このページでは、すでにチュートリアルを実施されている方を対象に、Neural Architecture Search のベスト プラクティスについて説明します。最初のセクションでは、Neural Architecture Search ジョブの完全なワークフローの概要を説明します。以降のセクションでは、各ステップについて詳しく説明します。最初の Neural Architecture Search ジョブを実行する前に、このページ全体を確認することを強くおすすめします。
推奨ワークフロー
ここでは、Neural Architecture Search の推奨ワークフローの概要を説明します。詳細については、対応するセクションへのリンクをご覧ください。
- ステージ 1 検索用にトレーニング データセットを分割します。
- 検索スペースが Google のガイドラインを遵守していることを確認します。
- ベースライン モデルで完全なトレーニングを実行し、検証曲線を取得します。
- プロキシタスク設計ツールを実行して、最適なプロキシタスクを見つけます。
- プロキシタスクの最終チェックを行います。
- トライアルの総数と並列トライアルの数を適切に設定してから、検索を開始します。
- 検索プロットをモニタリングし、収束した場合、大量のエラーが発生した場合、収束の兆候がない場合にプロットを停止します。
- 最終的な結果を得るために、検索から選択した上位 10 個のトライアルを使用して、フルトレーニングを実施します。フルトレーニングでは、可能な限り最高のパフォーマンスを得るために、追加の拡張または事前にトレーニング済みの重みを使用できます。
- 検索から保存された指標 / データを分析し、将来の検索スペースのイテレーションのための結論を導きます。
一般的な Neural Architecture Search
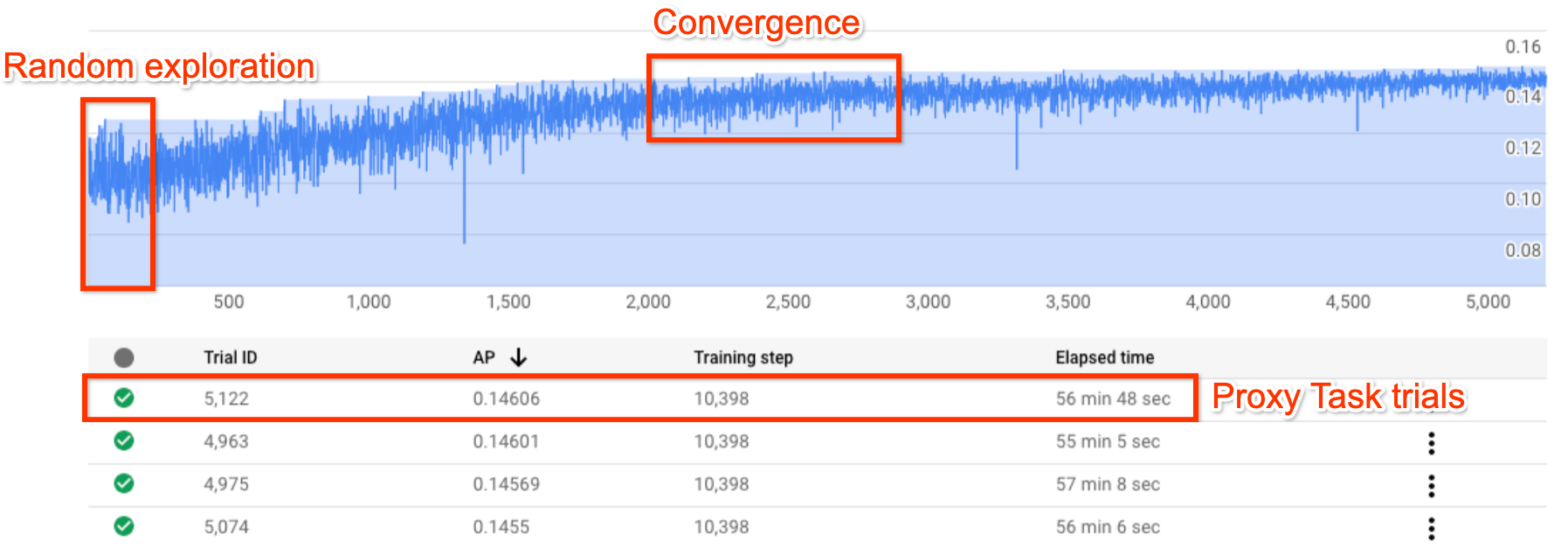
上の図は、Neural Architecture Search 曲線を示しています。この Y-axis はトライアルの報酬を示し、X-axis はこれまでに開始されたトライアルの数を示しています。最初の約 100~200 回のトライアルのほとんどは、コントローラによる検索スペースのランダムな探索です。初期の探索では、検索スペースにあるさまざまな種類のモデルが試行されているため、報酬に大きな差異が見られます。トライアル数を増やすと、コントローラはより優れたモデルの検出を開始します。したがって、まず報酬が増加し、その後、報酬の分散が始まり、報酬の増加が減少していきます。これは、収束を示しています。収束が起きるトライアル数は、検索スペースのサイズによって異なりますが、通常は約 2,000 回程度です。
Neural Architecture Search の 2 つのステージ: プロキシタスクとフルトレーニング
Neural Architecture Search は、次の 2 つのステージで動作します。
