このページでは、モデルを反復処理できるように AutoML テキスト エンティティ抽出モデルを評価する方法について説明します。
Vertex AI では、モデルのパフォーマンスを判定するためのモデル評価指標(適合率や再現率の指標など)が提供されます。Vertex AI では、評価指標の計算にテストセットが使用されます。
モデル評価指標の使い方
モデル評価指標は、テストセットに対するモデルのパフォーマンスを定量的に測定します。これらの評価指標をどのように解釈し、使用するかは、ビジネスニーズや、どのような問題をモデルのトレーニングで解決するかによって異なります。たとえば、偽陽性の許容範囲が偽陰性の許容範囲よりも低い場合もあれば、その逆の場合もあります。このような質問に対する答えは、どの指標を重視するかによって変わります。
モデルのパフォーマンスを向上させるための反復処理の詳細については、モデルの反復処理をご覧ください。
Vertex AI から返される評価指標
Vertex AI からは、適合率、再現率、信頼度しきい値など、さまざまな評価指標が返されます。返される評価指標は、モデルの目標によって異なります。たとえば、画像分類モデルと画像オブジェクト検出モデルでは、異なる評価指標が返されます。
Cloud Storage からダウンロードできるスキーマ ファイルによって、Vertex AI から各目標に対して提供される評価指標が決まります。次の各タブにはスキーマ ファイルへのリンクがあり、各モデル目標の評価指標を確認できます。
スキーマ ファイルは、Cloud Storage の gs://google-cloud-aiplatform/schema/modelevaluation/ で表示、ダウンロードできます。
- 信頼度しきい値: どの推論を返すかを決定する信頼度のスコア。モデルはこの値以上の推論を返します。信頼度しきい値が高いほど、適合率は向上しますが、再現率は低くなります。Vertex AI は、さまざまなしきい値に対する信頼指標を返し、しきい値が適合率と再現率にどのように影響するかを示します。
- 再現率: このクラスの推論のうち、モデルが正しく予測した割合。これは真陽性率とも呼ばれます。
- 適合率: モデルによって生成された分類予測のうち正しい推論であった割合。
- F1 スコア: 適合率と再現率の調和平均。適合率と再現率のバランスを取ることを求めていて、クラス分布が不均一な場合、F1 は有用な指標となります。
- 混同行列: 混同行列は、モデルによる予測のうち正しい予測の頻度を示します。間違った予測結果に対しては、代わりに、モデルが予測した内容を表示します。混同行列は、モデルが 2 つの結果を「混同」している場所を把握するのに役立ちます。
評価指標の取得
モデルに関する評価指標の集約型セットを取得できますが、目的によっては、特定のクラスやラベルに関する評価指標を取得することもできます。特定のクラスやラベルに関する評価指標は、評価スライスとも呼ばれます。以下のコンテンツでは、 Google Cloud コンソールまたは API を使用して集約型の評価指標と評価スライスを取得する方法を説明します。
Google Cloud コンソール
Google Cloud コンソールの Vertex AI セクションで、[モデル] ページに移動します。
[リージョン] プルダウンで、モデルが配置されているリージョンを選択します。
モデルの一覧からモデルをクリックすると、モデルの [評価] タブが開きます。
[評価] タブでは、モデルの集約型評価指標(平均適合率や再現率など)を確認できます。
モデルの目標に評価スライスが含まれる場合は、コンソールにラベルの一覧が表示されます。次の例に示すように、ラベルをクリックすると、そのラベルの評価指標を表示できます。
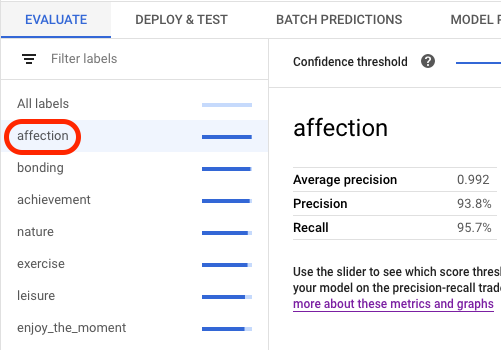
API
評価指標を取得するための API リクエストはデータ型や目標ごとに同じですが、その出力は異なります。以下のサンプルでは、同じリクエストが使用されていますが、レスポンスが異なっています。
集約型のモデル評価指標の取得
集約型のモデル評価指標は、モデル全体に関する情報を提供します。特定のスライスに関する情報を表示するには、モデル評価スライスを一覧表示します。
集約型のモデル評価指標を表示するには、projects.locations.models.evaluations.get メソッドを使用します。
Vertex AI は信頼度指標の配列を返します。各要素は、それぞれの confidenceThreshold 値(0 から最大 1)における評価指標を表示します。さまざまなしきい値を表示させることにより、その他の指標(適合率や再現率など)がしきい値によってどのように変化するか確認できます。
お使いの言語または環境に対応するタブを選択してください。
REST
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION: モデルが保存されているリージョン。
- PROJECT: 実際のプロジェクト ID。
- MODEL_ID: モデルリソースの ID。
- PROJECT_NUMBER: プロジェクトに自動生成されたプロジェクト番号。
- EVALUATION_ID: モデル評価の ID(レスポンスに表示される)。
HTTP メソッドと URL:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
次のコマンドを実行します。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations"
PowerShell
次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
Java
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Java の設定手順を完了してください。詳細については、Vertex AI Java API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Node.js の設定手順を完了してください。詳細については、Vertex AI Node.js API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。詳細については、Python API リファレンス ドキュメントをご覧ください。
すべての評価スライスの一覧表示
projects.locations.models.evaluations.slices.list メソッドは、モデルのすべての評価スライスを一覧表示します。モデルの評価 ID が必要です。この ID は、集約型のモデル評価指標を表示する際に取得できます。
モデル評価スライスを使用すると、特定のラベルでのモデルのパフォーマンスを判断できます。value フィールドは、指標の対象となるラベルを示します。
