Neural Architecture Search ジョブを実行して最適なモデルを検索する前に、プロキシタスクを定義します。ステージ 1 検索は、フル トレーニングよりもはるかに小さい表現で行われます。これは通常、約 1~2 時間以内に終了します。この表現はプロキシタスクと呼ばれ、検索コストを大幅に削減します。検索中に行われる各トライアルは、プロキシタスクの設定を使用してモデルをトレーニングします。
以下の各セクションでは、プロキシタスクの設計を適用する際に関連する内容について説明します。
- プロキシタスクの作成方法。
- 適切なプロキシタスクの要件。
- 3 つのプロキシタスク設計ツールを使用して、検索品質を維持しながら検索費用を削減できる最適なプロキシタスクを見つける方法。
プロキシタスクの作成方法
プロキシタスクを作成するには、以下の 3 つの一般的な方法があります。
- 使用するトレーニングのステップ数を削減する。
- サブサンプリングされたトレーニング データセットを使用する。
- スケールダウン モデルを使用する。
使用するトレーニングのステップ数を削減する
最も簡単にプロキシタスクを作成する方法は、トレーナーのトレーニング ステップ数を減らし、この部分的トレーニングに基づいてスコアをコントローラに報告することです。
サブサンプリングされたトレーニング データセットを使用する
このセクションでは、アーキテクチャ検索と拡張ポリシー検索の両方における、サブサンプリングされたトレーニング データセットの使用について説明します。
アーキテクチャの検索
プロキシタスクは、アーキテクチャ検索中にサブサンプリングされたトレーニング データセットを使用して作成できます。ただし、サブサンプリングは次のガイドラインに従います。
- シャード間でデータをランダムにシャッフルする。
- トレーニング データが不均衡である場合は、均衡を取るためにサブサンプリングする。
自動拡張を使用した拡張ポリシー検索
拡張のみの検索を実行しておらず、通常のアーキテクチャ検索のみを実行している場合は、このセクションをスキップしてください。自動拡張を使用して、拡張ポリシーを検索します。トレーニング ステップの数を減らすよりも、トレーニング データをサブサンプリングしてフル トレーニングを実行するのが理想的です。大幅に拡張してフル トレーニングを実行すると、スコアが安定します。また、削減したトレーニング データを使用して、検索費用を低く抑えてください。
スケールダウン モデルに基づくプロキシタスク
ベースライン モデルに対しモデルをスケールダウンして、プロキシタスクを作成することもできます。これは、ブロック デザイン検索をスケーリング検索から分離する場合にも有効です。
ただし、モデルをスケールダウンしてレイテンシの制約を使用する場合は、スケールダウンしたモデルに対してより厳格なレイテンシの制約を使用します。ヒント: ベースライン モデルをスケールダウンしてレイテンシを測定することで、より厳格なレイテンシの制約を設定できます。
スケールダウン モデルの場合は、元のベースライン モデルと比較して、拡張と正則化の量を減らすこともできます。
スケールダウンされたモデルの例
画像でトレーニングを行うコンピュータ ビジョン タスクでは、次の一般的な 3 つの方法でモデルをスケールダウンできます。
- モデルの幅を縮小する: チャネルの数。
- モデルの深度を低減する: レイヤ数とブロックの繰り返し回数。
- トレーニング画像のサイズを若干縮小する(特徴を排除しないようにする)か、タスクで許可されている場合はトレーニング画像を切り抜く。
推奨記事: EfficientNet の記事に、コンピュータ ビジョン タスクのモデル スケーリングに関する優れた分析情報が記載されています。また、3 つすべてのスケーリング方法が互いにどのように関係しているかについても説明があります。
Spinenet 検索は、Neural Architecture Search で使用されるモデル スケーリングのもう一つの例です。ステージ 1 検索では、チャネル数と画像サイズを縮小します。
組み合わせに基づくプロキシタスク
各アプローチは独立して機能しますが、異なる程度で組み合わせてプロキシタスクを作成することもできます。
