Vertex AI Neural Architecture Search を使用すると、精度、レイテンシ、メモリ、これらの組み合わせ、またはカスタム指標の観点から、最適なニューラル アーキテクチャを検索できます。
Vertex AI Neural Architecture Search が最適なツールかどうかを判断する
- Vertex AI Neural Architecture Search は、レイテンシ、メモリ、カスタム指標などの制約の有無にかかわらず、精度の観点から最適なニューラル アーキテクチャを見つけるために使用されるハイエンドの最適化ツールです。可能なニューラル アーキテクチャの選択肢の検索スペースは、10^20 にもなり得ます。これは、Nasnet、MNasnet、EfficientNet、NAS FPN、SpineNet など、過去数年間で、複数の最先端のコンピュータ ビジョン モデルの生成に成功した技術に基づいています。
- Neural Architecture Search は、データを持ち込めばテストなしで良い結果が期待できるといったソリューションではありません。これはテストツールです。
- Neural Architecture Search は、学習率やオプティマイザーの設定の調整など、ハイパーパラメータの調整に対応していません。これはアーキテクチャ検索のみを目的としています。ハイパーパラメータの調整と Neural Architecture Search は組み合わせるべきではありません。
- トレーニング データが限られている場合や、一部のクラスが非常にまれである著しく不均衡なデータセットの場合、アーキテクチャ検索はおすすめしません。データ不足のため、ベースライン トレーニングですでに大量の拡張を行っている場合、Neural Architecture Search はおすすめしません。
- まず、従来の ML の手法やテクニック(ハイパーパラメータ調整など)をお試しください。Neural Architecture Search は、このような従来の手法では効果が見られない場合にのみ使用してください。
- アーキテクチャ パラメータの変更や試行に関する基本的な考えを持つ、モデル調整のための社内チームを設置する必要があります。これらのアーキテクチャ パラメータには、カーネルサイズ、チャネル数、接続数など、多くの可能性が含まれます。探索する検索スペースが決まっている場合、Neural Architecture Search は非常に価値があり、最大 10^20 のアーキテクチャの選択肢という大規模な検索スペースを探索するために、エンジニアリング時間を少なくとも 6 か月短縮できます。
- Neural Architecture Search は、テストに数千ドルを費やすことができる企業のお客様を対象としています。
- Neural Architecture Search は、ビジョンのみのユースケースに限定されません。現在は、ビジョンベースのビルド済み検索スペースとトレーナーが提供されていますが、お客様が独自のビジョンなしの検索スペースとトレーナーを用意することもできます。
