Configurez un environnement avant de lancer un test Vertex AI Neural Architecture Search en suivant les sections ci-dessous.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Update and install
gcloudcomponents:gcloud components update
gcloud components install beta -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Update and install
gcloudcomponents:gcloud components update
gcloud components install beta - Pour accorder à tous les utilisateurs de Neural Architecture Search le rôle Utilisateur de Vertex AI (
roles/aiplatform.user), contactez votre administrateur de projet. - Installez Docker.
Si vous utilisez un système d'exploitation Linux, tel qu'Ubuntu ou Debian, ajoutez votre nom d'utilisateur au groupe
dockerafin de pouvoir exécuter Docker sans utilisersudo:sudo usermod -a -G docker ${USER}Une fois que vous vous serez ajouté au groupe
docker, vous devrez peut-être redémarrer votre système. - Ouvrez Docker. Pour vérifier que Docker est en cours d'exécution, exécutez la commande Docker suivante, qui renvoie la date et l'heure actuelles :
docker run busybox date
- Utilisez
gcloudcomme assistant d'identification pour Docker :gcloud auth configure-docker
- Facultatif : Si vous souhaitez exécuter le conteneur à l'aide d'un GPU en local, installez
nvidia-docker.
Configurer un bucket Cloud Storage
Vous trouverez dans cette section la procédure à suivre pour créer un bucket. Vous pouvez utiliser un bucket existant, mais il doit se trouver dans la même région que celle où vous exécutez des tâches AI Platform. En outre, s'il ne fait pas partie du projet que vous utilisez pour exécuter Neural Architecture Search, vous devez explicitement accorder l'accès aux comptes de service Neural Architecture Search.
-
Indiquez un nom pour votre nouveau bucket. Ce nom doit être unique par rapport à tous les buckets dans Cloud Storage.
BUCKET_NAME="YOUR_BUCKET_NAME"
Par exemple, vous pouvez utiliser le nom de votre projet en ajoutant
-vertexai-nas:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
Vérifiez le nom du bucket que vous avez créé.
echo $BUCKET_NAME
-
Sélectionnez une région pour votre bucket, puis définissez une variable d'environnement
REGION.Utilisez la même région que celle où vous prévoyez d'exécuter des tâches Neural Architecture Search.
Par exemple, le code suivant crée la variable
REGIONet la définit surus-central1:REGION=us-central1
-
Créez le bucket :
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
Demander un quota d'appareils supplémentaire pour le projet
Les tutoriels utilisent environ cinq machines à processeur et ne nécessitent aucun quota supplémentaire. Après avoir suivi les tutoriels, exécutez votre job Neural Architecture Search (recherche d'architecture neuronale).
Le job Neural Architecture Search entraîne un lot de modèles en parallèle. Chaque modèle entraîné correspond à un essai.
Lisez la section sur la définition de number-of-parallel-trials pour estimer la quantité de processeurs et de GPU nécessaire pour effectuer un job de recherche.
Par exemple, si chaque essai utilise deux GPU T4 et que vous définissez number-of-parallel-trials sur 20, vous avez besoin d'un quota total de 40 GPU T4 pour une tâche de recherche. En outre, si chaque essai utilise un processeur highmem-16, vous avez besoin de 16 unités de processeur par essai, soit 320 unités de processeur pour 20 essais parallèles.
Toutefois, nous demandons un quota minimal de 10 essais parallèles (ou de 20 GPU).
Le quota initial par défaut pour les GPU varie selon la région et le type de GPU. Il est généralement égal à 0, 6 ou 12 pour les Tesla_T4, et de 0 ou 6 pour les Tesla_V100. Le quota initial par défaut pour les processeurs varie selon les régions et est généralement de 20, 450 ou 2 200.
Facultatif : Si vous prévoyez d'exécuter plusieurs jobs de recherche en parallèle, effectuez le scaling des quotas requis en conséquence. Vous n'êtes pas facturé immédiatement à la demande de quota. Des frais vous sont facturés lorsque vous exécutez un job.
Si vous ne disposez pas d'un quota suffisant et que vous essayez de lancer un job qui nécessite plus de ressources que votre quota, le job ne se lance pas et génère une erreur semblable à ce qui suit :
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
Dans certains cas, si plusieurs tâches du même projet ont été démarrées en même temps et que le quota n'est pas suffisant pour toutes, l'une des tâches reste en file d'attente et ne commence pas l'entraînement. Dans ce cas, annulez le job mis en file d'attente et demandez plus de quota ou attendez la fin du job précédent.