適切なプロキシタスクの要件
プロキシタスクが、コントローラに安定した報酬を付与し、検索の品質を維持するためには、特定の要件を満たす必要があります。
ステージ 1 検索とステージ 2 フルトレーニングの間の順位相関
Neural Architecture Search にプロキシタスクを使用する場合、ステージ 1 のプロキシタスクのトレーニングでモデル A のパフォーマンスがモデル B より優れている場合に、ステージ 2 のフル トレーニングで、モデル A のパフォーマンスがモデル B よりも優れていることが、検索を成功させるための主な前提条件となります。この仮説を検証するには、検索スペース内の約 10~20 個のモデルに対して、ステージ 1 の検索とステージ 2 のフルトレーニングの報酬の間の順位相関を評価します。これらのモデルは、相関候補モデルと呼ばれます。
下の図は、相関性が低く(相関スコア = -0.03)、このプロキシタスクは検索の候補に適していない場合の例を示しています。

プロットの各点は、相関候補モデルを表しています。x 軸はモデルのステージ 2 フル トレーニングのスコアを表し、y 軸は同じモデルのステージ 1 プロキシタスクのスコアを表します。最高ポイントを確認します。このモデルは、プロキシタスクのスコア(y 軸)が最も高く、ステージ 2 のフルトレーニング(x 軸)では、他のモデルと比較してパフォーマンスが悪くなっています。対照的に、次の図は、このプロキシタスクが検索の候補として適している相関(相関スコア = 0.67)の例を示しています。

検索にレイテンシの制約がある場合は、レイテンシ値と良好な相関関係があるかも確認します。
相関候補モデルの報酬範囲が良好であり、妥当な範囲で報酬範囲がサンプリングされている必要があります。そうでない場合は、順位相関を評価できません。たとえば、相関候補モデルのステージ 1 の報酬がすべて 0.9 と 0.1 の 2 つの値の中間にある場合、サンプリングの分散は十分とは言えません。
分散チェック
プロキシタスクのもう一つの要件は、変更を加えずに同じモデルで複数回処理を繰り返す場合に、精度やレイテンシ スコアが大きく変化しないようにすることです。大きな変動が見られる場合は、ノイズの多い信号がコントローラに返されます。この分散を測定するためのツールが用意されています。
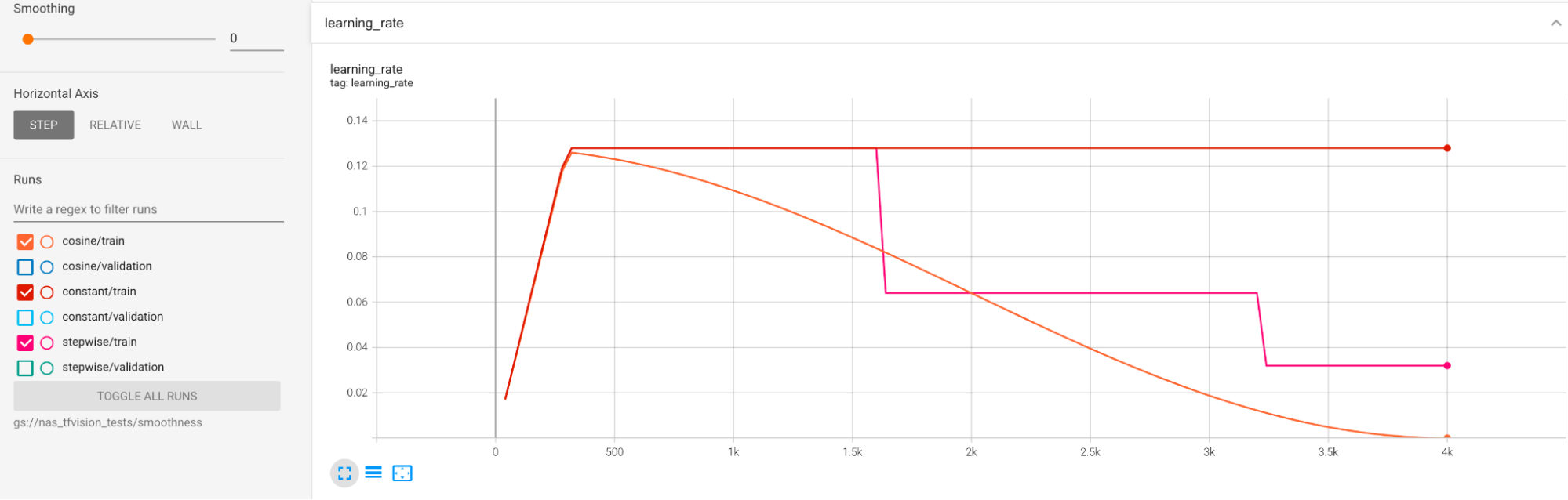
トレーニング中の大規模な分散を軽減するために例が用意されています。一つの方法として、cosine decay を学習率スケジュールとして使用することが挙げられます。次のプロットでは、3 つの学習率戦略を比較しています。

一番下のプロットは、一定の学習率に対応しています。トレーニングの最後にスコアが急増したときに、トレーニング ステップ数を減らすと、最後のプロキシタスクの報酬が大きく変わることがあります。プロキシタスクの報酬をより安定させるには、最上位のプロットの対応する検証スコアで示されるように、コサイン学習率の減衰を使用することをおすすめします。最上位のプロットがトレーニングの終わりに向かってより滑らかになることに注意してください。中央のプロットは、段階的な学習率の減衰に対応するスコアを示しています。一定の学習率の場合よりも優れていますが、それでもコサイン減衰ほど滑らかではなく、手動での調整も必要です。
以下に。学習率のスケジュールを示します。
追加の平滑化
大幅な増幅を行っている場合は、コサイン減衰により検証曲線が平滑にならない場合があります。増幅を大きくすると、トレーニング データが不足します。この場合は、Neural Architecture Search の使用はおすすめしません。代わりに拡張検索を使用することをおすすめします。
大幅な増幅が原因ではなく、すでにコサイン減衰を試しており、さらに平滑化を維持する必要がある場合は、指数移動平均(TensorFlow-2 の場合)または確率的加重平均(PyTorch の場合)を使用します。TensorFlow 2 で指数移動平均オプティマイザーを使用する例については、コードポインタをご覧ください。また、PyTorch の場合は、確率的加重平均の例をご覧ください。
