Esta guía para principiantes es una introducción al entrenamiento personalizado en Vertex AI. El entrenamiento personalizado se refiere al entrenamiento de un modelo mediante un framework de aprendizaje automático, como TensorFlow, PyTorch o XGBoost.
Objetivos de aprendizaje
Nivel de experiencia con Vertex AI: principiante
Tiempo de lectura estimado: 15 minutos
Aprenderás a hacer lo siguiente:
- Ventajas de usar un servicio gestionado para el entrenamiento personalizado.
- Prácticas recomendadas para empaquetar código de entrenamiento.
- Cómo enviar y monitorizar una tarea de entrenamiento.
¿Por qué usar un servicio de entrenamiento gestionado?
Imagina que estás trabajando en un nuevo problema de aprendizaje automático. Abre un cuaderno, importa tus datos y realiza experimentos. En este caso, crearás un modelo con el framework de aprendizaje automático que elijas y ejecutarás celdas de cuaderno para llevar a cabo un bucle de entrenamiento. Cuando se complete el entrenamiento, evalúa los resultados del modelo, haz los cambios que consideres oportunos y vuelve a ejecutar el entrenamiento. Este flujo de trabajo es útil para experimentar, pero, cuando empieces a pensar en crear aplicaciones de producción con aprendizaje automático, puede que te des cuenta de que ejecutar manualmente las celdas de tu cuaderno no es la opción más cómoda.
Por ejemplo, si tu conjunto de datos y tu modelo son grandes, puedes probar el entrenamiento distribuido. Además, en un entorno de producción, es poco probable que solo tengas que entrenar tu modelo una vez. Con el tiempo, volverás a entrenar tu modelo para asegurarte de que se mantiene actualizado y sigue produciendo resultados valiosos. Si quieres automatizar los experimentos a gran escala o volver a entrenar modelos para una aplicación de producción, utilizar un servicio de entrenamiento de aprendizaje automático gestionado simplificará tus flujos de trabajo.
En esta guía se explica cómo entrenar modelos personalizados en Vertex AI. Como el servicio de entrenamiento está totalmente gestionado, Vertex AI aprovisiona automáticamente los recursos de computación, realiza la tarea de entrenamiento y se asegura de que se eliminen los recursos de computación una vez que se haya completado el trabajo de entrenamiento. Ten en cuenta que hay otras personalizaciones, funciones y formas de interactuar con el servicio que no se describen aquí. Esta guía ofrece una descripción general. Para obtener más información, consulta la documentación de Vertex AI Training.
Descripción general del entrenamiento personalizado
Para entrenar modelos personalizados en Vertex AI, se sigue este flujo de trabajo estándar:
Empaqueta el código de tu aplicación de entrenamiento.
Configura y envía una tarea de entrenamiento personalizada.
Monitoriza la tarea de entrenamiento personalizada.
Empaquetar el código de la aplicación de entrenamiento
Para ejecutar una tarea de entrenamiento personalizada en Vertex AI, se usan contenedores. Los contenedores son paquetes que incluyen el código de las aplicaciones (en este caso, el código de entrenamiento) junto con sus dependencias, como versiones concretas de bibliotecas indispensables para ejecutar el código. Además de ayudar con la gestión de dependencias, los contenedores se pueden ejecutar prácticamente en cualquier lugar, lo que aumenta su portabilidad. Empaquetar el código de entrenamiento con sus parámetros y dependencias en un contenedor para crear un componente portátil es un paso importante a la hora de pasar las aplicaciones de aprendizaje automático del prototipo a la producción.
Antes de poder iniciar un trabajo de entrenamiento personalizado, debes empaquetar tu aplicación de entrenamiento. En este caso, la aplicación de entrenamiento hace referencia a un archivo o a varios archivos que realizan tareas como cargar datos, preprocesar datos, definir un modelo y ejecutar un bucle de entrenamiento. El servicio de entrenamiento de Vertex AI ejecuta el código que proporciones, por lo que depende totalmente de ti los pasos que incluyas en tu aplicación de entrenamiento.
