A Vertex AI oferece um serviço de preparação gerido que ajuda a operacionalizar a preparação de modelos em grande escala. Pode usar o Vertex AI para executar aplicações de preparação com base em qualquer framework de aprendizagem automática (AA) naGoogle Cloud infraestrutura. Para as seguintes frameworks de ML populares, o Vertex AI também tem suporte integrado que simplifica o processo de preparação para a preparação e a apresentação de modelos:
Esta página explica as vantagens da preparação personalizada na Vertex AI, o fluxo de trabalho envolvido e as várias opções de preparação disponíveis.
A Vertex AI operacionaliza a preparação em grande escala
Existem vários desafios na operacionalização da preparação de modelos. Estes desafios incluem o tempo e o custo necessários para formar modelos, a profundidade das competências necessárias para gerir a infraestrutura de computação e a necessidade de fornecer segurança ao nível empresarial. A Vertex AI resolve estes desafios e oferece uma série de outras vantagens.
Infraestrutura de computação totalmente gerida
|
|
A preparação de modelos na Vertex AI é um serviço totalmente gerido que não requer administração de infraestrutura física. Pode preparar modelos de ML sem ter de aprovisionar nem gerir servidores. Só paga pelos recursos de computação que consome. O Vertex AI também trata o registo, o processamento em fila e a monitorização de tarefas. |
Alto desempenho
|
|
As tarefas de preparação do Vertex AI estão otimizadas para a preparação de modelos de ML, o que pode oferecer um desempenho mais rápido do que executar diretamente a sua aplicação de preparação num cluster do Google Kubernetes Engine (GKE). Também pode identificar e depurar gargalos de desempenho no seu trabalho de preparação usando o Cloud Profiler. |
Preparação distribuída
|
|
O servidor de redução é um algoritmo de redução total na Vertex AI que pode aumentar a taxa de transferência e reduzir a latência da preparação distribuída de vários nós em unidades de processamento gráfico (GPUs) NVIDIA. Esta otimização ajuda a reduzir o tempo e o custo de concluir tarefas de preparação de grande escala. |
Otimização de hiperparâmetros
|
|
Os trabalhos de otimização de hiperparâmetros executam várias experiências da sua aplicação de preparação com diferentes valores de hiperparâmetros. Especifica um intervalo de valores a testar e o Vertex AI descobre os valores ideais para o seu modelo nesse intervalo. |
Segurança empresarial
|
|
O Vertex AI oferece as seguintes funcionalidades de segurança empresarial:
|
Integrações de operações de ML (MLOps)
|
|
O Vertex AI oferece um conjunto de ferramentas MLOps integradas e funcionalidades que pode usar para os seguintes fins:
|
Fluxo de trabalho para a formação personalizada
O diagrama seguinte mostra uma vista geral de nível superior do fluxo de trabalho de preparação personalizada no Vertex AI. As secções seguintes descrevem cada passo em detalhe.
