Nesta página, mostramos como treinar um modelo de previsão de um conjunto de dados tabular com o Fluxo de trabalho tabular para previsão.
Para saber mais sobre as contas de serviço usadas por esse fluxo de trabalho, consulte Contas de serviço para fluxos de trabalho tabulares.
Se você receber um erro de cota ao executar o fluxo de trabalho tabular para previsão, talvez seja necessário solicitar uma cota maior. Para saber mais, consulte Gerenciar cotas para fluxos de trabalho tabulares.
O fluxo de trabalho tabular para previsão não é compatível com a exportação de modelos.
APIs de fluxo de trabalho
Esse fluxo de trabalho usa as seguintes APIs:
- Vertex AI
- Dataflow
- Compute Engine
- Cloud Storage
Acessar o URI do resultado do ajuste de hiperparâmetros anterior
Se você já concluiu um fluxo de trabalho tabular para a previsão, use o resultado do ajuste de hiperparâmetro da execução anterior para economizar tempo e recursos de treinamento. Para encontrar o resultado anterior do ajuste de hiperparâmetro, use o console do Google Cloud ou carregue-o de maneira programática com a API.
Console do Google Cloud
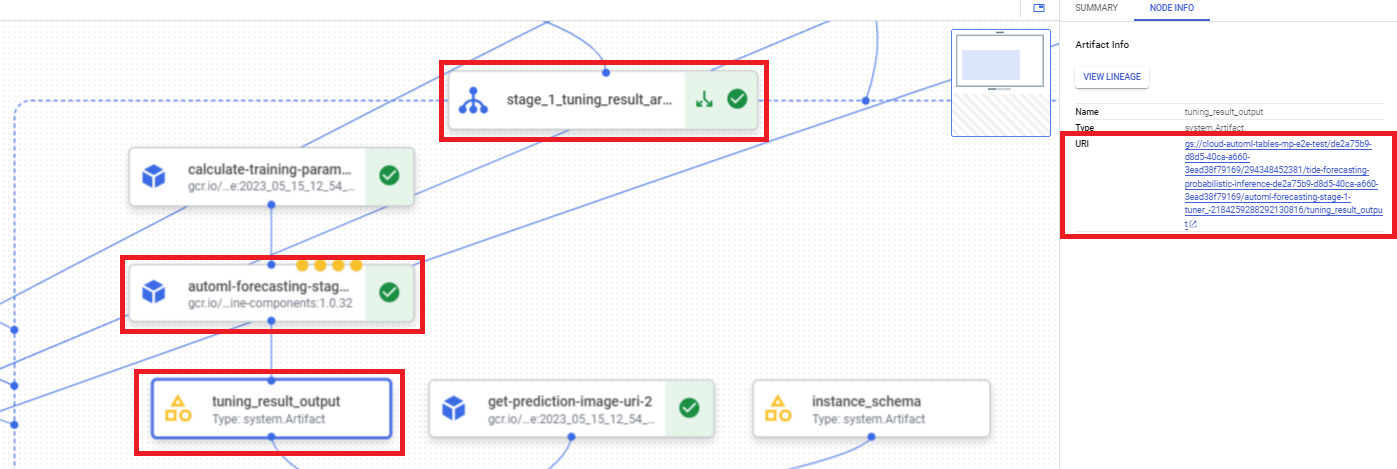
Para encontrar o URI do resultado de ajuste de hiperparâmetros usando o Google Cloud console, execute as seguintes etapas:
No console do Google Cloud , na seção "Vertex AI", acesse a página Pipelines.
Selecione a guia Execuções.
Selecione a execução do pipeline que você quer usar.
Selecione Expandir artefatos.
Clique no componente exit-handler-1.
Clique no componente stage_1_tuning_result_artifact_uri_empty.
Encontre o componente automl-forecasting-stage-1-tuner.
Clique no artefato associado tuning_result_output.
Selecione a guia Informações do nó.
Copie o URI para uso na etapa Treinar um modelo.