ステージ 1 検索では、フルトレーニングよりもはるかに小さい表現で行われます。これは通常、約 1~2 時間以内に終了します。これはプロキシタスクと呼ばれ、検索コストを低く抑えるのに役立ちます。
ステージ 2 フルトレーニングでは、ステージ 1 検索の上位 10 個のスコア付けモデルに対してフルトレーニングを行います。検索の確率論的性質により、ステージ 1 検索の最上位モデルは、ステージ 2 フルトレーニングで最上位モデルにならない場合があります。したがって、フルトレーニングにはモデルのプールを選択することが重要です。
コントローラは、完全なトレーニングではなく小さなプロキシタスクから報酬シグナルを受け取るため、タスクに最適なプロキシタスクを見つけることが重要です。
Neural Architecture Search の費用
Neural Architecture Search の費用は search-cost = num-trials-to-converge * avg-proxy-task-cost によって計算されます。proxy-task のコンピューティング時間がフルトレーニング時間の約 1/30 で、収束に必要なトライアル数が約 2, 000 と仮定すると、検索費用は最大で67 * full-training-cost になります。
Neural Architecture Search の費用は高額であるため、プロキシタスクの調整に時間をかけ、最初の検索に使用する検索スペースを小さくすることをおすすめします。
Neural Architecture Search の 2 つのステージに分割されたデータセット
ベースライン トレーニングのトレーニング データと検証用データがすでにある場合、NAS Neural Architecture Search の 2 つのステージに合わせて次のようにデータセットを分割することをおすすめします。
- ステージ 1 検索のトレーニング: トレーニング データの最大 90%
ステージ 1 検索の検証: トレーニング データの最大 10%
ステージ 2 フルトレーニングのトレーニング: トレーニング データの 100%
ステージ 2 フルトレーニングの検証: 検証用データの 100%
ステージ 2 フルトレーニングのデータ分割は、通常のトレーニングと同じです。ただし、ステージ 1 検索ではトレーニング データの分割を使用して検証を行います。ステージ 1 とステージ 2 で異なる検証用データを使用すると、データセットの分割に起因するモデル検索のバイアスを検出できます。トレーニング データをさらにパーティショニングしてからシャッフルし、最後の 10% のトレーニング データ分割の分布が元の検証用データと類似していることを確認します。
小規模または不均衡なデータ
