Nesta página, você encontra informações detalhadas sobre os parâmetros usados no treinamento do modelo de previsão. Para saber como treinar um modelo de previsão, consulte Treinar um modelo de previsão e Treinar um modelo com o fluxo de trabalho tabular para previsão.
Métodos de treinamento de modelo
Escolha entre os seguintes métodos para treinar o modelo:
Codificador denso de série temporal (TiDE): modelo codificador-decodificador baseado em DNN denso otimizado. Excelente qualidade de modelo com treinamento e inferência rápidos, especialmente para contextos e horizontes longos. Saiba mais.
Transformador de fusão temporal (TFT): modelo de DNN baseado em atenção projetado para produzir alta precisão e interpretabilidade, alinhando o modelo com a tarefa geral de previsão de vários horizontes. Saiba mais.
AutoML (L2L): uma boa opção para vários casos de uso. Saiba mais.
Seq2Seq+: uma boa opção para experimentação. O algoritmo provavelmente terá uma convergência mais rápida do que o AutoML, porque a arquitetura dele é mais simples e usa um espaço de pesquisa menor. Nossos experimentos descobriram que o Seq2Seq+ tem um bom desempenho com um orçamento pequeno e com conjuntos de dados menores do que 1 GB.
Tipo de recurso e disponibilidade na previsão
Cada coluna usada para treinar um modelo de previsão precisa ter um tipo: atributo ou covariável. As variantes são designadas como disponíveis ou indisponíveis no momento da previsão.
| Tipo de série | Disponível no momento da previsão | Descrição | Exemplos | Campos da API |
|---|---|---|---|---|
| Atributo | Disponível | Um atributo é um recurso estático que não muda com o tempo. | Cor do item e descrição do produto | time_series_attribute_columns |
| Covariável | Disponível |
Uma variável exagerada que pode ser alterada com o tempo. Uma covariável disponível no momento da previsão é um indicador principal. Forneça dados de inferência para essa coluna em cada ponto no horizonte de previsão. |
Feriados, promoções planejadas ou eventos. | available_at_forecast_columns |
| Covariável | Indisponível | Uma covariável não disponível no momento da previsão. Não é preciso fornecer valores para esses recursos ao criar uma previsão. | Previsão do tempo. | unavailable_at_forecast_columns |
Saiba mais sobre a relação entre a disponibilidade do recurso e o horizonte de previsão, a janela de contexto e a janela de previsão.
Horizonte de previsão, janela de contexto e janela de previsão
Os recursos de previsão são atributos estáticos ou covariáveis de variante de tempo. Consulte Tipo de recurso e disponibilidade na previsão.
Ao treinar um modelo de previsão, especifique quais dados de treinamento covariáveis são mais importantes para capturar. Isso é expresso na forma de uma janela de previsão, que é uma série de linhas compostas pelo seguinte:
- O contexto ou os dados históricos até o momento da inferência.
- O horizonte ou as linhas usadas para inferência.
Em conjunto, as linhas na janela definem uma instância de série temporal que serve como entrada de modelo: é a forma como a Vertex AI é treinada, avalia e usa para inferência. A linha usada para gerar a janela é a primeira linha do horizonte e a identifica exclusivamente na série temporal.
O horizonte de previsão determina em que ponto do modelo o valor desejado será determinado para cada linha de dados de inferência.
A janela de contexto define o período de deslocamento do modelo durante o treinamento (e as previsões). Em outras palavras, para cada ponto de dados de treinamento, a janela de contexto determina até onde o modelo procura padrões preditivos. Conheça as práticas recomendadas para encontrar um bom valor para a janela de contexto.
Por exemplo, se a janela de contexto = 14 e o horizonte de previsão = 7, cada exemplo de janela terá linhas de 14 + 7 = 21.
Disponibilidade na previsão
As covariáveis de previsão podem ser divididas entre as que estão disponíveis no momento da previsão e as que estão indisponíveis no momento da previsão.
Ao lidar com covariáveis que estão disponíveis no momento da previsão, a Vertex AI considera valores covariáveis da janela de contexto e do horizonte da previsão para treinamento, avaliação e inferência. Ao lidar com covariáveis que não estão disponíveis no momento da previsão, a Vertex AI considera valores covariáveis da janela de contexto, mas exclui explicitamente valores covariáveis do horizonte da previsão.
Estratégias de janela contínua
A Vertex AI gera janelas de previsão com base em dados de entrada usando uma estratégia de janela contínua. A estratégia padrão é Contagem.