Vertex AI proporciona contenedores precompilados para TensorFlow, PyTorch, XGBoost y Scikit-learn. Estos contenedores se actualizan periódicamente e incluyen bibliotecas comunes que puedes necesitar en tu código de entrenamiento. Puedes ejecutar tu código de entrenamiento con uno de estos contenedores o crear un contenedor personalizado que tenga tu código de entrenamiento y las dependencias preinstaladas.
Hay tres opciones para empaquetar tu código en Vertex AI:
- Envía un único archivo Python.
- Crea una distribución de origen de Python.
- Usar contenedores personalizados.
Archivo de Python
Esta opción es adecuada para hacer experimentos rápidos. Puedes usar esta opción si todo el código necesario para ejecutar tu aplicación de entrenamiento está en un archivo de Python y uno de los contenedores de entrenamiento precompilados de Vertex AI tiene todas las bibliotecas necesarias para ejecutar tu aplicación. Para ver un ejemplo de cómo empaquetar tu aplicación de entrenamiento en un solo archivo de Python, consulta el tutorial del cuaderno Entrenamiento personalizado e inferencia por lotes.
Distribución de código fuente de Python
Puedes crear una distribución de origen de Python que contenga tu aplicación de entrenamiento. Almacenarás la distribución de origen junto con el código de entrenamiento y las dependencias en un segmento de Cloud Storage. Para ver un ejemplo de cómo empaquetar tu aplicación de entrenamiento como una distribución de origen de Python, consulta el tutorial del cuaderno Entrenar, optimizar y desplegar un modelo de clasificación de PyTorch.
Contenedor personalizado
Esta opción es útil cuando quieres tener más control sobre tu aplicación o cuando quieres ejecutar código que no esté escrito en Python. En este caso, tendrás que escribir un Dockerfile, crear tu imagen personalizada y subirla a Artifact Registry. Para ver un ejemplo de cómo contenerizar tu aplicación de entrenamiento, consulta el tutorial del cuaderno Perfil del rendimiento del entrenamiento de modelos con Profiler.
Estructura recomendada de la solicitud de formación
Si decides empaquetar tu código como una distribución de origen de Python o como un contenedor personalizado, te recomendamos que estructures tu aplicación de la siguiente manera:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Crea un directorio para almacenar todo el código de tu aplicación de entrenamiento. En este caso, training-application-dir. Este directorio contendrá un archivo setup.py si usas una distribución de origen de Python o un archivo Dockerfile si usas un contenedor personalizado.
En ambos casos, este directorio de nivel superior también contendrá un subdirectorio trainer, que incluye todo el código para ejecutar el entrenamiento. En trainer,
task.py es el punto de entrada principal de tu aplicación. Este archivo ejecuta el entrenamiento del modelo. Puedes poner todo el código en este archivo, pero en las aplicaciones de producción es probable que tengas archivos adicionales, como model.py, data.py y utils.py, por mencionar algunos.
Realizar un entrenamiento personalizado
Las tareas de entrenamiento en Vertex AI aprovisionan automáticamente recursos de computación, ejecutan el código de la aplicación de entrenamiento y aseguran la eliminación de los recursos de computación una vez que se completa la tarea de entrenamiento.
A medida que desarrolles flujos de trabajo más complejos, es probable que uses el SDK de Vertex AI para Python para configurar, enviar y monitorizar tus trabajos de entrenamiento. Sin embargo, la primera vez que ejecutes una tarea de entrenamiento personalizada, te resultará más fácil usar la Google Cloud consola.