Vous pouvez ensuite demander un quota d'appareils supplémentaire à partir de la page Quotas.
Vous pouvez également appliquer des filtres pour trouver le quota à modifier :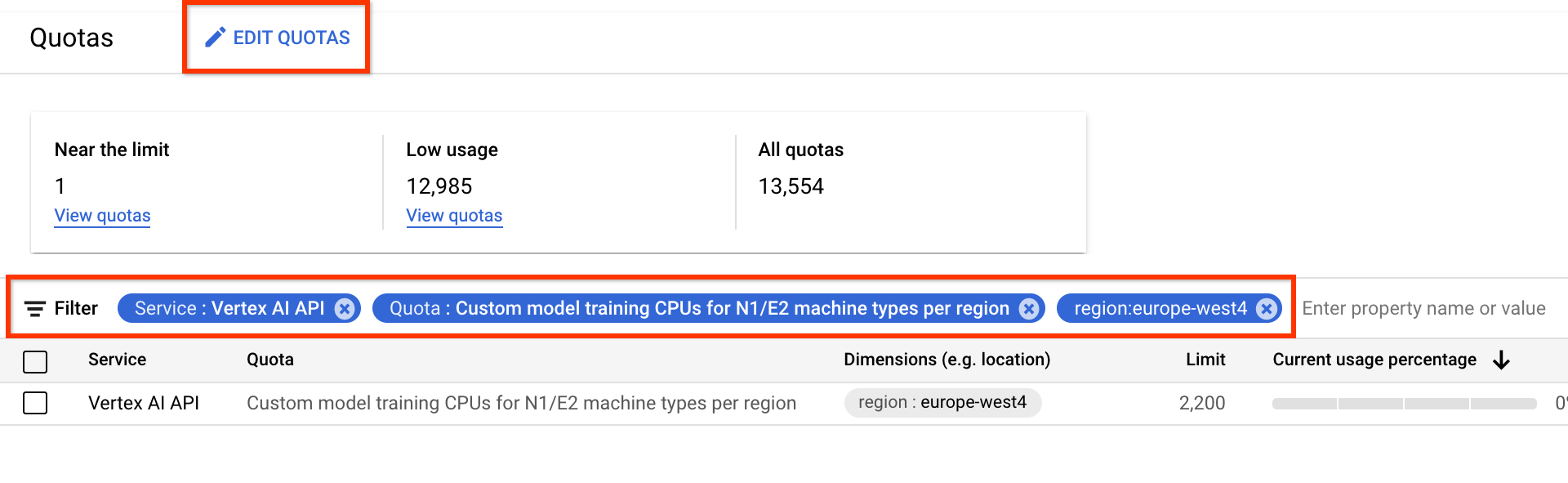
- Dans le champ Service, sélectionnez API Vertex AI.
- Dans le champ Région, sélectionnez la région dans laquelle vous souhaitez appliquer des filtres.
- Dans le champ Quota, sélectionnez un nom d'accélérateur dont le préfixe est Entraînement de modèle personnalisé.
- Pour les GPU V100, la valeur est définie sur GPU Nvidia V100 pour l'entraînement de modèles personnalisés par région.
- Pour les processeurs, la valeur peut être Processeurs pour l'entraînement de modèles personnalisés pour les types de machines N1/E2 par région. Le nombre de processeurs représente l'unité de processeur. Si vous voulez huit processeurs
highmem-16, envoyez une demande de quota pour 8 * 16 = 128 unités de processeur. Saisissez également la valeur souhaitée pour la région.
Une fois que vous avez créé une demande de quota, vous recevez un Case number ainsi que des e-mails de suivi de l'état de votre demande. L'approbation d'un quota de GPU peut prendre deux à cinq jours ouvrés. En général, l'obtention d'un quota d'environ 20 à 30 GPU est plus rapide et intervient dans un délai de deux à trois jours environ, et l'approbation d'environ 100 GPU peut prendre cinq jours ouvrés. L'approbation d'un quota de processeurs peut prendre jusqu'à deux jours ouvrés.
Toutefois, si une région connaît une pénurie importante d'un type de GPU, il n'y a aucune garantie d'approbation, même avec une demande de quota modeste.
