이 섹션에서는 머신러닝(ML) 워크플로로 머신러닝 작업(MLOps)을 구현하는 데 도움이 되는 Vertex AI 서비스를 설명합니다.
모델을 배포한 후에는 최적의 성능을 발휘하고 관련성을 유지할 수 있도록 환경의 데이터 변경 상황에 대응해야 합니다. MLOps는 ML 시스템의 안정성과 신뢰성을 향상시키는 일련의 관행입니다.
Vertex AI MLOps 도구는 AI팀 간 공동작업을 수행하고 예측 모델 모니터링, 알림, 진단, 활용 가능한 설명을 통해 모델을 개선하는 데 도움이 됩니다. 모든 도구는 모듈식이므로 필요에 따라 기존 시스템에 통합할 수 있습니다.
MLOps에 대한 자세한 내용은 머신러닝의 지속적 배포 및 자동화 파이프라인 및 MLOps 실무자 가이드를 참조하세요.
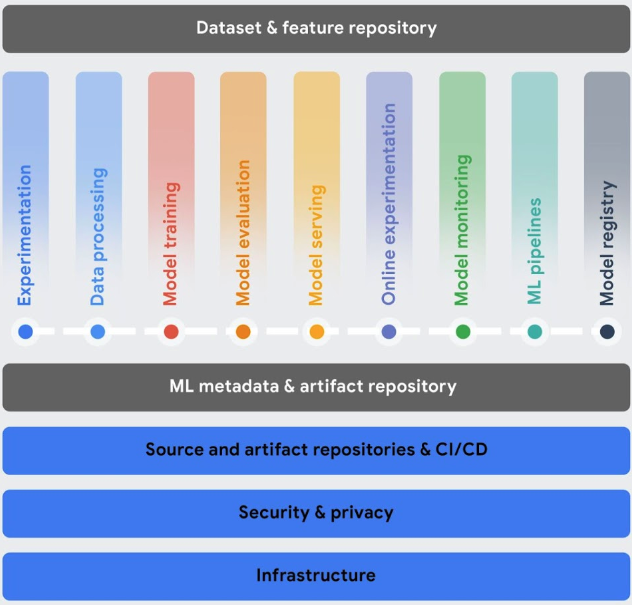
워크플로 조정: 모델을 수동으로 학습시키고 제공하는 데 시간이 오래 걸리고 오류가 발생하기 쉬운데 프로세스를 여러 번 반복해야 하는 경우 특히 그렇습니다.
- Vertex AI Pipelines는 ML 워크플로를 자동화, 모니터링, 제어하는 데 도움이 됩니다.
ML 시스템에서 사용되는 메타데이터 추적: 데이터 과학에서 ML 워크플로에서 사용되는 매개변수, 아티팩트, 측정항목을 추적하는 것이 중요합니다. 특히 워크플로를 여러 번 반복하는 경우 더욱 그렇습니다.
- Vertex ML Metadata를 사용하면 ML 시스템에서 사용되는 메타데이터, 매개변수, 아티팩트를 기록할 수 있습니다. 그런 다음 ML 시스템 또는 ML 시스템에서 생성하는 아티팩트의 성능을 분석, 디버깅, 감사하는 데 도움이 되도록 해당 메타데이터를 쿼리할 수 있습니다.
사용 사례에 가장 적합한 모델 식별: 새 학습 알고리즘을 시도할 때는 어떤 학습된 모델이 가장 우수한 성능을 발휘하는지 알아야 합니다.
Vertex AI Experiments를 사용하면 다양한 모델 아키텍처, 초매개변수, 학습 환경을 추적하고 분석하여 사용 사례에 가장 적합한 모델을 식별할 수 있습니다
Vertex AI 텐서보드는 ML 실험을 추적, 시각화, 비교하여 모델이 성능을 잘 발휘하는지 측정하는 데 도움이 됩니다.
모델 버전 관리: 모델을 중앙 저장소에 추가하면 모델 버전을 추적할 수 있습니다
- Vertex AI Model Registry는 모델 개요를 제공하므로 새 버전을 더욱 효과적으로 구성 및 추적하고 학습시킬 수 있습니다. Model Registry에서 모델을 평가하고, 모델을 엔드포인트에 배포하고, 일괄 추론을 만들고, 특정 모델과 모델 버전에 대한 세부정보를 볼 수 있습니다.
특성 관리: 여러 팀에서 ML 특성을 재사용하는 경우 특성을 공유하고 제공할 수 있는 빠르고 효율적인 방법이 필요합니다.
- Vertex AI Feature Store는 ML 특성을 구성, 저장, 제공할 수 있는 중앙 집중식 저장소를 제공합니다. 중앙 집중식 피처스토어를 사용하면 조직에서 ML 특성을 대규모로 재사용하고 새 ML 애플리케이션을 개발하고 배포하는 속도를 높일 수 있습니다.
모델 품질 모니터링: 프로덕션에 배포된 모델은 학습 데이터와 유사한 추론 입력 데이터에서 최고의 성능을 발휘합니다. 입력 데이터가 모델을 학습시키는 데 사용된 데이터와 다르면 모델 자체가 변경되지 않았더라도 모델 성능이 저하될 수 있습니다.
- Vertex AI Model Monitoring은 학습-서빙 편향과 추론 드리프트에 대해 모델을 모니터링하고 수신 추론 데이터 편향이 학습 기준에서 너무 멀리 벗어나면 알림을 전송합니다. 알림 및 특성 배포를 사용하여 모델을 다시 학습시켜야 하는지 여부를 평가할 수 있습니다.
AI 및 Python 애플리케이션 확장: Ray는 AI 및 Python 애플리케이션을 확장하기 위한 오픈소스 프레임워크입니다. Ray는 머신러닝(ML) 워크플로에 대해 분산형 계산과 병렬 처리를 수행하기 위한 인프라를 제공합니다.
- Vertex AI용 Ray는 동일한 오픈소스 Ray 코드를 사용하여 최소한의 변경만으로 Vertex AI에서 프로그램을 작성하고 애플리케이션을 개발할 수 있도록 설계되었습니다. 그런 다음 Vertex AI 추론 및 BigQuery와 같은 다른 Google Cloud 서비스와 Vertex AI의 통합 기능을 머신러닝 (ML) 워크플로의 일부로 사용할 수 있습니다.