トレーニング データが限られている場合や、一部のクラスが非常にまれなデータセットの場合、アーキテクチャ検索はおすすめしません。データ不足のため、ベースライン トレーニングですでに大量の拡張を行っている場合、モデル検索はおすすめしません。
この場合、最も適したなアーキテクチャを検索するのではなく、最適な拡張ポリシーを検索する場合のみに、拡張検索を使用します。
検索スペースのデザイン
アーキテクチャ検索を強化検索やハイパーパラメータ検索(学習率やオプティマイザーの設定など)と混在させないでください。アーキテクチャ検索の目的は、アーキテクチャ ベースの違いのみが存在する場合にモデル A とモデル B のパフォーマンスを比較することです。したがって、拡張とハイパーパラメータの設定は同じにしておく必要があります。
拡張検索は、アーキテクチャ検索の実行後、さらに別のステージとして実行できます。
Neural Architecture Search は、検索スペースのサイズを最大 10^20 まで増やすことができます。ただし、検索スペースが大きい場合は、検索スペースを相互排他的な部分に分割できます。たとえば、デコーダやヘッドとは別にエンコーダを検索できます。これらすべてに対して検索を行う場合は、以前に検出した最適な個別オプションに合わせて、より小さな検索スペースを作成できます。
(省略可)検索スペースを設計する際は、ブロック デザインからモデル スケーリングを使用できます。ブロック デザインの検索は、最初にスケールダウンしたモデルで行う必要があります。これにより、プロキシタスクのランタイムの費用を大幅に削減できます。その後、別途検索を行い、モデルをスケールアップします。詳細については、
Examples of scaled down modelsをご覧ください。
トレーニングと検索時間の最適化
Neural Architecture Search を実行する前に、ベースライン モデルのトレーニング時間を最適化することが重要です。これにより、長期的なコストを節約できます。トレーニングを最適化するには、次のような方法があります。
- データの読み込み速度を最大化します。
- データが存在するバケットがジョブと同じリージョンにあることを確認してください。
- TensorFlow を使用している場合は、
Best practice summaryをご覧ください。データに TFRecord 形式を使用することもできます。 - PyTorch を使用する場合は、ガイドラインに沿って、PyTorch を効率的にトレーニングします。
- 複数のアクセラレータや複数のマシンを利用する場合は、分散トレーニングを使用します。
- トレーニングを大幅に高速化し、メモリ使用量を減らすには、混合精度トレーニングを使用します。TensorFlow 混合精度トレーニングについては、
Mixed Precisionをご覧ください。 - 一般に、一部のアクセラレータ(A100 など)は費用対効果が高くなります。
