-IDF dan TfidfVectorizer?.
Dalam contoh ini, kita menggunakan tokenisasi tingkat kata dasar dan vektorisasi TF-IDF agar lebih sederhana. Dalam pengembangan produksi, Anda dapat memilih opsi lain untuk tokenisasi dan vektorisasi guna menghasilkan sematan jarang berdasarkan kebutuhan Anda. Untuk tokenizer, dalam banyak kasus, tokenizer subkata berperforma baik dibandingkan dengan tokenisasi tingkat kata dan merupakan pilihan populer. Untuk vectorizer, BM25 populer sebagai versi TF-IDF yang lebih baik. SPLADE adalah algoritma vektorisasi populer lainnya yang menggunakan beberapa semantik untuk embedding renggang.
Mendapatkan embedding renggang
Untuk mempermudah penggunaan vectorizer dengan Penelusuran Vektor, kita akan menentukan
fungsi wrapper, get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
Fungsi ini meneruskan parameter "text" ke vectorizer untuk menghasilkan sematan jarang. Kemudian, konversikan ke format {"values": ...., "dimensions": ...}
yang disebutkan sebelumnya untuk membuat indeks jarang Vector Search.
Anda dapat menguji fungsi ini:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
Tindakan ini akan menghasilkan embedding jarang berikut:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
Membuat file data input
Untuk contoh ini, kita akan membuat embedding renggang untuk semua 200 item.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
Kode ini menghasilkan baris berikut untuk setiap item:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
Kemudian, simpan sebagai file JSONL "items.json" dan upload ke bucket Cloud Storage.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gcloud storage cp items.json $BUCKET_URI
Membuat indeks embedding renggang di Vector Search
Selanjutnya, kita akan membuat dan men-deploy indeks embedding renggang di Penelusuran Vektor. Prosedur ini sama dengan yang didokumentasikan dalam mulai cepat Vector Search.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
Untuk menggunakan indeks, Anda perlu membuat endpoint indeks. Instance ini berfungsi sebagai server yang menerima permintaan kueri untuk indeks Anda.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
Dengan endpoint indeks, deploy indeks dengan menentukan ID indeks yang di-deploy secara unik.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
Setelah menunggu deployment, kita siap menjalankan kueri pengujian.
Menjalankan kueri dengan indeks sematan jarang
Untuk menjalankan kueri dengan indeks embedding renggang, Anda perlu membuat objek HybridQuery
untuk mengenkapsulasi embedding renggang dari teks kueri, seperti dalam
contoh berikut:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
Contoh kode ini menggunakan teks "Kids" untuk kueri. Sekarang, jalankan kueri dengan objek
HybridQuery.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
Ini akan memberikan output seperti berikut:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
Dari 200 item, hasilnya berisi nama item yang memiliki kata kunci "Anak-Anak".
Contoh: Cara menggunakan penelusuran campuran
Contoh ini menggabungkan penelusuran berbasis token dengan penelusuran semantik untuk membuat penelusuran campuran di Vector Search.
Cara membuat indeks campuran
Untuk membuat indeks campuran, setiap item harus memiliki "embedding" (untuk embedding padat) dan "sparse_embedding":
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
Fungsi get_dense_embedding() menggunakan Vertex AI Embedding
API untuk membuat embedding teks
dengan 768 dimensi. Tindakan ini akan menghasilkan embedding padat dan jarang dalam format berikut:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
Proses lainnya sama seperti pada Contoh: Cara menggunakan penelusuran berbasis token: upload file JSONL ke bucket Cloud Storage, buat indeks Vector Search dengan file tersebut, dan deploy indeks ke endpoint indeks.
Menjalankan kueri campuran
Setelah men-deploy indeks campuran, Anda dapat menjalankan kueri campuran:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
Untuk teks kueri "Kids", buat embedding padat dan renggang untuk kata tersebut, lalu gabungkan ke objek HybridQuery. Perbedaannya dari
HybridQuery sebelumnya adalah dua parameter tambahan: dense_embedding dan
rrf_ranking_alpha.