API: Python
No exemplo de código a seguir, demonstramos como carregar o resultado do ajuste de hiperparâmetros usando a API. A variável job refere-se à execução anterior do pipeline de treinamento de modelo.
def get_task_detail(
task_details: List[Dict[str, Any]], task_name: str
) -> List[Dict[str, Any]]:
for task_detail in task_details:
if task_detail.task_name == task_name:
return task_detail
pipeline_task_details = job.gca_resource.job_detail.task_details
stage_1_tuner_task = get_task_detail(
pipeline_task_details, "automl-forecasting-stage-1-tuner"
)
stage_1_tuning_result_artifact_uri = (
stage_1_tuner_task.outputs["tuning_result_output"].artifacts[0].uri
)
Treinar um modelo
O exemplo de código a seguir demonstra como executar um pipeline de treinamento de modelo:
job = aiplatform.PipelineJob(
...
template_path=template_path,
parameter_values=parameter_values,
...
)
job.run(service_account=SERVICE_ACCOUNT)
O parâmetro opcional service_account em job.run() permite definir a
conta de serviço dos Pipelines da Vertex AI para uma conta de sua escolha.
A Vertex AI é compatível com os seguintes métodos para treinar o modelo:
Codificador denso de série temporal (TiDE, na sigla em inglês) Para usar esse método de treinamento de modelo, defina os valores de pipeline e parâmetro usando a seguinte função:
template_path, parameter_values = automl_forecasting_utils.get_time_series_dense_encoder_forecasting_pipeline_and_parameters(...)Transformador de fusão temporal (TFT, na sigla em inglês) Para usar esse método de treinamento de modelo, defina os valores de pipeline e parâmetro usando a seguinte função:
template_path, parameter_values = automl_forecasting_utils.get_temporal_fusion_transformer_forecasting_pipeline_and_parameters(...)AutoML (L2L). Para usar esse método de treinamento de modelo, defina os valores de pipeline e parâmetro usando a seguinte função:
template_path, parameter_values = automl_forecasting_utils.get_learn_to_learn_forecasting_pipeline_and_parameters(...)Seq2Seq+. Para usar esse método de treinamento de modelo, defina os valores de pipeline e parâmetro usando a seguinte função:
template_path, parameter_values = automl_forecasting_utils.get_sequence_to_sequence_forecasting_pipeline_and_parameters(...)
Para saber mais, consulte Métodos de treinamento de modelo.
Os dados de treinamento podem ser um arquivo CSV no Cloud Storage ou uma tabela no BigQuery.
Veja a seguir um subconjunto de parâmetros de treinamento de modelo:
| Nome do parâmetro | Tipo | Definição |
|---|---|---|
optimization_objective |
String | Por padrão, a Vertex AI minimiza a raiz do erro médio quadrático (REQM). Se você quiser um objetivo de otimização diferente para seu modelo de previsão, escolha uma das opções em Objetivos de otimização para modelos de previsão. Se você optar por minimizar a perda de quantil, também vai precisar especificar um valor para quantiles. |
enable_probabilistic_inference |
Booleano | Se definido como true, a Vertex AI modela a distribuição de probabilidade da previsão. A inferência probabilística pode melhorar a qualidade do modelo ao lidar com dados com ruído e quantificar a incerteza. Se quantiles forem especificados, a Vertex AI também vai retornar os quantis da distribuição. A inferência probabilística é compatível apenas com os métodos de treinamento do codificador denso de série temporal (TiDE, na sigla em inglês) e do AutoML (L2L). A inferência probabilística é incompatível com o objetivo de otimização minimize-quantile-loss. |
quantiles |
Lista[float] | Quantis a serem usados para o objetivo de otimização de minimize-quantile-loss e inferência probabilística. Forneça uma lista de até cinco números exclusivos entre 0 e 1. |
time_column |
String | A coluna de data/hora. Para saber mais, consulte Requisitos de estrutura de dados. |
time_series_identifier_columns |
List[str] | Colunas do identificador de série temporal. Para saber mais, consulte Requisitos de estrutura de dados. |
weight_column |
String | (Opcional) a coluna de peso. Para saber mais, consulte Adicionar pesos aos seus dados de treinamento. |
time_series_attribute_columns |
List[str] | (Opcional) O nome ou os nomes das colunas que são atributos de série temporal. Para saber mais, consulte Tipo de recurso e disponibilidade na previsão. |
available_at_forecast_columns |
List[str] | (Opcional) Os nomes das colunas covariáveis, cujo valor é conhecido no momento da previsão. Para saber mais, consulte Tipo de recurso e disponibilidade na previsão. |
unavailable_at_forecast_columns |
List[str] | (Opcional) O nome ou os nomes das colunas covariadas cujo valor é desconhecido no momento da previsão. Para saber mais, consulte Tipo de recurso e disponibilidade na previsão. |
forecast_horizon |
