테이블 형식 워크플로는 테이블 형식 데이터를 사용하는 엔드 투 엔드 ML을 위한 확장 가능한 완전 관리형 통합 파이프라인 집합입니다. 모델 개발에 Google 기술을 활용하고 개발자 요구사항에 맞는 맞춤설정 옵션을 제공합니다.
이점
- 완전 관리형: 업데이트, 종속 항목, 충돌에 대해 걱정할 필요가 없습니다.
- 손쉬운 확장: 워크로드 또는 데이터 세트 증가에 따라 인프라를 다시 엔지니어링할 필요가 없습니다.
- 성능 최적화: 워크플로 요구사항에 맞게 적절한 하드웨어가 자동으로 구성됩니다.
- 긴밀한 통합: Vertex AI Pipelines 및 Vertex AI 실험과 같은 Vertex AI MLOps 제품군과의 호환성 덕분에 짧은 시간 내에 많은 실험을 실행할 수 있습니다.
기술 개요
각 워크플로는 Vertex AI Pipelines의 관리형 인스턴스입니다.
Vertex AI Pipelines는 Kubeflow 파이프라인을 실행하는 서버리스 서비스입니다. 파이프라인을 사용하여 머신러닝 및 데이터 준비 태스크를 자동화하고 모니터링할 수 있습니다. 파이프라인의 각 단계에서 파이프라인 워크플로 일부를 수행합니다. 예를 들어 파이프라인에 데이터 분할, 데이터 유형 변환, 모델 학습 단계가 포함될 수 있습니다. 단계는 파이프라인 구성요소의 인스턴스이므로 단계에는 입력, 출력, 컨테이너 이미지가 있습니다. 단계 입력은 파이프라인의 입력에서 설정되거나 이 파이프라인 내의 다른 단계의 출력에 따라 달라질 수 있습니다. 이러한 종속 항목은 파이프라인의 워크플로를 방향성 비순환 그래프(DAG)로 정의합니다.
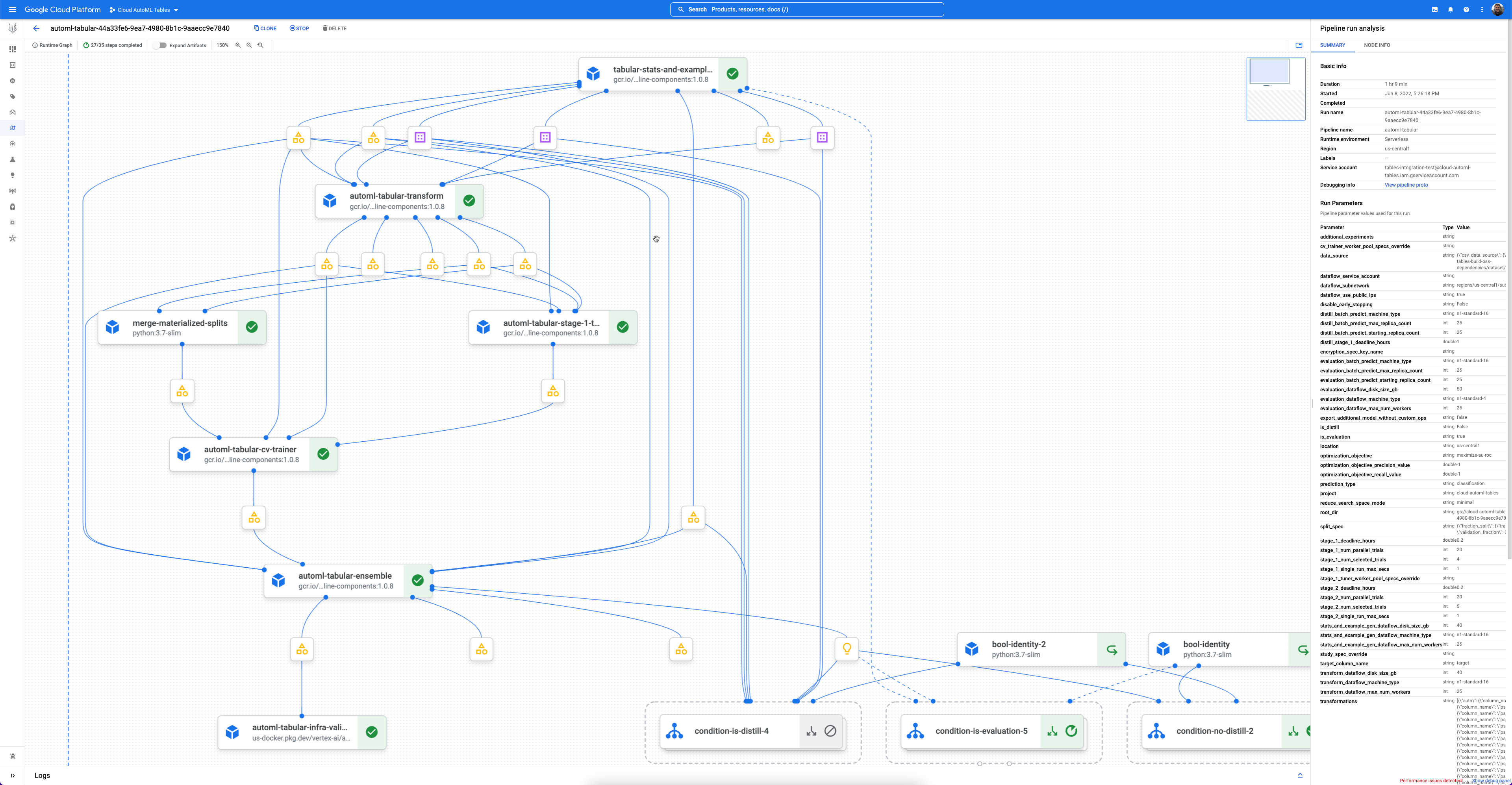
시작하기
대부분의 경우 Google Cloud 파이프라인 구성요소 SDK를 사용하여 파이프라인을 정의하고 실행합니다. 다음 샘플 코드는 이 프로세스를 보여줍니다. 코드를 실제로 구현하는 것은 다를 수 있습니다.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
샘플 Colab 및 노트북이 필요하면 영업 담당자에게 문의하거나 요청 양식을 작성하세요.