Kali ini, kita akan mencetak jarak untuk setiap item:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
Di setiap objek neighbor, ada properti distance yang memiliki jarak
antara kueri dan item dengan sematan padat, serta properti sparse_distance
yang memiliki jarak dengan sematan jarang. Nilai ini adalah
jarak terbalik, sehingga nilai yang lebih tinggi berarti jarak yang lebih pendek.
Dengan menjalankan kueri dengan HybridQuery, Anda akan mendapatkan hasil berikut:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
Selain hasil penelusuran berbasis token yang memiliki kata kunci "Kids", ada juga hasil penelusuran semantik yang disertakan. Misalnya, "Google White Classic Youth Tee" disertakan karena model penyematan tahu bahwa "Youth" dan "Kids" serupa secara semantik.
Untuk menggabungkan hasil penelusuran semantik dan berbasis token, penelusuran campuran menggunakan
Reciprocal Rank Fusion
(RRF). Untuk mengetahui informasi selengkapnya tentang RRF dan cara
menentukan parameter rrf_ranking_alpha, lihat Apa yang dimaksud dengan Penggabungan Peringkat Timbal Balik?.
Pengurutan ulang
RRF menyediakan cara untuk menggabungkan peringkat dari hasil penelusuran semantik dan berbasis token. Dalam banyak sistem pengambilan informasi atau sistem rekomendasi produksi, hasil akan melalui algoritma peringkat presisi lebih lanjut — yang disebut peringkat ulang. Dengan kombinasi pengambilan cepat tingkat milidetik dengan Vector Search dan penentuan peringkat ulang yang presisi pada hasilnya, Anda dapat membangun sistem multi-tahap yang memberikan kualitas penelusuran atau performa rekomendasi yang lebih tinggi.
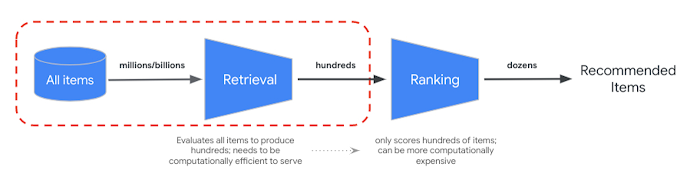
Vertex AI Ranking API menyediakan cara untuk menerapkan peringkat berdasarkan relevansi umum antara teks kueri dan teks hasil penelusuran dengan model terlatih. TensorFlow Ranking juga memberikan pengantar tentang cara mendesain dan melatih model learning to rank (LTR) untuk penyesuaian peringkat lanjutan yang dapat disesuaikan untuk berbagai persyaratan bisnis.
Mulai menggunakan penelusuran hybrid
Referensi berikut dapat membantu Anda mulai menggunakan penelusuran campuran di Vector Search.
Referensi penelusuran campuran
- Menggabungkan Penelusuran Semantik & Kata Kunci: Tutorial Penelusuran Campuran dengan Vertex AI Vector Search: Contoh notebook untuk mulai menggunakan penelusuran campuran
- Format dan struktur data input: Format data input untuk membuat indeks embedding renggang
- Membuat kueri indeks publik untuk mendapatkan tetangga terdekat: Cara menjalankan kueri dengan penelusuran campuran
- Reciprocal Rank Fusion mengungguli Metode Pembelajaran Peringkat individu dan Condorcet: Pembahasan algoritma RRF
Referensi Vector Search
Konsep tambahan
Bagian berikut menjelaskan TF-IDF dan TfidVectorizer, Reciprocal Rank Fusion, dan parameter alfa secara lebih mendetail.
Bagaimana cara kerja TF-IDF dan TfidfVectorizer?
