Cette page explique comment diffuser des prédictions à partir de votre modèle de classification d'images et les afficher dans une application Web.
Ce tutoriel comporte plusieurs pages :Effectuer des prédictions à partir d'un modèle de classification d'images personnalisé
Chaque page suppose que vous avez déjà effectué les instructions des pages précédentes du tutoriel.
Dans la suite de ce document, nous partons du principe que vous utilisez le même environnement Cloud Shell que vous avez créé lors de la première page de ce tutoriel. Si votre session Cloud Shell d'origine n'est plus ouverte, vous pouvez revenir à l'environnement en procédant comme suit :-
In the Google Cloud console, activate Cloud Shell.
-
Dans la session Cloud Shell, exécutez la commande suivante :
cd hello-custom-sample
Créer un point de terminaison
Pour obtenir des prédictions en ligne à partir du modèle de ML que vous avez entraîné en suivant la page précédente de ce tutoriel, créez un point de terminaison Vertex AI. Les points de terminaison diffusent les prédictions en ligne à partir d'un ou de plusieurs modèles.
Accédez à la page Modèles de Google Cloud Console, dans la section Vertex AI.
Recherchez la ligne du modèle que vous avez entraîné à l'étape précédente de ce tutoriel (
hello_custom), puis cliquez sur le nom du modèle pour ouvrir la page contenant ses informations.Dans l'onglet Déployer et tester, cliquez sur Déployer sur le point de terminaison pour ouvrir le volet Déployer sur le point de terminaison.
À l'étape Définir votre point de terminaison, ajoutez des informations de base concernant votre point de terminaison:
Sélectionnez Créer un point de terminaison.
Dans le champ Nom du point de terminaison, saisissez
hello_custom.Dans la section Paramètres du modèle, vérifiez que le nom du modèle s'affiche, également appelé
hello_custom. Spécifiez les paramètres du modèle suivants:Dans le champ Répartition du trafic, saisissez
100. Vertex AI permet la répartition du trafic pour un point de terminaison vers plusieurs modèles, mais ce tutoriel n'utilise pas cette fonctionnalité.Dans le champ Nombre minimal de nœuds de calcul, saisissez
1.Dans la liste déroulante Type de machine, sélectionnez n1-standard-2 dans la section Standard.
Cliquez sur OK.
Dans la section Journalisation, assurez-vous que les deux types de journalisation de prédiction sont activés.
Cliquez sur Continuer.
À l'étape Informations sur le point de terminaison, vérifiez que votre point de terminaison sera déployé dans
us-central1 (Iowa).Ne cochez pas la case Utiliser une clé de chiffrement gérée par le client (CMEK). Ce tutoriel n'utilise pas de clé de chiffrement CMEK.
Cliquez sur Déployer pour créer le point de terminaison et déployer votre modèle sur ce point de terminaison.
Après quelques minutes, apparaît à côté du nouveau point de terminaison dans la table Points de terminaison. Parallèlement, vous recevez également un e-mail indiquant que vous avez créé le point de terminaison et déployé votre modèle sur ce point de terminaison.
Déployer une fonction Cloud Run
Vous pouvez obtenir des prédictions à partir du point de terminaison Vertex AI que vous venez de créer en envoyant des requêtes à l'interface REST de l'API AI Vertex. Cependant, seuls les comptes principaux disposant de l'autorisation aiplatform.endpoints.predict peuvent envoyer des requêtes de prédiction en ligne. Vous ne pouvez pas rendre le point de terminaison public pour permettre à quiconque d'envoyer des requêtes, par exemple via une application Web.
Dans cette section, déployez le code sur les fonctions Cloud Run pour gérer les requêtes non authentifiées. L'exemple de code que vous avez téléchargé lors de la lecture de la première page de ce tutoriel contient du code pour cette fonction Cloud Run dans le répertoire function/. Vous pouvez éventuellement exécuter la commande suivante pour explorer le code de la fonction Cloud Run:
less function/main.py
Le déploiement de la fonction remplit les conditions suivantes:
Vous pouvez configurer une fonction Cloud Run pour recevoir des requêtes non authentifiées. En outre, les fonctions s'exécutent à l'aide d'un compte de service avec le rôle d'éditeur par défaut, qui inclut l'autorisation
aiplatform.endpoints.predictnécessaire pour obtenir des prédictions à partir de votre point de terminaison Vertex AI.Cette fonction effectue également un prétraitement utile des requêtes. Le point de terminaison Vertex AI attend des requêtes de prédiction au format de la première couche du graphe entraîné TensorFlow Keras: un Tensor de valeurs flottantes normalisées avec des dimensions fixes. La fonction utilise l'URL d'une image en entrée et prétraite l'image dans ce format avant de demander une prédiction à partir du point de terminaison Vertex AI.
Pour déployer la fonction Cloud Run, procédez comme suit :
Dans la console Google Cloud, dans la section Vertex AI, accédez à la page Points de terminaison.
Recherchez la ligne du point de terminaison que vous avez créé dans la section précédente, nommée
hello_custom. Sur cette ligne, cliquez sur Exemple de requête pour ouvrir le volet Exemple de requête.Dans le volet Sample request (Exemple de requête), recherchez la ligne de code de l'interface système correspondant au modèle suivant:
ENDPOINT_ID="ENDPOINT_ID"
ENDPOINT_ID est un nombre qui identifie ce point de terminaison spécifique.