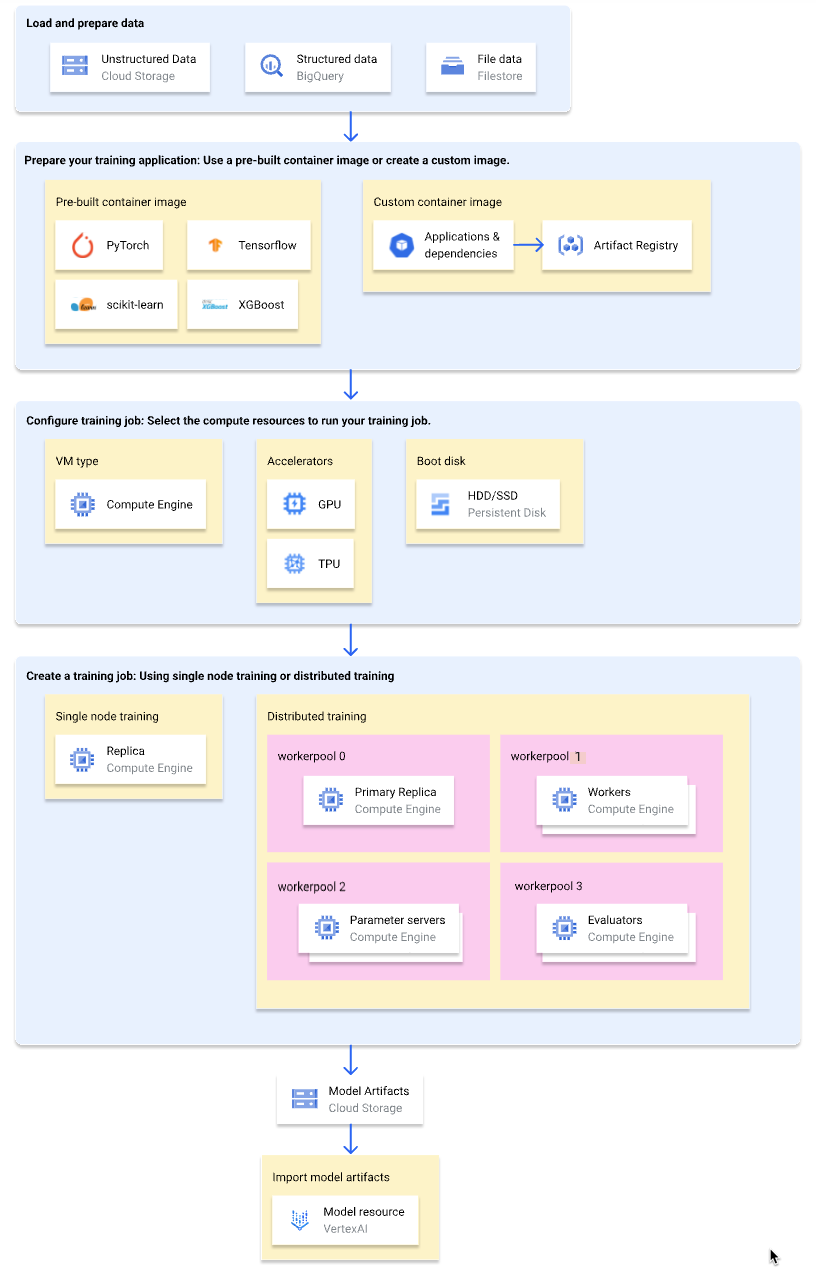
Carregue e prepare os dados de preparação
Para o melhor desempenho e apoio técnico, use um dos seguintes Google Cloud serviços como origem de dados:
Para uma comparação destes serviços, consulte o artigo Vista geral da preparação de dados.
Também pode especificar um conjunto de dados gerido do Vertex AI como origem de dados quando usa um pipeline de preparação para preparar o modelo. A preparação de um modelo personalizado e um modelo do AutoML com o mesmo conjunto de dados permite-lhe comparar o desempenho dos dois modelos.
Prepare a sua candidatura à formação
Para preparar a aplicação de preparação para utilização no Vertex AI, faça o seguinte:
- Implemente as práticas recomendadas de código de preparação para o Vertex AI.
- Determine um tipo de imagem de contentor a usar.
- Empacote a sua aplicação de preparação num formato suportado com base no tipo de imagem de contentor selecionado.
Implemente práticas recomendadas de código de preparação
A sua aplicação de preparação deve implementar as práticas recomendadas de código de preparação para o Vertex AI. Estas práticas recomendadas estão relacionadas com a capacidade da sua aplicação de preparação de fazer o seguinte:
- Aceder Google Cloud serviços.
- Carregue os dados de entrada.
- Ative o registo automático para o acompanhamento de experiências.
- Exporte artefactos do modelo.
- Use as variáveis de ambiente do Vertex AI.
- Garantir a resiliência aos reinícios de VMs.
Selecione um tipo de contentor
O Vertex AI executa a sua aplicação de preparação numa imagem de contentor do Docker. Uma imagem de contentor do Docker é um pacote de software autónomo que inclui código e todas as dependências, que pode ser executado em quase qualquer ambiente de computação. Pode especificar o URI de uma imagem de contentor pré-criada para usar ou criar e carregar uma imagem de contentor personalizada com a sua aplicação de preparação e dependências pré-instaladas.