- Neural Architecture Search では、独自のデータを用意してそれをソリューションとするスーパーネット(ワンショット NAS または重み共有ベースの NAS)の手法は使用しません。スーパーネットをカスタマイズするのは簡単ではありません(数か月かかります)。スーパーネットとは異なり、Neural Architecture Search は、カスタム検索スペースと報酬を定義するために高度にカスタマイズできます。カスタマイズは、約 1~2 日で行えます。
- Neural Architecture Search は、世界中の 8 リージョンでサポートされています。利用可能なリージョンをご確認ください。
Neural Architecture Search を使用する前に、予想される費用、結果の増加、GPU 割り当ての要件に関する次のセクションもご覧ください。
予想される費用、結果の増加、GPU 割り当ての要件
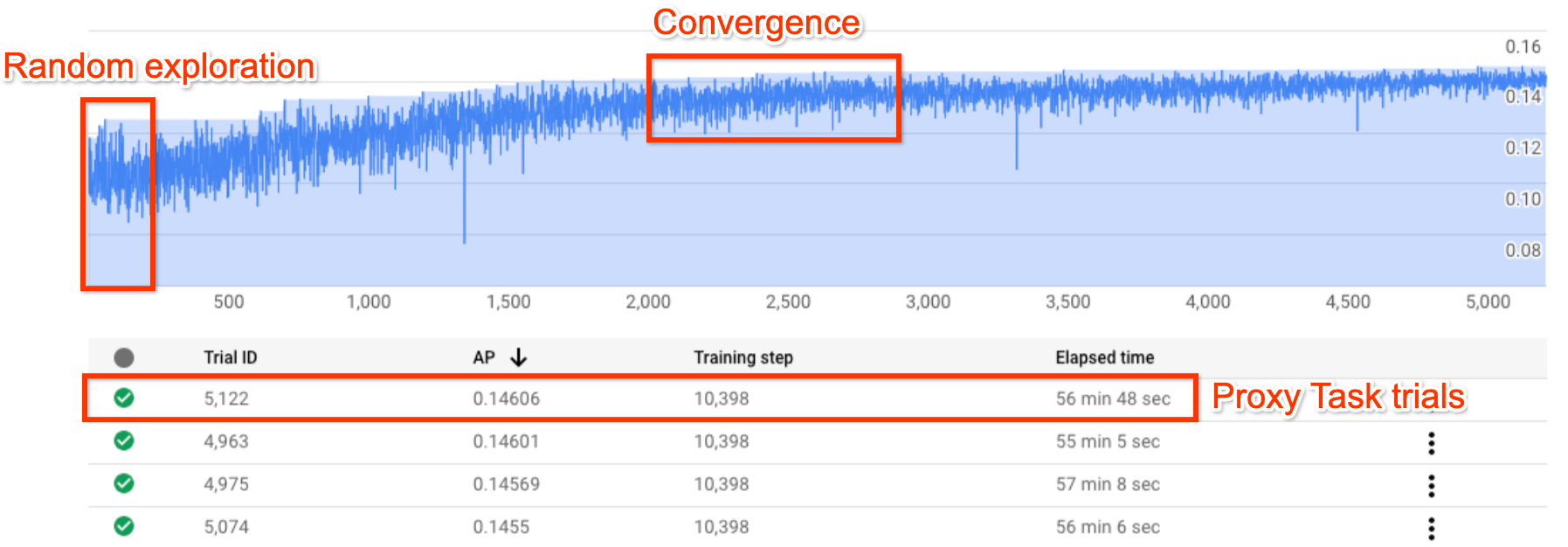
上の図は、Neural Architecture Search 曲線を示しています。Y-axis は試行報酬、X-axis は試行回数を示します。トライアル数を増やすと、コントローラはより優れたモデルの検出を開始します。そのため、報酬が増加し始め、その後報酬の分散と報酬の増加が縮小し始め、収束を示します。収束点では、試行回数は検索スペースのサイズによって異なりますが、約 2,000 回程度です。各試行は、プロキシタスクと呼ばれる小規模なトレーニング バージョンとして、2 つの Nvidia V100 GPU で約 1~2 時間実行するように設計されています。お客様は、任意の時点で検索を手動で停止することが可能で、収束点が生じる前に、ベースラインと比較してより高い報酬モデルを見つけることができます。より良い結果を選択するには、収束点に達するまで待つことをおすすめします。検索後、次の段階では、上位 10 件の試行(モデル)を選び、それに対して完全なトレーニングを実行します。
(省略可)事前構築済みの MNasNet 検索空間とトレーナーをテストする
このモードでは、検索曲線かいくつかの試行(約 25 回)を観察し、事前構築済みの MNasNet 検索スペースとトレーナーを使用してテスト運用を行います。
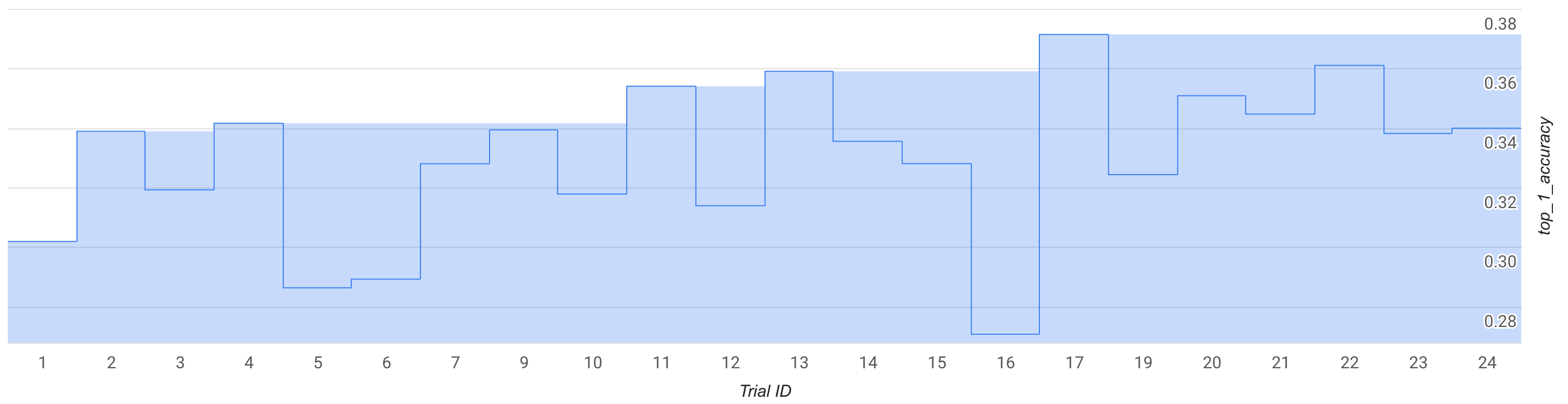
図では、ステージ 1 の最高報酬が、トライアル 1 の約 0.30 から、トライアル 17 の約 0.37 に上昇しています。サンプリングのランダム性により、正確な動作は多少異なる場合がありますが、最高報酬では多少の増加が確認できるはずです。これは小さいテストであり、概念実証や公的なベンチマーク検証を表すものではありません。
この実行に対する費用の詳細は次のとおりです。
- ステージ 1:
- 試行回数: 25
- 1 試行あたりの GPU 数: 2
- GPU タイプ: TESLA_T4
- 1 試行あたりの CPU 数: 1
- CPU タイプ: n1-highmem-16
- トレーニングの試行 1 回の平均時間: 3 時間
- 並列試行数: 6