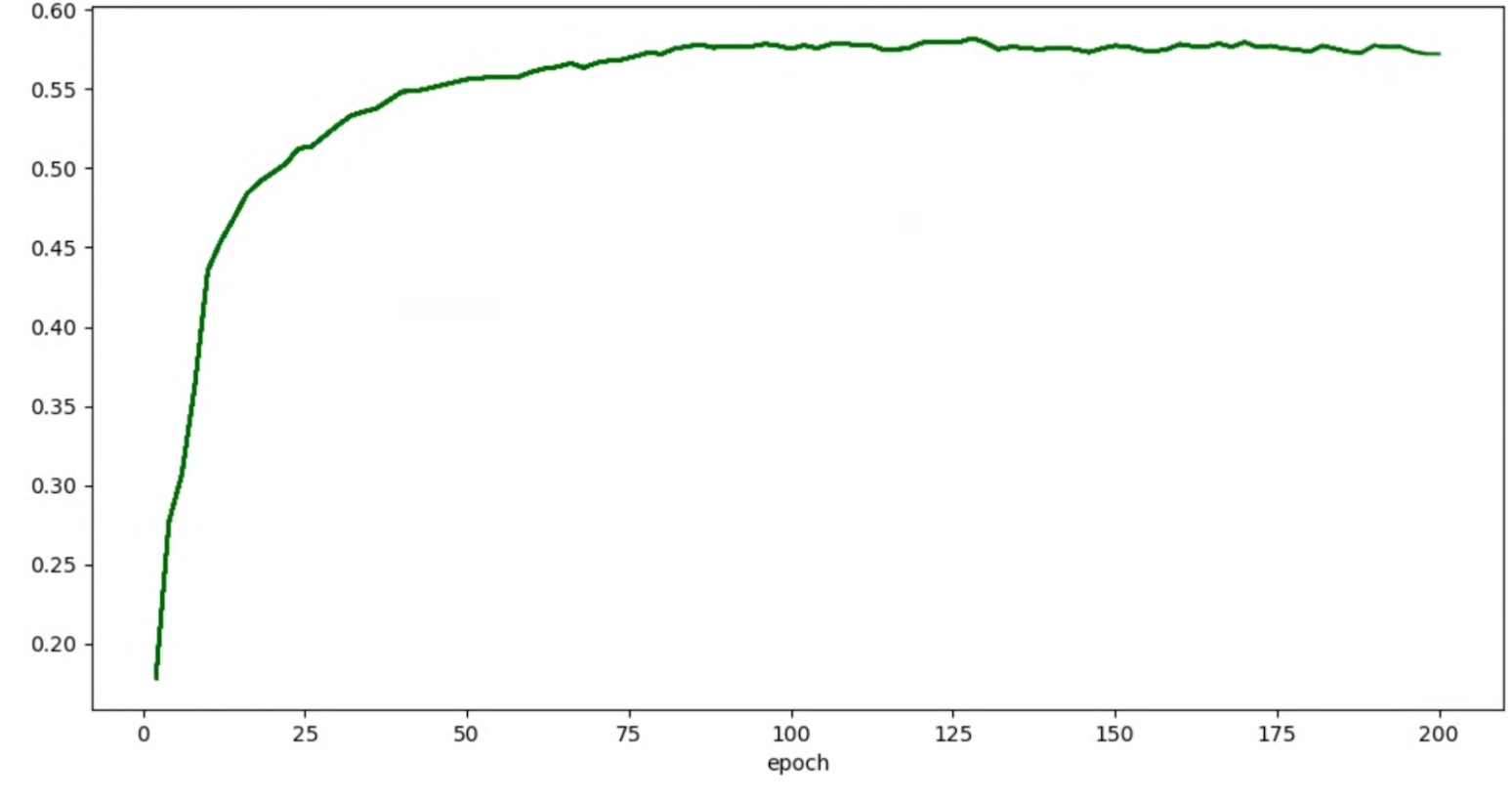
トライアルの精度 / エポックグラフが次のように表示される場合を考えてみましょう。

この場合、上記の平滑化技術(確率的加重平均、指数移動平均の使用など)を適用して、次のように、より一貫性のあるグラフを作成します。
メモリ不足(OOM)と学習率に関連するエラー
アーキテクチャ検索スペースでは、ベースラインよりもはるかに大きなモデルを生成できます。ベースライン モデルのバッチサイズが調整されている可能性がありますが、検索で大きなモデルがサンプリングされると、この設定は失敗し、OOM エラーが発生します。この場合は、バッチサイズを減らす必要があります。
他に表示されるエラーとして、NaN(番号ではない)エラーがあります。初期学習率を引き下げるか、勾配のクリップを追加する必要があります。
チュートリアル 2 で説明したように、検索スペースモデルの 20% 以上が無効なスコアを返している場合は、完全な検索を実行しないでください。Google のプロキシタスク設計ツールには、障害率を評価する方法が用意されています。
プロキシタスク設計ツール
前の各セクションでは、プロキシタスク設計の原則について説明しました。このセクションでは、さまざまな設計方法に基づいてすべての要件を満たす最適なプロキシタスクを自動的に見つけるための 3 つのプロキシタスク設計ツールについて説明します。
必要なコードの変更
まず、トレーナー コードを若干変更して、反復プロセス中にプロキシタスク設計ツールとやり取りできるようにする必要があります。tf_vision/train_lib.py に例を示します。まず、以下のとおりライブラリをインポートする必要があります。
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
トレーニング ループでトレーニング サイクルを開始する前に、プロキシタスク設計ツールでライブラリを使用する必要があるため、トレーニングを早期に停止する必要があるかどうかを確認します。
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
トレーニング ループ内の各トレーニング サイクルが完了したら、新しい精度スコア、トレーニング サイクルの開始と終了のステップ、トレーニング サイクル時間(秒単位)、合計トレーニング ステップを更新します。
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
トレーニング サイクル時間には、検証スコア評価の時間を含めないでください。検証曲線の十分なサンプリングを行えるように、トレーナーが検証スコアを頻繁に(評価頻度)計算するようにします。レイテンシの制約を使用している場合は、レイテンシを計算してからレイテンシ指標を更新します。
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
モデル選択ツールの場合は、連続するイテレーションのために前のチェックポイントを読み込む必要があります。以前のチェックポイントの再利用を有効にするには、tf_vision/cloud_search_main.py に示すとおり、トレーナーにフラグを追加します。
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
モデルをトレーニングする前に、このチェックポイントを読み込みます。
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
また、トレーナーから報告された精度とレイテンシの値に対応する metric-id も必要です。トレーナーの報酬(精度とレイテンシの組み合わせの場合もあります)が精度と異なる場合は、トレーナーの other_metrics を使用して精度のみの指標も報告してください。たとえば、次の例は、事前構築済みのトレーナーから報告された精度のみの指標とレイテンシ指標を示しています。
分散測定
トレーナー コードを変更したら、最初にトレーナーの分散を測定します。分散測定では、ベースライン トレーニング構成を次のように変更します。
