Avant d'exécuter un job Neural Architecture Search pour rechercher un modèle optimal, vous devez définir votre tâche de proxy. Stage1-search utilise une représentation beaucoup plus petite d'un entraînement de modèle complet qui se termine généralement dans un délai de deux heures. Cette représentation est appelée tâche de proxy et réduit considérablement le coût de recherche. Chaque essai pendant la recherche entraîne un modèle à l'aide des paramètres de tâche de proxy.
Les sections suivantes décrivent les éléments impliqués dans l'application de la conception de tâches proxy :
- Approches permettant de créer une tâche de proxy.
- Prérequis pour une tâche de proxy de qualité.
- Comment utiliser les trois outils de conception de tâches de proxy pour trouver la tâche de proxy optimale, ce qui réduit les coûts tout en maintenant la qualité de la recherche.
Approches permettant de créer une tâche de proxy
Il existe trois approches courantes pour créer une tâche de proxy, parmi lesquelles :
- Utiliser moins d'étapes d'entraînement.
- Utiliser un ensemble de données d'entraînement sous-échantillonné.
- Utiliser un modèle réduit.
Utiliser moins d'étapes d'entraînement
Le moyen le plus simple de créer une tâche de proxy consiste à réduire le nombre d'étapes d'entraînement pour votre outil d'entraînement et à signaler un score au contrôleur sur la base de cet entraînement partiel.
Utiliser un ensemble de données d'entraînement sous-échantillonné
Cette section décrit l'utilisation d'un ensemble de données d'entraînement sous-échantillonné pour une recherche d'architecture et une recherche de règles d'augmentation.
Recherche d'architecture
Vous pouvez créer une tâche de proxy à l'aide d'un ensemble de données d'entraînement sous-échantillonné lors de la recherche d'architecture. Toutefois, lorsque vous sous-échantillonnez, suivez les consignes suivantes :
- Mélangez les données de manière aléatoire entre les segments.
- Si les données d'entraînement sont déséquilibrées, sous-échantillonnez les données de manière à les équilibrer.
Recherche de règles d'augmentation à l'aide de l'augmentation automatique
Ignorez cette section si vous n'exécutez pas de recherche qui soit exclusivement une recherche d'augmentation, et que vous n'effectuez que la recherche d'architecture standard. Utilisez la fonctionnalité d'augmentation automatique pour rechercher une règle d'augmentation. Il est souhaitable de sous-échantillonner les données d'entraînement et d'exécuter un entraînement complet plutôt que de réduire le nombre d'étapes d'entraînement. L'exécution d'un entraînement complet avec une augmentation forte préserve la stabilité des scores. En outre, utilisez les données d'entraînement réduites pour réduire le coût de recherche.
Tâche de proxy basée sur un modèle à capacité réduite
Vous pouvez également réduire le modèle par rapport au modèle de référence pour créer une tâche de proxy. Cela peut également être utile lorsque vous souhaitez séparer block-design-search de scaling-search.
Toutefois, lorsque vous réduisez le modèle et que vous souhaitez utiliser une contrainte de latence, utilisez une contrainte de latence plus stricte pour le modèle réduit. Indice : Vous pouvez réduire le modèle de référence et mesurer sa latence pour définir cette contrainte de latence plus étroite.
Pour le modèle à capacité réduite, vous pouvez également réduire le volume d'augmentation et de régularisation par rapport au modèle de référence d'origine.
Exemples de modèle à capacité réduite
Pour les tâches computer-vision où vous effectuez l'entraînement sur des images, trois méthodes sont disponibles pour effectuer le scaling à la baisse d'un modèle :
- Réduire la largeur du modèle : nombre de canaux.
- Réduire la profondeur du modèle : nombre de couches et répétitions de blocs.
- Réduire légèrement la taille de l'image d'entraînement (afin de ne pas éliminer de caractéristiques) ou recadrer les images d'entraînement si votre tâche le permet.
Suggestions de lecture : l'article EfficientNet fournit des informations précieuses sur le scaling des modèles pour les tâches de vision par ordinateur. Cela explique également la relation entre ces trois méthodes de scaling.
La recherche Spinnaker est un autre exemple de scaling de modèle utilisé avec Neural Architecture Search. Pour la recherche de phase 1, elle réduit le nombre de canaux et la taille de l'image.
Tâche de proxy basée sur une combinaison
Les approches fonctionnent indépendamment et peuvent être combinées à différents degrés pour créer une tâche de proxy.
Prérequis pour une tâche de proxy de qualité
Une tâche de proxy doit répondre à certaines exigences avant de pouvoir renvoyer une récompense stable au contrôleur et maintenir la qualité de la recherche.
Corrélation entre le classement de la recherche de la phase 1 et de l'entraînement complet de la phase 2
Lorsque vous utilisez une tâche de proxy pour Neural Architecture Search, une hypothèse clé pour une recherche réussie est que si le modèle A est plus performant que le modèle B pendant la phase 1 de l'entraînement de recherche d'architecture neuronale, le modèle A sera également plus performant que le modèle B lors de l'entraînement complet à la phase 2. Pour valider cette hypothèse, vous devez évaluer la corrélation des classements des récompenses entre la recherche à la phase1 et l'entraînement complet sur environ 10-20 modèles dans votre espace de recherche. Ces modèles sont appelés correlation-candidate-models.
La figure ci-dessous montre un exemple de mauvaise corrélation (correlation-score = -0,03), ce qui rend cette tâche de proxy inadaptée à une recherche :
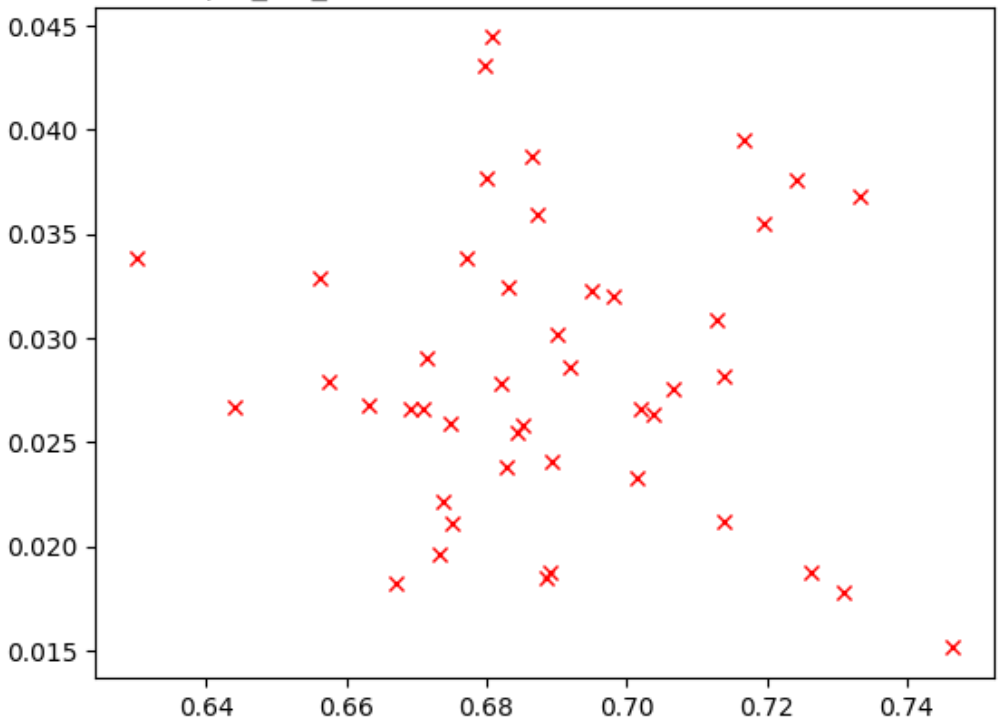
Chaque point du tracé représente un modèle correlation-candidate.
L'axe x représente les scores d'entraînement complets de la phase 2 pour les modèles, et l'axe y représente les scores de tâche de proxy de phase 1 pour les mêmes modèles.