Vertex AI は信頼度指標の配列を返します。各要素は、それぞれの confidenceThreshold 値(0 から最大 1)における評価指標を表示します。さまざまなしきい値を表示させることにより、その他の指標(適合率や再現率など)がしきい値によってどのように変化するか確認できます。
REST
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION: モデルが配置されているリージョン。例:
us-central1 - PROJECT:
- MODEL_ID: モデルの ID。
- EVALUATION_ID: リストする評価スライスを含むモデル評価の ID。
HTTP メソッドと URL:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
次のコマンドを実行します。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices"
PowerShell
次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
Java
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Java の設定手順を完了してください。詳細については、Vertex AI Java API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Node.js の設定手順を完了してください。詳細については、Vertex AI Node.js API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。詳細については、Python API リファレンス ドキュメントをご覧ください。
単一のスライスに関する指標の取得
単一のスライスに関する評価指標を表示するには、projects.locations.models.evaluations.slices.get メソッドを使用します。スライス ID が必要になります。これは、すべてのスライスを一覧表示するときに提供される ID です。次のサンプルは、すべてのデータ型と目標に適用されます。
REST
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION: モデルが配置されているリージョン。たとえば、us-central1 などです。
- PROJECT:
- MODEL_ID: モデルの ID。
- EVALUATION_ID: 取得する評価スライスを含むモデル評価の ID。
- SLICE_ID: 取得する評価スライスの ID。
- PROJECT_NUMBER: プロジェクトに自動生成されたプロジェクト番号。
- EVALUATION_METRIC_SCHEMA_FILE_NAME: 戻り値となる評価指標を定義するスキーマ ファイルの名前(
classification_metrics_1.0.0など)。
HTTP メソッドと URL:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
次のコマンドを実行します。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID"
PowerShell
次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID" | Select-Object -Expand Content
次のような JSON レスポンスが返されます。
Java
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Java の設定手順を完了してください。詳細については、Vertex AI Java API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
このサンプルを試す前に、Vertex AI クイックスタート: クライアント ライブラリの使用にある Node.js の設定手順を完了してください。詳細については、Vertex AI Node.js API のリファレンス ドキュメントをご覧ください。
Vertex AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。詳細については、Python API リファレンス ドキュメントをご覧ください。
モデルの反復処理
モデル評価指標は、モデルが期待する条件を満たしていない場合に、モデルをデバッグするための起点となります。たとえば、適合率スコアと再現率スコアが低い場合は、モデルに追加のトレーニング データが必要であるか、ラベルに一貫性がないことを示している可能性があります。適合率と再現率が完璧である場合は、テストデータの予測が容易すぎるか、または一般化が十分でない可能性があります。
トレーニング データを反復修正することにより、新しいモデルを作成できます。新しいモデルを作成した後に、既存のモデルと新しいモデルの評価指標を比較できます。
次に示す提案は、分類モデルや検出モデルなど、項目にラベル付けするモデルを改善するのに役立ちます。
- トレーニング データのサンプルを追加するか、サンプルの範囲を広げます。たとえば、画像分類モデルの場合、広角画像、高解像度または低解像度の画像、さまざまな視点の画像を含めることが考えられます。詳細については、対象としているデータ型と目標に関するデータの準備をご覧ください。
- サンプル数が少ないクラスやラベルを削除します。サンプルの数が少ないと、クラスやラベルに関するモデルの予測が、不確実で一貫性のないものになります。
- コンピュータはクラス名やラベル名の意味を理解できません。また、「door」と「door_with_knob」のような名前のニュアンスも理解できません。コンピュータがそのようなニュアンスを認識できるようなデータを提供する必要があります。
- 真陽性と真陰性のサンプルを追加してデータを強化します。特に判定境界に近いサンプルを追加することで、モデルが混同するのを緩和します。
- 独自のデータ分割(トレーニング、検証、テスト)を指定します。Vertex AI は各セットにアイテムをランダムに割り当てます。そのため、トレーニング セットや検証セットに重複に近いアイテムが割り当てられる可能性があり、過剰適合によってテストセットでのパフォーマンスが低下する可能性があります。独自のデータ分割の設定については、AutoML モデルのデータ分割についてをご覧ください。
- モデルの評価指標に混同行列が含まれている場合、モデルが 2 つのラベルを混同(特定のラベルを真のラベルより強く予測)していないか確認できます。サンプルに正しいラベルが付けられているかどうか、データを確認してください。
- トレーニング時間が短い(最大ノード時間数が少ない)場合は、トレーニング時間を長くする(最大ノード時間数を増やす)ことにより、より高品質のモデルが得られる場合があります。