Número inteiro | (Opcional) O horizonte de previsão determina em que ponto do modelo o valor desejado será determinado para cada linha de dados de inferência. Para saber mais, consulte horizonte de previsão, janela de contexto e janela de previsão. |
context_window |
Número inteiro | (Opcional) A janela de contexto define o período de deslocamento do modelo durante o treinamento (e as previsões). Em outras palavras, para cada ponto de dados de treinamento, a janela de contexto determina até onde o modelo procura padrões preditivos. Para saber mais, consulte horizonte de previsão, janela de contexto e janela de previsão. |
window_max_count |
Inteiro | (Opcional) A Vertex AI gera janelas de previsão com base em dados de entrada usando
uma estratégia de janela contínua. A estratégia padrão é Contagem. O valor padrão para o número máximo de janelas é 100,000,000. Defina este parâmetro para fornecer um valor personalizado para o número máximo de janelas. Para saber mais, consulte Estratégias de janela contínua. |
window_stride_length |
Inteiro | (Opcional) A Vertex AI gera janelas de previsão com base em dados de entrada usando uma estratégia de janela contínua. Para selecionar a estratégia Stride, defina este parâmetro como o valor do tamanho da passada. Para saber mais, consulte Estratégias de janela contínua. |
window_predefined_column |
String | (Opcional) A Vertex AI gera janelas de previsão com base em dados de entrada usando
uma estratégia de janela contínua. Para selecionar a estratégia Column, defina esse parâmetro como o nome da coluna com valores True ou False. Para saber mais, consulte Estratégias de janela contínua. |
holiday_regions |
List[str] | (Opcional) É possível selecionar uma ou mais regiões geográficas para ativar a modelagem de efeitos de feriados. Durante o treinamento, a Vertex AI cria atributos categóricos de fim de ano no modelo com base na data de time_column e nas regiões geográficas especificadas. Por padrão, a modelagem de efeitos de datas comemorativas está desativada. Para saber mais, consulte Regiões de férias. |
predefined_split_key |
String | (Opcional) Por padrão, a Vertex IA usa um algoritmo de divisão cronológica para
separar os dados de previsão nas três divisões de dados. Se você quiser controlar quais linhas de dados de treinamento serão usadas em cada divisão, forneça o nome da coluna que contém os valores de divisão de dados (TRAIN, VALIDATION, TEST). Para saber mais, consulte Divisão de dados para previsão. |
training_fraction |
Ponto flutuante | (Opcional) Por padrão, a Vertex IA usa um algoritmo de divisão cronológica para separar os dados de previsão nas três divisões de dados. 80% dos dados são atribuídos ao conjunto de treinamento, 10% à divisão de validação e 10% à divisão de teste. Defina este parâmetro se você quiser personalizar a fração dos dados atribuídos ao conjunto de treinamento. Para saber mais, consulte Divisões de dados para previsão. |
validation_fraction |
Ponto flutuante | (Opcional) Por padrão, a Vertex IA usa um algoritmo de divisão cronológica para separar os dados de previsão nas três divisões de dados. 80% dos dados são atribuídos ao conjunto de treinamento, 10% à divisão de validação e 10% à divisão de teste. Defina este parâmetro se você quiser personalizar a fração dos dados atribuídos ao conjunto de validação. Para saber mais, consulte Divisões de dados para previsão. |
test_fraction |
Ponto flutuante | (Opcional) Por padrão, a Vertex IA usa um algoritmo de divisão cronológica para separar os dados de previsão nas três divisões de dados. 80% dos dados são atribuídos ao conjunto de treinamento, 10% à divisão de validação e 10% à divisão de teste. Defina este parâmetro se você quiser personalizar a fração dos dados atribuídos ao conjunto de testes. Para saber mais, consulte Divisões de dados para previsão. |
data_source_csv_filenames |
String | Um URI para um CSV armazenado no Cloud Storage. |
data_source_bigquery_table_path |
String | Um URI de uma tabela do BigQuery. |
dataflow_service_account |
String | (Opcional) Conta de serviço personalizada para executar jobs do Dataflow. É possível configurar o job do Dataflow para usar IPs privados e uma sub-rede VPC específica. Esse parâmetro funciona como uma substituição para a conta de serviço do worker padrão do Dataflow. |
run_evaluation |
Booleano | Se definido como True, a Vertex AI avalia o modelo de ensemble na divisão de teste. |
evaluated_examples_bigquery_path |
String | O caminho do conjunto de dados do BigQuery usado durante a avaliação do modelo. O conjunto de dados serve como destino para os exemplos previstos. Você precisa definir o valor do parâmetro se run_evaluation for definido como True e tiver o seguinte formato: bq://[PROJECT].[DATASET]. |
Transformações
É possível fornecer um mapeamento de dicionário de resoluções automáticas ou de tipo para colunas de atributo. Os tipos compatíveis são: automático, numérico, categórico, texto e carimbo de data/hora.