Observez le point le plus élevé. Ce modèle a obtenu le score de tâche de proxy le plus élevé (en axe y), mais offre de mauvaises performances lors de l'entraînement complet en phase 2 (axe x) par rapport aux autres modèles. La figure ci-dessous montre un exemple de bonne corrélation (correlation-score = 0,67), ce qui fait de cette tâche de proxy un bon candidat pour une recherche :
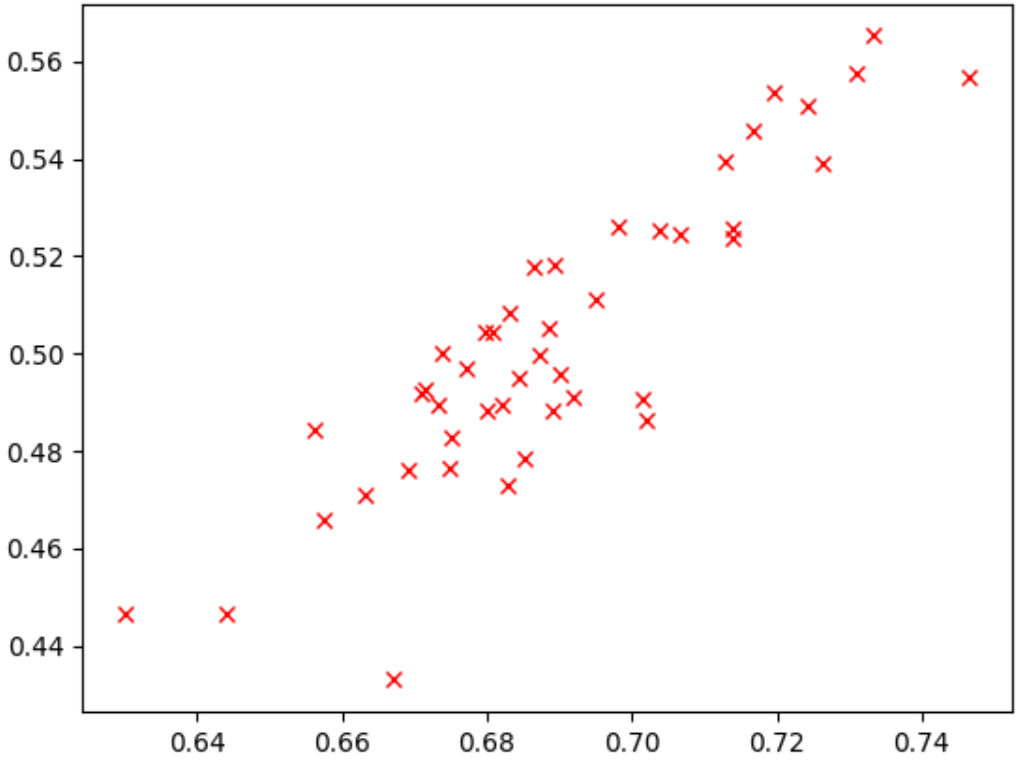
Si votre recherche implique une contrainte de latence, vérifiez également la corrélation des valeurs de latence.
Notez que les récompenses des correlation-candidate-models sont associées à une bonne plage et offrent un échantillonnage correct de la plage de récompenses. Sinon, vous ne pouvez pas évaluer la corrélation des classements. Par exemple, si toutes les récompenses de l'étape 1 des modèles de corrélation sont centrées autour de deux valeurs seulement : 0,9 et 0,1, la variance d'échantillonnage est insuffisante.
Vérification de la variance
Un autre prérequis pour une tâche de proxy est qu'elle ne doit pas présenter de variation importante de la justesse ni de son score de latence lorsqu'elle est répétée plusieurs fois pour le même modèle sans aucune modification. Dans ce cas, un signal bruyant est renvoyé au contrôleur. Un outil permettant de mesurer cette variance est fourni.
Des exemples sont fournis pour atténuer la variance importante pendant l'entraînement. Une solution consiste à utiliser cosine decay comme planification de learning-rate. Le graphique suivant compare trois stratégies de learning-rate :
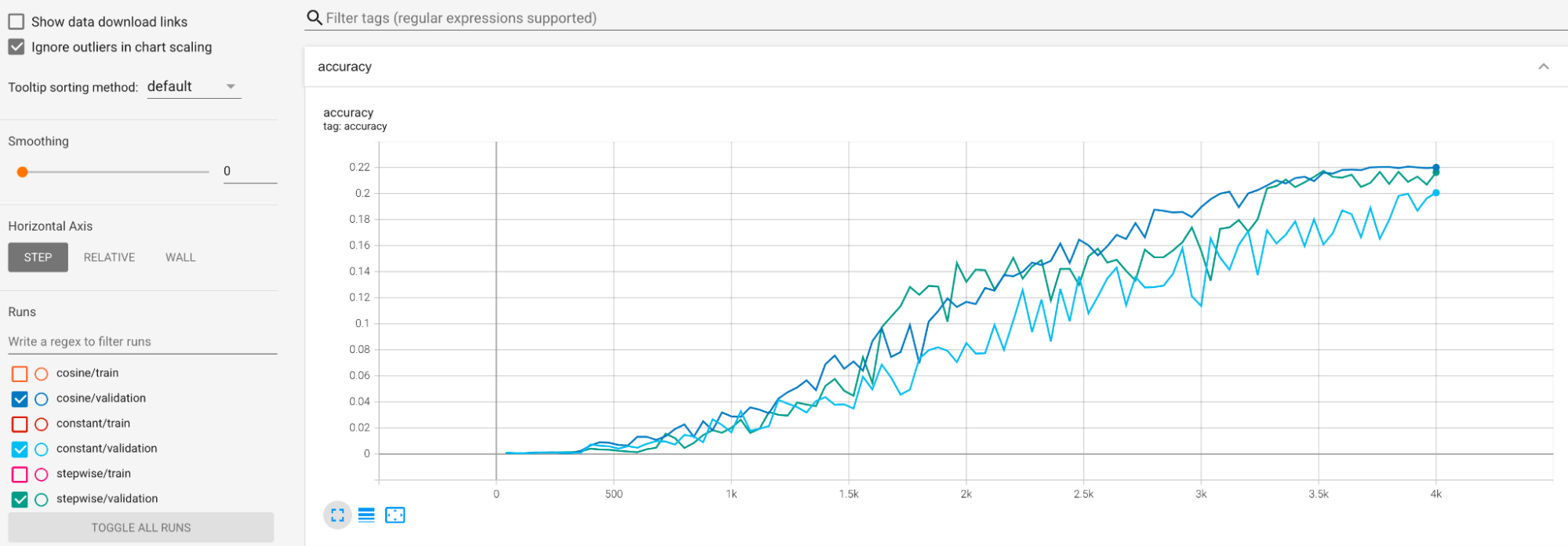
Le tracé le plus bas correspond à un taux d'apprentissage constant. Lorsque le score saute à la fin de l'entraînement, une légère modification du choix du nombre réduit d'étapes d'entraînement peut entraîner un changement important dans la récompense finale de la tâche de proxy. Pour rendre la récompense de la tâche de proxy plus stable, il est préférable d'utiliser une décroissance du taux d'apprentissage cosinus, comme indiqué par les scores de validation correspondants dans le tracé le plus élevé de la figure. Notez que le tracé le plus élevé est plus fluide vers la fin de l'entraînement. Le tracé du milieu montre le score correspondant à la décroissance du taux d'apprentissage par étapes. Il est préférable au taux constant, mais pas aussi fluide que la décroissance cosinus et nécessite un réglage manuel.
Les planifications des taux d'apprentissage sont présentées ci-dessous :
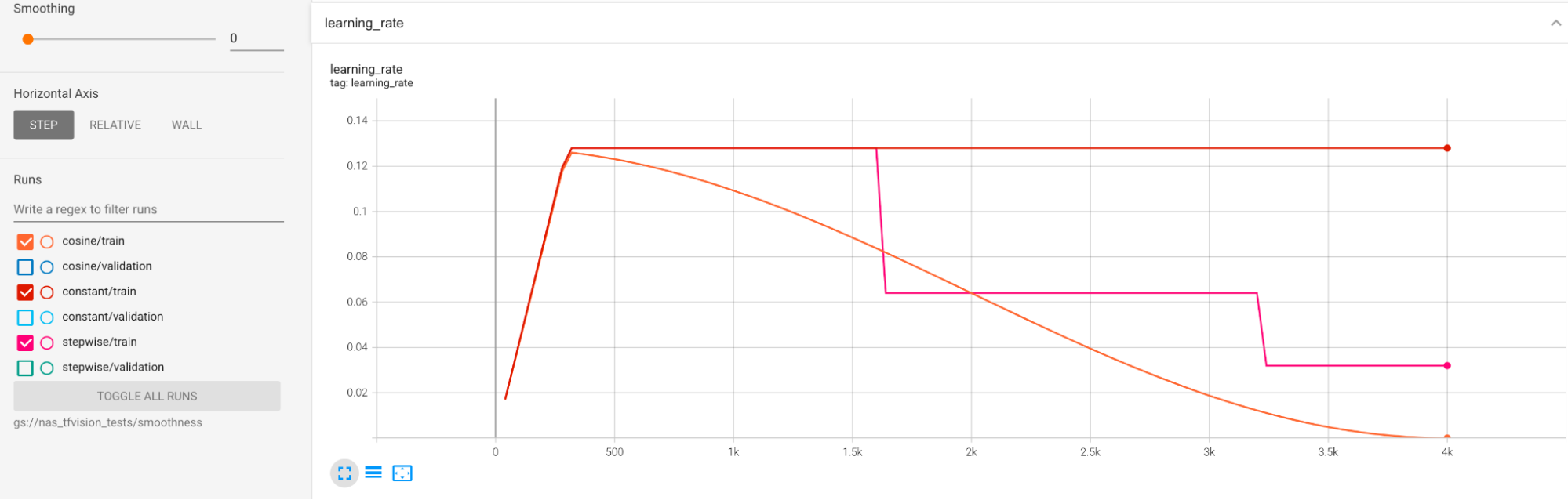
Lissage supplémentaire
Si vous utilisez une augmentation élevée, votre courbe de validation peut ne pas devenir suffisamment lisse avec la décroissance cosinus. L'utilisation d'une augmentation élevée indique un manque de données d'entraînement. Dans ce cas, l'utilisation de la technologie NAS (Neural Architecture Search) n'est pas recommandée, et nous vous recommandons d'utiliser plutôt augmentation-search.