- 使用される GPU 割り当て: (1 試行あたりの GPU 数 × 並列試行数)= 12 GPU試行には us-central1 リージョンを使用し、同じリージョンにトレーニング データを配置します。追加の割り当ては必要ありません。
- 実行時間: (試行回数 × 1 試行あたりのトレーニング時間)÷(並列試行数)= 12 時間
- GPU 時間: (試行回数 × 1 試行あたりのトレーニング時間 × 1 試行あたりの GPU 数)= 150 T4 GPU 時間
- CPU 時間: (試行回数 * 1 試行あたりのトレーニング時間 * 1 試行あたりの CPU 数)= 75 n1-highmem-16 時間
- 費用: 約 $185ジョブは、早期に停止して費用を削減できます。正確な料金を計算するには、料金ページをご覧ください。
これは小さいテストであるため、ステージ 1 のモデルに対して完全なステージ 2 トレーニングを実行する必要はありません。ステージ 2 の実行の詳細については、チュートリアル 3 をご覧ください。
この実行には、MnasNet ノートブックが使用されます。
(省略可)事前構築済みの MNasNet 検索スペースとトレーナーの概念実証(POC)実行
公開された MNasnet の結果をほぼ再現する場合は、このモードを使用できます。この論文によると、MnasNet は Google Pixel で 78 ミリ秒のレイテンシで 75.2% のトップ 1 の精度を達成しています。これは MobileNetV2 の 1.8 倍の速さで 0.5% 高い精度、NASNet の 2.3 倍の速さで 1.2% 高い精度となっています。ただし、この例では、トレーニングに TPU ではなく GPU を使用し、レイテンシの評価に cloud-CPU(n1-highmem-8)を使用します。この例では、MNasNet で予想されるステージ 2 のトップ 1 精度は 75.2%、cloud-CPU(n1-highmem-8)で 50 ミリ秒のレイテンシになります。
この実行に対する費用の詳細は次のとおりです。
ステージ 1 の検索:
- 試行回数: 2,000
- 1 試行あたりの GPU 数: 2
- GPU タイプ: TESLA_T4
- トレーニングの試行 1 回の平均時間: 3 時間
- 並列試行数: 10
- 使用される GPU 割り当て: (1 試行あたりの GPU 数 × 並列試行数)= 20 T4 GPUこの数はデフォルトの割り当てを超えているため、プロジェクト UI から割り当てリクエストを作成します。詳細については、setting_up_path をご覧ください。
- 実行時間: (試行回数 * 1 試行あたりのトレーニング時間)÷(並列試行数)÷ 24 = 25 日注: ジョブは 14 日後に終了します。その後 14 日間は、1 つのコマンドで簡単に検索ジョブを再開できます。GPU 割り当てが大きくなるほど、それに比例して実行時間は減少します。
- GPU 時間: (試行回数 × 1 試行あたりのトレーニング時間 × 1 試行あたりの GPU 数)= 12,000 T4 GPU 時間
- 費用: 約 $15,000
ステージ 2 は、上位 10 個のモデルでフルトレーニングを実施:
- 試行回数: 10