- たとえば、1~2 個のみの GPU でトレーニング ステップを約 1 時間実行する場合は、トレーニング ステップ数を削減します。完全なトレーニングの小規模なサンプルが必要です。
- コサイン減衰の学習率を使用し、ステップをこれらの削減されたステップと同じに設定して、終了時点に近づくにつれて学習率がほぼゼロになるようにします。
分散測定ツールは、検索スペースから 1 つのモデルをサンプリングし、このモデルが OOM エラーまたは NAN エラーを発生させることなくトレーニングを開始できることを確認します。このモデルの 5 つのコピーをユーザーが行った設定で約 1 時間実行し、トレーニング スコアの分散と平滑度を報告します。このツールの実行に要する合計費用は、ユーザーが行った設定で約 1 時間 5 つのモデルを実行する場合とほぼ同じです。
次のコマンドを実行して、バリアンス測定ジョブを起動します(サービス アカウントが必要です)。
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
この分散測定ジョブを起動すると、ジョブリンクが表示されます。ジョブ名に接頭辞 Variance_Measurement が付加されている必要があります。ジョブ UI の例を以下に示します。
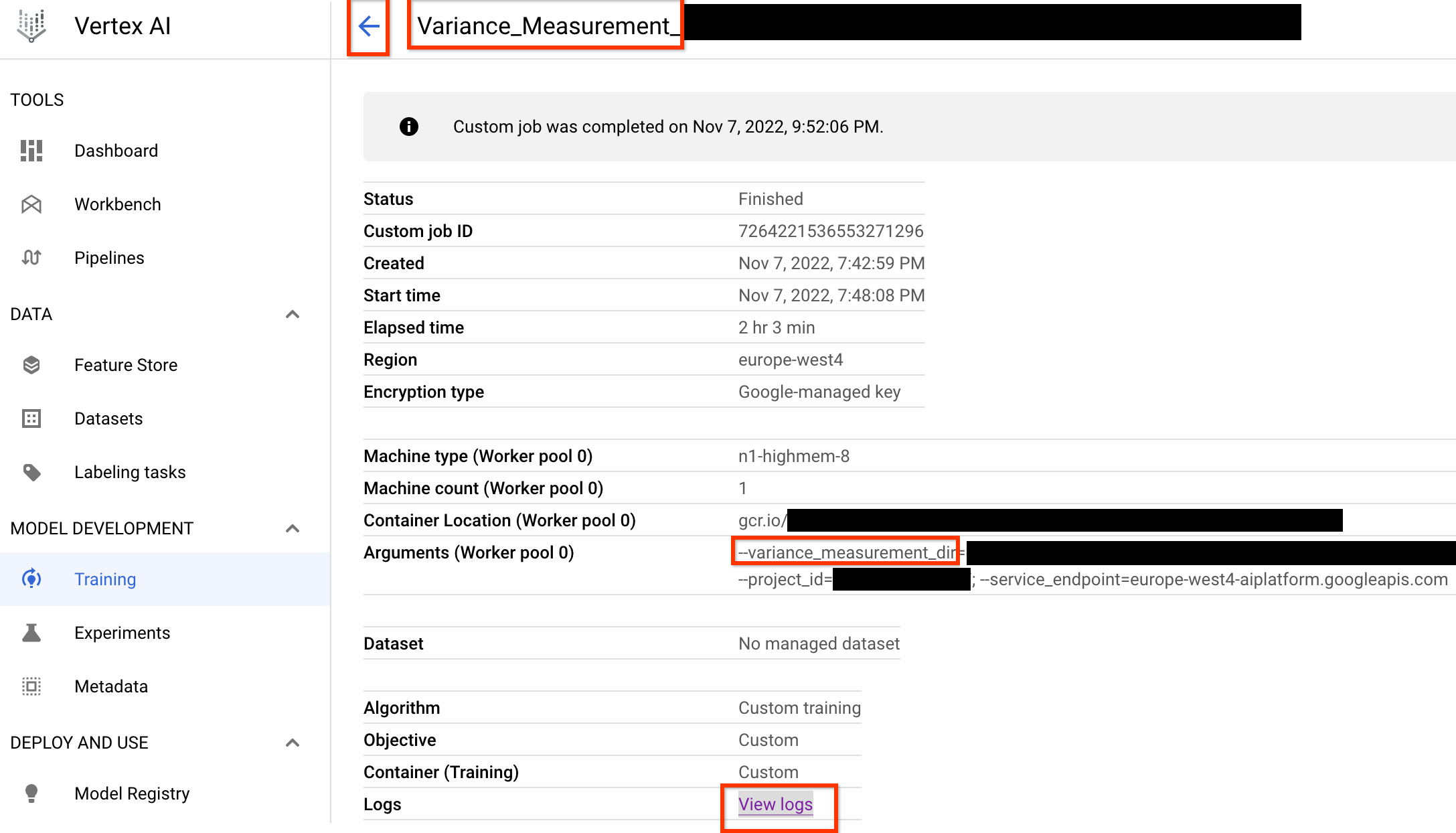
variance_measurement_dir にはすべての出力が含まれます。[View logs] リンクをクリックすると、ログを確認できます。デフォルトでは、このジョブはクラウド上で 1 つの CPU を使用してカスタムジョブとしてバックグラウンドで実行し、子 NAS ジョブを起動して管理します。
NAS ジョブの下に、Find_workable_model_<your job name> という名前のジョブが表示されます。このジョブは、検索スペースをサンプリングして 1 つのモデルを見つけます。この場合、エラーは発生しません。このようなモデルが見つかると、分散測定ジョブが別の NAS ジョブ <your job name> を起動します。このジョブは、先ほど設定したトレーニング ステップ数に対してこのモデルの 5 つのコピーを実行します。これらのモデルのトレーニングが完了すると、分散測定ジョブによってスコアの分散と平滑性が測定され、ログに記録されます。
分散が大きい場合は、こちらに記載されている手法を調べることができます。
モデルの選択
トレーナーの分散が大きくないことを確認したら、次の手順を実施します。
- 約 10 個の相関候補モデルを見つける。
- 完全なトレーニング スコアを計算する。これは、後でさまざまなプロキシタスク オプションのプロキシタスクの相関スコアを計算するときに参考情報として使用されます。
Google のツールは、これらの相関候補モデルを自動的かつ効率的に検出し、精度とレイテンシの両方に対して適切なスコア分布を確保します。これは、将来の相関計算の適切なベースとなります。このために、ツールは次の処理を行います。
- 検索空間から
N_beginモデルをランダムにサンプリングする。この例では、N_begin = 30とします。このツールは、フル トレーニング時間の 1/30 の時間でトレーニングを行います。 - 30 個のモデル中 5 個のモデルを拒否する。モデルの精度とレイテンシは分散されません。次の図に、例を示します。拒否されたモデルは赤色の点で表示されています。
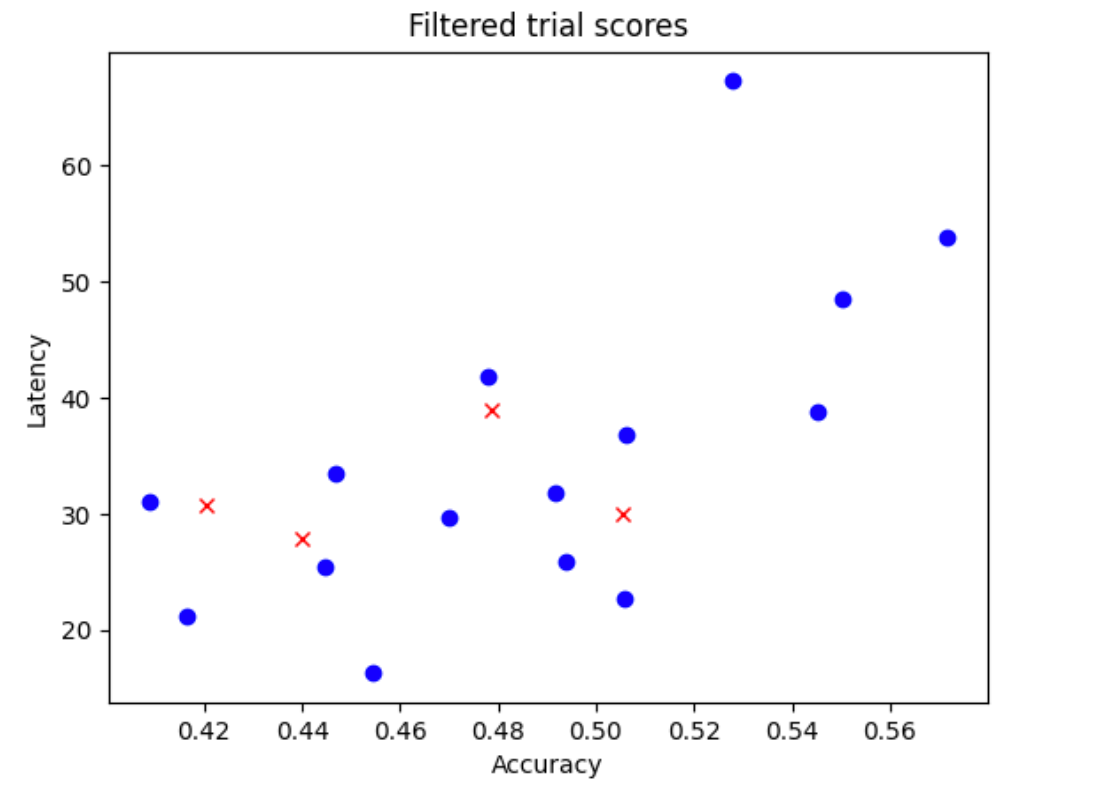
- 選択した 25 個のモデルをフル トレーニング時間の 1/25 の時間でトレーニングし、その時点までのスコアに基づいてさらに 5 つのモデルを拒否する。25 個のモデルのトレーニングは、以前のチェックポイントから継続されます。
- 分布が良好な
N個のモデルだけが残るまで、この処理を繰り返す。 - これらの最後の
Nモデルのトレーニングを完了する。