Si la forte augmentation n'est pas la cause du problème et que vous avez déjà essayé la décroissance cosinus, mais que vous souhaitez obtenir davantage de lissage, utilisez exponential-moving-average (moyenne exponentielle mobile) pour TensorFlow 2 ou la stochastic-weighted-averaging (moyenne pondérée stochastique) pour PyTorch. Reportez-vous à ce point de code pour obtenir un exemple utilisant l'optimiseur de moyenne mobile exponentielle avec TensorFlow 2 et à cet exemple de moyenne pondérée stochastique pour PyTorch.
Si vos graphes de justesse/époque pour les essais se présentent comme suit :
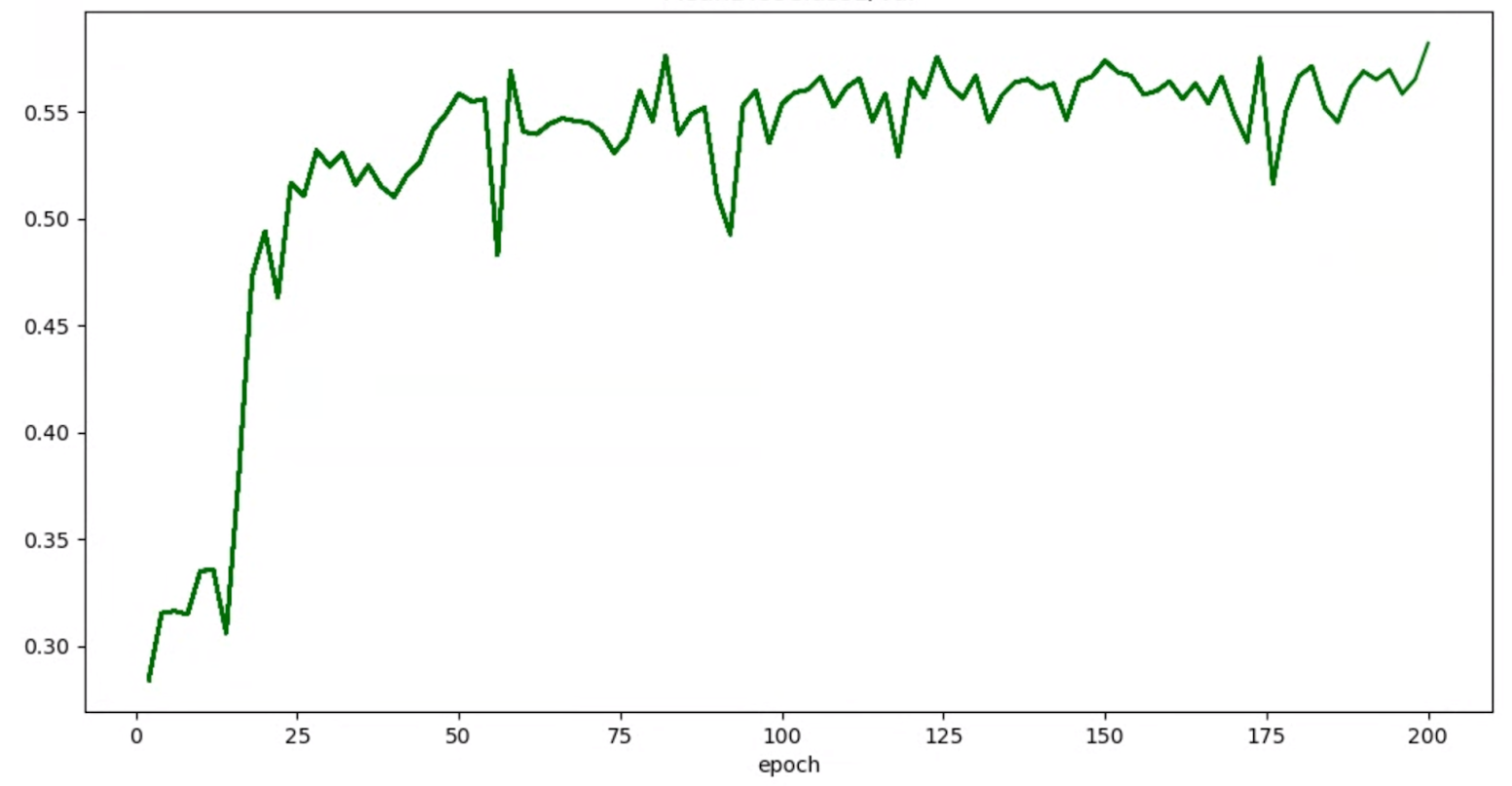
vous pouvez appliquer les techniques de lissage mentionnées ci-dessus (telles que la moyenne pondérée stochastique ou l'utilisation de la moyenne mobile exponentielle) pour obtenir un graphique plus cohérent, par exemple :
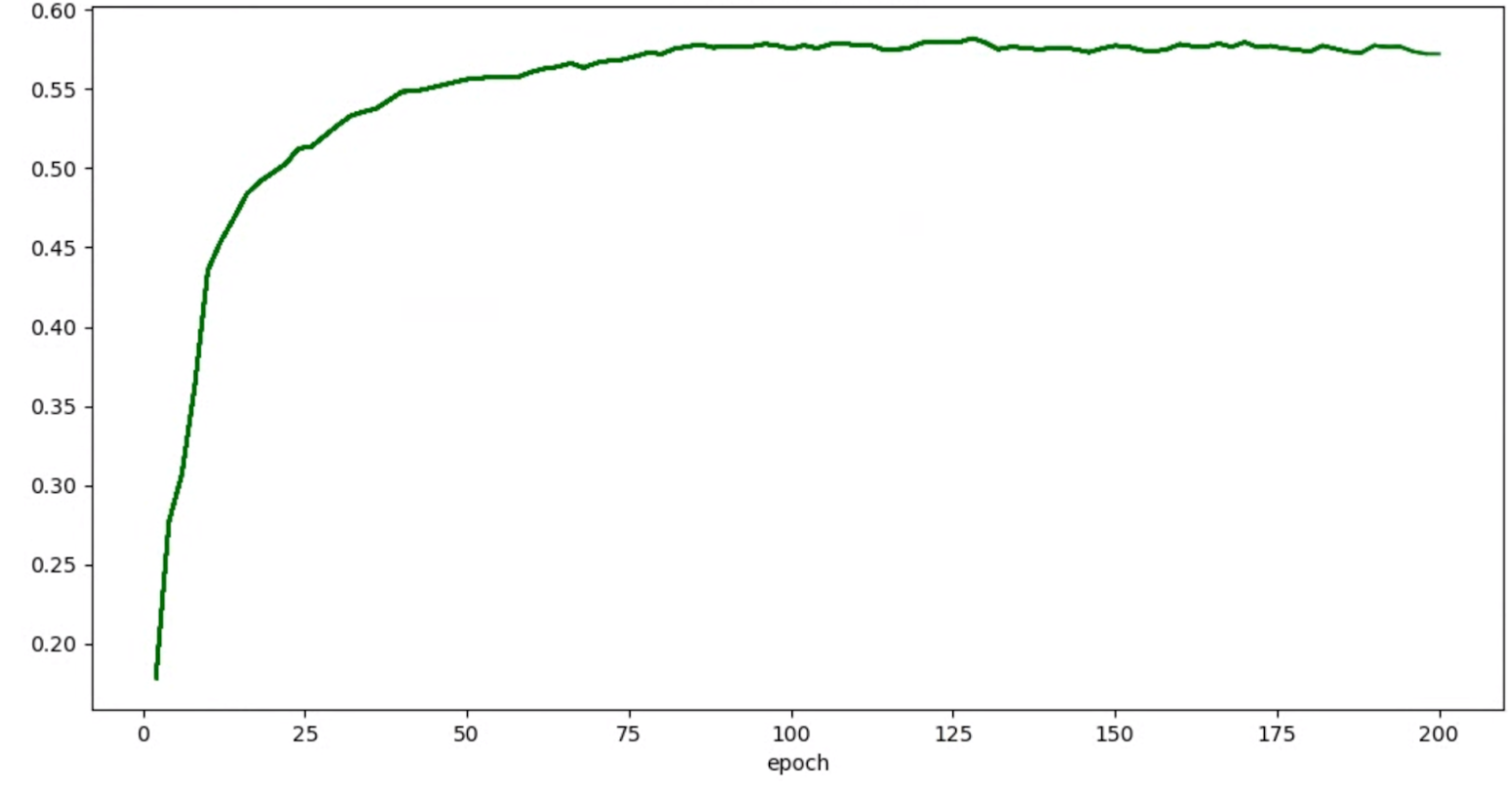
Erreurs liées à la mémoire insuffisante et au taux d'apprentissage
L'espace de recherche d'architecture peut générer des modèles beaucoup plus volumineux que votre référence. Si vous avez ajusté la taille de lot de votre modèle de référence, ce paramètre peut échouer lorsque des modèles plus volumineux sont échantillonnés lors de la recherche, entraînant des erreurs de mémoire insuffisante. Dans ce cas, vous devez réduire la taille de lot.