| Nome do parâmetro | Tipo | Definição |
|---|---|---|
transformations |
Dict[str, List[str]] | Mapeamento de dicionário de resoluções automáticas ou de tipo |
O código a seguir fornece uma função auxiliar para preencher o parâmetro transformations. Ele também demonstra como usar essa função para aplicar transformações automáticas a um conjunto de colunas definido por uma variável features.
def generate_transformation(
auto_column_names: Optional[List[str]]=None,
numeric_column_names: Optional[List[str]]=None,
categorical_column_names: Optional[List[str]]=None,
text_column_names: Optional[List[str]]=None,
timestamp_column_names: Optional[List[str]]=None,
) -> List[Dict[str, Any]]:
if auto_column_names is None:
auto_column_names = []
if numeric_column_names is None:
numeric_column_names = []
if categorical_column_names is None:
categorical_column_names = []
if text_column_names is None:
text_column_names = []
if timestamp_column_names is None:
timestamp_column_names = []
return {
"auto": auto_column_names,
"numeric": numeric_column_names,
"categorical": categorical_column_names,
"text": text_column_names,
"timestamp": timestamp_column_names,
}
transformations = generate_transformation(auto_column_names=features)
Para saber mais sobre transformações, consulte Tipos de dados e transformações.
Opções de personalização do fluxo de trabalho
É possível personalizar o fluxo de trabalho tabular para previsão, definindo valores de argumento que são passados durante a definição do pipeline. É possível personalizar seu fluxo de trabalho das seguintes maneiras:
- Configurar hardware
- Pular pesquisa de arquitetura
Configurar hardware
O parâmetro de treinamento de modelo a seguir permite configurar os tipos de máquina e o número de máquinas para treinamento. Essa é uma boa opção para quem tem um conjunto de dados grande e quer otimizar o hardware da máquina adequadamente.
| Nome do parâmetro | Tipo | Definição |
|---|---|---|
stage_1_tuner_worker_pool_specs_override |
Dict[String, Any] | (Opcional) Configuração personalizada dos tipos de máquina e do número de máquinas para o treinamento. Esse parâmetro configura o componente automl-forecasting-stage-1-tuner do pipeline. |
O código a seguir demonstra como definir o tipo de máquina n1-standard-8 para o
nó principal do TensorFlow e o tipo de máquina n1-standard-4 para o
nó do avaliador do TensorFlow:
worker_pool_specs_override = [
{"machine_spec": {"machine_type": "n1-standard-8"}}, # override for TF chief node
{}, # override for TF worker node, since it's not used, leave it empty
{}, # override for TF ps node, since it's not used, leave it empty
{
"machine_spec": {
"machine_type": "n1-standard-4" # override for TF evaluator node
}
}
]
Pular pesquisa de arquitetura
Com o parâmetro de treinamento de modelo a seguir, é possível executar o pipeline sem a pesquisa de arquitetura e fornecer um conjunto de hiperparâmetros de uma execução de pipeline anterior como alternativa.
| Nome do parâmetro | Tipo | Definição |
|---|---|---|
stage_1_tuning_result_artifact_uri |
String | (Opcional) URI do resultado do ajuste de hiperparâmetros de uma execução de pipeline anterior. |
A seguir
- Saiba mais sobre inferências em lote para modelos de previsão.
- Saiba mais sobre os preços do treinamento de modelos.