버전 관리 및 유지보수
테이블 형식 워크플로에는 애플리케이션의 브레이킹 체인지 없이 지속적인 업데이트와 개선을 지원하는 효율적인 버전 관리 시스템이 있습니다.
각 워크플로는 Google Cloud 파이프라인 구성요소 SDK의 일부로 출시되고 업데이트됩니다. 워크플로에 대한 업데이트 및 수정사항은 해당 워크플로의 새 버전으로 출시됩니다. 이전 버전의 모든 워크플로는 항상 이전 버전의 SDK를 통해 제공됩니다. SDK 버전이 고정되면 워크플로 버전도 고정됩니다.
사용 가능한 워크플로
Vertex AI는 다음과 같은 테이블 형식 워크플로를 제공합니다.
| 이름 | 유형 | 가용성 |
|---|---|---|
| Feature Transform Engine | 특성 추출 | 공개 미리보기 |
| 엔드 투 엔드 AutoML | 분류 및 회귀 | 정식 버전 |
| TabNet | 분류 및 회귀 | 공개 미리보기 |
| 와이드 앤 딥 | 분류 및 회귀 | 공개 미리보기 |
| 예측 | 예측 | 공개 미리보기 |
추가 정보 및 샘플 노트북이 필요하면 영업 담당자에게 문의하거나 요청 양식을 작성하세요.
Feature Transform Engine
Feature Transform Engine에서 특성 선택과 특성 변환을 수행합니다. 특성 선택이 사용 설정되면 Feature Transform Engine에서 순위가 지정된 중요한 특성 집합을 만듭니다. 특성 변환이 사용 설정되면 Feature Transform Engine에서 모델 학습과 모델 서빙에 필요한 입력이 일관되도록 특성을 처리합니다. Feature Transform Engine은 단독으로 또는 테이블 형식 학습 워크플로와 함께 사용할 수 있습니다. TensorFlow 및 비TensorFlow 프레임워크를 모두 지원합니다.
자세한 내용은 특성 추출을 참조하세요.
분류 및 회귀용 테이블 형식 워크플로
엔드 투 엔드 AutoML의 테이블 형식 워크플로
엔드 투 엔드 AutoML의 테이블 형식 워크플로는 분류 및 회귀 태스크를 위한 완전 AutoML 파이프라인입니다. AutoML API와 비슷하지만 제어할 항목과 자동화할 항목을 선택할 수 있습니다. 전체 파이프라인을 제어하는 대신 파이프라인의 모든 단계를 제어할 수 있습니다. 이러한 파이프라인 제어에는 다음이 포함됩니다.
- 데이터 분할
- 특성 추출
- 아키텍처 검색
- 모델 학습
- 모델 앙상블
- 모델 정제
이점
- 크기가 수 TB이고 열이 최대 1,000개까지 있는 대규모 데이터 세트를 지원합니다.
- 아키텍처 유형의 검색 공간을 제한하거나 아키텍처 검색을 건너뛰어 안정성을 높이고 학습 시간을 낮출 수 있습니다.
- 학습 및 아키텍처 검색에 사용되는 하드웨어를 수동으로 선택하여 학습 속도를 향상시킬 수 있습니다.
- 정제를 사용하거나 앙상블 크기를 변경하여 모델 크기를 줄이고 지연 시간을 개선할 수 있습니다.
- 변환된 데이터 테이블, 평가된 모델 아키텍처, 기타 다양한 세부정보를 볼 수 있는 강력한 파이프라인 그래프 인터페이스에서 각 AutoML 구성요소를 검사할 수 있습니다.
- 각 AutoML 구성요소는 매개변수, 하드웨어, 뷰 프로세스 상태, 로그 등을 맞춤설정할 수 있게 하는 등 유연성과 투명성이 확장됩니다.