N_begin のデフォルト設定は 30 であり、proxy_task/proxy_task_model_selection_lib_constants.py ファイル内で START_NUM_MODELS として確認できます。N のデフォルト設定は 10 であり、proxy_task/proxy_task_model_selection_lib_constants.py ファイル内で FINAL_NUM_MODELS として確認できます。
このモデル選択プロセスの追加費用は、次のように計算されます。
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
ただし、N=10 設定を下回らないようにします。プロキシタスク検索ツールは、後でこれらの N モデルを並列実行します。そのため、この処理を行うための十分な GPU 割り当てがあることを確認してください。たとえば、プロキシタスクで 1 つのモデルに 2 つの GPU を使用している場合は、少なくとも 2*N 個の GPU の割り当てが必要です。
モデル選択ジョブでは、ステージ 2 のフル トレーニング ジョブと同じデータセット パーティションを使用し、同じトレーナー構成をベースラインのフル トレーニングに使用します。
これで、次のコマンドを実行してモデル選択ジョブを起動できるようになりました(サービス アカウントが必要です)。
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
このモデル選択コントローラ ジョブを起動すると、ジョブリンクが届きます。ジョブ名の先頭には接頭辞 Model_Selection_ が付加されています。ジョブ UI の例を以下に示します。
model_selection_dir にはすべての出力が含まれます。View logs リンクをクリックしてログを確認します。このモデル選択コントローラ ジョブは、デフォルトで Google Cloud 上の 1 つの CPU を使用して、バックグラウンドでカスタムジョブとして実行され、その後、モデル選択のイテレーションごとに子 NAS ジョブを起動して管理します。
各子 NAS ジョブの名前は <your_job_name>_iter_3 などです(イテレーション 0 を除く)。一度に 1 つのイテレーションが実行されます。イテレーションごとにモデルの数(トライアルの数)が減少し、トレーニング期間が長くなります。それぞれのイテレーションの最後に、各 NAS ジョブは gs://<job-output-dir>/search/filtered_trial_scores.png ファイルを保存します。このファイルは、このイテレーションで拒否されたモデルを視覚的に表示します。また、次のコマンドを実行することもできます。
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
これにより、モデル選択コントローラ ジョブのイテレーションと現在の状態、ジョブ名、各イテレーションのリンクが表示されます。
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
最後のイテレーションでは、参照モデルの最終的な数のスコアが良好に分布した状態になります。これらのモデルとそれらのスコアは、次のステップでプロキシタスクの検索に使用されます。参照モデルの最終精度とレイテンシ スコアの範囲が既存のベースライン モデルよりも良好または近似している場合は、検索スペースについて早期に把握できます。最終的な精度とレイテンシのスコア範囲がベースラインよりも著しく低い場合は、検索スペースを確認します。
最初のイテレーションでトライアルの 20% 以上が失敗した場合は、モデル選択ジョブをキャンセルして、失敗の根本原因を特定します。これは、検索スペースまたはバッチサイズと学習率の設定の問題であることが考えられます。
モデルの選択にオンプレミスのレイテンシ デバイスを使用する
モデル選択にオンプレミスのレイテンシ デバイスを使用するには、 Google Cloudでレイテンシ Docker を起動する必要がないため、レイテンシ Docker とレイテンシ Docker フラグを指定せずに select_proxy_task_models コマンドを実行します。次に、チュートリアル 4 で説明されている run_latency_calculator_local コマンドを使用して、オンプレミス レイテンシ計算ツールのジョブを起動します。--search_job_id フラグを渡すのではなく、select_proxy_task_models コマンドの実行後に取得した数値の model-selection job-id に --controller_job_id フラグを渡します。