- 1 試行あたりの GPU 数: 4
- GPU タイプ: TESLA_T4
- トレーニングの試行 1 回の平均時間: 約 9 日
- 並列試行数: 10
- 使用される GPU 割り当て: (1 試行あたりの GPU 数 × 並列試行数)= 40 T4 GPUこの数はデフォルトの割り当てを超えているため、プロジェクト UI から割り当てリクエストを作成します。詳細については、setting_up_path をご覧ください。また、10 個すべてを並列に実行するのではなく 5 個のモデルでジョブを 2 回実行することで、20 個の T4 GPU でこれを実行することもできます。
- 実行時間: (試行回数 × 1 試行あたりのトレーニング時間)÷(並列試行数)÷ 24 = 約 9 日
- GPU 時間: (試行回数 × 1 試行あたりのトレーニング時間 × 1 試行あたりの GPU 数)= 8,960 T4 GPU 時間
- 費用: 約 $8,000
総費用: 約 $23,000。正確な料金を計算するには、料金ページをご覧ください。注: この例は、平均的な通常のトレーニング ジョブではありません。フル トレーニングは、4 個の TESLA_T4 GPU で約 9 日間実行されます。
この実行には、MnasNet ノートブックが使用されます。
検索スペースとトレーナーの使用
平均的なカスタム ユーザーのおおよその費用を提示します。お客様のニーズは、トレーニング タスク、使用する GPU と CPU によって異なります。こちらで説明するように、エンドツーエンドの実行には少なくとも 20 GPU の割り当てが必要です。注: パフォーマンスの向上は完全にタスクに依存します。パフォーマンス向上の参考例としては、MNasnet のような例しか提供できません。
この仮定のカスタム実行にかかる費用は次のとおりです。
ステージ 1 の検索:
- 試行回数: 2,000
- 1 試行あたりの GPU 数: 2
- GPU タイプ: TESLA_T4
- トレーニングの試行 1 回の平均時間: 1.5 時間
- 並列試行数: 10
- 使用される GPU 割り当て: (1 試行あたりの GPU 数 × 並列試行数)= 20 T4 GPUこの数はデフォルトの割り当てを超えているため、プロジェクト UI から割り当てリクエストを作成する必要があります。詳しくは、プロジェクトの追加のデバイス割り当てをリクエストするをご覧ください。
- 実行時間: (試行回数 * 1 試行あたりのトレーニング時間)÷(並列試行数)÷ 24 = 12.5 日
- GPU 時間: (試行回数 × 1 試行あたりのトレーニング時間 × 1 試行あたりの GPU 数)= 6,000 T4 GPU 時間
- 費用: 約 $7,400
ステージ 2 は、上位 10 個のモデルでフルトレーニングを実施:
- 試行回数: 10
- 1 試行あたりの GPU 数: 2
- GPU タイプ: TESLA_T4
- トレーニングの試行 1 回の平均時間: 約 4 日
- 並列試行数: 10