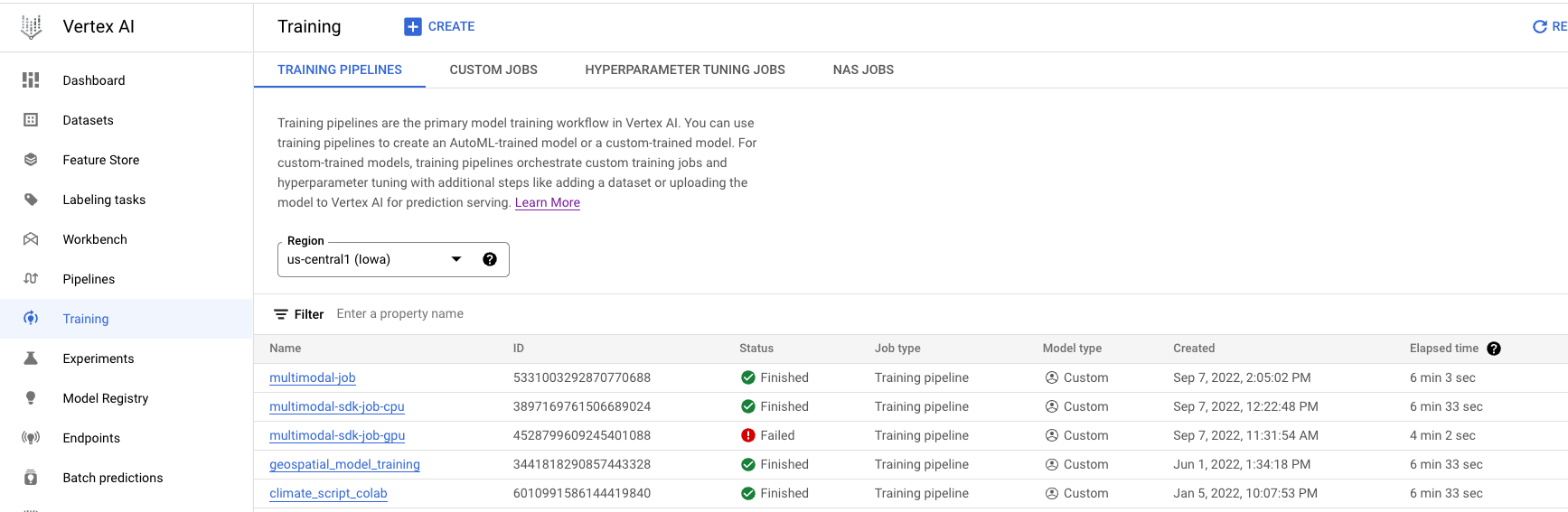
- Ve a Entrenamiento en la sección Vertex AI de la consola de Cloud. Para crear un trabajo de entrenamiento, haz clic en el botón CREAR.
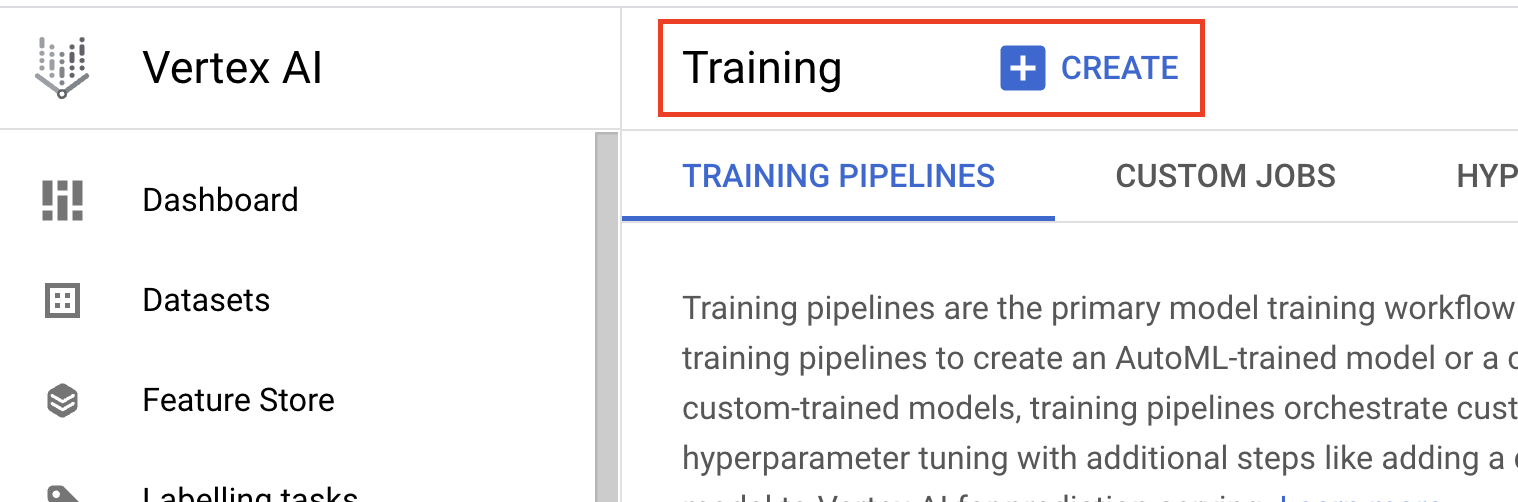
- En Método de entrenamiento del modelo, selecciona Entrenamiento personalizado (avanzado).