입력/출력
- Cloud Storage에서 BigQuery 테이블이나 CSV 파일을 입력으로 사용합니다.
- Vertex AI 모델을 출력으로 생성합니다.
- 중간 출력에는 데이터 세트 통계와 데이터 세트 분할이 포함됩니다.
자세한 내용은 엔드 투 엔드 AutoML의 테이블 형식 워크플로를 참조하세요.
TabNet의 테이블 형식 워크플로
TabNet의 테이블 형식 워크플로는 분류 또는 회귀 모델을 학습시키는 데 사용할 수 있는 파이프라인입니다. TabNet은 순차적 주의를 사용하여 각 결정 단계에서 추론할 특성을 선택합니다. 이렇게 하면 학습 용량이 가장 중요한 특징에 사용되므로 해석 가능성과 학습 효율성이 향상됩니다.
이점
- 데이터 세트 크기, 추론 유형, 학습 예산에 따라 적절한 하이퍼파라미터 검색 공간을 자동으로 선택합니다.
- Vertex AI와 통합되었습니다. 학습된 모델은 Vertex AI 모델입니다. 일괄 추론을 실행하거나 온라인 추론에 사용되는 모델을 즉시 배포할 수 있습니다.
- 고유한 모델 해석 가능성을 제공합니다. 의사 결정에 사용된 TabNet 기능에 대한 인사이트를 얻을 수 있습니다.
- GPU 학습을 지원합니다.
입력/출력
Cloud Storage에서 BigQuery 테이블 또는 CSV 파일을 입력으로 가져오고 Vertex AI 모델을 출력으로 제공합니다.
자세한 내용은 TabNet의 테이블 형식 워크플로를 참조하세요.
와이드 앤 딥의 테이블 형식 워크플로
와이드 앤 딥의 테이블 형식 워크플로는 분류 또는 회귀 모델을 학습시키는 데 사용할 수 있는 파이프라인입니다. 와이드 앤 딥은 와이드 선형 모델과 심층신경망을 공동으로 학습시킵니다. 기억과 일반화의 이점을 결합합니다. 일부 온라인 실험 결과, 와이드 앤 딥에서 와이드 전용 및 딥 전용 모델에 비해 Google 스토어 애플리케이션 획득이 크게 증가했습니다.
이점
- Vertex AI와 통합되었습니다. 학습된 모델은 Vertex AI 모델입니다. 일괄 추론을 실행하거나 온라인 추론에 사용되는 모델을 즉시 배포할 수 있습니다.
입력/출력
Cloud Storage에서 BigQuery 테이블 또는 CSV 파일을 입력으로 가져오고 Vertex AI 모델을 출력으로 제공합니다.
자세한 내용은 와이드 앤 딥용 테이블 형식 워크플로를 참조하세요.
예측을 위한 테이블 형식 워크플로
예측을 위한 테이블 형식 워크플로
예측용 테이블 형식 워크플로는 예측 태스크의 전체 파이프라인입니다. AutoML API와 비슷하지만 제어할 항목과 자동화할 항목을 선택할 수 있습니다. 전체 파이프라인을 제어하는 대신 파이프라인의 모든 단계를 제어할 수 있습니다. 이러한 파이프라인 제어에는 다음이 포함됩니다.
- 데이터 분할
- 특성 추출
- 아키텍처 검색
- 모델 학습
- 모델 앙상블
이점
- 크기가 최대 1TB이고 열이 최대 200개까지 있는 대규모 데이터 세트를 지원합니다.
- 아키텍처 유형의 검색 공간을 제한하거나 아키텍처 검색을 건너뛰어 안정성을 높이고 학습 시간을 줄일 수 있습니다.
- 학습과 아키텍처 검색에 사용되는 하드웨어를 수동으로 선택하여 학습 속도를 향상시킬 수 있습니다.
- 앙상블 크기를 변경하여 모델 크기를 줄이고 지연 시간을 줄일 수 있습니다.
- 변환된 데이터 테이블, 평가된 모델 아키텍처, 기타 다양한 세부정보를 볼 수 있는 강력한 파이프라인 그래프 인터페이스에서 각 구성요소를 검사할 수 있습니다.
- 각 구성요소는 매개변수, 하드웨어, 뷰 프로세스 상태, 로그 등을 맞춤설정할 수 있게 하는 등 유연성과 투명성이 확장됩니다.
입력/출력
- Cloud Storage에서 BigQuery 테이블이나 CSV 파일을 입력으로 사용합니다.
- Vertex AI 모델을 출력으로 생성합니다.
- 중간 출력에는 데이터 세트 통계와 데이터 세트 분할이 포함됩니다.
자세한 내용은 예측을 위한 테이블 형식 워크플로를 참조하세요.
다음 단계
- 엔드 투 엔드 AutoML의 테이블 형식 워크플로 알아보기
- TabNet의 테이블 형식 워크플로 알아보기
- 와이드 앤 딥의 테이블 형식 워크플로 알아보기
- 예측을 위한 테이블 형식 워크플로 알아보기
- 특성 추출 알아보기
- 테이블 형식 워크플로 가격 책정 알아보기