- Contagem.
O número de janelas geradas pela Vertex AI não pode exceder um
máximo fornecido pelo usuário. Se o número de linhas no conjunto de dados de entrada for menor que o número máximo de janelas, cada linha será usada para gerar uma janela.
Caso contrário, a Vertex AI
realiza uma amostragem aleatória para selecionar as linhas.
O valor padrão para o número máximo de janelas é
100,000,000. O número máximo de janelas não pode exceder100,000,000. - Passada.
A Vertex AI usa uma em cada X linhas de entrada para
gerar uma janela com um máximo de até 100 milhões de janelas. Essa opção é útil para inferências sazonais ou periódicas. Por exemplo, é possível limitar a previsão a um único
dia da semana ao definir o valor de tamanho da passada como
7. O valor pode estar entre1e1000. - Coluna.
É possível adicionar uma coluna aos dados de entrada em que os valores sejam
TrueouFalse. A Vertex AI gera uma janela para cada linha de entrada em que o valor da coluna éTrue. Os valoresTrueeFalsepodem ser definidos em qualquer ordem, desde que a contagem total de linhasTrueseja menor que100,000,000. Preferimos valores booleanos, mas valores de string também são aceitos. Os valores de string não diferenciam maiúsculas de minúsculas.
Ao gerar menos janelas de 100,000,000 que as janelas padrão, é possível reduzir o tempo necessário para o pré-processamento e a avaliação do modelo. Além disso, a redução
da janela oferece mais controle sobre a distribuição das janelas vistas durante o treinamento.
Se usado corretamente, isso pode gerar resultados melhores e mais consistentes.
Como a janela de contexto e o horizonte de previsão são usados durante o treinamento e as previsões
Suponha que você tenha dados coletados mensalmente, com uma janela de contexto de 5 meses e previsão do horizonte de 5 meses. O treinamento do modelo com 12 meses de dados resultaria nos seguintes conjuntos de entradas e previsões
[1-5]:[6-10][2-6]:[7-11][3-7]:[8-12]
Após o treinamento, o modelo pode ser usado para prever os meses 13 a 17:
[8-12]:[13-17]
O modelo usa apenas os dados que se enquadram na janela de contexto para fazer a previsão. Todos os dados fornecidos que estiverem fora da janela de contexto serão ignorados.
Após a coleta dos dados do 13º mês, eles podem ser usados para fazer previsões até o 18º mês:
[9-13]:[14-18]
Isso pode continuar no futuro, desde que você tenha bons resultados. É possível treinar o modelo com os novos dados. Por exemplo, se você retreinou o modelo depois de adicionar mais seis meses de dados, os dados de treinamento seriam usados da seguinte forma:
[2-6]:[7-11][3-7]:[8-12][4-8]:[9-13][5-9]:[10-14][6-10]:[11-15][7-11]:[12-16][8-12]:[13-17][9-13]:[14-18]
Você pode usar o modelo para prever os meses 19 a 23:
[14-18]:[19-23]
Objetivos de otimização para modelos de previsão
Ao treinar um modelo, a Vertex AI seleciona um objetivo de otimização padrão com base no tipo de modelo e no tipo de dados usado na coluna de destino. Veja na tabela a seguir alguns detalhes sobre os problemas mais adequados para os modelos de previsão:
| Objetivo da otimização | Valor da API | Use este objetivo se você quiser... |
|---|---|---|
| REMQ | minimize-rmse |
Minimizar a raiz do erro médio quadrado (REMQ) Captura valores mais extremos com precisão e é menos enviesado ao agregar inferências. Valor padrão. |
| MAE | minimize-mae |
Minimizar erro médio absoluto (MAE, na sigla em inglês). Ver os valores extremos como outliers, o que impacta menos o modelo. |