- GPU 使用率が最大になるように、バッチサイズを調整します。次のプロットは、GPU の利用率が 50% 未満であることを示しています。
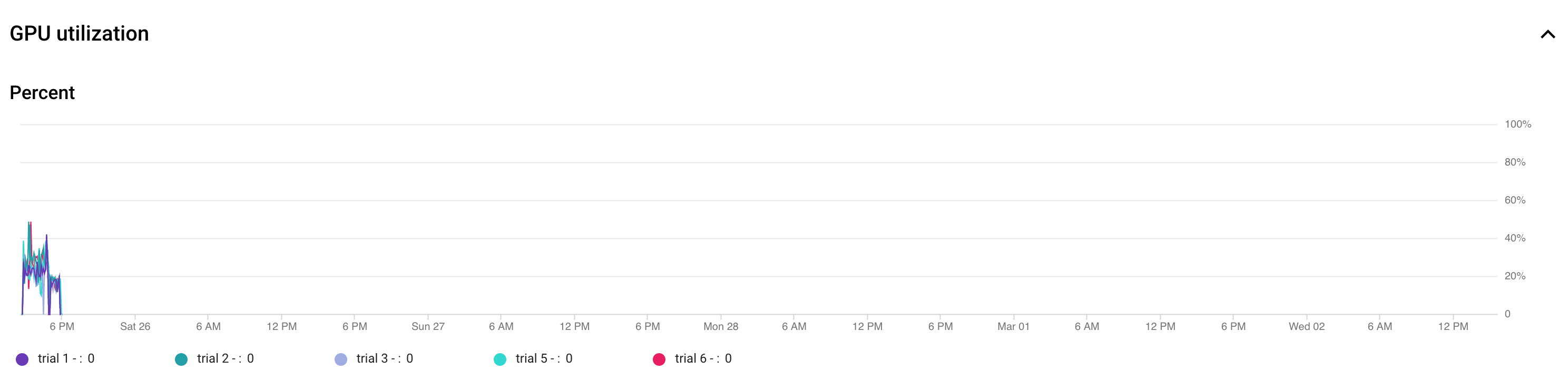 バッチサイズを増やすと GPU をさらに活用できます。ただし、検索時のメモリ不足エラーが増える可能性があるため、バッチサイズの増加は慎重に行ってください。
バッチサイズを増やすと GPU をさらに活用できます。ただし、検索時のメモリ不足エラーが増える可能性があるため、バッチサイズの増加は慎重に行ってください。 - 特定のアーキテクチャ ブロックが検索スペースから独立している場合は、ブロックの事前トレーニング済みチェックポイントを読み込み、トレーニングを迅速に行うことができます。事前トレーニング済みのチェックポイントは、検索スペース全体で同じにし、バイアスの発生を防ぐ必要があります。たとえば、デコーダ用の検索スペースしかない場合、エンコーダは事前トレーニング済みのチェックポイントを使用できます。
検索トライアルごとの GPU 数
トライアルあたりの GPU 数を減らして、起動時間を短縮します。たとえば、2 つの GPU を起動するには 5 分かかり、8 つの GPU では 20 分かかります。トライアルごとに 2 つの GPU を使用して、Neural Architecture Search ジョブのプロキシタスクを実行するのが効率的です。
検索トライアルの合計数と並列トライアル数
トライアルの合計数の設定
最適なプロキシタスクを検索して選択したら、完全な検索を実行できます。ただし、収束するまでのトライアル数を事前に把握することはできません。収束が発生するトライアルの数は、検索スペースのサイズによって異なりますが、通常は約 2,000 回程度です。
--max_nas_trial には非常に高い値(約 5,000~10,000)に設定し、検索プロットが収束を示したら検索ジョブを完了前にキャンセルすることをおすすめします。search_resume コマンドを使用して、以前の検索ジョブを再開することもできます。また、別の検索再開ジョブから検索を再開することはできません。そのため、元の検索ジョブは 1 回だけ再開できます。
並列トライアルの設定
ステージ 1 検索ジョブは、一度に --max_parallel_nas_trial 件のトライアルを並行して実行することで、バッチ処理を行います。これは、検索ジョブの全体的な実行時間を短縮するうえで重要です。検索の予想日数を計算できます(days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24))。注: 最初に 3000 を trials-to-converge の大まかな推定値として使用できます。この値は最初に指定するのに適した上限です。最初に avg-trial-duration-in-hours の概算値として 2 時間を使用できます。これは、各プロキシタスクの実行にかかる時間の適切な上限です。