Este guia para principiantes é uma introdução à obtenção de inferências de modelos personalizados no Vertex AI.
Objetivos de aprendizagem
Nível de experiência do Vertex AI: principiante
Tempo de leitura estimado: 15 minutos
O que vai aprender:
- Vantagens da utilização de um serviço de inferência gerido.
- Como funcionam as inferências em lote no Vertex AI.
- Como funcionam as inferências online no Vertex AI.
Por que motivo deve usar um serviço de inferência gerido?
Imagine que lhe foi atribuída a tarefa de criar um modelo que recebe como entrada uma imagem de uma planta e prevê a espécie. Pode começar por preparar um modelo num bloco de notas, experimentando diferentes hiperparâmetros e arquiteturas. Quando tiver um modelo preparado, pode chamar o método predict na sua framework de ML preferencial e testar a qualidade do modelo.
Este fluxo de trabalho é excelente para a experimentação, mas quando quiser usar o modelo para obter inferências em muitos dados ou obter inferências de baixa latência em tempo real, vai precisar de algo mais do que um bloco de notas. Por exemplo, suponhamos que está a tentar medir a biodiversidade de um ecossistema específico e, em vez de ter humanos a identificar e contar manualmente as espécies de plantas na natureza, quer usar este modelo de AA para classificar grandes lotes de imagens. Se estiver a usar um bloco de notas, pode atingir restrições de memória. Além disso, a obtenção de inferências para todos esses dados é provavelmente uma tarefa de execução prolongada que pode exceder o tempo limite no seu bloco de notas.
Ou, e se quisesse usar este modelo numa aplicação em que os utilizadores pudessem carregar imagens de plantas e identificá-las imediatamente? Precisa de um local para alojar o modelo que existe fora de um bloco de notas que a sua aplicação pode chamar para uma inferência. Além disso, é improvável que tenha tráfego consistente para o seu modelo, pelo que vai querer um serviço que possa ser dimensionado automaticamente quando necessário.
Em todos estes casos, um serviço de inferência gerido reduz a fricção do alojamento e da utilização dos seus modelos de ML. Este guia apresenta uma introdução à obtenção de inferências de modelos de ML no Vertex AI. Tenha em atenção que existem personalizações, funcionalidades e formas adicionais de interagir com o serviço que não são abordadas aqui. Este guia destina-se a fornecer uma vista geral. Para mais informações, consulte a documentação sobre inferências da Vertex AI.
Vista geral do serviço de inferência gerido
O Vertex AI suporta inferências em lote e online.
A inferência em lote é um pedido assíncrono. É adequado quando não precisa de uma resposta imediata e quer processar dados acumulados numa única solicitação. No exemplo abordado na introdução, este seria o exemplo de utilização de caracterização da biodiversidade.
Se quiser obter inferências de baixa latência a partir de dados transmitidos ao seu modelo em tempo real, pode usar a inferência online. No exemplo abordado na introdução, este seria o exemplo de utilização em que quer incorporar o seu modelo numa app que ajude os utilizadores a identificar imediatamente espécies de plantas.
Carregue o modelo para o Registo de modelos do Vertex AI
Para usar o serviço de previsão, o primeiro passo é carregar o seu modelo de ML preparado para o Registo de modelos Vertex AI. Este é um registo onde pode gerir o ciclo de vida dos seus modelos.
Crie um recurso de modelo
Quando prepara modelos com o serviço de preparação personalizada da Vertex AI, pode importar automaticamente o modelo para o registo após a conclusão da tarefa de preparação. Se ignorou esse passo ou preparou o modelo fora do Vertex AI, pode carregá-lo manualmente através da Google Cloud consola ou do SDK Vertex AI para Python indicando uma localização do Cloud Storage com os artefactos do modelo guardados. O formato destes artefactos do modelo pode ser savedmodel.pb, model.joblib, etc., consoante a framework de AA que estiver a usar.