L'autre type d'erreur qui s'affiche est l'erreur NaN (n'est pas un nombre). Vous devez réduire le taux d'apprentissage initial ou ajouter le bornement de la norme du gradient.
Comme indiqué dans le tutorial-2, si plus de 20 % de vos modèles d'espace de recherche renvoient des scores non valides, vous ne devez pas exécuter la recherche complète. Nos outils de conception de tâches de proxy vous permettent d'évaluer le taux d'échecs.
Outils de conception de tâches de proxy
Les sections précédentes traitent des principes de conception d'une tâche de proxy. Cette section fournit trois outils de conception de tâche de proxy permettant d'identifier automatiquement la tâche de proxy optimale, en fonction des différentes approches de conception, et qui réponde à toutes les exigences.
Modifications de code requises
Vous devez d'abord modifier légèrement le code de votre application d'entraînement afin qu'elle puisse interagir avec les outils de conception de tâches de proxy pendant un processus itératif.
tf_vision/train_lib.py en est un exemple. Vous devez d'abord importer notre bibliothèque :
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Avant de commencer un cycle d'entraînement, vérifiez si vous devez arrêter prématurément l'entraînement, car l'outil de conception de tâches de proxy vous oblige à utiliser notre bibliothèque :
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Une fois chaque cycle d'entraînement de la boucle d'entraînement terminé, mettez à jour le nouveau score de justesse, l'étape de début et de fin du cycle d'entraînement, le temps d'entraînement en secondes et le nombre total d'étapes d'entraînement.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
Notez que la durée de cycle d'entraînement ne doit pas inclure de temps d'évaluation du score de validation. Assurez-vous que votre application d'entraînement calcule fréquemment les scores de validation (evaluation-frequency) afin d'avoir un échantillonnage suffisant de votre courbe de validation. Si vous utilisez une contrainte de latence, mettez à jour la métrique de latence après le calcul de la latence :
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
L'outil model-selection nécessite le chargement du point de contrôle précédent pour les itérations successives.
Pour activer la réutilisation d'un point de contrôle précédent, ajoutez une option à votre application d'entraînement, comme indiqué dans tf_vision/cloud_search_main.py :
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Chargez ce point de contrôle avant d'entraîner votre modèle :
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
Vous avez également besoin de l'ID metric-id correspondant aux valeurs de justesse et de latence signalées par votre application d'entraînement. Si votre récompense d'entraînement (qui est parfois une combinaison de justesse et de latence) est différente de la justesse, veillez à renvoyer également la métrique accuracy-only en utilisant l'option other_metrics de votre application d'entraînement.
L'exemple suivant montre les métriques accuracy-only et de latence signalées par notre application d'entraînement prédéfinie :
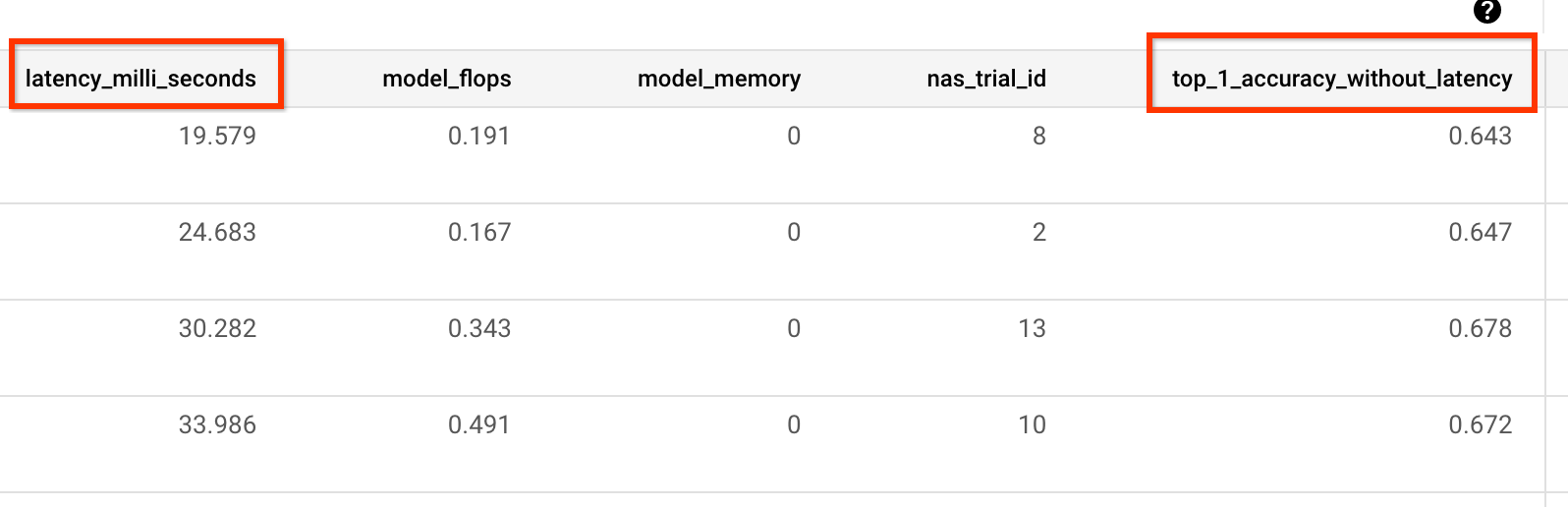
Mesure de la variance
Après avoir modifié le code de votre application d'entraînement, la première étape consiste à mesurer la variance pour votre application d'entraînement. Pour la mesure de la variance, modifiez votre configuration d'entraînement de référence pour les éléments suivants :
- Allégez les étapes d'entraînement en les exécutant pendant environ une heure avec seulement un ou deux GPU. Nous avons besoin d'un petit échantillon d'entraînement complet.
- Utiliser le taux d'apprentissage avec décroissance cosinus et définir ses étapes pour qu'elles soient identiques à ces étapes réduites afin que le taux d'apprentissage devienne proche de zéro.
L'outil de mesure de la variance échantillonne un modèle à partir de l'espace de recherche et s'assure que ce modèle peut commencer l'entraînement sans générer d'erreurs OOM ou NAN. L'outil exécute cinq copies de ce modèle avec vos paramètres pendant environ une heure, puis indique la variance et le lissage du score d'entraînement. Le coût total d'exécution de cet outil correspond à peu près à celui de l'exécution de cinq modèles avec vos paramètres pendant environ une heure.
Lancez le job variance-measurement en exécutant la commande suivante (vous devez disposer d'un compte de service) :
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Une fois ce job de mesure de variance lancé, vous obtenez un job-link (lien de job). Le job-name (nom du job) doit commencer par le préfixe Variance_Measurement. Voici un exemple d'interface utilisateur de job :
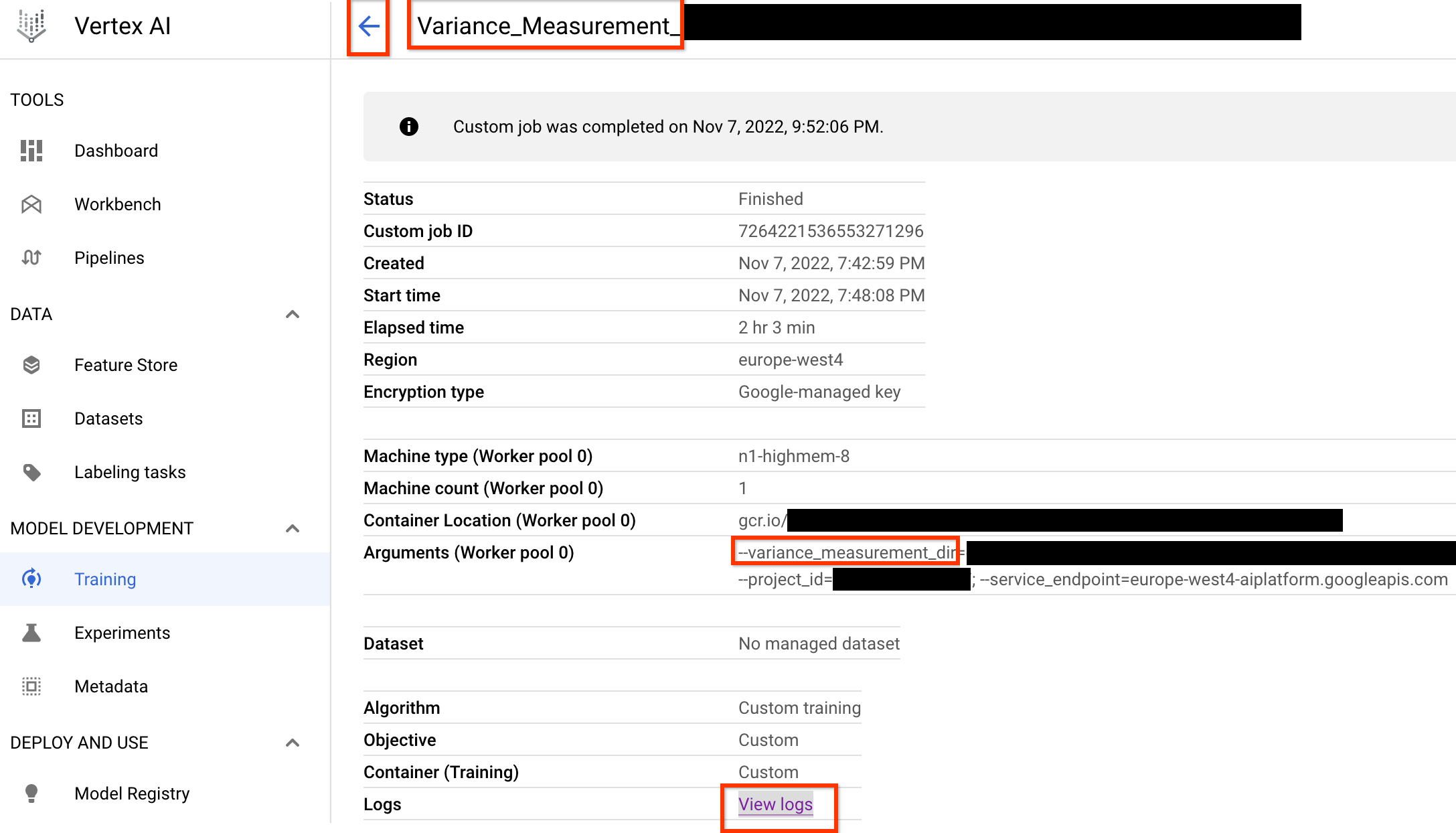
Le fichier variance_measurement_dir contiendra toutes les sorties et vous pourrez vérifier les journaux en cliquant sur le lien Afficher les journaux.