Dans ce cas, il se peut qu'on vous demande de choisir une autre région ou un autre type de GPU. En général, les GPU T4 sont plus faciles à obtenir que les GPU V100. Les GPU T4 ont une durée d'exécution plus lente, mais sont plus rentables.
Pour plus d'informations, consultez la page Demander une limite de quota supérieure.
Configurer Artifact Registry pour votre projet
Vous devez configurer un dépôt Artifact Registry pour votre projet et la région dans laquelle vous transférez vos images Docker.
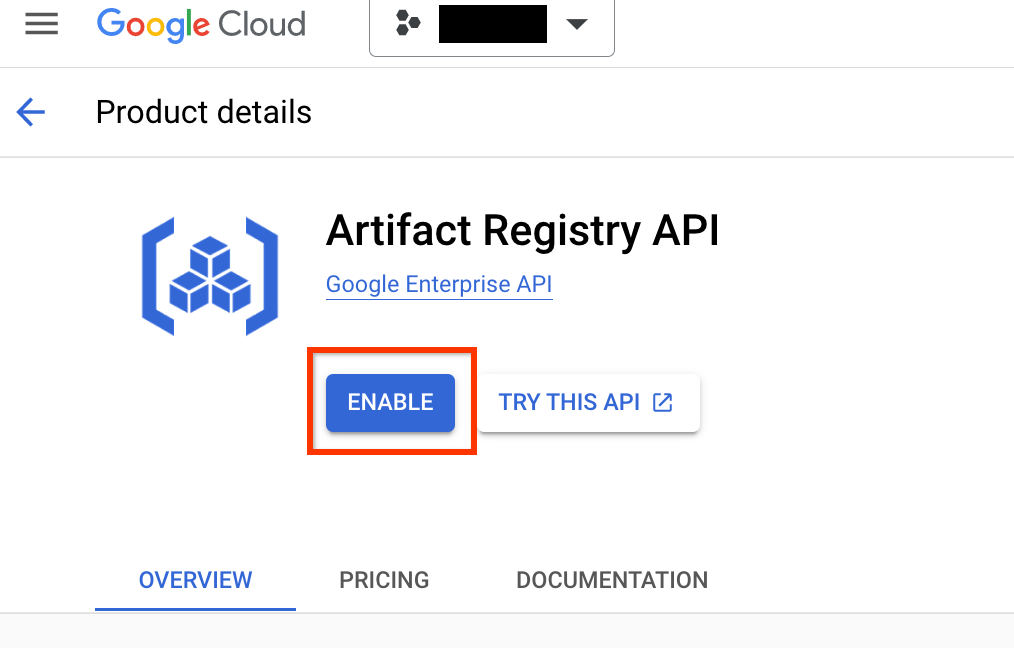
Accédez à la page Artifact Registry de votre projet. Si ce n'est pas déjà fait, commencez par activer l'API Artifact Registry pour votre projet :
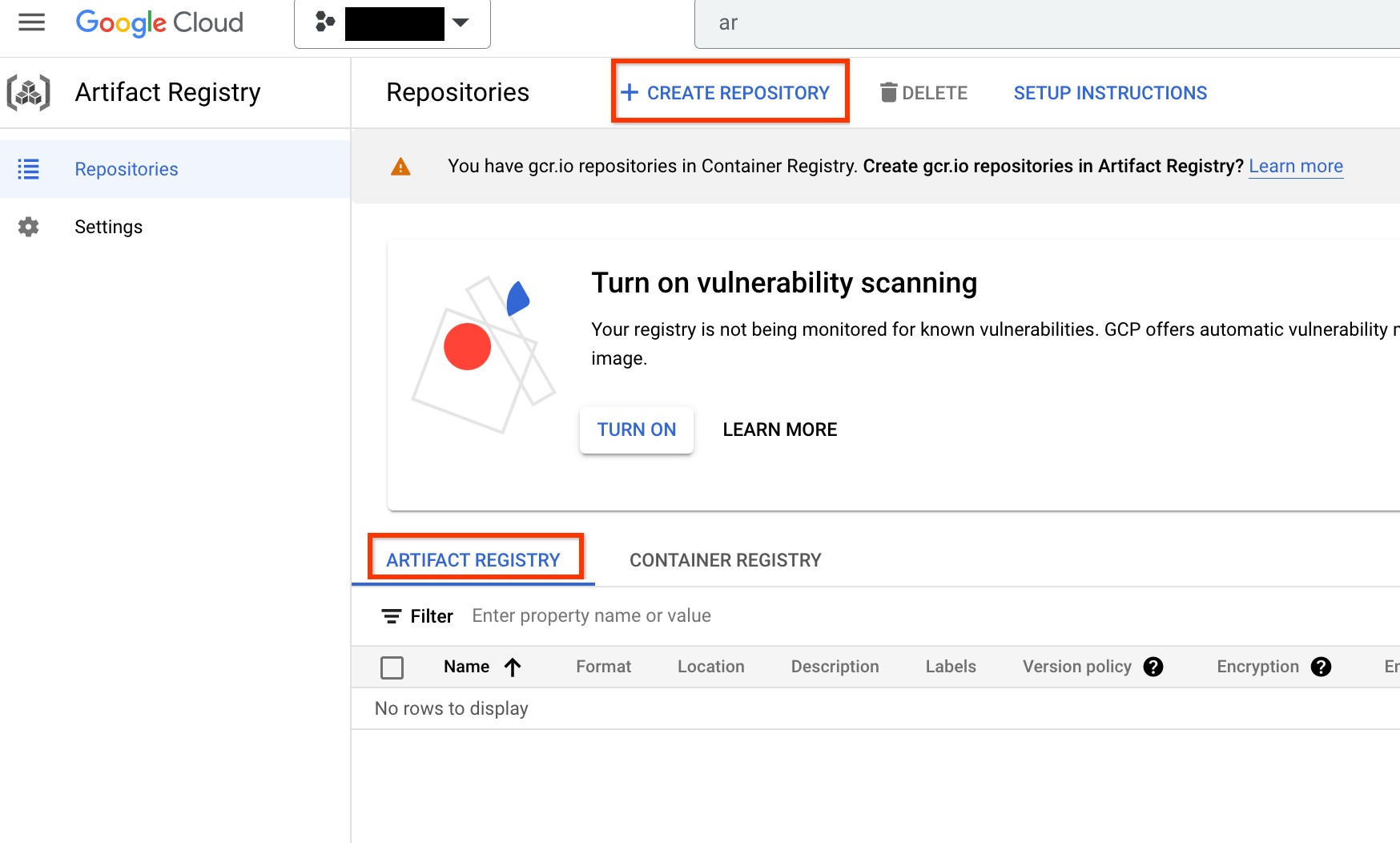
Une fois l'API activée, commencez par créer un dépôt en cliquant sur CRÉER UN DÉPÔT :
Définissez comme Nom la valeur nas, comme Format la valeur Docker et comme Type d'emplacement la valeur Région. Pour la Région, choisissez l'emplacement où vous exécutez vos tâches, puis cliquez sur CRÉER.
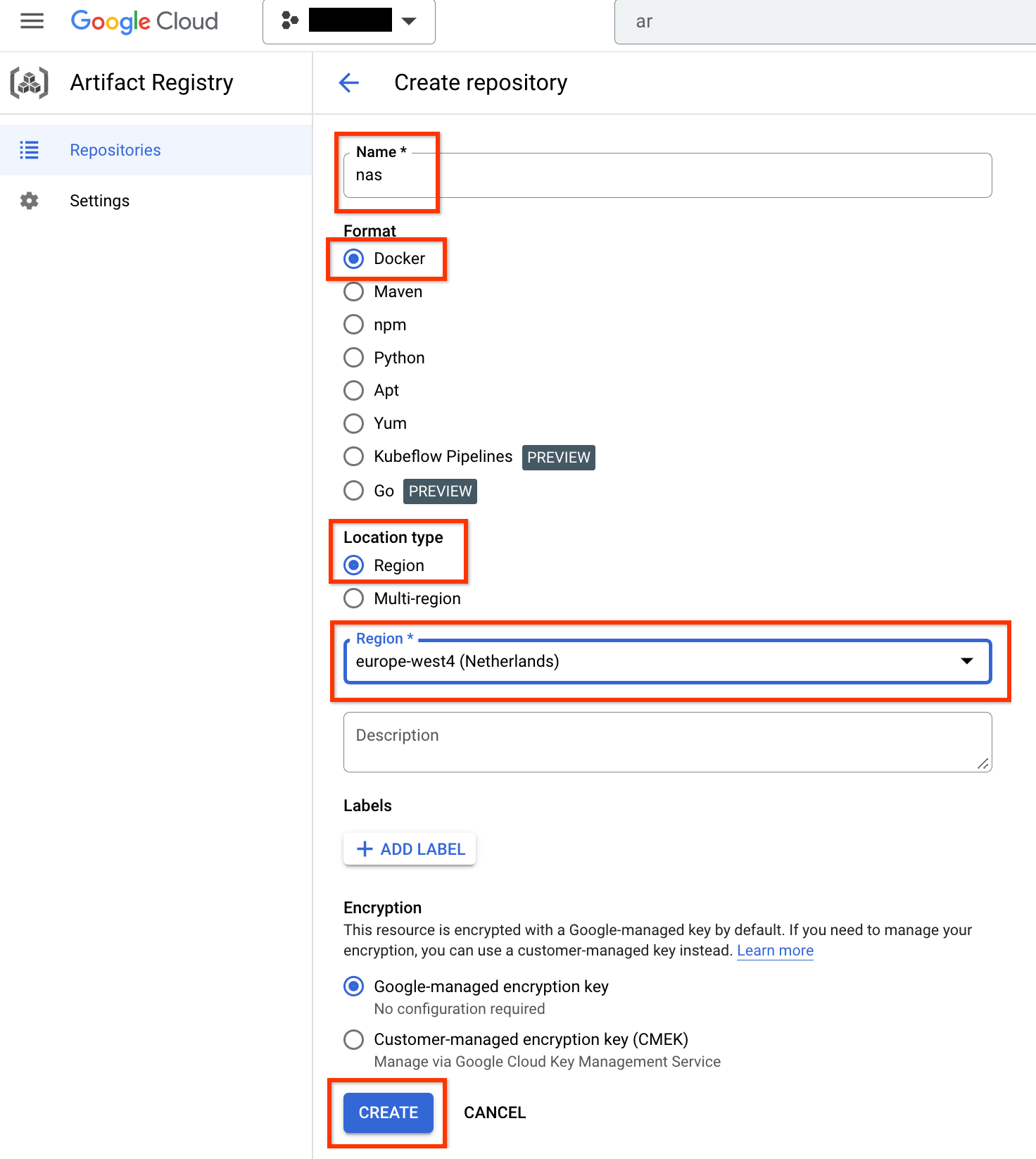