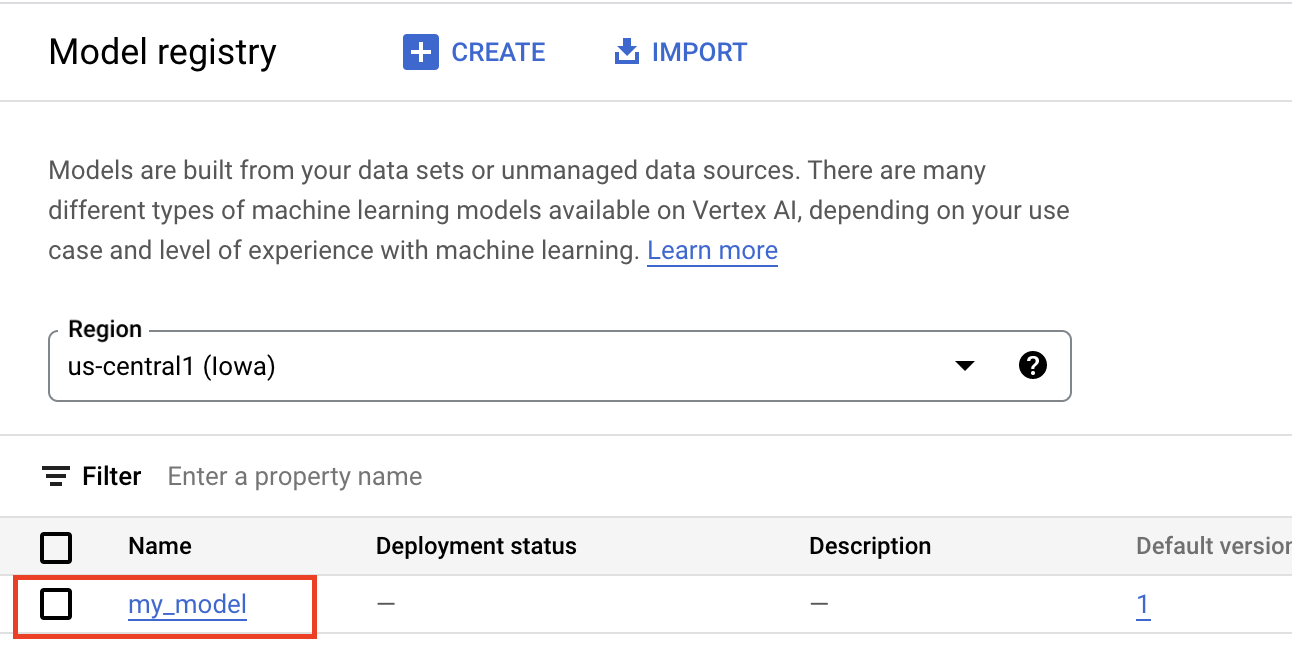
O carregamento de artefactos para o Registo de modelos do Vertex AI cria um recurso Model, que é visível na Google Cloud consola:
Selecione um contentor
Quando importa um modelo para o Registo de modelos da Vertex AI, tem de o associar a um contentor para que a Vertex AI sirva pedidos de inferência.
Contentores pré-criados
O Vertex AI fornece contentores pré-criados que pode usar para inferências. Os contentores pré-criados estão organizados por framework de ML e versão do framework, e fornecem servidores de inferência HTTP que pode usar para publicar inferências com uma configuração mínima. Só executam a operação de inferência da framework de aprendizagem automática. Por isso, se precisar de pré-processar os seus dados, isso tem de acontecer antes de fazer o pedido de inferência. Da mesma forma, qualquer pós-processamento tem de ocorrer depois de fazer o pedido de inferência. Para ver um exemplo de utilização de um contentor pré-criado, consulte o bloco de notas Apresentação de modelos de imagens PyTorch com contentores pré-criados no Vertex AI.