- 使用される GPU 割り当て: (1 試行あたりの GPU 数 × 並列試行数)= 20 T4 GPU**この数はデフォルトの割り当てを超えているため、プロジェクト UI から割り当てリクエストを作成する必要があります。詳しくは、プロジェクトの追加のデバイス割り当てをリクエストするをご覧ください。カスタム割り当てのニーズについては、同ドキュメントをご覧ください。
- 実行時間: (試行回数 × 1 試行あたりのトレーニング時間)÷(並列試行数)÷ 24 = 約 4 日
- GPU 時間: (試行回数 × 1 試行あたりのトレーニング時間 × 1 試行あたりの GPU 数)= 1,920 T4 GPU 時間
- 費用: 約 $2,400
プロキシタスクの設計コストの詳細については、プロキシタスクの設計をご覧ください。この費用は、12 モデルのトレーニングに類似しています(図のステージ 2 では 10 モデルを使用しています)。
- 使用される GPU 割り当て: 図のステージ 2 の実行と同じ。
- 費用: (12 / 10)× 10 モデル分のステージ 2 の費用 = 約 $2,880
総費用: 約 $12,680。正確な料金を計算するには、料金ページをご覧ください。
このステージ 1 の検索費用は、収束点に達するまで検索を行い、最大のパフォーマンスを得るためのものです。しかし、検索が収束するまで待たないでください。検索・報酬曲線が成長し始めると、これまでのベストモデルでステージ 2 のフルトレーニングを実行することで、より低コストでより小さいパフォーマンス向上が期待できます。たとえば、前に示した検索プロットの場合、収束までの試行回数が 2,000 件に達するまで待たないでください。より良いモデルは、700 回や 1,200 回の試行で見つけることができ、それらに対してステージ 2 のフルトレーニングも実施できます。費用を抑えるため、検索はいつでも停止できます。検索の実行中にステージ 2 のフルトレーニングも並行して実行できますが、余分な並列ジョブをサポートするための GPU 割り当てがあることを確認してください。
パフォーマンスと費用の概要
次の表は、さまざまなユースケースと、関連するパフォーマンスとコストを含むいくつかのデータポイントをまとめたものです。
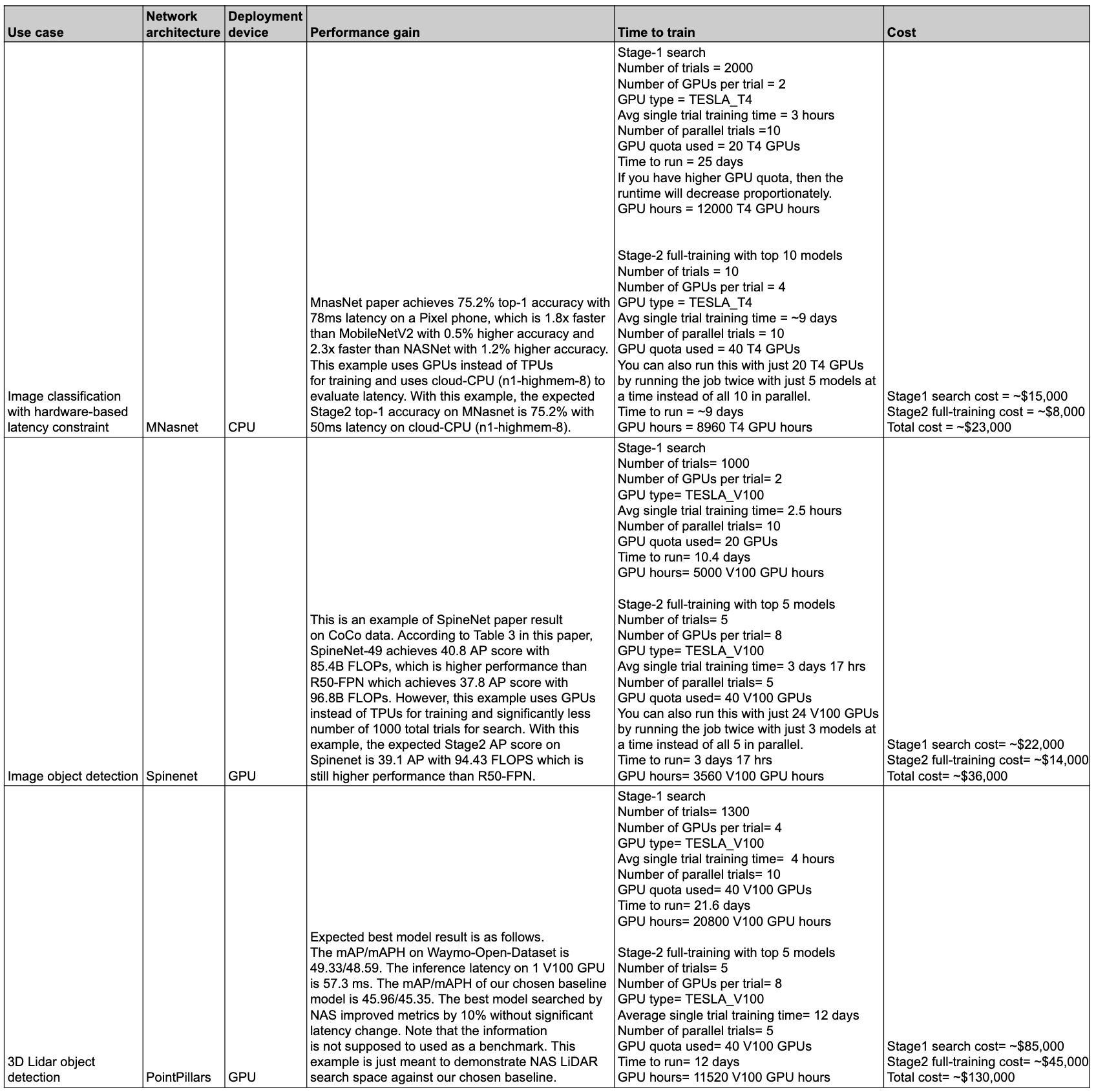
ユースケースと機能
Neural Architecture Search は柔軟性が高く、使いやすい機能です。初めて使用する場合でも、追加の設定なしで、事前構築済みの検索スペース、トレーナー、ノートブックを使用して、データセットの Vertex AI Neural Architecture Search を開始できます。また、エキスパート ユーザーは、カスタム トレーナー、カスタム検索スペース、カスタム推論デバイスを使用して Neural Architecture Search を利用できます。また、ビジョン以外のユースケースにもアーキテクチャ検索を拡張できます。
Neural Architecture Search には、次のユースケース向けに GPU で実行されるビルド済みトレーナーと検索スペースが用意されています。
- ノートブックに公開された一般公開のデータセット ベースの結果を含む Tensorflow トレーナー
