이 초보자 가이드는 Vertex AI에 대한 커스텀 모델에서 예측을 수행하는 방법을 소개합니다.
학습 목표
Vertex AI 환경 수준: 초급
예상 읽기 시간: 15분
학습할 내용:
- 관리형 예측 서비스를 사용할 때의 이점
- Vertex AI에서 일괄 예측이 작동하는 방식
- Vertex AI에서 온라인 예측 작동 방법
관리형 예측 서비스를 사용해야 하는 이유
식물의 이미지를 입력으로 받아 종을 예측하는 모델을 만드는 작업을 맡았다고 가정해 보겠습니다. 노트북에서 모델을 학습하여 다양한 하이퍼파라미터와 아키텍처를 시도해 볼 수 있습니다. 학습된 모델이 있으면 선택한 ML 프레임워크에서 predict 메서드를 호출하여 모델 품질을 테스트할 수 있습니다.
이 워크플로는 실험에 적합하지만 모델을 사용하여 많은 데이터에 대한 예측을 가져오거나 짧은 지연 시간 예측을 가져오려면 노트북 이상의 것이 필요합니다. 예를 들어 특정 생태계의 생물 다양성을 측정하려 하는데 인간이 야생에서 직접 식물 종의 수를 식별하고 세는 대신 이 ML 모델을 사용하여 대규모 이미지 배치를 분류한다고 가정해 보겠습니다. 노트북을 사용하는 경우 메모리 제약이 발생할 수 있습니다. 또한 모든 데이터에 대한 예측을 수행하는 것이 노트북에서 시간 초과될 수 있는 장기 실행 작업일 수 있습니다.
또는 사용자가 식물 이미지를 업로드하고 즉시 식별할 수 있는 애플리케이션에서 이 모델을 사용하고 싶다면 어떻게 해야 하나요? 애플리케이션에서 예측을 위해 호출할 수 있는 노트북 외부에 있는 모델을 호스팅할 공간이 필요합니다. 또한 모델에 대한 트래픽이 일정하지 않을 수 있으므로 필요한 경우 자동 확장 가능한 서비스가 필요할 수 있습니다.
이러한 모든 경우에 관리형 예측 서비스는 ML 모델을 호스팅하고 사용하는 데 따른 불편을 줄입니다. 이 가이드에서는 Vertex AI의 ML 모델에서 예측을 수행하는 방법을 소개합니다. 여기에서는 다루지 않지만 추가 맞춤설정, 기능 및 서비스와 상호작용하는 방법이 포함됩니다. 이 가이드에서는 개요를 제공합니다. 자세한 내용은 Vertex AI 예측 문서를 참조하세요.
관리형 예측 서비스 개요
Vertex AI는 일괄 예측과 온라인 예측을 지원합니다.
일괄 예측은 비동기식 요청입니다. 즉각적인 응답이 필요하지 않고 누적된 데이터를 단일 요청으로 처리하려는 경우에 적합합니다. 소개에서 설명한 예시에서 이것은 생물 다양성 특성화 사용 사례입니다.
모델에 전달되는 데이터에서 지연 시간이 짧은 예측을 가져오려면 온라인 예측을 사용하면 됩니다. 소개에서 설명한 예시에서 이것은 사용자가 식물 종을 즉시 식별하는 데 도움이 되는 앱에 모델을 포함하려는 사용 사례입니다.
모델을 Vertex AI Model Registry에 업로드합니다.
예측 서비스를 사용하기 위한 첫 번째 단계는 학습된 ML 모델을 Vertex AI Model Registry에 업로드하는 것입니다. 모델의 수명 주기를 관리할 수 있는 레지스트리입니다.