モデル選択コントローラ ジョブの再開
次の状況では、モデル選択コントローラ ジョブを再開する必要があります。
- 親モデル選択コントローラ ジョブが停止した(まれなケース)。
- 誤ってモデル選択コントローラ ジョブをキャンセルした。
まず、子 NAS イテレーション ジョブ(NAS タブ)がすでに実行中の場合はキャンセルしないでください。次に、親モデル選択コントローラ ジョブを再開するには、以前と同じように select_proxy_task_models コマンドを実行しますが、今回は --previous_model_selection_dir フラグを渡して前のモデル選択コントローラ ジョブの出力ディレクトリに設定します。再開されたモデル選択コントローラ ジョブは、このディレクトリから以前の状態を読み込み、以前と同様に作業を継続します。
プロキシタスク検索
相関候補モデルとそれらのフル トレーニング スコアを見つけたら、次のステップでは、それらを使用してさまざまなプロキシタスクの選択肢の相関スコアを評価し、最適なプロキシタスクを選択します。プロキシタスク検索ツールを使用すると、次のようなプロキシタスクを自動的に検出できます。
- NAS の最小検索費用。
- プロキシタスク検索スペースの定義を提示した後、最小相関要件のしきい値を満たします。
前述のとおり、最適なプロキシタスクを検索するための一般的なディメンションは 3 つあります。これらには、以下に示す内容が含まれます。
- トレーニング ステップ数を削減する。
- トレーニング データの量を削減する。
- モデルのスケールを縮小する。
次に示すとおり、これらのディメンションをサンプリングすることで、離散プロキシタスク検索スペースを作成できます。

上に示した割合の数値は、概算値と例としてのみ設定されています。実際には、任意の選択を行うことができます。上の検索スペースにはトレーニング ステップ ディメンションは含まれていません。これは、プロキシタスク検索ツールが、プロキシタスクの選択肢に基づいて最適なトレーニング ステップを見つけるためです。プロキシタスクに [50% training data, 25% model scale] を選択することを検討してください。トレーニング ステップの数は、フル ベースライン トレーニングの場合と同じ量に設定します。このプロキシタスクを評価すると、プロキシタスク検索ツールは相関候補モデルのトレーニングを開始し、現在の精度スコアをモニタリングして、ランク相関スコアを継続的に計算します(参照モデルの過去のフル トレーニング スコアを使用)。

プロキシタスク検索ツールは、必要な相関関係(0.65 など)が得られたらプロキシタスク トレーニングを停止できます。または、検索コスト割り当て(例: プロキシタスクあたり 3 時間の上限)を超過した場合は、早期に停止することもできます。そのため、トレーニング ステップを明示的に検索する必要はありません。プロキシタスク検索ツールは、個別の検索スペースから各プロキシタスクをグリッド検索として評価し、最適なオプションを提示します。
以下に、proxy_task/proxy_task_search_spaces.py ファイルで定義された MnasNet プロキシタスク検索スペースの定義例 mnasnet_proxy_task_config_generator で、独自の検索スペースを定義する方法を示します。
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