Par défaut, ce job utilise un processeur sur le cloud pour s'exécuter en arrière-plan en tant que job personnalisé, puis lance et gère des jobs NAS enfants.
Sous les jobs NAS, vous trouverez un job nommé Find_workable_model_<your job name>. Ce job échantillonne votre espace de recherche pour trouver un modèle qui ne génère aucune erreur. Une fois ce modèle trouvé, le job de mesure de variance lance un autre job NAS <your job name>, qui exécute cinq copies de ce modèle pour le nombre d'étapes d'entraînement que vous avez défini précédemment. Une fois l'entraînement de ces modèles terminé, le job de mesure de variance mesure sa variance et sa fluidité, puis les inscrit dans ses journaux :
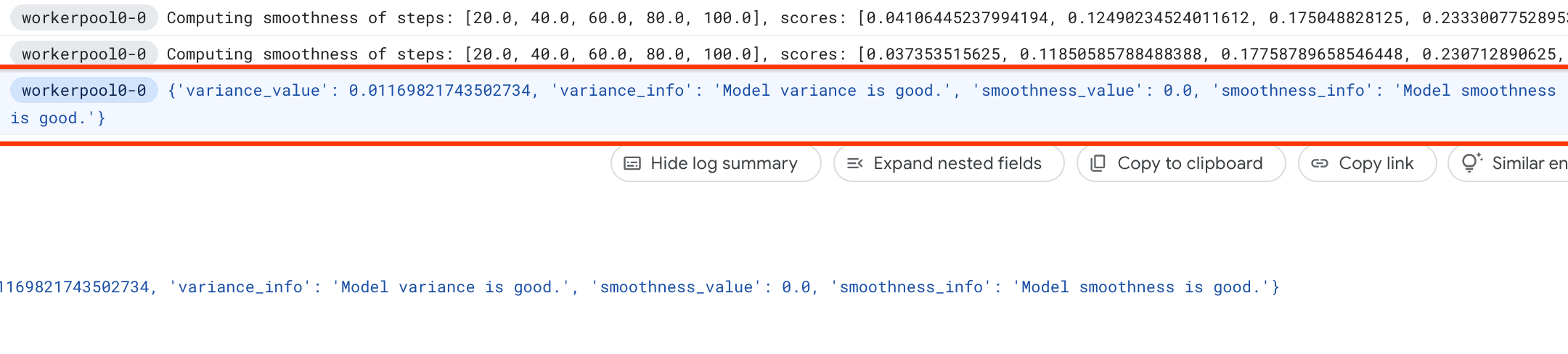
Si la variance est élevée, vous pouvez explorer les techniques répertoriées ici.
Sélection du modèle
Une fois que vous avez vérifié que votre application d'entraînement ne présente pas de variance élevée, les étapes suivantes sont possibles :
- Trouver environ 10 modèles correlation-candidate-models
- Calculer les scores d'entraînement complets qui serviront de référence lorsque vous calculerez les scores de corrélation du proxy pour différentes options de tâche de proxy ultérieurement.
Notre outil détecte automatiquement et efficacement ces modèles de corrélation et garantit une bonne distribution des scores pour la justesse et la latence afin que le calcul de corrélation futur dispose d'une bonne base. Pour ce faire, l'outil effectue les opérations suivantes :
- Il échantillonne de manière aléatoire
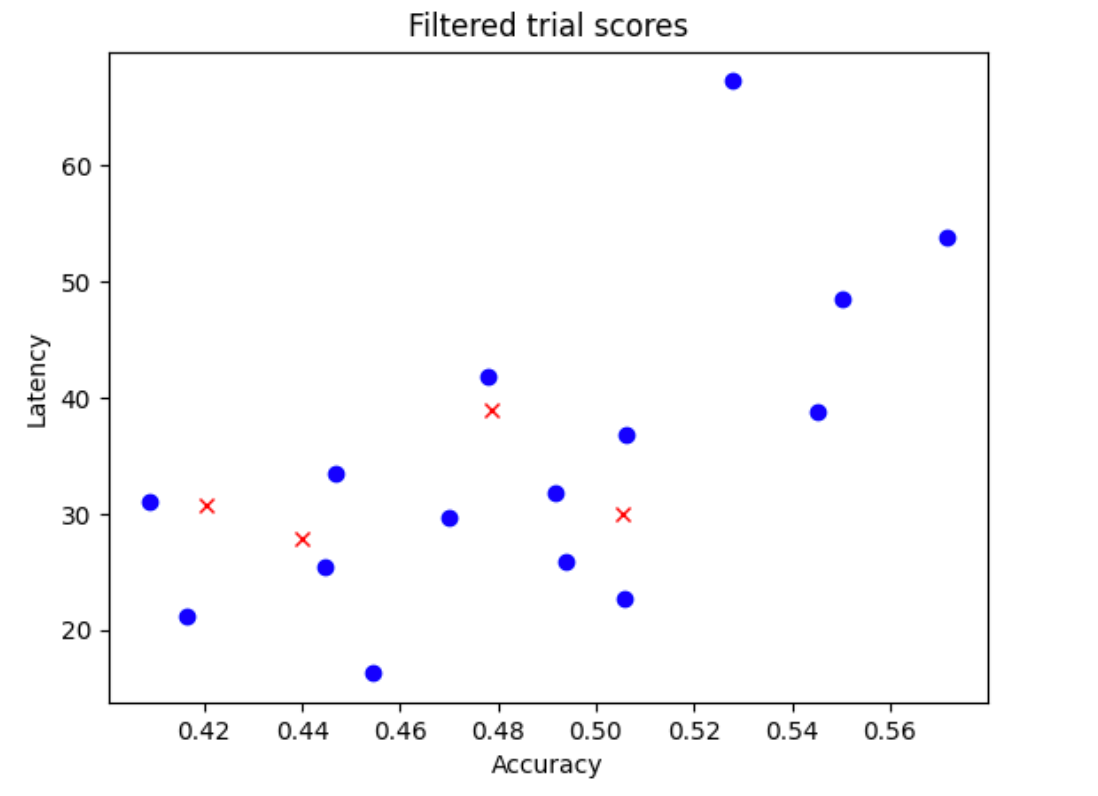
N_beginmodèles à partir de votre espace de recherche. Pour exemple ci-dessous, supposons queN_begin = 30. L'outil entraîne ces modèles pendant 1/30e de la durée d'entraînement complète. - Il refuse 5 modèles sur 30, qui n'augmentent pas la distribution de la justesse et de la latence. La figure suivante illustre ce comportement à titre d'exemple. Les modèles refusés sont affichés sous forme de points rouges :
- Il entraîne les 25 modèles sélectionnés pendant 1/25e du temps d'entraînement complet, puis refuse cinq autres modèles en fonction des scores obtenus jusqu'à présent. Notez que l'entraînement des 25 modèles se poursuit à partir de leur point de contrôle précédent.
- Répétez ce processus jusqu'à ce qu'il ne reste que des modèles
Nprésentant une bonne distribution. - Entraînez ces
Nderniers modèles jusqu'au bout.