プロジェクトのアクセラレータ割り当ての量と days-required-for-search に応じて、--max_parallel_nas_trial を 20~50 に設定することをおすすめします。たとえば、--max_parallel_nas_trial を 20 に設定し、各プロキシタスクで 2 つの NVIDIA T4 GPU を使用する場合は、少なくとも 40 個の NVIDIA T4 GPU の割り当てを予約する必要があります。--max_parallel_nas_trial 設定は検索結果全体には影響しませんが、days-required-for-search には影響します。max_parallel_nas_trial に約 10 などの小さな値を設定することも可能です(20 GPU)が、大まかに days-required-for-search を推定し、ジョブのタイムアウト上限を超えないようにしてください。
ステージ 2 フルトレーニング ジョブは通常、デフォルトですべてのトライアルを並行してトレーニングします。通常、これは上位 10 件のトライアルが並行して実行されます。ただし、各ステージ 2 フルトレーニング トライアルでユースケースに複数の GPU(それぞれ 8 個の GPU)を使用し、十分な割り当てがない場合は、ステージ 2 のジョブを手動で一括実行できます。たとえば、最初に 5 回のトライアルで stage2-full-training を実行してから、次の 5 回のトライアルで別の stage2-full-training を実行することも可能です。
ジョブのデフォルトのタイムアウト
NAS ジョブのデフォルトのタイムアウトは 14 日に設定されており、14 日が経過するとジョブはキャンセルされます。より長い期間にわたってジョブの実行が予想される場合は、検索ジョブを 14 日間だけ再開できます。全体として、検索ジョブは再開を含めて 28 日間実行できます。
トライアルの最大失敗回数の設定
トライアルの最大失敗回数は、max_nas_trial 設定の約 1/3 に設定する必要があります。失敗したトライアルの数がこの上限に達すると、ジョブはキャンセルされます。
検索を停止するタイミング
次の場合は検索を停止する必要があります。
検索曲線が収束し始めます(分散が小さくなります)。
注: レイテンシの制約を使用しない場合、またはハード レイテンシの制約を緩めた場合、レイテンシの上限を超えると、報酬が増加せずに収束を示します。これは、検索の早い段階でコントローラが精度を正確に把握していた可能性があります。全トライアルの 20% 以上で無効な報酬(失敗)が発生しています。
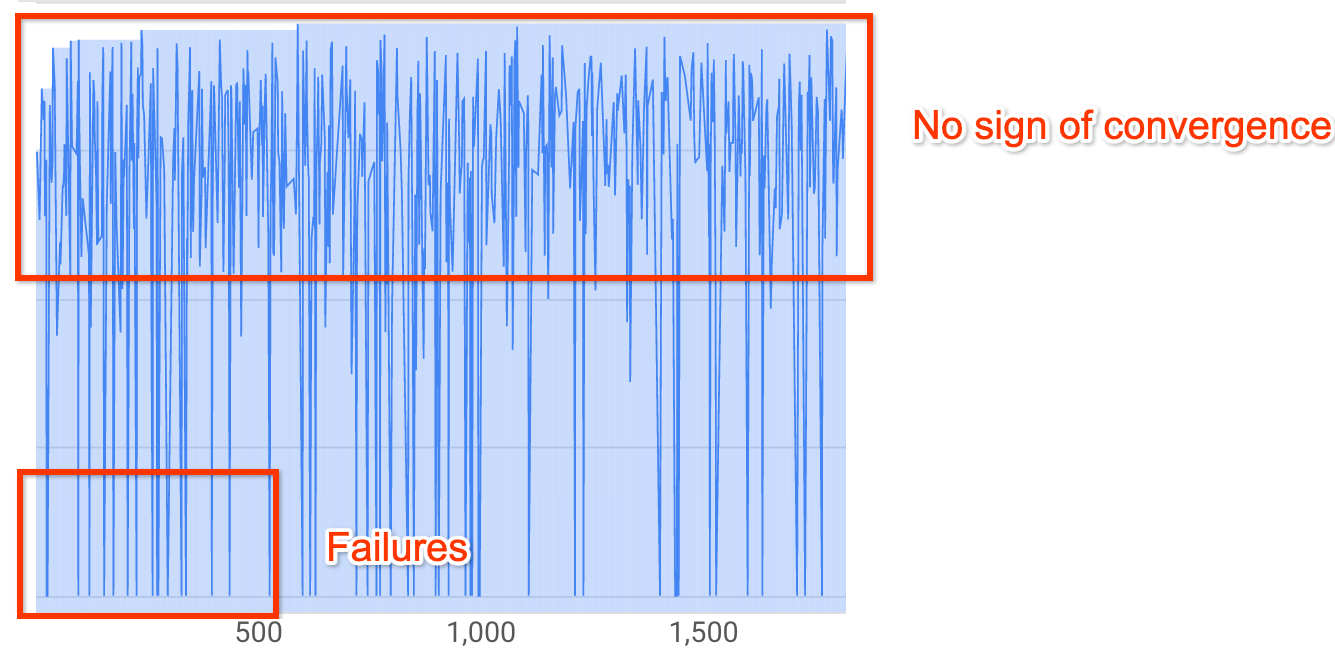
500 回のトライアルの後でも、前述のように検索曲線が上増加も収束もしません。報酬の増加または減少が見られる場合は、続行できます