A tabela seguinte mostra as diferenças entre as imagens de contentores pré-criadas e personalizadas:
| Especificações | Imagens de contentores pré-criadas | Imagens de contentores personalizadas |
|---|---|---|
| Framework de ML | Cada imagem de contentor é específica de uma framework de ML. | Usar qualquer framework de ML ou não usar nenhuma. |
| Versão da estrutura de ML | Cada imagem de contentor é específica de uma versão da framework de ML. | Use qualquer versão da framework de AA, incluindo versões secundárias e compilações noturnas. |
| Relações de dependência da aplicação | As dependências comuns da framework de ML estão pré-instaladas. Pode especificar dependências adicionais a instalar na sua aplicação de preparação. | Pré-instale as dependências de que a sua aplicação de preparação precisa. |
| Formato de fornecimento de aplicações |
|
Pré-instale a aplicação de preparação na imagem do contentor personalizado. |
| Esforço de configuração | Baixo | Alto |
| Recomendado para | Aplicações de preparação Python baseadas numa framework de ML e numa versão da framework que tenha uma imagem de contentor pré-criada disponível. |
|
Empacote a sua aplicação de preparação
Depois de determinar o tipo de imagem de contentor a usar, crie um pacote da aplicação de preparação num dos seguintes formatos com base no tipo de imagem de contentor:
Ficheiro Python único para utilização num contentor pré-criado
Escreva a sua aplicação de preparação como um único ficheiro Python e use o Vertex AI SDK para Python para criar uma classe
CustomJobouCustomTrainingJob. O ficheiro Python é incluído num pacote de distribuição de origem Python e instalado numa imagem de contentor pré-criada. A disponibilização da sua aplicação de preparação como um único ficheiro Python é adequada para a criação de protótipos. Para aplicações de preparação de produção, é provável que tenha a sua aplicação de preparação organizada em mais do que um ficheiro.Distribuição de origem Python para utilização num contentor pré-criado
Empacote a sua aplicação de preparação em uma ou mais distribuições de origem Python e carregue-as para um contentor do Cloud Storage. O Vertex AI instala as distribuições de origem numa imagem de contentor pré-criada quando cria uma tarefa de preparação.
Imagem de contentor personalizada
Crie a sua própria imagem de contentor Docker com a aplicação de preparação e as dependências pré-instaladas e carregue-a para o Artifact Registry. Se a sua aplicação de preparação estiver escrita em Python, pode executar estes passos com um comando da Google Cloud CLI.
Configure a tarefa de preparação
Uma tarefa de preparação do Vertex AI executa as seguintes tarefas:
- Aprovisiona uma (treino de nó único) ou mais (treino distribuído) máquinas virtuais (VMs).
- Executa a sua aplicação de preparação contentorizada nas VMs aprovisionadas.
- Elimina as VMs após a conclusão da tarefa de preparação.
O Vertex AI oferece três tipos de tarefas de preparação para executar a sua aplicação de preparação:
-
Uma tarefa personalizada (
CustomJob) executa a sua aplicação de preparação. Se estiver a usar uma imagem de contentor pré-criada, os artefactos do modelo são enviados para o contentor do Cloud Storage especificado. Para imagens de contentores personalizados, a sua aplicação de preparação também pode gerar artefactos do modelo noutras localizações. Tarefa de aperfeiçoamento de hiperparâmetros
Uma tarefa de aperfeiçoamento de hiperparâmetros (
HyperparameterTuningJob) executa várias experiências da sua aplicação de preparação usando diferentes valores de hiperparâmetros até produzir artefactos do modelo com os valores de hiperparâmetros de desempenho ideais. Especifica o intervalo de valores de hiperparâmetros a testar e as métricas para as quais quer otimizar.-
Um pipeline de preparação (
CustomTrainingJob) executa uma tarefa personalizada ou uma tarefa de hiperaperfeiçoamento dos parâmetros e, opcionalmente, exporta os artefactos do modelo para o Vertex AI para criar um recurso de modelo. Pode especificar um conjunto de dados gerido do Vertex AI como origem de dados.