Copiez cette ligne de code et exécutez-la dans votre session Cloud Shell pour définir la variable
ENDPOINT_ID.Exécutez la commande suivante dans votre session Cloud Shell pour déployer la fonction Cloud Run:
gcloud functions deploy classify_flower \ --region=us-central1 \ --source=function \ --runtime=python37 \ --memory=2048MB \ --trigger-http \ --allow-unauthenticated \ --set-env-vars=ENDPOINT_ID=${ENDPOINT_ID}
Déployer des requêtes de prédiction à l'aide d'une application Web
Enfin, hébergez une application Web statique sur Cloud Storage pour obtenir des prédictions à partir de votre modèle de ML entraîné. L'application Web envoie des requêtes à votre fonction Cloud Run, qui les prétraite et obtient les prédictions à partir du point de terminaison Vertex AI.
Le répertoire webapp de l'exemple de code que vous avez téléchargé contient un exemple d'application Web. Dans votre session Cloud Shell, exécutez les commandes suivantes pour préparer et déployer l'application Web:
Définissez quelques variables d'interface système pour les commandes dans les étapes suivantes:
PROJECT_ID=PROJECT_ID BUCKET_NAME=BUCKET_NAMERemplacez l'élément suivant :
- PROJECT_ID : ID de votre projet Google Cloud.
- BUCKET_NAME: nom du bucket Cloud Storage que vous avez créé en suivant la première page de ce tutoriel.
Modifiez l'application pour lui fournir l'URL du déclencheur de votre fonction Cloud Run:
echo "export const CLOUD_FUNCTION_URL = 'https://us-central1-${PROJECT_ID}.cloudfunctions.net/classify_flower';" \ > webapp/function-url.jsImportez le répertoire
webappdans votre bucket Cloud Storage:gcloud storage cp webapp gs://${BUCKET_NAME}/ --recursiveMettez les fichiers de l'application Web que vous venez d'importer en mode public:
gcloud storage objects update gs://${BUCKET_NAME}/webapp/** --add-acl-grant=entity=allUsers,role=READERVous pouvez maintenant accéder à l'URL suivante pour ouvrir l'application Web et obtenir des prédictions:
https://storage.googleapis.com/BUCKET_NAME/webapp/index.html
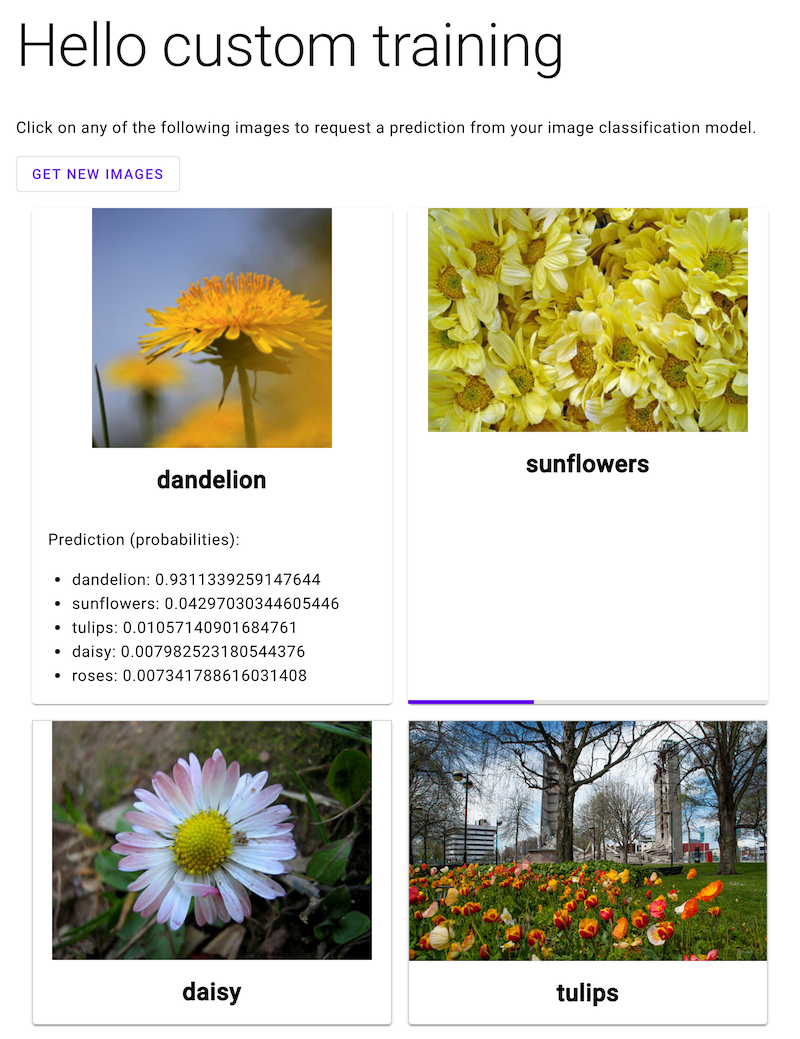
Ouvrez l'application Web, puis cliquez sur l'image d'une fleur pour afficher la classification de votre modèle de ML correspondant à ce type de fleur. L'application Web présente la prédiction sous forme d'une liste des types de fleurs et de la probabilité que l'image contienne chaque type de fleur.
Dans la capture d'écran suivante, l'application Web a déjà obtenu une prédiction et est en cours d'envoi d'une autre requête de prédiction.
Étape suivante
Suivez la dernière page du tutoriel pour nettoyer les ressources que vous avez créées.