| RMSLE | minimize-rmsle |
Minimizar o erro logarítmico quadrado médio (RMSLE, na sigla em inglês). Penaliza o erro conforme o tamanho relativo e não o valor absoluto. É útil quando valores previstos e reais podem ser muito grandes. |
| RMSPE | minimize-rmspe |
Minimizar o erro percentual médio quadrado (RMSPE). Captura uma grande variedade de valores com precisão. Semelhante ao REQM, mas relativo à magnitude desejada. Útil quando o intervalo de valores é grande. |
| WAPE | minimize-wape-mae |
Minimizar a combinação de erro percentual absoluto ponderado (WAPE, na sigla em inglês) e erro médio absoluto (MAE, na sigla em inglês). Útil quando os valores reais são baixos. |
| Perda quantil | minimize-quantile-loss |
Minimize a perda escalonada de pinball para os quantis definidos a fim de quantificar a indefinição nas estimativas. As inferências de quantil quantificam a incerteza das inferências. Elas medem a probabilidade de uma inferência estar dentro de um intervalo. |
Regiões de feriados
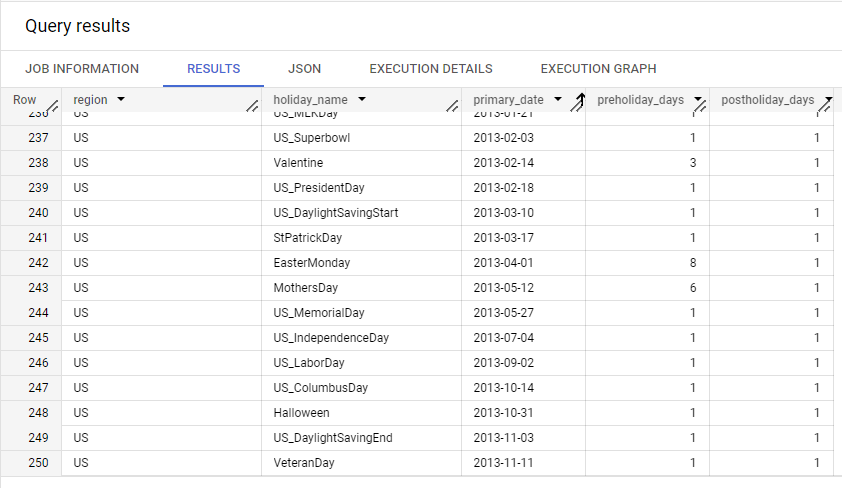
Para determinados casos de uso, os dados de previsão podem apresentar comportamento irregular em dias que correspondem a feriados regionais. Se você quiser que seu modelo considere esse efeito, selecione a região ou as regiões geográficas que correspondem aos dados de entrada. Durante o treinamento, a Vertex AI cria recursos categóricos de datas comemorativas de acordo com o modelo com base na data da coluna de tempo e nas regiões geográficas especificadas.
Veja a seguir um trecho de datas e recursos categóricos de fim de ano para os Estados Unidos. Um recurso categórico é atribuído à data principal, um ou mais dias antes do período de festas e um ou mais dias após o período de festas de fim de ano. Por exemplo, a data principal do Dia das Mães nos EUA em 2013 foi em 12 de maio. Os recursos do Dia das Mães são atribuídos à data principal, seis dias antes do feriado e um dia após o feriado.
| Data | Recurso categórico de fim de ano |
|---|---|
| 2013-05-06 | MothersDay |
| 2013-05-07 | MothersDay |
| 2013-05-08 | MothersDay |
| 2013-05-09 | MothersDay |
| 2013-05-10 | MothersDay |
| 2013-05-11 | MothersDay |
| 2013-05-12 | MothersDay |
| 2013-05-13 | MothersDay |
| 2013-05-26 | US_MemorialDay |
| 2013-05-27 | US_MemorialDay |
| 2013-05-28 | US_MemorialDay |
Os valores aceitáveis para regiões de férias incluem:
GLOBAL: detecta datas comemorativas em todas as regiões do mundo.NA: detecta datas comemorativas na América do Norte.JAPAC: detecta datas comemorativas no Japão e na Ásia-Pacífico.EMEA: detecta datas comemorativas na Europa, no Oriente Médio e na África.LAC: detecta datas comemorativas na América Latina e no Caribe.- Códigos de país ISO 3166-1: detecta datas comemorativas para países individuais.
Para ver a lista completa de datas de feriados para cada região geográfica, consulte a tabela holidays_and_events_for_forecasting no BigQuery. É possível abrir essa tabela pelo console do Google Cloud usando as seguintes etapas:
-
No console do Google Cloud , na seção "BigQuery", acesse a página BigQuery Studio.
- No painel Explorer, abra
o projeto
bigquery-public-data. Se você não encontrar esse projeto ou quiser saber mais, consulte Abrir um conjunto de dados público. - Abra o conjunto de dados
ml_datasets. - Abra a tabela
holidays_and_events_for_forecasting.
Veja a seguir um trecho da tabela holidays_and_events_for_forecasting: