Panduan pemula ini adalah pengantar untuk mendapatkan inferensi dari model kustom di Vertex AI.
Tujuan Pembelajaran
Tingkat pengalaman Vertex AI: Pemula
Perkiraan waktu baca: 15 menit
Yang akan Anda pelajari:
- Manfaat menggunakan layanan inferensi terkelola.
- Cara kerja inferensi batch di Vertex AI.
- Cara kerja inferensi online di Vertex AI.
Mengapa menggunakan layanan inferensi terkelola?
Bayangkan Anda ditugaskan untuk membuat model yang mengambil gambar tanaman sebagai input, dan memprediksi spesies tersebut. Anda mungkin akan mulai dengan melatih model di
notebook, dengan mencoba berbagai hyperparameter dan arsitektur. Jika sudah memiliki model terlatih, Anda dapat memanggil metode predict dalam framework ML pilihan Anda dan menguji kualitas model.
Alur kerja ini bagus untuk eksperimen, tetapi saat Anda ingin menggunakan model untuk mendapatkan inferensi pada banyak data, atau mendapatkan inferensi latensi rendah dengan cepat, Anda akan membutuhkan lebih dari sekadar notebook. Misalnya, Anda mencoba mengukur keanekaragaman hayati ekosistem tertentu dan alih-alih meminta manusia mengidentifikasi dan menghitung spesies tanaman secara manual di alam liar, Anda ingin menggunakan model ML ini untuk mengklasifikasikan kumpulan gambar dalam jumlah besar. Jika menggunakan notebook, Anda mungkin mengalami batasan memori. Selain itu, mendapatkan inferensi untuk semua data tersebut kemungkinan besar akan menjadi tugas yang berjalan lama dan dapat habis waktunya di notebook Anda.
Atau bagaimana jika Anda ingin menggunakan model ini di aplikasi di mana pengguna dapat mengupload gambar tanaman dan tanaman tersebut dapat langsung diidentifikasi? Anda memerlukan tempat untuk menghosting model yang ada di luar notebook yang dapat dipanggil oleh aplikasi Anda untuk inferensi. Selain itu, sangat kecil kemungkinannya Anda akan memiliki traffic yang konsisten ke model, jadi sebaiknya gunakan layanan yang dapat menskalakan otomatis saat diperlukan.
Dalam semua kasus ini, layanan inferensi terkelola akan mengurangi hambatan dalam menghosting dan menggunakan model ML Anda. Panduan ini memberikan pengantar untuk mendapatkan inferensi dari model ML di Vertex AI. Perhatikan bahwa ada penyesuaian, fitur, dan cara tambahan untuk berinteraksi dengan layanan yang tidak dibahas di sini. Panduan ini ditujukan untuk memberikan ringkasan. Untuk mengetahui informasi selengkapnya, lihat dokumentasi inferensi Vertex AI.
Ringkasan layanan inferensi terkelola
Vertex AI mendukung inferensi batch dan online.
Inferensi batch adalah permintaan asinkron. Jenis ini cocok untuk Anda jika tidak memerlukan respons langsung dan ingin memproses data yang terakumulasi dengan satu permintaan. Dalam contoh yang dibahas di bagian pendahuluan, ini adalah contoh kasus penggunaan mengkarakterisasi keanekaragaman hayati.
Jika ingin mendapatkan inferensi latensi rendah dari data yang diteruskan ke model Anda dengan cepat, Anda dapat menggunakan Inferensi online. Dalam contoh yang dibahas di bagian pendahuluan, ini adalah kasus penggunaan ketika Anda ingin menyematkan model dalam aplikasi yang membantu pengguna mengidentifikasi spesies tanaman dengan segera.
Mengupload model ke Vertex AI Model Registry
Untuk menggunakan layanan inferensi, langkah pertama adalah mengupload model ML terlatih Anda ke Vertex AI Model Registry. Ini adalah registry tempat Anda dapat mengelola siklus proses model.
Membuat resource model
Saat melatih model dengan layanan pelatihan kustom Vertex AI, Anda dapat mengimpor model secara otomatis ke registry setelah tugas pelatihan selesai. Jika Anda melewati langkah tersebut atau melatih model di luar Vertex AI, Anda dapat menguploadnya secara manual menggunakan Google Cloud konsol atau Vertex AI SDK untuk Python dengan mengarahkan ke lokasi Cloud Storage dengan artefak model yang disimpan. Format artefak model ini dapat berupa savedmodel.pb, model.joblib, dll., bergantung pada framework ML yang Anda gunakan.
Mengupload artefak ke Vertex AI Model Registry akan membuat resource Model, yang terlihat di konsol Google Cloud :
Pilih container
Saat mengimpor model ke Vertex AI Model Registry, Anda harus mengaitkannya dengan container agar Vertex AI dapat menampilkan permintaan inferensi.
Container bawaan
Vertex AI menyediakan container bawaan yang dapat Anda gunakan untuk inferensi. Container bawaan diatur berdasarkan framework ML dan versi framework serta menyediakan server inferensi HTTP yang dapat Anda gunakan untuk menyajikan inferensi dengan konfigurasi minimal. Fungsi ini hanya melakukan operasi inferensi framework machine learning sehingga jika Anda perlu melakukan prapemrosesan data, hal tersebut harus terjadi sebelum Anda membuat permintaan inferensi. Demikian pula, setiap pascapemrosesan harus terjadi setelah Anda melakukan permintaan inferensi. Untuk mengetahui contoh penggunaan container bawaan, lihat notebook Menayangkan model gambar PyTorch dengan container bawaan di Vertex AI.
Container kustom
Jika kasus penggunaan Anda memerlukan library yang tidak disertakan dalam container bawaan, atau mungkin Anda memiliki transformasi data kustom yang ingin dilakukan sebagai bagian dari permintaan inferensi, Anda dapat menggunakan container kustom yang Anda buat dan kirim ke Artifact Registry. Meskipun container kustom memungkinkan penyesuaian yang lebih besar, container tersebut harus menjalankan server HTTP. Secara khusus, container harus memproses dan merespons pemeriksaan keaktifan, health check, dan permintaan inferensi. Pada umumnya, menggunakan container bawaan jika memungkinkan adalah opsi yang direkomendasikan dan lebih sederhana. Untuk contoh penggunaan container kustom, lihat notebook Satu GPU Klasifikasi Gambar PyTorch menggunakan Pelatihan Vertex dengan Container Kustom
Rutinitas inferensi kustom
Jika kasus penggunaan Anda memerlukan transformasi prapemrosesan dan pascapemrosesan kustom, dan Anda tidak ingin ada overhead pembuatan dan pengelolaan container kustom, Anda dapat menggunakan rutinitas inferensi kustom. Dengan rutinitas inferensi kustom, Anda dapat menyediakan transformasi data sebagai kode Python, dan di belakang layar, Vertex AI SDK untuk Python akan membuat container kustom yang dapat Anda uji secara lokal dan deploy ke Vertex AI. Untuk contoh penggunaan rutinitas inferensi kustom, lihat notebook Rutinitas inferensi kustom dengan Sklearn
Mendapatkan inferensi batch
Setelah model berada di Vertex AI Model Registry, Anda dapat mengirimkan tugas inferensi batch dari konsol Google Cloud atau Vertex AI SDK untuk Python. Anda akan menentukan lokasi data sumber, serta lokasi di Cloud Storage atau BigQuery tempat Anda ingin menyimpan hasil. Anda juga dapat menentukan jenis mesin yang diinginkan untuk menjalankan tugas ini, serta akselerator opsional apa pun. Karena layanan inferensi terkelola sepenuhnya, Vertex AI akan otomatis menyediakan resource komputasi, melakukan tugas inferensi, dan memastikan penghapusan resource komputasi setelah tugas inferensi selesai. Status tugas inferensi batch Anda dapat dilacak di konsol Google Cloud .
Mendapatkan inferensi online
Jika ingin mendapatkan inferensi online, Anda harus melakukan langkah tambahan untuk
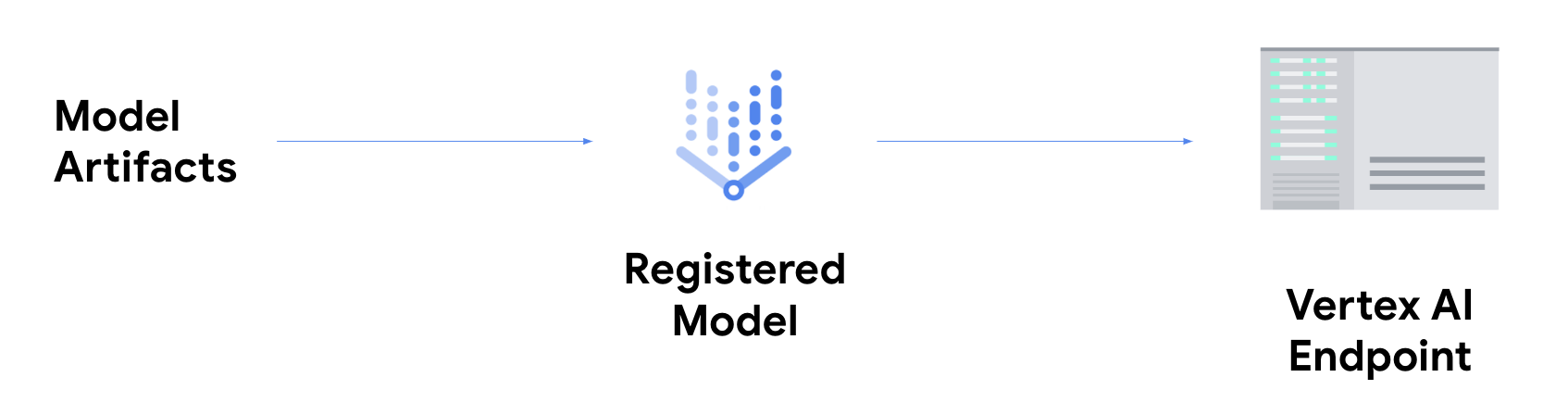
men-deploy model Anda
ke endpoint Vertex AI.
Hal ini mengaitkan artefak model dengan resource fisik untuk layanan berlatensi rendah dan membuat resource DeployedModel.
Setelah model di-deploy ke endpoint, model akan menerima permintaan seperti endpoint REST lainnya. Artinya, Anda dapat memanggilnya dari fungsi Cloud Run, chatbot, aplikasi web, dll. Perlu diperhatikan bahwa Anda dapat men-deploy beberapa model untuk satu endpoint, yang membagi traffic di antara model-model tersebut. Fungsionalitas ini berguna, misalnya, jika Anda ingin meluncurkan versi model baru, tetapi tidak ingin langsung mengarahkan semua traffic ke model baru. Anda juga dapat men-deploy model yang sama ke beberapa endoint.
Resource untuk mendapatkan inferensi dari model kustom di Vertex AI
Untuk mempelajari lebih lanjut cara menghosting dan menyalurkan model di Vertex AI, lihat referensi berikut atau lihat repo GitHub Vertex AI Samples.
- Video Mendapatkan Prediksi
- Melatih dan menyajikan model TensorFlow menggunakan container bawaan
- Menayangkan model image PyTorch dengan container bawaan di Vertex AI
- Menyajikan model Stable Diffusion menggunakan container bawaan
- Rutinitas inferensi kustom dengan Sklearn