- チュートリアルのサンプルとしてのみ使用される PyTorch トレーナー
- PyTorch の 3D 医療画像セグメンテーション検索空間の例
- PyTorch ベースの MNasNet 分類
- レイテンシとメモリの制約のある、ターゲット デバイスを対象とした検索
- コードを含む、追加の Tensorflow ベースの最先端のビルド済み検索スペース
- モデルのスケーリング
- データの拡張
Neural Architecture Search が提供する機能の完全なセットは、カスタマイズされたアーキテクチャとユースケースにも簡単に使用できます。
- 可能なニューラル アーキテクチャでカスタム検索スペースを定義し、この検索スペースをカスタム トレーナー コードと統合する Neural Architecture Search 言語。
- コードを含む、すぐに利用できる最先端の検索スペース。
- コードを含む、すぐに使用できる事前構築済みのトレーナー。TPU / GPU で実行されます。
- 以下を含むアーキテクチャ検索のマネージド サービス:
- 検索スペースをサンプリングして最適なアーキテクチャを検索する Neural Architecture Search コントローラ。
- コードを含む事前構築済みの Docker / ライブラリ。カスタム ハードウェアのレイテンシ / FLOP / メモリの計算を行います。
- NAS の使い方を説明するチュートリアル。
- プロキシタスクを設計するための一連のツール。
- Vertex AI を使用した効率的な PyTorch トレーニングのガイダンスと例。
- カスタム指標のレポートと分析に対するライブラリ サポート。
- ジョブのモニタリングと管理を行う Google Cloud Console UI。
- ノートブックを利用して簡単に検索を開始できます。
- プロジェクトまたはジョブレベルの粒度での GPU / CPU のリソース使用量管理に対するライブラリ サポート。
- Docker のビルド、NAS ジョブの起動、以前の検索ジョブの再開を行う Python ベースの Nas クライアント。
- Google Cloud コンソールの UI ベースのカスタマー サポート。
背景
Neural Architecture Search は、ニューラル ネットワークの設計を自動化する手法です。過去数年間で、次のような最先端のコンピュータ ビジョン モデルを実現しました。
これらのモデルは、コンピュータ ビジョンの問題の 3 つの主要なクラス(画像分類、オブジェクト検出、セグメンテーション)で最先端の方法を提供しています。
Neural Architecture Search を使用すると、1 回の試行で精度、レイテンシ、メモリをモデルに合わせて最適化できるため、モデルのデプロイに必要な時間を短縮できます。Neural Architecture Search は、さまざまな種類のモデルを探索します。コントローラは ML モデルを提案し、モデルのトレーニングと評価を行います。これを 1,000 回以上繰り返し、ターゲット デバイスに対するレイテンシとメモリの制約に対する最適解を検索します。次の図は、アーキテクチャ検索フレームワークの主なコンポーネントを示しています。