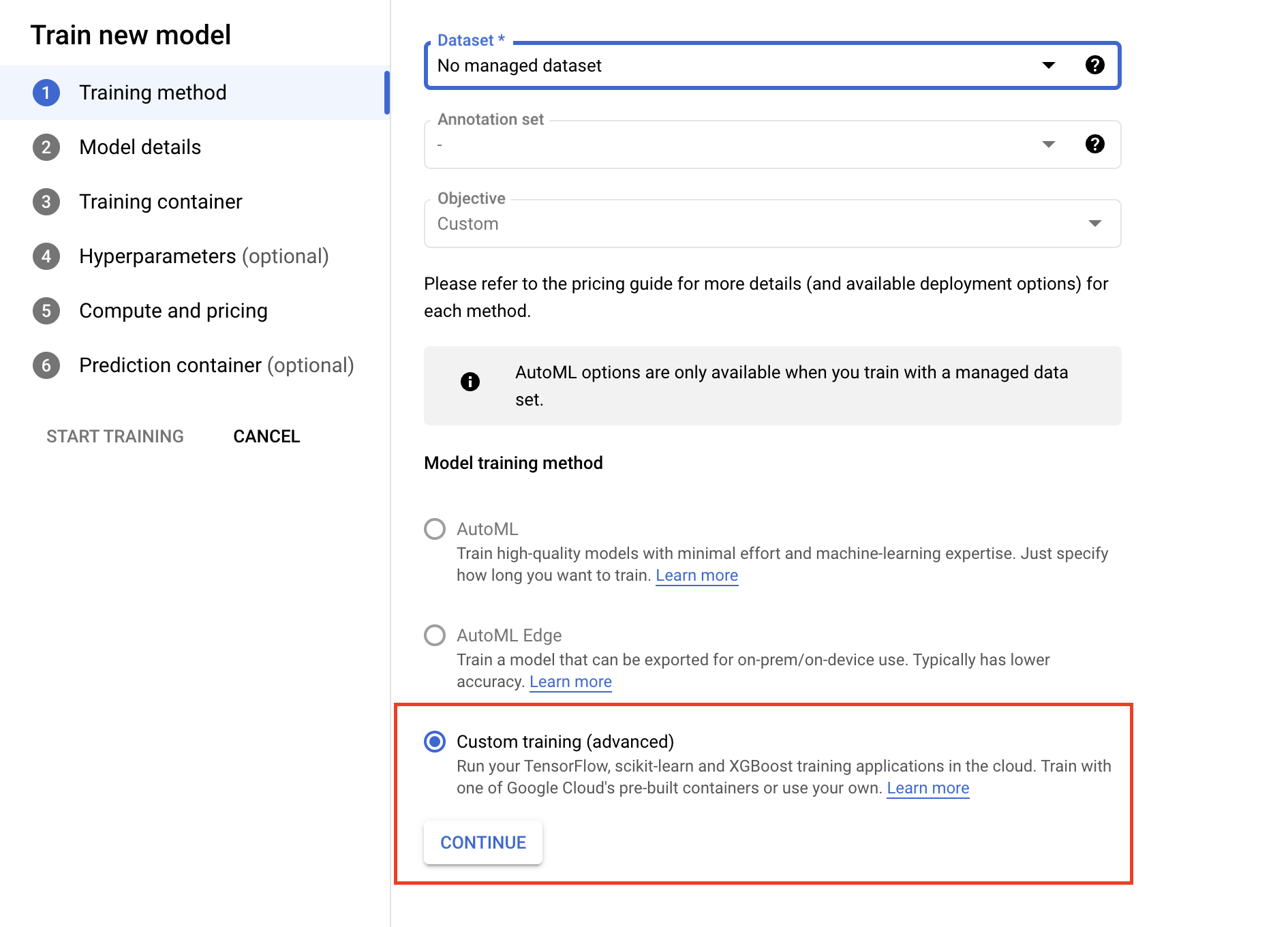
- En la sección Training Container (Contenedor de entrenamiento), selecciona un contenedor precompilado o personalizado, en función de cómo hayas empaquetado tu aplicación.
