このガイドでは、Google の事前構築済みの検索スペースとトレーナー コードを MnasNet と SpineNet 用の TF-vision に基づいて使用して、Vertex AI Neural Architecture Search ジョブを実行する方法について説明します。エンドツーエンドの例については、MnasNet 分類ノートブックと SpineNet オブジェクト検出ノートブックをご覧ください。
事前構築済みトレーナーで使用するデータの準備
Neural Architecture Search の事前構築済みトレーナーを使用するには、tf.train.Example を含む TFRecord 形式のデータが必要です。tf.train.Example には、次のフィールドを含める必要があります。
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
ImageNet データの準備手順はこちらでご確認いただけます。
カスタムデータを変換するには、ダウンロードしたサンプルコードとユーティリティに含まれている解析スクリプトを使用します。データ解析をカスタマイズするには、tf_vision/dataloaders/*_input.py ファイルを変更します。
TFRecord と tf.train.Example の詳細をご覧ください。
テスト用の環境変数を定義する
テストを実施する前に、次の環境変数を定義する必要があります。
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(推奨の形式) テストで使用するトレーニング データセットと検証データセットがある Cloud Storage のロケーション。例(検出用の CoCo):
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
テストの出力を格納する Cloud Storage のロケーション。推奨される形式
gs://${USER}_nas_experiment
リージョン: テスト出力バケット リージョンと同じリージョン。例:
us-central1。PARAM_OVERRIDE: 事前構築済みトレーナーのパラメータをオーバーライドする .yaml ファイル。 Neural Architecture Search には、使用可能なデフォルトの構成があります。
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
トレーニングの要件に合わせて、オーバーライド ファイルを選択または変更することをおすすめします。次の点を考慮してください。
- GPU または CPU から選択するように
--accelerator_typeを設定できます。CPU を使用した高速テストで少数のエポックのみを実行するには、--accelerator_type=""フラグを設定し、構成ファイルtf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yamlを使用します。 - エポック数
- トレーニングの実行時間
- 学習率などのハイパーパラメータ
トレーニング ジョブを制御するすべてのパラメータの一覧については、tf_vision/configs/ をご覧ください。主なパラメータは次のとおりです。
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
Neural Architecture Search がジョブ出力(チェックポイントなど)を格納する Cloud Storage バケットを作成します。
gcloud storage buckets create $GCS_ROOT_DIR
トレーナー コンテナとレイテンシ計算コンテナをビルドする
次のコマンドは、URI gcr.io/PROJECT_ID/TRAINER_DOCKER_ID を使用して Google Cloud にトレーナー イメージをビルドします。これは、次のステップの Neural Architecture Search ジョブで使用します。
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
検索スペースと報酬を変更するには、これらを Python ファイルで更新し、Docker イメージを再ビルドします。
トレーナーをローカルでテストする