Contentores personalizados
Se o seu exemplo de utilização exigir bibliotecas que não estão incluídas nos contentores pré-criados ou se tiver transformações de dados personalizadas que quer realizar como parte do pedido de inferência, pode usar um contentor personalizado que cria e envia para o Artifact Registry. Embora os contentores personalizados permitam uma maior personalização, o contentor tem de executar um servidor HTTP. Especificamente, o contentor tem de ouvir e responder a verificações de vitalidade, verificações de estado e pedidos de inferência. Na maioria dos casos, usar um contentor pré-criado, se possível, é a opção recomendada e mais simples. Para ver um exemplo de utilização de um contentor personalizado, consulte o bloco de notas PyTorch Image Classification Single GPU using Vertex Training with Custom Container
Rotinas de inferência personalizadas
Se o seu exemplo de utilização exigir transformações de pré e pós-processamento personalizadas e não quiser a sobrecarga de criar e manter um contentor personalizado, pode usar rotinas de inferência personalizadas. Com as rotinas de inferência personalizadas, pode fornecer as suas transformações de dados como código Python e, nos bastidores, o SDK Vertex AI para Python cria um contentor personalizado que pode testar localmente e implementar no Vertex AI. Para ver um exemplo de utilização de rotinas de inferência personalizadas, consulte o bloco de notas Rotinas de inferência personalizadas com o Sklearn
Obtenha inferências em lote
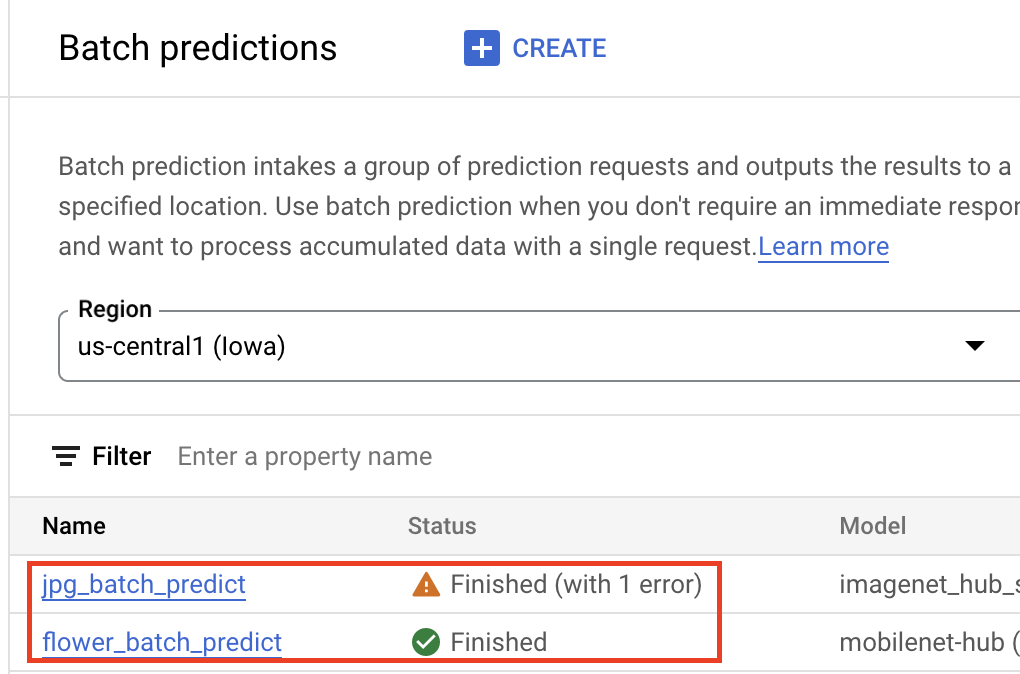
Assim que o modelo estiver no Registo de modelos do Vertex AI, pode enviar um trabalho de previsão em lote a partir da Google Cloud consola ou do SDK Vertex AI para Python. Especifica a localização dos dados de origem, bem como a localização no Cloud Storage ou no BigQuery onde quer que os resultados sejam guardados. Também pode especificar o tipo de máquina no qual quer que esta tarefa seja executada e quaisquer aceleradores opcionais. Uma vez que o serviço de inferências é totalmente gerido, a Vertex AI aprovisiona automaticamente os recursos de computação, executa a tarefa de inferência e garante a eliminação dos recursos de computação assim que a tarefa de inferência terminar. Pode acompanhar o estado das suas tarefas de inferência em lote na Google Cloud consola.