Le paramètre par défaut de N_begin est 30 et est défini sous la forme START_NUM_MODELS dans le fichier proxy_task/proxy_task_model_selection_lib_constants.py.
Le paramètre par défaut de N est 10 et est défini sous la forme FINAL_NUM_MODELS dans le fichier proxy_task/proxy_task_model_selection_lib_constants.py.
Le coût supplémentaire de ce processus de sélection de modèle est calculé comme suit :
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
Toutefois, restez au-dessus du paramètre N=10. L'outil de recherche de tâche de proxy exécute ensuite ces modèles N en parallèle. Par conséquent, assurez-vous de disposer d'un quota de GPU suffisant. Par exemple, si votre tâche de proxy utilise deux GPU pour un modèle, vous devez disposer d'un quota d'au moins 2*N GPU.
Pour le job model-selection, utilisez la même partition d'ensemble de données que pour le job d'entraînement complet de phase 2 et utilisez la même configuration d'application d'entraînement pour votre entraînement complet de référence.
Vous êtes maintenant prêt à lancer le job de sélection de modèle en exécutant la commande suivante (vous devez disposer d'un compte de service) :
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Une fois le job du contrôleur de sélection de modèle lancé, vous recevez un lien de job. Le nom du job commence par le préfixe Model_Selection_. Voici un exemple d'interface utilisateur de job :
model_selection_dir contient toutes les sorties. Vérifiez les journaux en cliquant sur le lien View logs.
Par défaut, ce job du contrôleur de sélection de modèle utilise un processeur sur Google Cloud pour s'exécuter en arrière-plan en tant que job personnalisé, puis il lance et gère des jobs enfants de recherche d'architecture neuronale pour chaque itération de la sélection de modèles.
Chaque job enfant de NAS porte un nom tel que <your_job_name>_iter_3 (sauf pour l'itération 0). Une seule itération est exécutée à la fois. À chaque itération, le nombre de modèles (nombre d'essais) diminue et la durée d'entraînement augmente. À la fin de chaque itération, chaque job NAS enregistre le fichier gs://<job-output-dir>/search/filtered_trial_scores.png qui indique visuellement les modèles refusés à cette itération.
Vous pouvez également exécuter la commande suivante :
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
Elle affiche un récapitulatif des itérations et de l'état actuel du job du contrôleur de sélection de modèle, le nom du job et les liens correspondant à chaque itération :
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
La dernière itération comporte le nombre final de modèles de référence avec une bonne distribution des scores. Ces modèles et leurs scores sont utilisés pour la recherche de tâches de proxy à l'étape suivante. Si la plage de justesse et de score de latence finale des modèles de référence semble meilleure ou proche de votre modèle de référence existant, vous obtenez une bonne indication anticipée pour votre espace de recherche. Si la plage de justesse et de latence finale est nettement inférieure à la valeur de référence, revenez à votre espace de recherche.
Notez que si plus de 20 % de vos essais échouent lors de la première itération, annulez le job de sélection du modèle et identifiez la cause première des échecs. Il peut s'agir d'un problème lié à votre espace de recherche ou à vos paramètres de taille de lot et de taux d'apprentissage.
Utiliser un appareil sur site avec latence pour sélectionner un modèle
Pour utiliser un appareil sur site avec latence pour sélectionner un modèle, exécutez la commande select_proxy_task_models sans les options latency docker et latency-docker, car vous n'avez pas intérêt à lancer le docker de latence sur Google Cloud. Exécutez ensuite la commande run_latency_calculator_local décrite dans le tutoriel 4 pour lancer le job de simulateur de latence sur site. Au lieu de transmettre l'option --search_job_id, transmettez l'option --controller_job_id avec l'ID numérique du job de sélection de modèle que vous avez obtenu après l'exécution de la commande select_proxy_task_models.
Relancer le job du contrôleur de sélection de modèle
Les situations suivantes nécessitent de relancer le job du contrôleur de sélection de modèle :
- Le job parent du contrôleur de sélection de modèle s'arrête (cas rare).
- Vous annulez accidentellement le job du contrôleur de sélection de modèle.
Tout d'abord, n'annulez pas le job d'itération enfant de NAS (onglet NAS) s'il est déjà en cours d'exécution. Ensuite, pour relancer le job parent du contrôleur de sélection de modèle, exécutez la commande select_proxy_task_models comme auparavant, mais transmettez cette fois l'option --previous_model_selection_dir et définissez-la sur le répertoire de sortie correspondant au précédent job du contrôleur de sélection de modèle. Le job du contrôleur de sélection de modèle relancé charge son état précédent depuis le répertoire et continue de fonctionner comme auparavant.
Recherche de tâche de proxy
Une fois que vous avez trouvé les modèles correlation-candidate et leurs scores d'entraînement complets, l'étape suivante consiste à les utiliser pour évaluer les scores de corrélation pour différents choix de tâche de proxy, puis choisir la tâche de proxy optimale. Notre outil de recherche de tâches de proxy peut trouver automatiquement une tâche de proxy, ce qui offre les avantages suivants :
- Le coût de recherche d'architecture neuronale le plus bas.
- Respect d'un seuil minimal de corrélation requis après avoir fourni une définition d'espace de recherche de tâche de proxy.
Rappelez-vous qu'il existe trois dimensions courantes permettant de rechercher une tâche de proxy optimale, qui incluent :
- Réduction du nombre d'étapes d'entraînement
- Quantité réduite de données d'entraînement.
- Échelle du modèle réduite.
Vous pouvez créer un espace de recherche de tâche de proxy privé en échantillonnant ces dimensions, comme indiqué ici :
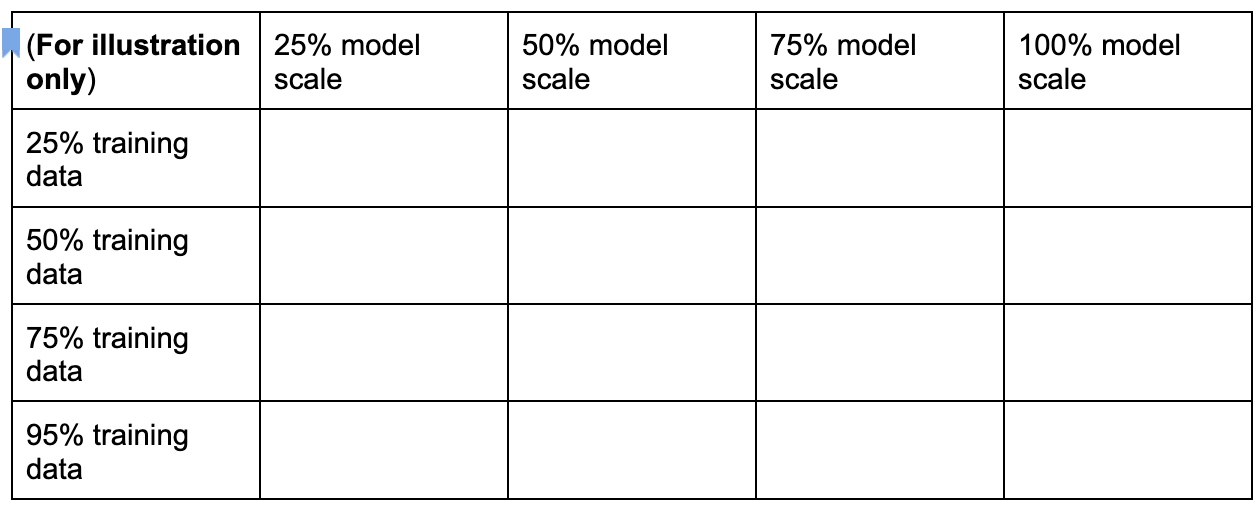
Les pourcentages ci-dessus ne sont définis qu'à titre indicatif et sous forme d'exemple. En pratique, vous pouvez choisir n'importe quelle valeur.
Notez que nous n'avons pas inclus la dimension des étapes d'entraînement dans l'espace de recherche ci-dessus. En effet, l'outil de recherche de tâche de proxy détermine l'étape d'entraînement optimale en fonction d'un choix de tâche de proxy.
Envisagez un choix de tâche de proxy de [50% training data, 25% model scale]. Définissez le même nombre d'étapes d'entraînement que pour un entraînement de référence complet.
