Apa itu Retrieval-Augmented Generation (RAG)?
RAG atau Retrieval-Augmented Generation adalah framework AI yang menggabungkan kemampuan sistem pengambilan informasi tradisional (seperti penelusuran dan database) dengan kemampuan model bahasa besar (LLM) generatif. Dengan menggabungkan data dan pengetahuan dunia Anda dengan keterampilan bahasa LLM, pembuatan berbasis data yang terpercaya akan membuat hasil yang lebih akurat, terbaru, dan relevan dengan kebutuhan spesifik Anda. Lihat eBook ini untuk mendapatkan “Enterprise Truth”.
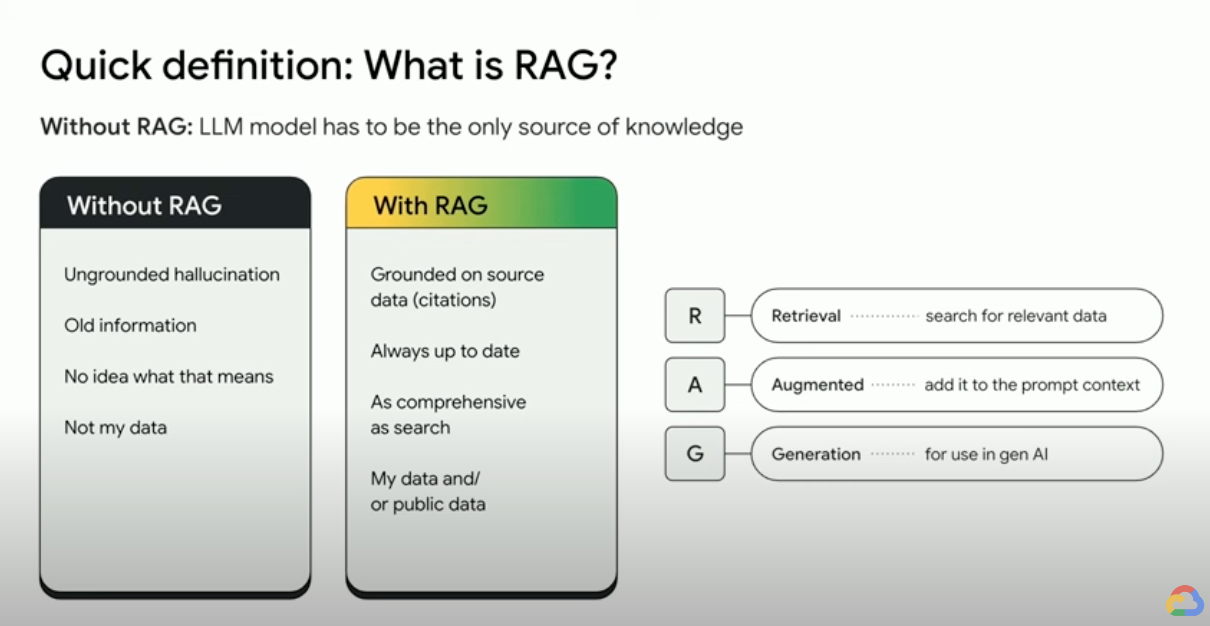
Bagaimana cara kerja Retrieval-Augmented Generation?
RAG beroperasi dengan beberapa langkah utama untuk membantu meningkatkan output AI generatif:
- Pengambilan dan pra-pemrosesan: RAG memanfaatkan algoritma penelusuran yang canggih untuk mengkueri data eksternal, seperti halaman web, pusat informasi, dan database. Setelah diambil, informasi yang relevan akan melalui pra-pemrosesan, termasuk tokenisasi, stemming, dan penghapusan kata yang diabaikan.
- Pembuatan berbasis rujukan: Informasi yang telah diproses sebelumnya dan diambil, kemudian akan diselaraskan ke dalam LLM yang telah dilatih sebelumnya. Integrasi ini meningkatkan konteks LLM, sehingga memberikan pemahaman topik yang lebih komprehensif. Konteks yang ditingkatkan ini memungkinkan LLM menghasilkan respons yang lebih akurat, informatif, dan menarik.
Mengapa menggunakan RAG?