サービスでジョブを起動するには数分かかります。このため、トレーナー Docker をローカルでテストするほうが便利な場合があります(TFRecord の形式を検証する場合など)。 Google Cloud ここでは例として spinenet 検索スペースを使用します。これにより、検索ジョブをローカルで実行できます(モデルはランダムにサンプリングされます)。
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
training_data_path と validation_data_path は、TFRecord へのパスです。
ステージ 1 検索ジョブを開始してから、ステージ 2 トレーニング ジョブを開始する Google Cloud
エンドツーエンドの例については、MnasNet 分類ノートブックと SpineNet オブジェクト検出ノートブックをご覧ください。
--max_parallel_nas_trialフラグと--max_nas_trialフラグを設定してカスタマイズできます。Neural Architecture Search はmax_parallel_nas_trial個のトライアルを並行して開始し、max_nas_trial個のトライアルの実行後に終了します。--target_device_latency_msフラグが設定されている場合、--target_device_typeフラグで指定されたアクセラレータで別のlatency calculatorジョブが開始します。Neural Architecture Search コントローラは、FLAG
--nas_params_strを介して各トライアルに新しいアーキテクチャ候補の提案を提供します。各トライアルは、FLAG
nas_params_strの値に基づいてグラフを作成し、トレーニング ジョブを開始します。また、各トライアルの値は JSON ファイル(os.path.join(nas_job_dir, str(trial_id), "nas_params_str.json"))に保存されます。
レイテンシの制約がある報酬
MnasNet 分類ノートブックには、Cloud CPU デバイスベースのレイテンシ制約型検索の例を示します。
レイテンシ制約のあるモデルを検索する場合、トレーナーが精度とレイテンシの両方の関数として報酬を報告する場合があります。
共有ソースコードでは、報酬は次のように計算されます。
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
mnasnet の論文の 3 ページに記載されている reward 計算の別のバリアントを使用することもできます。
target_device_typeには、 Google Cloudでサポートされているターゲット デバイスタイプ(NVIDIA_TESLA_P100など)を指定します。use_prebuilt_latency_calculatorは、事前構築済みのレイテンシ計算ツールtf_vision/latency_computation_using_saved_model.pyを使用します。target_device_latency_msには、ターゲット デバイスのレイテンシを指定します。
レイテンシ計算関数をカスタマイズする方法については、tf_vision/latency_computation_using_saved_model.py をご覧ください。
Neural Architecture Search ジョブの進捗状況をモニタリングする
Google Cloud コンソールのジョブページのグラフには reward vs. trial number が表示され、テーブルには各トライアルの報酬が表示されます。報酬が最も高い上位のトライアルを確認できます。
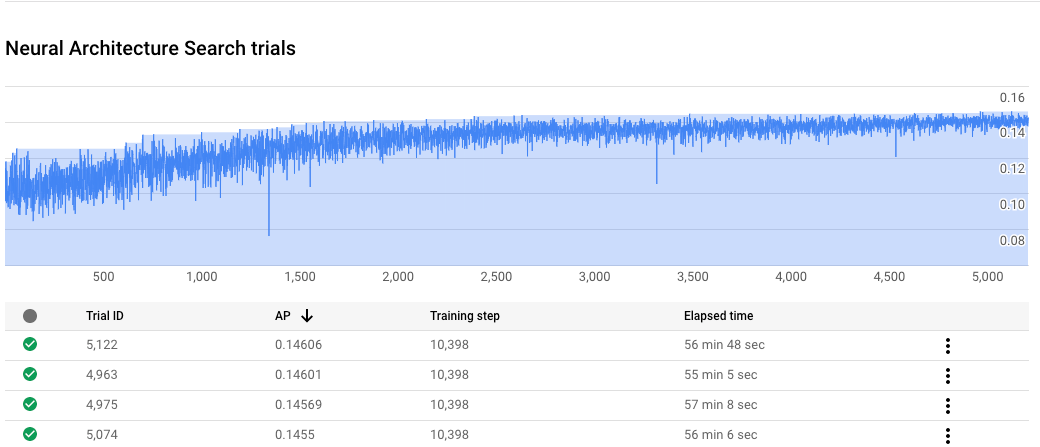
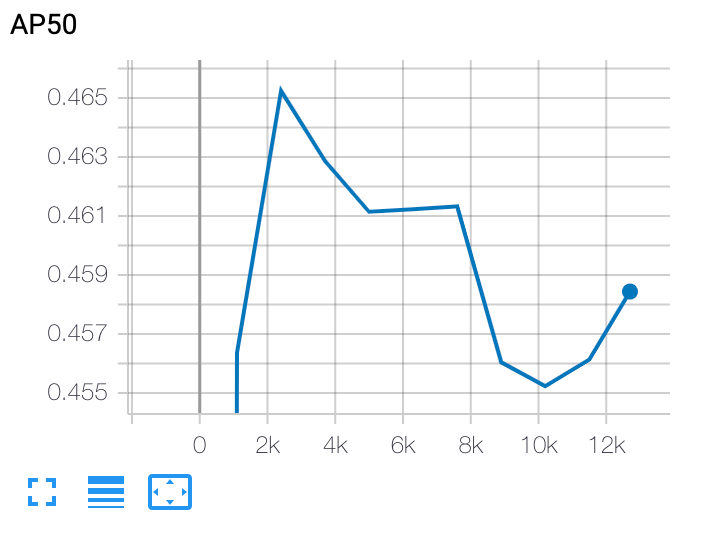
ステージ 2 のトレーニング曲線をプロットする
ステージ 2 のトレーニング後、Cloud Shell または Google Cloud
TensorBoard を使用して、ジョブ ディレクトリを指すトレーニング曲線をプロットします。
選択したモデルをデプロイする
SavedModel を作成するには、params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml で export_saved_model.py スクリプトを使用します。