この例では、training-data-percent で 25、50、75、95 という単純な検索スペースを作成します(100% のトレーニング データはステージ 1 検索では使用されません)。mnasnet_proxy_task_config_generator 関数は、トレーニング Docker 引数の共通ベースライン テンプレートを受け取ってから、目的のプロキシタスク トレーニング データサイズごとにこれらの引数を変更します。次に、proxy-task-config のリストを返します。これは、後でプロキシタスク検索ツールによって同じ順序で 1 つずつ処理されます。各プロキシタスク構成には name と docker_args_map があります。これは、プロキシタスクの Docker 引数の Key-Value マップです。
トレーニング データの削減やモデルのスケール縮小といった 2 つを超えるディメンションに対しても、独自の要件に従って独自の検索スペース定義を実装し、独自のプロキシタスク検索スペースを設計できます。ただし、繰り返しのコンピューティングは浪費を伴うため、トレーニング ステップを明示的に検索することはおすすめしません。プロキシタスク検索ツールがこのディメンションを処理します。
最初のプロキシタスク検索では、トレーニング データ(MnasNet の例と同様)のみを削減し、モデル スケーリングには image-size、num-filters、num-blocks のいずれかのパラメータが必要となるため、縮小したモデルスケールはスキップできます。ほとんどの場合、トレーニング データの削減(およびトレーニング ステップの削減に対する暗黙的な検索)だけで十分に適切なプロキシタスクを見つけることができます。
トレーニング ステップ数をフル ベースライン トレーニングで使用する数に設定します。ステージ 2 のフル トレーニングとステージ 1 のプロキシタスク トレーニングの構成には違いがあります。プロキシタスクでは、2 つの GPU または 4 つの GPU のみを使用するように、フル ベースライン トレーニング構成と比較して batch-size を削減する必要があります。通常、フル トレーニングでは 4 個の GPU、8 個の GPU、またはこれらを超える数の GPU を使用しますが、プロキシタスクは 2 個の GPU または 4 個の GPU のみを使用します。もう一つの違いは、トレーニングと検証の分割です。MnasNet 構成で、ステージ 2 のフル トレーニング用の 4 GPU から 2 つの GPU に変更し、プロキシタスクの検索用に別の検証分割を行う例を次に示します。
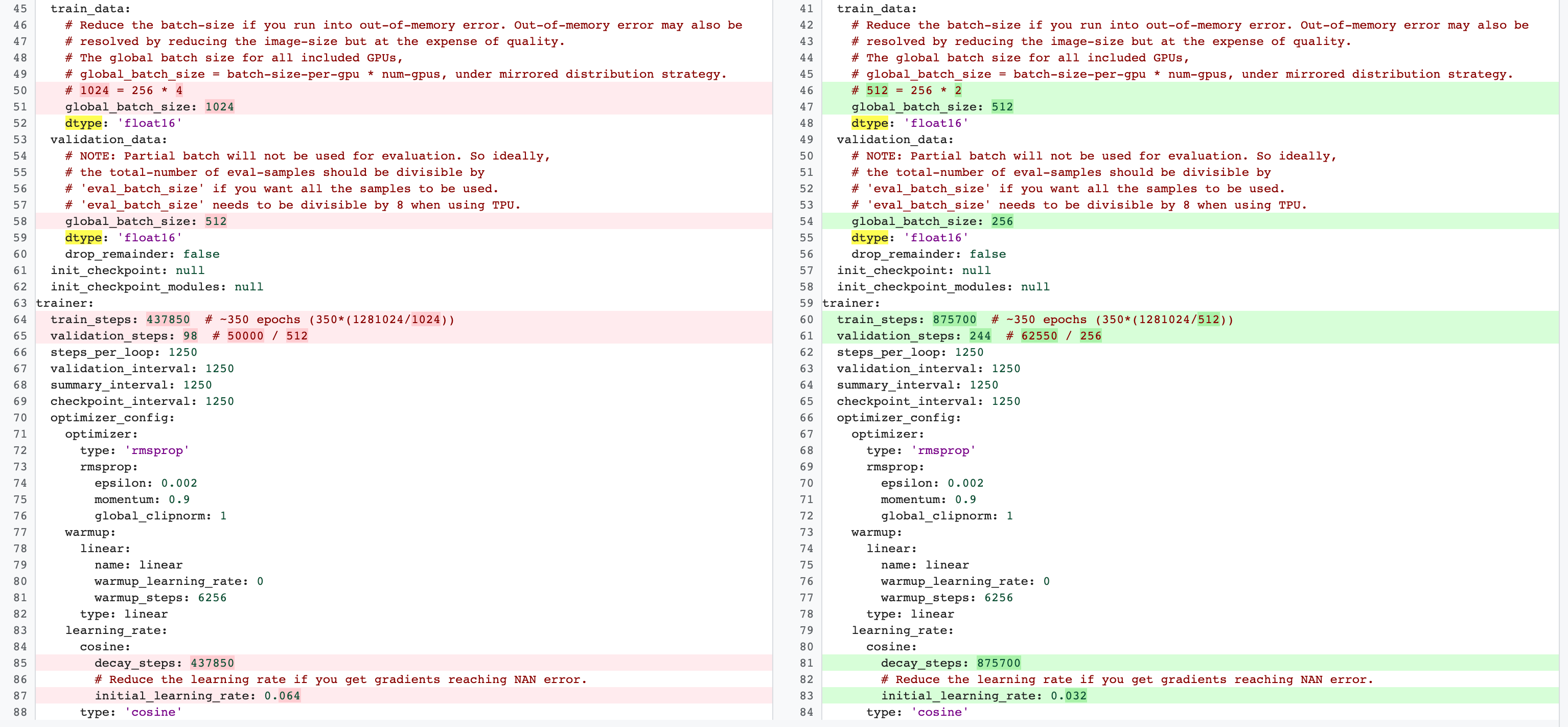
次のコマンドを実行して、プロキシタスク検索コントローラ ジョブを起動します(サービス アカウントが必要です)。
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
このプロキシタスク検索コントローラ ジョブを起動すると、ジョブリンクが届きます。ジョブ名の先頭には接頭辞 Search_controller_ が付加されています。ジョブ UI の例を以下に示します。
search_controller_dir にはすべての出力が含まれます。View logs リンクをクリックすると、ログを確認できます。このジョブは、デフォルトでクラウド上の 1 つの CPU を使用してカスタムジョブとしてバックグラウンドで実行された後、各プロキシタスクの評価のために子 NAS ジョブを起動して管理します。
各プロキシタスクの NAS ジョブには、ProxyTask_<your-job-name>_<proxy-task-name> などの名前が付いています。ここで <proxy-task-name> は、プロキシタスク構成生成ツールのモジュールが各プロキシタスクに提供するものです。一度に実行されるプロキシタスクの評価は 1 つのみです。また、次のコマンドを実行することもできます。
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
このコマンドは、すべてのプロキシタスクの評価の概要と、検索コントローラ ジョブの現在の状態、ジョブ名、各評価のリンクを表示します。