RAG menawarkan beberapa keunggulan yang memperkuat metode tradisional dalam pembuatan teks, terutama ketika menangani informasi faktual atau respons berdasarkan data. Berikut adalah beberapa alasan utama yang menjelaskan manfaat penggunaan RAG:
Akses ke informasi baru
LLM dibatasi oleh data yang dilatih sebelumnya. Hal ini menyebabkan respons yang tidak terkini dan berpotensi tidak akurat. RAG mengatasi masalah ini dengan memberikan informasi terbaru ke LLM.
Penyelarasan faktual
LLM adalah alat yang efektif untuk menghasilkan teks yang kreatif dan menarik, tetapi terkadang bisa menyajikan informasi yang tidak akurat sebagai fakta. Hal ini karena LLM dilatih menggunakan data teks dalam jumlah besar, yang mungkin mengandung ketidakakuratan atau bias.
Memberikan “fakta” kepada LLM sebagai bagian dari perintah input dapat memitigasi “halusinasi AI generatif”. Inti dari pendekatan ini adalah memastikan bahwa LLM mendapatkan fakta yang paling relevan, dan bahwa output LLM sepenuhnya didasarkan pada fakta tersebut, sekaligus menjawab pertanyaan pengguna dan mematuhi petunjuk sistem serta batasan keamanan.
Menggunakan jendela konteks panjang (LCW) Gemini adalah cara yang bagus untuk menyediakan materi referensi ke LLM. Jika Anda perlu memberikan lebih banyak informasi daripada yang bisa dimuat dalam LCW, atau jika Anda perlu meningkatkan performa, Anda dapat menggunakan pendekatan RAG yang akan mengurangi jumlah token, sehingga menghemat waktu dan biaya.
Penelusuran dengan database vektor dan pemeringkat ulang relevansi
RAG biasanya mengambil fakta melalui penelusuran, dan mesin telusur modern kini memanfaatkan database vektor untuk mengambil dokumen relevan dengan efisien. Database vektor menyimpan dokumen sebagai embedding dalam ruang berdimensi tinggi, sehingga memungkinkan pengambilan yang cepat dan akurat berdasarkan kemiripan semantik. Embedding multimodal dapat digunakan untuk gambar, audio, video, dan lainnya. Embedding media ini dapat diambil bersama dengan embedding teks atau embedding multibahasa.
Mesin penelusuran lanjutan seperti Agent Search di Platform Agen Gemini Enterprise menggunakan penelusuran semantik dan penelusuran kata kunci secara bersamaan (disebut penelusuran hybrid), serta pemeringkat ulang yang memberikan skor pada hasil penelusuran untuk memastikan hasil teratas yang ditampilkan adalah yang paling relevan. Selain itu, penelusuran akan berjalan lebih baik dengan kueri yang jelas dan terfokus tanpa kesalahan ejaan. Jadi, sebelum melakukan penelusuran, mesin telusur canggih akan mengubah kueri dan memperbaiki kesalahan ejaan.
Relevansi, akurasi, dan kualitas
Mekanisme pengambilan dalam RAG adalah hal yang sangat penting. Anda memerlukan penelusuran semantik terbaik di atas pusat informasi pilihan untuk memastikan bahwa informasi yang diambil relevan dengan kueri atau konteks input. Jika informasi yang Anda ambil tidak relevan, hasil pembuatan Anda mungkin berbasis pada rujukan, tetapi tidak relevan dengan topik atau salah.
Dengan melakukan fine-tuning atau rekayasa perintah terhadap LLM untuk menghasilkan teks yang sepenuhnya didasarkan pada pengetahuan yang diambil, RAG membantu meminimalkan kontradiksi dan inkonsistensi dalam teks yang dihasilkan. Hal ini secara signifikan meningkatkan kualitas teks yang dihasilkan, dan meningkatkan pengalaman pengguna.
Evaluasi model di Platform Agen Gemini Enterprise kini memberikan skor pada teks yang dihasilkan LLM dan potongan data yang diambil berdasarkan metrik seperti “coherence”, “fluency”, “groundedness”, "safety", “instruction_following”, “question_answering_quality”, dan lainnya. Metrik ini membantu Anda mengukur teks berbasis rujukan yang Anda dapatkan dari LLM (untuk beberapa metrik yang merupakan perbandingan dengan jawaban kebenaran nyata yang telah Anda berikan). Dengan menerapkan evaluasi ini, Anda akan mendapatkan pengukuran dasar dan dapat mengoptimalkan kualitas RAG dengan mengonfigurasi mesin telusur, menyeleksi data sumber Anda, meningkatkan strategi penguraian atau pemotongan tata letak sumber, atau menyempurnakan pertanyaan pengguna sebelum melakukan penelusuran. RAG Ops, pendekatan berbasis metrik seperti ini akan membantu Anda mencapai RAG berkualitas tinggi dan mendapatkan hasil yang berbasis referensi.