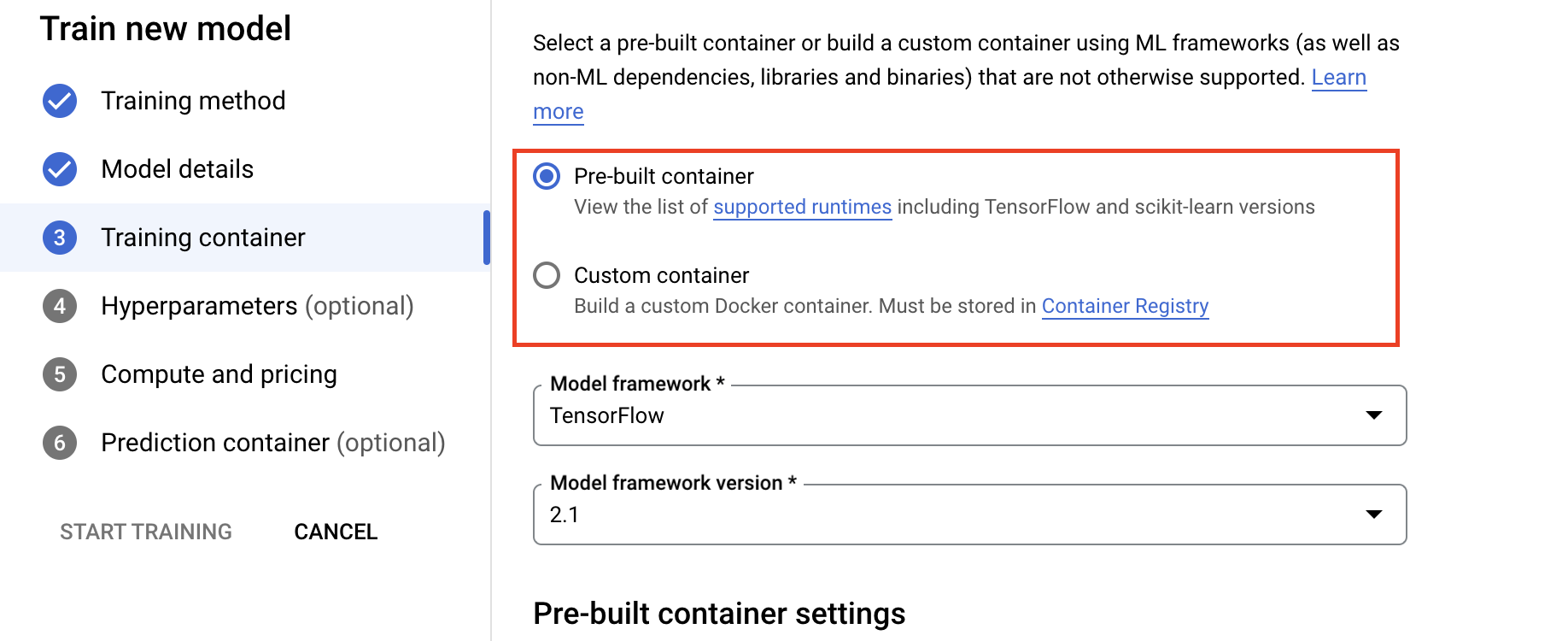
- En Computación y precios, especifica el hardware de la tarea de entrenamiento. Para el entrenamiento de un solo nodo, solo tienes que configurar el grupo de trabajadores 0. Si te interesa llevar a cabo un entrenamiento distribuido, tendrás que conocer los demás grupos de trabajadores. Puedes consultar más información en Entrenamiento distribuido.