Obtenha inferências online
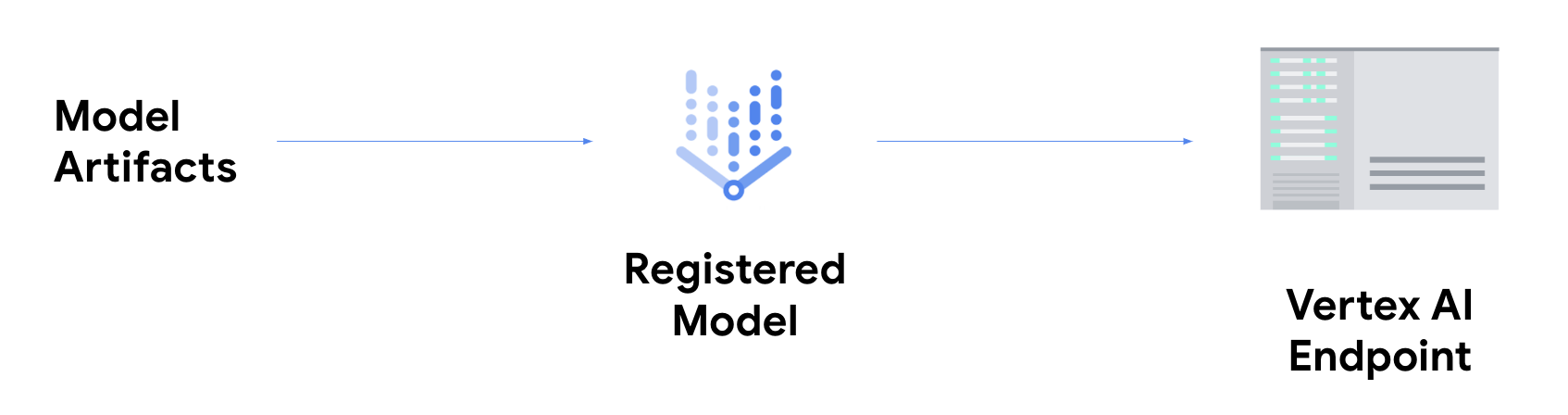
Se quiser obter inferências online, tem de dar o passo adicional de implementar o seu modelo num ponto final do Vertex AI.
Isto associa os artefactos do modelo a recursos físicos para publicação com baixa latência e cria um recurso DeployedModel.
Depois de implementado num ponto final, o modelo aceita pedidos como qualquer outro ponto final REST, o que significa que pode chamá-lo a partir de uma função do Cloud Run, de um chatbot, de uma app Web, etc. Tenha em atenção que pode implementar vários modelos num único ponto final, dividindo o tráfego entre eles. Esta funcionalidade é útil, por exemplo, se quiser implementar uma nova versão do modelo, mas não quiser direcionar todo o tráfego para o novo modelo imediatamente. Também pode implementar o mesmo modelo em vários pontos finais.
Recursos para obter inferências de modelos personalizados na Vertex AI
Para saber mais sobre a alojamento e a publicação de modelos no Vertex AI, consulte os seguintes recursos ou consulte o repositório do GitHub de exemplos do Vertex AI.
- Vídeo sobre como obter previsões
- Prepare e publique um modelo do TensorFlow com um contentor pré-criado
- Publicar modelos de imagens PyTorch com contentores pré-criados no Vertex AI
- Implemente um modelo Stable Diffusion com um contentor pré-criado
- Rotinas de inferência personalizadas com o Sklearn