모델 리소스 만들기
Vertex AI 커스텀 학습 서비스로 모델을 학습할 때 학습 작업이 완료되면 모델을 레지스트리로 자동으로 가져올 수 있습니다. 해당 단계를 건너뛰거나 Vertex AI 외부에서 모델을 학습시킨 경우 Google Cloud 콘솔 또는 저장된 모델 아티팩트가 있는 Cloud Storage 위치를 가리키는 Python용 Vertex AI SDK를 통해 수동으로 업로드할 수 있습니다. 이러한 모델 아티팩트의 형식은 사용 중인 ML 프레임워크에 따라 savedmodel.pb, model.joblib 등이 될 수 있습니다.
Vertex AI Model Registry에 아티팩트를 업로드하면 Google Cloud 콘솔에 표시되는 Model 리소스가 생성됩니다.
컨테이너를 선택합니다.
Vertex AI Model Registry로 모델을 가져올 때 Vertex AI의 컨테이너와 연결하여 예측 요청을 제공해야 합니다.
사전 빌드된 컨테이너
Vertex AI는 예측에 사용할 수 있는 사전 빌드된 컨테이너를 제공합니다. 사전 빌드된 컨테이너는 ML 프레임워크 및 프레임워크 버전으로 구성되며 최소한의 구성으로 예측을 제공하는 데 사용할 수 있는 HTTP 예측 서버를 제공합니다. 머신러닝 프레임워크의 예측 작업만 수행하므로 데이터를 사전 처리해야 하는 경우 예측 요청을 하기 전에 해당 작업이 수행되어야 합니다. 마찬가지로 후처리는 예측 요청을 실행한 후에 실행해야 합니다. 사전 빌드된 컨테이너 사용 예시는 Vertex AI에서 사전 빌드된 컨테이너로 PyTorch 이미지 모델 제공 노트북을 참조하세요.
커스텀 컨테이너
사전 빌드된 컨테이너에 포함되지 않은 라이브러리가 사용 사례에 필요한 경우 또는 예측 요청의 일부로 수행하려는 커스텀 데이터 변환이 있는 경우 빌드하여 Artifact Registry에 푸시하는 커스텀 컨테이너를 사용할 수도 있습니다. 커스텀 컨테이너를 사용하면 더 세부적으로 맞춤설정할 수 있지만 컨테이너에서 HTTP 서버를 실행해야 합니다. 특히 컨테이너가 활성 확인, 상태 확인, 예측 요청을 리슨하고 여기에 응답해야 합니다. 대부분의 경우 가능한 한 사전 빌드된 컨테이너를 사용하는 것이 좋으며, 더 간단한 옵션입니다. 커스텀 컨테이너 사용 예시는 커스텀 컨테이너에서 Vertex Training을 사용하여 PyTorch 이미지 분류 단일 GPU 노트북을 참조하세요.
커스텀 예측 루틴
사용 사례에 커스텀 사전 및 사후 처리 변환이 필요하고 커스텀 컨테이너 빌드 및 유지보수 오버헤드를 원하지 않는 경우 커스텀 예측 루틴을 사용할 수 있습니다. 커스텀 예측 루틴을 사용하면 데이터 변환을 Python 코드로 제공할 수 있으며, 백그라운드에서 Python용 Vertex AI SDK가 로컬에서 테스트하고 Vertex AI에 배포할 수 있는 커스텀 컨테이너를 빌드합니다. 커스텀 예측 루틴 사용 예시는 Sklearn으로 커스텀 예측 루틴 노트북을 참조하세요.
일괄 예측 가져오기
모델이 Vertex AI Model Registry에 있으면 Google Cloud console 또는 Python용 Vertex AI SDK에서 일괄 예측 작업을 제출할 수 있습니다. 소스 데이터의 위치와 Cloud Storage 또는 BigQuery에서 결과를 저장하려는 위치를 지정합니다. 또한 이 작업을 실행할 머신 유형과 모든 가속기(선택사항)를 지정할 수 있습니다. 예측 서비스는 완전 관리형이기 때문에 Vertex AI는 컴퓨팅 리소스를 자동으로 프로비저닝하고, 예측 작업을 수행하고, 예측 작업이 완료되면 컴퓨팅 리소스를 반드시 삭제합니다. Google Cloud console에서 일괄 예측 작업의 상태를 추적할 수 있습니다.