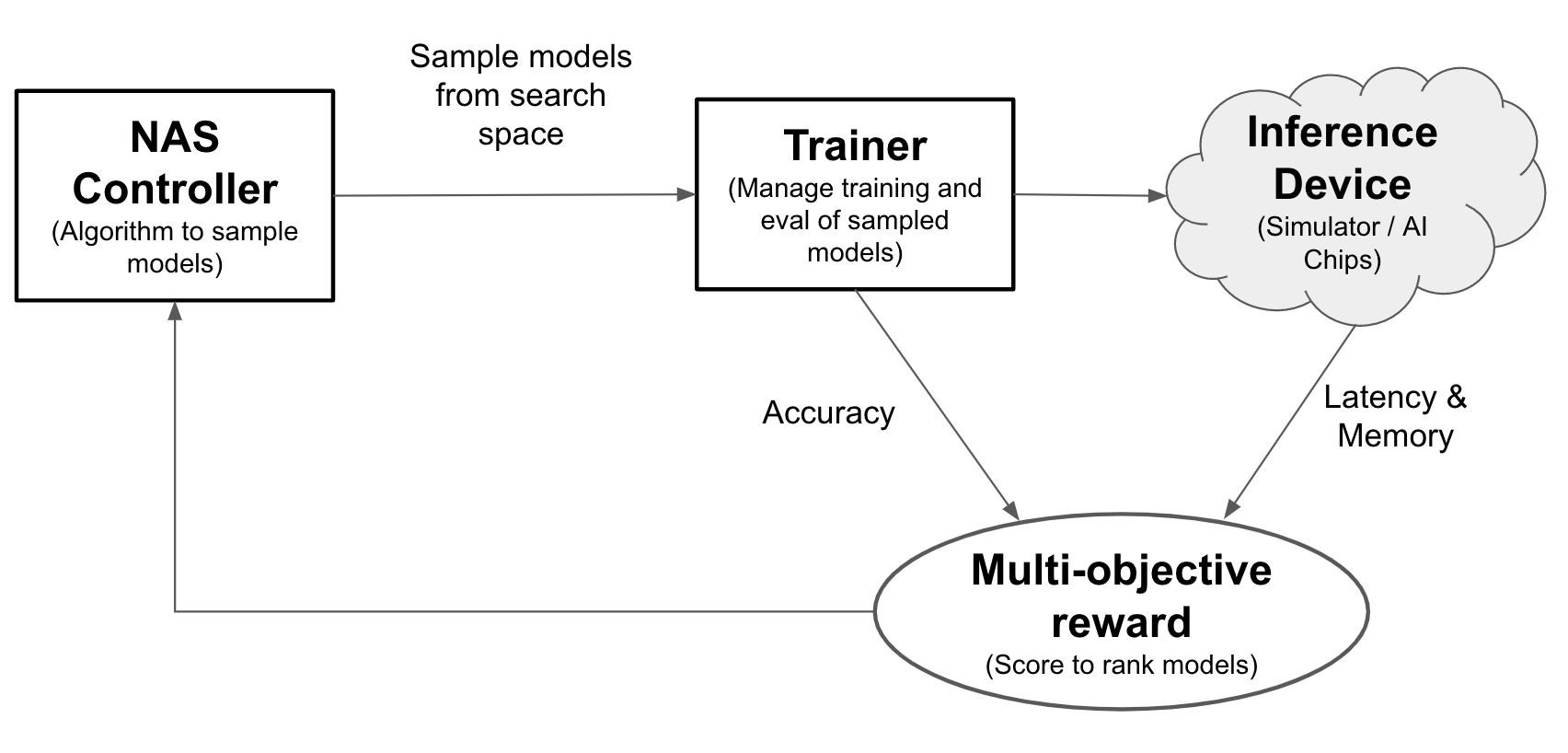
- モデル: オペレーションと接続のニューラル アーキテクチャ。
- 検索スペース: 設計と最適化が可能なモデル(オペレーションと接続)のスペース。
- トレーナー Docker: カスタマイズ可能なトレーナー コード。モデルをトレーニングして評価し、モデルの精度を計算します。
- 推論デバイス: モデルのレイテンシとメモリ使用量を計算する CPU / GPU などのハードウェア デバイス。
- 報酬: モデルの指標(精度、レイテンシ、メモリなど)を組み合わせ。モデルのランキングに使用されます。
- Neural Architecture Search コントローラ: 次のことを行うオーケストレーション アルゴリズム。(a)検索スペースからモデルをサンプリングする。(b)モデルの報酬を受け取る。(c)評価用のモデル提案セットを提供して、最適なモデルを検索する。
ユーザー設定タスク
Neural Architecture Search は、事前構築済みの検索スペースに統合された事前構築済みのトレーナーを提供します。追加の設定を行わなくても、付属のノートブックで簡単に使用できます。
ただし、ほとんどのユーザーは、カスタム トレーナー、カスタム検索スペース、カスタム指標(メモリ、レイテンシ、トレーニング時間など)、カスタム報酬(精度やレイテンシなどの組み合わせ)を使用する必要があります。そのため、以下のことを行う必要があります。
- 付属の Neural Architecture Search 言語を使用してカスタム検索スペースを定義する。
- 検索スペースの定義をトレーナー コードに統合する。
- カスタム指標のレポートをトレーナー コードに追加する。
- カスタム報酬をトレーナー コードに追加する。
- トレーニング コンテナを構築して Neural Architecture Search ジョブを開始する。
次の図に、この作業を示します。
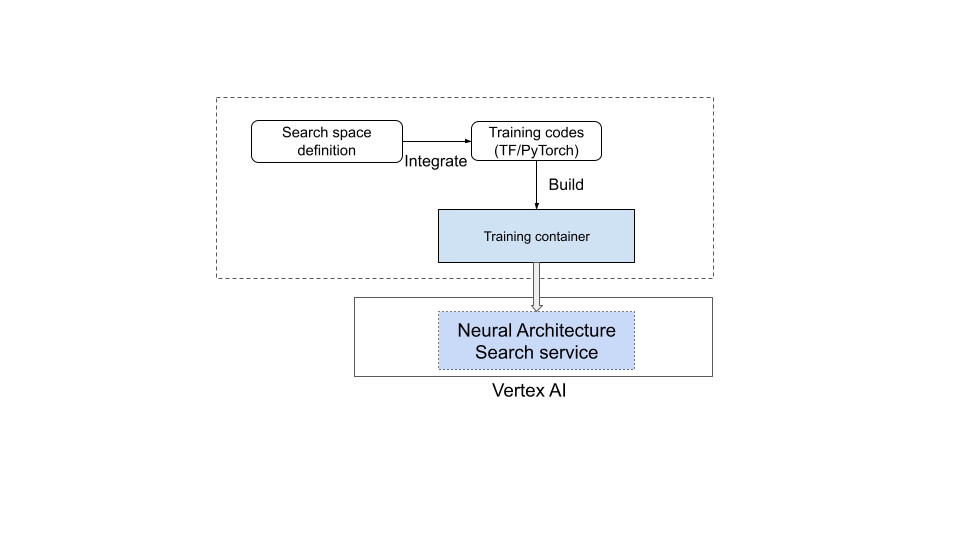
Neural Architecture Search サービスの実行
使用するトレーニング コンテナを設定すると、Neural Architecture Search サービスは、複数の GPU デバイスを使用して、複数のトレーニング コンテナを並行して起動します。トレーニングで並行して使用するトライアルの数と、開始するトライアルの合計数を管理できます。各トレーニング コンテナには、検索スペースから推奨のアーキテクチャが提供されます。トレーニング コンテナは推奨のモデルを構築し、トレーニングと評価を行い、Neural Architecture Search サービスに報酬を報告します。Neural Architecture Search サービスはこのプロセスを継続し、報酬のフィードバックを使用して、より優れたモデル アーキテクチャを探します。検索後、報告された指標にアクセスして、さらに詳しい分析を行うことができます。
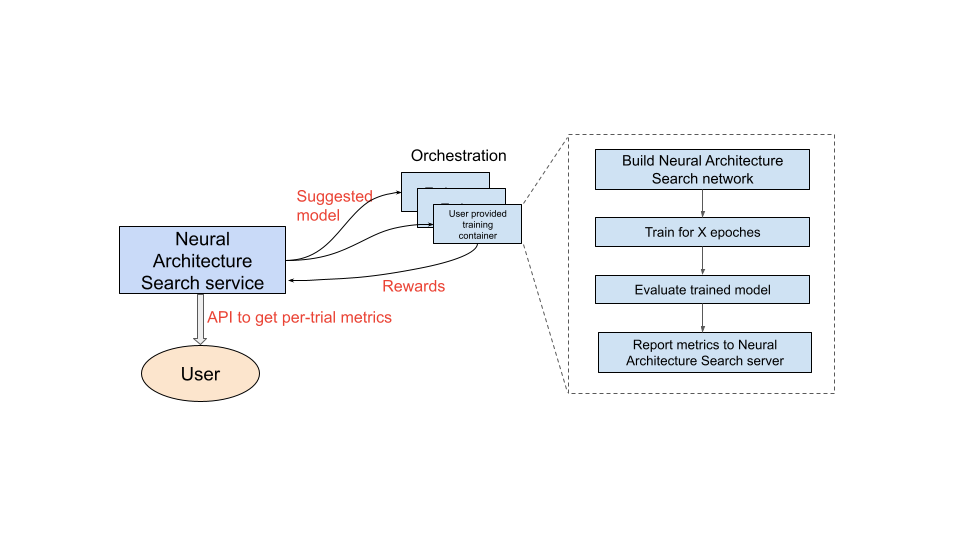