Cela doit créer le dépôt Docker souhaité comme indiqué ci-dessous :
Vous devez également configurer l'authentification pour transférer les images Docker vers ce dépôt. La section Configurer votre environnement local ci-dessous inclut cette étape.
Configurer votre environnement local
Vous pouvez exécuter ces étapes à l'aide du shell Bash dans votre environnement local ou les exécuter dans une instance de notebooks gérés par l'utilisateur Vertex AI Workbench.
Configurez les variables d'environnement de base :
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginConfigurez l'authentication Docker pour votre dépôt Artifact Registry :
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(Facultatif) Configurez un environnement virtuel Python 3. L'utilisation de Python 3 est recommandée, mais pas indispensable :
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activateInstallez des bibliothèques supplémentaires :
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0
Configurer un compte de service
Vous devez configurer un compte de service avant d'exécuter des tâches NAS. Vous pouvez exécuter ces étapes à l'aide du shell Bash dans votre environnement local ou les exécuter dans une instance de notebooks gérés par l'utilisateur Vertex AI Workbench.
Créez un compte de service :
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAMEAttribuez les rôles
aiplatform.useretstorage.objectAdminau compte de service à l'aide des commandes suivantes :gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdmin
Par exemple, les commandes suivantes créent un compte de service nommé my-nas-sa sous le projet my-nas-project avec les rôles aiplatform.user et storage.objectAdmin:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
Télécharger le code
Pour démarrer un test Neural Architecture Search, vous devez télécharger l'exemple de code Python, qui inclut des applications d'entraînement prédéfinies, des définitions d'espace de recherche et des bibliothèques clientes associées.
Pour télécharger le code source, procédez comme suit :
Ouvrez un nouveau terminal Shell.
Exécutez la commande "git clone" :
git clone https://github.com/google/vertex-ai-nas.git