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map は各プロキシタスク評価の出力を保存し、best_proxy_task_name は検索に最適なプロキシタスクを記録します。各プロキシタスク エントリには proxy_task_stats などの追加データがあり、精度相関の進捗状況、p 値、精度の中央値、トレーニング ステップに対するトレーニング時間の中央値が記録されます。また、該当する場合はレイテンシ関連の相関を記録し、このジョブを停止する理由(トレーニング時間の上限を超過したなど)と停止する時点のトレーニング ステップを記録します。次のコマンドを実行することで、search_controller_dir の内容をローカル フォルダにコピーして、これらの統計情報をプロットとして表示することもできます。
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
プロット画像を調べます。たとえば、次のプロットは、最適なプロキシタスクの精度相関とトレーニング時間を示しています。

検索が完了し、最適なプロキシタスク構成が見つかったら、次のことを行う必要があります。
- トレーニング ステップ数を、優先対象のプロキシタスクの
final_training_stepsに設定する。 - コサイン減衰ステップを
final_training_stepsと同じに設定し、終了時点に近づくにつれ学習率がほぼゼロになるようにする。 - (省略可)トレーニングの最後に検証スコアの評価を 1 回行う。これにより、複数の評価費用が削減されます。
プロキシタスク検索にオンプレミス レイテンシ デバイスを使用する
プロキシタスク検索にオンプレミスのレイテンシ デバイスを使用するには、 Google Cloudでレイテンシ Docker を起動する必要がないため、レイテンシ Docker とレイテンシ Docker フラグを指定せずに search_proxy_task コマンドを実行します。次に、チュートリアル 4 で説明されている run_latency_calculator_local コマンドを使用して、オンプレミス レイテンシ計算ツールのジョブを起動します。--search_job_id フラグを渡すのではなく、search_proxy_task コマンドの実行後に取得した数値の proxy-task-search job-id に --controller_job_id フラグを渡します。
プロキシタスク検索コントローラ ジョブの再開
次の状況では、プロキシタスクの検索コントローラ ジョブを再開する必要があります。
- 親プロキシタスクの検索コントローラ ジョブが停止した(まれなケース)。
- プロキシタスク検索コントローラ ジョブを誤ってキャンセルした。
- プロキシタスクの検索スペースを(多数の数日が経過した後であっても)後で拡張する必要がある。
まず、子 NAS イテレーション ジョブ(NAS タブ)がすでに実行中の場合はキャンセルしないでください。次に、親プロキシタスクの検索コントローラ ジョブを再開するために、以前と同様に search_proxy_task コマンドを実行しますが、今回は --previous_proxy_task_search_dir フラグを渡し、前のプロキシタスク検索コントローラ ジョブの出力ディレクトリに設定します。再開されたプロキシタスク検索コントローラ ジョブは、このディレクトリから以前の状態を読み込み、以前と同様に作業を継続します。
最終チェック
プロキシタスクの 2 つの最終チェックには、検索範囲と、検索後の分析用のデータ保存が含まれます。
報酬範囲
コントローラに報告される報酬は [1e-3, 10] の範囲でなければなりません。これが true でない場合は、この目標を達成するために、報酬を手動で拡大できます。
検索後の分析用のデータの保存
プロキシタスク コードでは、追加の指標とデータを Cloud Storage に保存する必要があります。これは、後で検索スペースを分析する際に有用な可能性があります。Google の Neural Architecture Search プラットフォームは、浮動小数点 other_metrics を 5 つまでしか記録できません。後で分析するために、追加の指標は Cloud Storage に保存する必要があります。