Fungsi fit_transform() menjalankan dua proses penting algoritma TF-IDF:
Fit: Vectorizer menghitung Inverse Document Frequency (IDF) untuk setiap istilah dalam kosakata. IDF mencerminkan seberapa penting suatu istilah di seluruh korpus. Istilah langka mendapatkan skor IDF yang lebih tinggi:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)Transformasi:
- Tokenisasi: Memecah dokumen menjadi istilah individual (kata atau frasa)
Penghitungan Term Frequency (TF): Menghitung seberapa sering setiap istilah muncul dalam setiap dokumen dengan:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)Penghitungan TF-IDF: Menggabungkan TF untuk setiap istilah dengan IDF yang telah dihitung sebelumnya untuk membuat skor TF-IDF. Skor ini menunjukkan pentingnya suatu istilah dalam dokumen tertentu dibandingkan dengan seluruh korpus.
TF-IDF(t, d) = TF(t, d) * IDF(t)Vectorizer TF-IDF mencoba memberikan bobot yang lebih tinggi pada kata-kata khas dalam set data, seperti "Kemeja" atau "Dino", dibandingkan dengan kata-kata sepele, seperti "The", "a", atau "of", dan menghitung berapa kali kata-kata khas tersebut digunakan dalam dokumen yang ditentukan. Setiap nilai sematan jarang merepresentasikan frekuensi setiap kata berdasarkan jumlahnya.
Apa itu Reciprocal Rank Fusion?
Untuk menggabungkan hasil penelusuran berbasis token dan semantik, penelusuran campuran menggunakan Reciprocal Rank Fusion (RRF). RRF adalah algoritma untuk menggabungkan beberapa daftar item yang diberi peringkat menjadi satu peringkat terpadu. Teknik ini populer untuk menggabungkan hasil penelusuran dari berbagai sumber atau metode pengambilan, terutama dalam sistem penelusuran campuran dan model bahasa besar.
Dalam kasus penelusuran hibrida Penelusuran Vektor, jarak padat dan jarak renggang diukur dalam ruang yang berbeda dan tidak dapat dibandingkan secara langsung satu sama lain. Dengan demikian, RRF berfungsi secara efektif untuk menggabungkan dan memberi peringkat hasil dari dua ruang yang berbeda.
Berikut cara kerja RRF:
- Peringkat timbal balik: Untuk setiap item dalam daftar peringkat, hitung peringkat timbal baliknya. Artinya, mengambil kebalikan dari posisi (peringkat) item dalam daftar. Misalnya, item yang diberi peringkat nomor satu mendapatkan peringkat timbal balik 1/1 = 1, dan item yang diberi peringkat nomor dua mendapatkan 1/2 = 0,5.
- Jumlah peringkat kebalikan: Menjumlahkan peringkat kebalikan untuk setiap item di semua daftar peringkat. Hal ini memberikan skor akhir untuk setiap item.
- Urutkan menurut skor akhir: Urutkan item menurut skor akhir dalam urutan menurun. Item dengan skor tertinggi dianggap paling relevan atau penting.
Singkatnya, item dengan peringkat lebih tinggi dalam hasil padat dan renggang akan ditarik ke bagian atas daftar. Oleh karena itu, item "Google Blue Kids Sunglasses" berada di bagian atas karena memiliki peringkat yang lebih tinggi dalam hasil penelusuran padat dan jarang. Item seperti "Google White Classic Youth Tee" memiliki peringkat rendah karena hanya memiliki peringkat di hasil penelusuran yang padat.
Perilaku parameter alfa
Contoh cara menggunakan penelusuran campuran menetapkan parameter rrf_ranking_alpha
sebagai 0,5 saat membuat objek HybridQuery. Anda dapat menentukan bobot pada
peringkat hasil penelusuran padat dan jarang menggunakan nilai berikut untuk
rrf_ranking_alpha:
1, atau tidak ditentukan: Penelusuran hybrid hanya menggunakan hasil penelusuran padat dan mengabaikan hasil penelusuran jarang.0: Penelusuran campuran hanya menggunakan hasil penelusuran jarang dan mengabaikan hasil penelusuran padat.0hingga1: Penelusuran hybrid menggabungkan hasil dari padat dan jarang dengan bobot yang ditentukan oleh nilai. 0,5 berarti keduanya akan digabungkan dengan bobot yang sama.