Neural Architecture Search でのユーザーの作業の概要
Neural Architecture Search の大まかなテスト手順は次のとおりです。
設定と定義:
- ラベル付きデータセットを識別し、タスクの種類(検出、セグメンテーションなど)を指定します。
- トレーナー コードをカスタマイズします。
- 事前構築済みの検索スペースを使用するか、Neural Architecture Search 言語を使用してカスタム検索スペースを定義します。
- 検索スペースの定義をトレーナー コードに統合する。
- カスタム指標のレポートをトレーナー コードに追加する。
- カスタム報酬をトレーナー コードに追加する。
- トレーナー コンテナをビルドする。
- 部分的なトレーニング(プロキシタスク)用にトライアル検索パラメータを設定します。検索トレーニングは、モデルを部分的にトレーニングするために、高速で完了する(30~60 分など)ことが理想的です。
- サンプリングされたモデルで報酬を収集するために必要な最小エポック(最小エポックではモデルの収束を保証する必要はありません)。
- ハイパーパラメータ(学習率など)。
検索スペースの統合コンテナが適切に実行されるように、検索スペースをローカルで実行します。
5 つのテスト トライアルを含む Google Cloud Search(ステージ 1)ジョブを開始し、検索のトライアルがランタイムと精度の目標を達成していることを確認します。
1,000 回以上のトライアルを含む Google Cloud Search(ステージ 1)ジョブを開始します。
検索の一環として(ステージ 2 の)上位 N 個のモデルをトレーニングする間隔も設定します。
- ハイパーパラメータ検索のハイパーパラメータとアルゴリズム。ステージ 2 では通常、ステージ 1 と同様の構成が使用されますが、特定のパラメータ(トレーニング ステップ、エポックなど)やチャネル数などの設定が高くなります。
- 停止基準(エポック数)。
報告された指標を分析するか、アーキテクチャを可視化して分析情報を確認します。
アーキテクチャ検索のテスト後に、スケーリング検索のテスト、拡張検索テストの順に行うことができます。
ドキュメントを読む順序
- (必須)環境を設定する
- (必須)チュートリアル
- (PyTorch をご利用のお客様のみ必須)クラウドデータを使用した PyTorch の効率的なトレーニング
- (必須)ベスト プラクティスとおすすめのワークフロー
- (必須)プロキシタスクの設計
- (ビルド済みのトレーナーを使用する場合のみ必須)ビルド済みの検索スペースとトレーナーを使用する方法
リファレンス
- 機械学習を使用してニューラル ネットワーク アーキテクチャを調べる
- MnasNet: モバイル機械学習モデルの設計の自動化
- EfficientNet: AutoML とモデルのスケーリングによる精度と効率の改善
- NAS-FPN: オブジェクト検出のためのスケーラブルな特徴ピラミッド アーキテクチャを学習する
- SpineNet: 認識とローカライズのためのスケール交換バックボーンを学習する
- RandAugment