Quando criar uma tarefa de preparação, especifique os recursos de computação a usar para executar a sua aplicação de preparação e configure as definições do contentor.
Configurações de computação
Especifique os recursos de computação a usar para uma tarefa de preparação. A Vertex AI suporta a preparação de nó único, em que a tarefa de preparação é executada numa VM, e a preparação distribuída, em que a tarefa de preparação é executada em várias VMs.
Os recursos de computação que pode especificar para a sua tarefa de preparação são os seguintes:
Tipo de máquina de VM
Os diferentes tipos de máquinas oferecem diferentes CPUs, tamanhos de memória e larguras de banda.
Unidades de processamento de gráficos (GPUs)
Pode adicionar uma ou mais GPUs a VMs do tipo A2 ou N1. Se a sua aplicação de preparação for concebida para usar GPUs, a adição de GPUs pode melhorar significativamente o desempenho.
Unidades de processamento tensor (TPUs)
Os TPUs foram concebidos especificamente para acelerar as cargas de trabalho de aprendizagem automática. Quando usa uma VM de TPU para o treino, só pode especificar um grupo de trabalhadores. Esse conjunto de trabalhadores só pode ter uma réplica.
Discos de arranque
Pode usar SSDs (predefinição) ou HDDs para o disco de arranque. Se a sua aplicação de preparação ler e escrever no disco, a utilização de SSDs pode melhorar o desempenho. Também pode especificar o tamanho do disco de arranque com base na quantidade de dados temporários que a sua aplicação de preparação escreve no disco. Os discos de arranque podem ter entre 100 GiB (predefinição) e 64 000 GiB. Todas as VMs num conjunto de trabalhadores têm de usar o mesmo tipo e tamanho de disco de arranque.
Configurações do contentor
As configurações do contentor que tem de fazer dependem de estar a usar uma imagem de contentor pré-criada ou personalizada.
Configurações de contentores pré-criadas:
- Especifique o URI da imagem do contentor pré-criada que quer usar.
- Se a sua aplicação de preparação estiver incluída num pacote como uma distribuição de origem Python, especifique o URI do Cloud Storage onde o pacote está localizado.
- Especifique o módulo do ponto de entrada da sua aplicação de preparação.
- Opcional: especifique uma lista de argumentos da linha de comandos a transmitir ao módulo do ponto de entrada da sua aplicação de preparação.
Configurações de contentores personalizadas:
- Especifique o URI da sua imagem de contentor personalizada, que pode ser um URI do Artifact Registry ou do Docker Hub.
- Opcional: substitua as instruções
ENTRYPOINTouCMDna imagem do contentor.
Crie uma tarefa de preparação
Depois de preparar os dados e a aplicação de preparação, execute a aplicação de preparação criando um dos seguintes trabalhos de preparação:
- Crie uma tarefa personalizada.
- Crie uma tarefa de hiperaperfeiçoamento dos parâmetros.
- Crie um pipeline de preparação.
Para criar a tarefa de preparação, pode usar a Google Cloud consola, a CLI Google Cloud, o SDK Vertex AI para Python ou a API Vertex AI.
(Opcional) Importe artefactos de modelos para o Vertex AI
É provável que a sua aplicação de preparação produza um ou mais artefactos do modelo numa localização especificada, normalmente um contentor do Cloud Storage. Antes de poder obter previsões no Vertex AI a partir dos artefactos do modelo, primeiro importe os artefactos do modelo para o Registo de modelos Vertex AI.
Tal como as imagens de contentores para preparação, o Vertex AI dá-lhe a opção de usar imagens de contentores pré-criadas ou personalizadas para inferências. Se estiver disponível uma imagem de contentor pré-criada para inferências para a sua framework de ML e versão da framework, recomendamos que use uma imagem de contentor pré-criada.
O que se segue?
- Obtenha inferências do seu modelo.
- Avalie o seu modelo.
- Experimente o tutorial Olá, preparação personalizada para obter instruções passo a passo sobre a preparação de um modelo de classificação de imagens do TensorFlow Keras no Vertex AI.