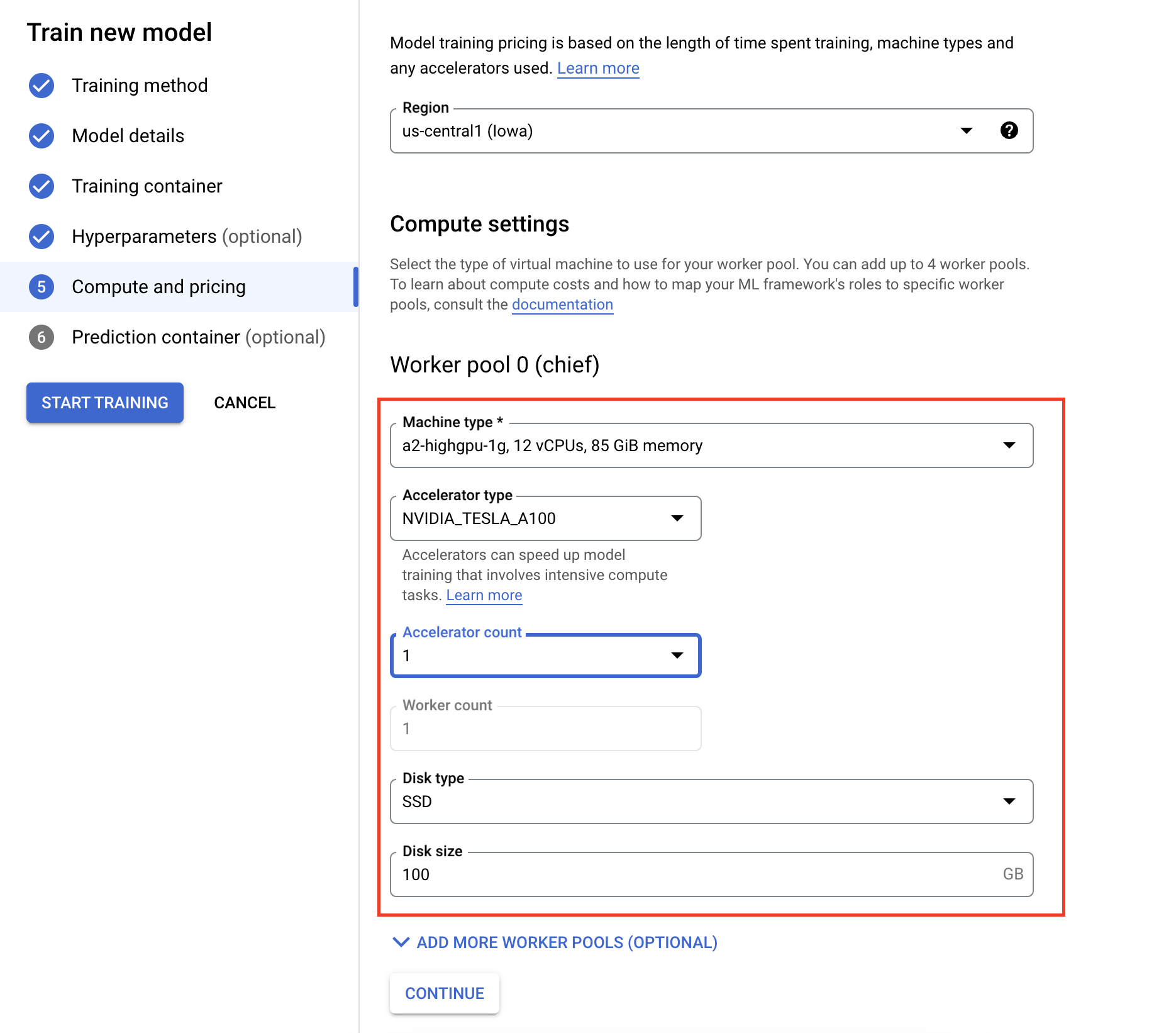
Configurar el contenedor de inferencia es opcional. Si solo quieres entrenar un modelo en Vertex AI y acceder a los artefactos del modelo guardado resultante, puedes omitir este paso. Si quieres alojar y desplegar el modelo resultante en el servicio de inferencia gestionado de Vertex AI, tendrás que configurar un contenedor de inferencia. Para obtener más información, consulta el artículo Obtener inferencias de un modelo entrenado personalizado.
Monitorizar tareas de entrenamiento
Puedes monitorizar tu trabajo de entrenamiento en la consola de Google Cloud . Verás una lista con todos los trabajos que se han ejecutado. Puedes hacer clic en un trabajo concreto y examinar los registros si algo va mal.