온라인 예측 수행
온라인 예측을 수행하려면 Vertex AI 엔드포인트에 모델 배포라는 추가 단계를 수행해야 합니다.
이렇게 하면 지연 시간이 짧은 서비스를 제공하기 위해 모델 아티팩트가 물리적 리소스와 연결되고 DeployedModel 리소스가 생성됩니다.
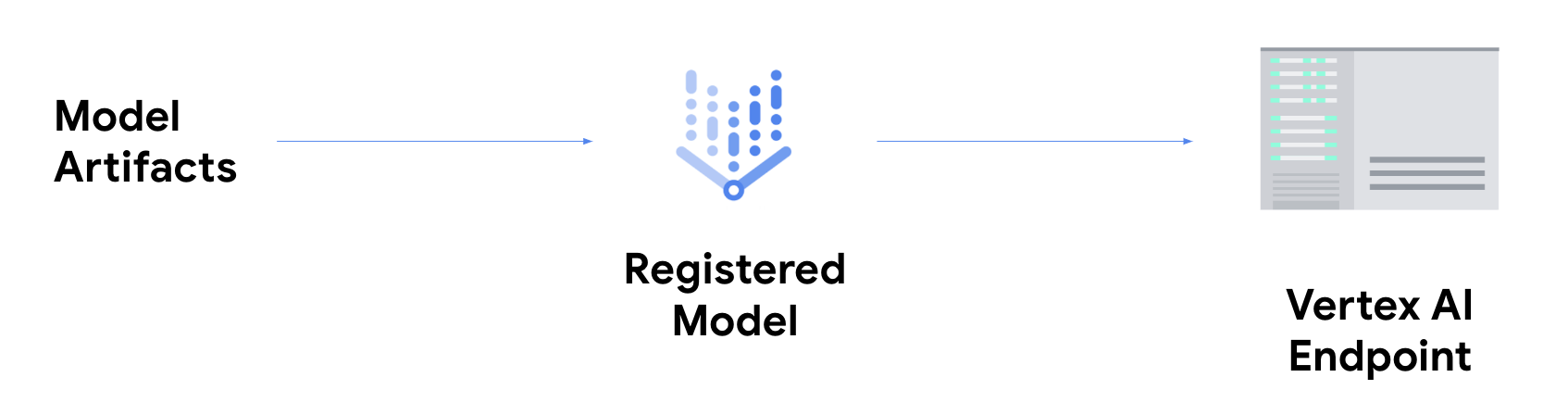
모델이 엔드포인트에 배포되면 다른 REST 엔드포인트와 마찬가지로 요청을 수락합니다. 즉, Cloud Run Functions, 챗봇, 웹 앱 등에서 호출할 수 있습니다. 단일 엔드포인트에 여러 모델을 배포하여 트래픽을 분할할 수 있습니다. 이 기능은 예를 들어 새 모델 버전을 출시하고 싶지만 모든 트래픽을 새 모델로 즉시 이전하지 않으려는 경우에 유용합니다. 동일한 모델을 여러 엔드포인트에 배포할 수도 있습니다.
Vertex AI의 커스텀 모델에서 예측을 수행하기 위한 리소스
Vertex AI에서 모델을 호스팅하고 제공하는 방법에 관한 자세한 내용은 다음 리소스를 참조하거나 Vertex AI 샘플 GitHub 저장소를 참조하세요.
- 예측 수행 동영상
- 사전 빌드된 컨테이너를 사용하여 TensorFlow 모델 학습 및 제공
- Vertex AI에서 사전 빌드된 컨테이너로 PyTorch 이미지 모델 제공
- 사전 빌드된 컨테이너를 사용하여 안정적인 분산 모델 제공
- Sklearn을 사용한 커스텀 예측 루틴