RAG, agen, dan chatbot
RAG dan grounding dapat diintegrasikan ke dalam aplikasi atau agen LLM mana pun yang memerlukan akses ke data baru, pribadi, atau khusus. Pengetahuan eksternal dapat dimanfaatkan dengan mengakses informasi eksternal, chatbot dan agen percakapan yang didukung RAG untuk memberikan respons yang lebih komprehensif, informatif, dan kontekstual, sehingga meningkatkan pengalaman pengguna secara keseluruhan.
Data dan kasus penggunaan Anda adalah aspek yang membedakan hal yang Anda bangun dengan AI generatif. RAG dan grounding menghadirkan data Anda ke LLM secara efisien dan skalabel.
Produk dan layanan Google Cloud apa yang terkait dengan RAG?
Produk Google Cloud berikut terkait dengan Retrieval-Augmented Generation:
 Mesin RAG Platform Agen Gemini EnterpriseFramework data untuk mengembangkan aplikasi LLM dengan konteks yang diperkuat, dan memfasilitasi retrieval-augmented generation.
Mesin RAG Platform Agen Gemini EnterpriseFramework data untuk mengembangkan aplikasi LLM dengan konteks yang diperkuat, dan memfasilitasi retrieval-augmented generation.- Agent Search di Platform Agen Gemini EnterpriseAgent Search adalah Google Penelusuran untuk data Anda, builder RAG dan penelusuran siap pakai yang terkelola sepenuhnya.
 Penelusuran Vektor di Platform Agen Gemini EnterpriseIndeks vektor dengan performa yang sangat tinggi yang mendukung Agent Search. Indeks ini memungkinkan penelusuran dan pengambilan semantik dan hybrid dari koleksi embedding yang sangat besar dengan perolehan kembali yang tinggi pada tingkat kueri yang tinggi.
Penelusuran Vektor di Platform Agen Gemini EnterpriseIndeks vektor dengan performa yang sangat tinggi yang mendukung Agent Search. Indeks ini memungkinkan penelusuran dan pengambilan semantik dan hybrid dari koleksi embedding yang sangat besar dengan perolehan kembali yang tinggi pada tingkat kueri yang tinggi. BigQuerySet data besar yang dapat Anda gunakan untuk melatih model machine learning, termasuk model untuk Penelusuran Vektor di Platform Agen.
BigQuerySet data besar yang dapat Anda gunakan untuk melatih model machine learning, termasuk model untuk Penelusuran Vektor di Platform Agen.- Grounded Generation APIMode fidelitas tinggi Gemini yang berbasis rujukan pada Google Penelusuran atau fakta langsung, atau menggunakan mesin telusur Anda sendiri.
 AlloyDB AIJalankan model di Platform Agen dan akses model tersebut di aplikasi Anda menggunakan kueri SQL yang sudah dikenal. Gunakan model Google, seperti Gemini, atau model kustom Anda sendiri.
AlloyDB AIJalankan model di Platform Agen dan akses model tersebut di aplikasi Anda menggunakan kueri SQL yang sudah dikenal. Gunakan model Google, seperti Gemini, atau model kustom Anda sendiri.
Bacaan lebih lanjut
Pelajari lebih lanjut tentang penggunaan retrieval-augmented generation dengan referensi ini.
- RAG yang didukung oleh teknologi Google Penelusuran
- RAG dengan database di Google Cloud
- API untuk membangun sistem penelusuran dan Retrieval Augmented Generation (RAG) Anda sendiri
- Cara menggunakan RAG di BigQuery untuk memperkuat LLM
- Contoh kode dan panduan memulai untuk memahami RAG
- Infrastruktur untuk aplikasi AI generatif berkemampuan RAG menggunakan GKE
Langkah selanjutnya
Mulailah membangun solusi di Google Cloud dengan kredit gratis senilai $300 dan lebih dari 20 produk yang selalu gratis.
Perlu bantuan untuk memulai?
Hubungi bagian penjualanBekerja sama dengan partner tepercaya
Temukan partnerLanjutkan menjelajah
Lihat semua produk


