Lors de l'évaluation de cette tâche de proxy, l'outil de recherche de tâche de proxy lance l'entraînement pour les modèles correlation-candidate, surveille leurs scores de justesse actuels puis calcule en continu le score de corrélation des classements (en utilisant les précédents scores d'entraînement complets pour les modèles de référence) :
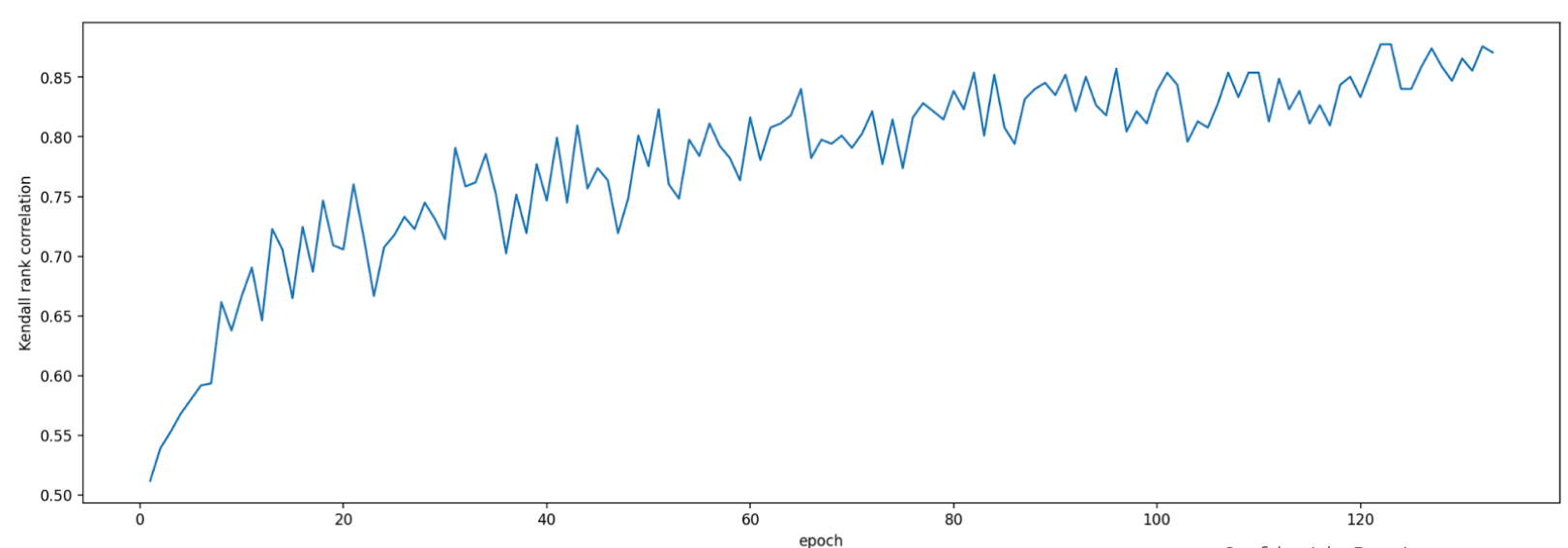
Ainsi, l'outil de recherche de tâche de proxy peut arrêter l'entraînement de tâche de proxy une fois la corrélation souhaitée (par exemple, 0,65) obtenue, ou peut s'arrêter prématurément si le quota de coûts de recherche (par exemple, 3 heures par tâche de proxy) est dépassé. Par conséquent, vous n'avez pas besoin d'effectuer une recherche explicite sur les étapes d'entraînement. L'outil de recherche de tâche de proxy évalue chaque tâche de proxy depuis votre espace de recherche privé à la manière d'une recherche par quadrillage et vous offre la meilleure option.
Vous trouverez ci-dessous un exemple de définition d'espace de recherche de tâche de proxy MnasNet mnasnet_proxy_task_config_generator, défini dans le fichier proxy_task/proxy_task_search_spaces.py, qui vous montrera comment définir votre propre espace de recherche :
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
Dans cet exemple, nous créons un espace de recherche simple sur les valeurs training-data-percent 25, 50, 75 et 95 (notez que les données d'entraînement à 100 % ne sont pas utilisées pour stage1-search).
La fonction mnasnet_proxy_task_config_generator prend un modèle de référence commun pour les arguments Docker d'entraînement, puis modifie ces arguments pour chaque taille de données d'entraînement souhaitée pour la tâche de proxy. Il renvoie ensuite une liste de proxy-task-config, qui seront traitées une par une ultérieurement par l'outil de recherche de tâche de proxy, dans le même ordre. Chaque configuration de tâche de proxy possède un name et un docker_args_map, qui sont un mappage clé-valeur pour les arguments Docker de la tâche de proxy.
Vous êtes libre de mettre en œuvre votre propre définition d'espace de recherche en fonction de vos propres exigences, et de concevoir vos propres espaces de recherche de tâche de proxy, même pour des valeurs autres que les deux dimensions de données d'entraînement réduites ou d'échelle de modèle réduite. Toutefois, il n'est pas recommandé de rechercher explicitement les étapes d'entraînement, car cela implique un gaspillage répété de puissance de calcul. Laissez l'outil de recherche de tâche de proxy gérer cette dimension pour vous.
Pour votre première recherche de tâche de proxy, vous pouvez essayer de ne réduire que les données d'entraînement (comme dans l'exemple MnasNet) et ignorer la mise à l'échelle réduite du modèle, car la mise à l'échelle du modèle peut impliquer plusieurs paramètres au niveau de image-size, num-filters ou num-blocks.
Dans la plupart des cas, les données d'entraînement réduites (et la recherche implicite sur les étapes d'entraînement réduites) suffisent à trouver une tâche de proxy appropriée.
Définissez le nombre d'étapes d'entraînement sur le nombre utilisé pour l'entraînement de référence complet.
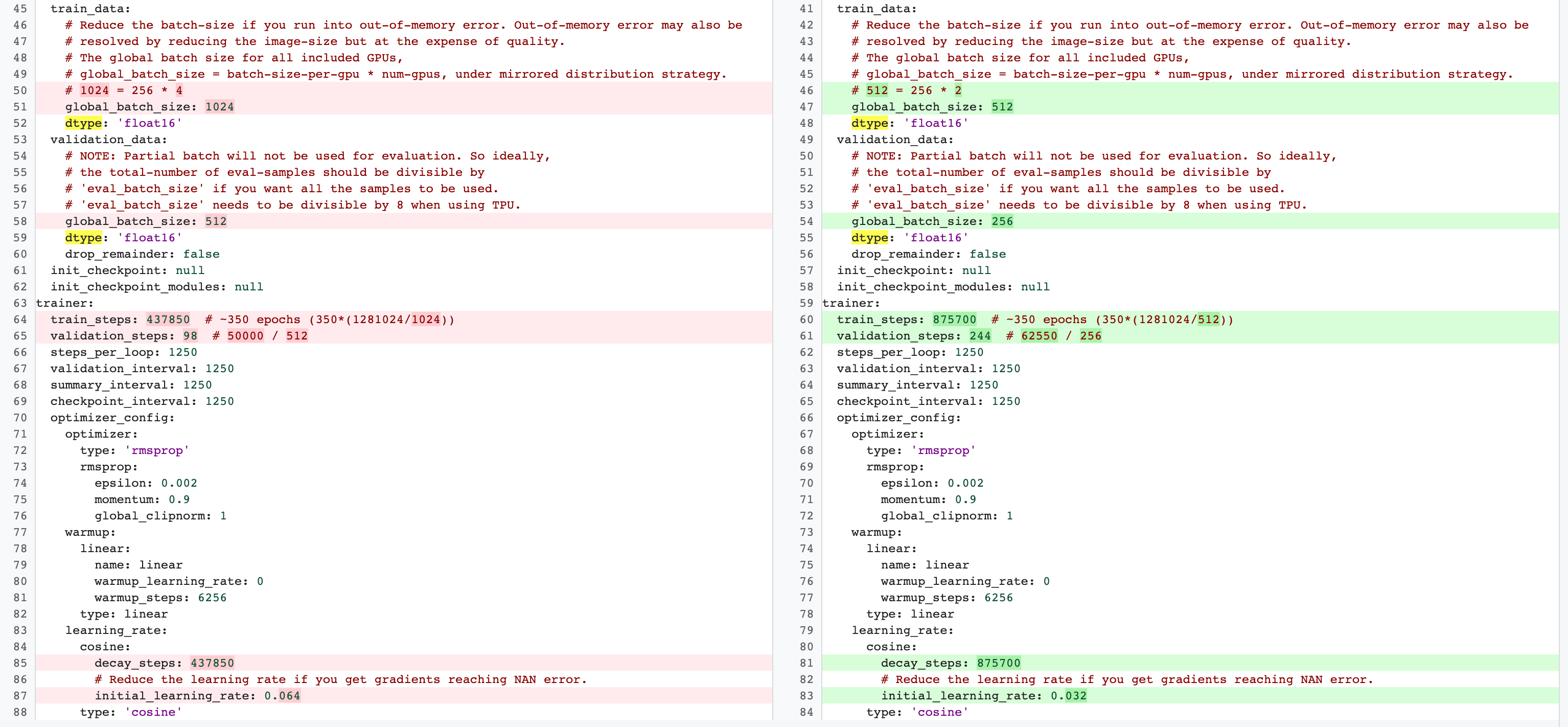
Il existe des différences entre les configurations d'entraînement complet de phase 2 et les configurations d'entraînement de tâche de proxy de phase 1. Pour la tâche de proxy, vous devez réduire la valeur batch-size par rapport à la configuration d'entraînement de référence complète pour n'utiliser que deux GPU ou quatre GPU.
En règle générale, l'entraînement complet utilise quatre GPU, huit GPU ou plus, mais la tâche de proxy n'utilise que deux GPU ou quatre GPU.
Une autre différence réside dans la division des ensembles d'entraînement et de validation.
Voici un exemple de modifications de la configuration MnasNet passant de quatre GPU pour l'entraînement complet de phase 2 à deux GPU avec une division de validation différente pour la recherche de tâche de proxy :
Lancez le job du contrôleur de recherche de tâche de proxy en exécutant la commande suivante (vous devez disposer d'un compte de service) :
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Une fois que vous avez lancé ce job du contrôleur de recherche de tâche de proxy, vous recevez un lien de job. Le nom du job commence par le préfixe Search_controller_. Voici un exemple d'interface utilisateur de job :
Le fichier search_controller_dir contiendra toutes les sorties et vous pourrez vérifier les journaux en cliquant sur le lien View logs.
Par défaut, ce job utilise un processeur sur le cloud pour s'exécuter en arrière-plan en tant que job personnalisé, puis lance et gère des jobs NAS enfants pour chaque tâche d'évaluation de proxy.
Chaque job NAS proxy-task porte un nom tel que ProxyTask_<your-job-name>_<proxy-task-name>, où <proxy-task-name> est le nom fourni par votre module de générateur de configuration de tâche de proxy pour chaque tâche de proxy. Une seule évaluation de tâche de proxy s'exécute à la fois.
Vous pouvez également exécuter la commande suivante :
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Cette commande affiche un résumé de toutes les évaluations de tâche de proxy, ainsi que l'état actuel du job search-controller (recherche de contrôleur), le nom du job et les liens pour chaque évaluation :
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
Le proxy_tasks_map stocke la sortie pour chaque évaluation de tâche de proxy et best_proxy_task_name enregistre la meilleure tâche de proxy pour la recherche. Chaque entrée proxy-task dispose de données supplémentaires telles que proxy_task_stats, qui enregistre la progression de la corrélation de justesse, ses valeurs p, sa justesse moyenne et sa durée moyenne d'entraînement au cours des étapes d'entraînement. Elle enregistre également la corrélation liée à la latence, le cas échéant, et enregistre le motif d'arrêt de ce job (tel que le délai d'entraînement dépassé) et l'étape d'entraînement à laquelle elle s'arrête. Vous pouvez également afficher ces statistiques sous forme de tracés en copiant le contenu du search_controller_dir dans votre dossier local en exécutant la commande suivante :
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
et inspecter les images de tracé. Par exemple, le graphique suivant montre la corrélation de justesse contre temps d'entraînement pour la meilleure tâche de proxy :
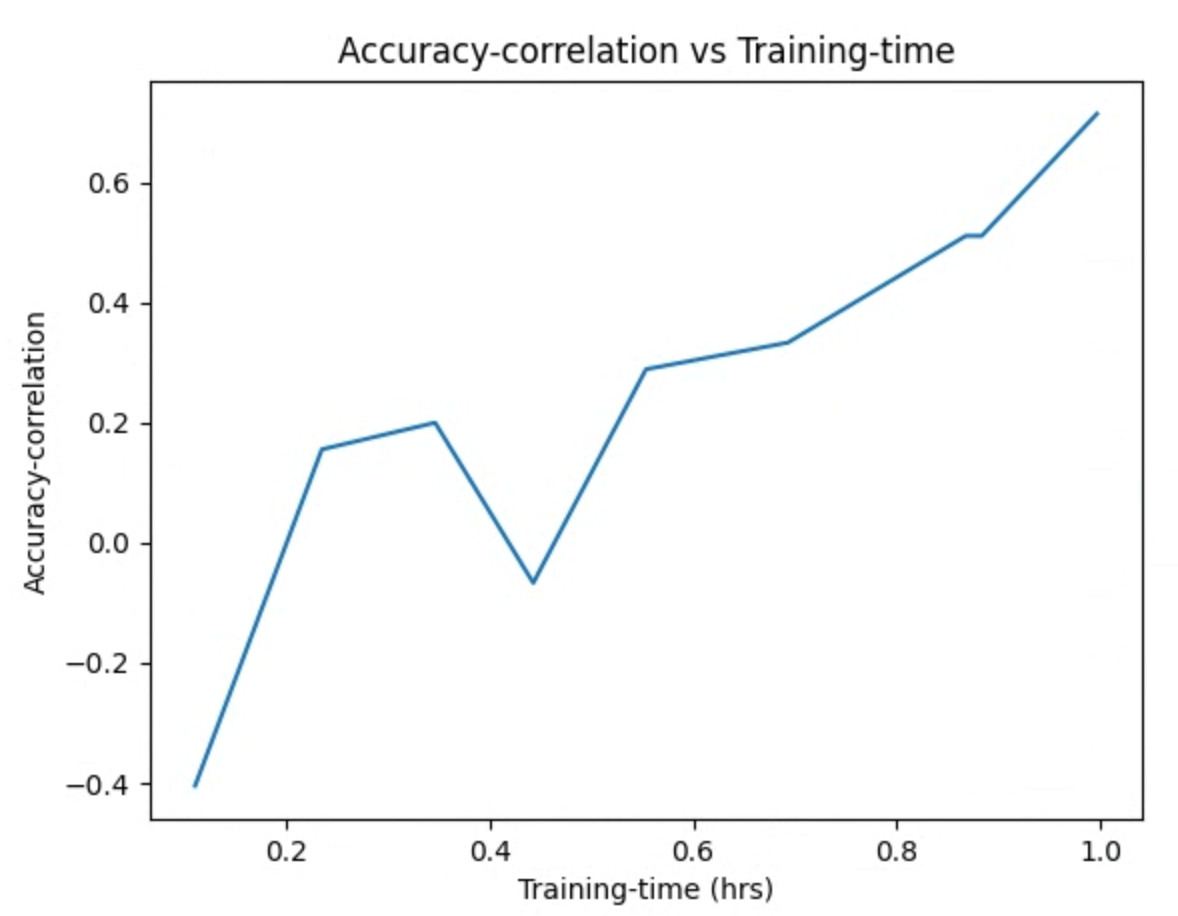
Votre recherche est terminée et vous avez trouvé la meilleure configuration de tâche de proxy. Vous devez procéder comme suit :
- Définir le nombre d'étapes d'entraînement sur le
final_training_stepsde la tâche de proxy la plus performante. - Définir les étapes de décroissance cosinus identiques à
final_training_stepspour que le taux d'apprentissage devienne presque égal à zéro vers la fin. - [Facultatif] Effectuer une évaluation des scores de validation à la fin de l'entraînement, ce qui permet de réduire les coûts associés aux évaluations multiples.
Utiliser un appareil sur site avec latence pour la recherche de tâche de proxy
Pour utiliser un appareil sur site avec latence pour la recherche de tâche de proxy, exécutez la commande search_proxy_task sans les options latency docker et latency-docker, car vous n'avez pas intérêt à lancer le docker de latence sur Google Cloud. Exécutez ensuite la commande run_latency_calculator_local décrite dans le tutoriel 4 pour lancer le job de simulateur de latence sur site. Au lieu de transmettre l'option --search_job_id, transmettez l'option --controller_job_id avec l'ID numérique du job de recherche de tâche de proxy que vous avez obtenu après l'exécution de la commande search_proxy_task.
Relancer le job du contrôleur de recherche de tâche de proxy
Les situations suivantes nécessitent de relancer le job du contrôleur de recherche de tâche de proxy :
- Le job parent du contrôleur de recherche de tâche de proxy s'arrête (cas rare).
- Vous annulez accidentellement le job du contrôleur de recherche de tâche de proxy.
- Vous souhaitez étendre votre espace de recherche de tâche de proxy ultérieurement (même après plusieurs jours).
Tout d'abord, n'annulez pas le job d'itération enfant de NAS (onglet NAS) s'il est déjà en cours d'exécution. Ensuite, pour relancer le job parent du contrôleur de recherche de tâche de proxy, exécutez la commande search_proxy_task comme auparavant, mais transmettez cette fois l'option --previous_proxy_task_search_dir et définissez-la sur le répertoire de sortie correspondant au précédent job du contrôleur de recherche de tâche de proxy. Le job du contrôleur de recherche de tâche de proxy relancé charge son état précédent depuis le répertoire et continue de fonctionner comme auparavant.
Dernières vérifications
Deux vérifications finales pour votre tâche de proxy incluent la plage de récompenses et l'enregistrement des données pour l'analyse post-recherche.
Plage de récompenses
La récompense signalée au contrôleur doit être comprise dans la plage [1e-3, 10]. Si ce n'est pas le cas, vous pouvez augmenter artificiellement la récompense afin d'atteindre cet objectif.
Enregistrer des données pour l'analyse après la recherche
Le code de votre tâche de proxy doit enregistrer toutes les métriques et données supplémentaires dans l'emplacement de stockage cloud, ce qui peut s'avérer utile pour analyser ultérieurement votre espace de recherche. Notre plate-forme Neural Architecture Search n'accepte que jusqu'à cinq valeurs à virgule flottante other_metrics à enregistrer.
Toute métrique supplémentaire doit être enregistrée dans l'emplacement de stockage cloud pour une analyse ultérieure.