Questa sezione descrive i servizi Vertex AI che ti aiutano a implementare Machine Learning Operations (MLOps) con il tuo flusso di lavoro di machine learning (ML).
Dopo il deployment, i modelli devono tenere il passo con i dati in continua evoluzione dell'ambiente per funzionare in modo ottimale e rimanere pertinenti. MLOps è un insieme di pratiche che migliorano la stabilità e l'affidabilità dei tuoi sistemi ML.
Gli strumenti MLOps di Vertex AI ti aiutano a collaborare con i team di AI e a migliorare i tuoi modelli tramite il monitoraggio, gli avvisi, la diagnosi e le spiegazioni utilizzabili del modello predittivo. Tutti gli strumenti sono modulari, quindi puoi integrarli nei tuoi sistemi esistenti in base alle esigenze.
Per saperne di più sulle MLOps, consulta Pipeline di automazione e distribuzione continua nel machine learning e la Guida alle MLOps per professionisti.
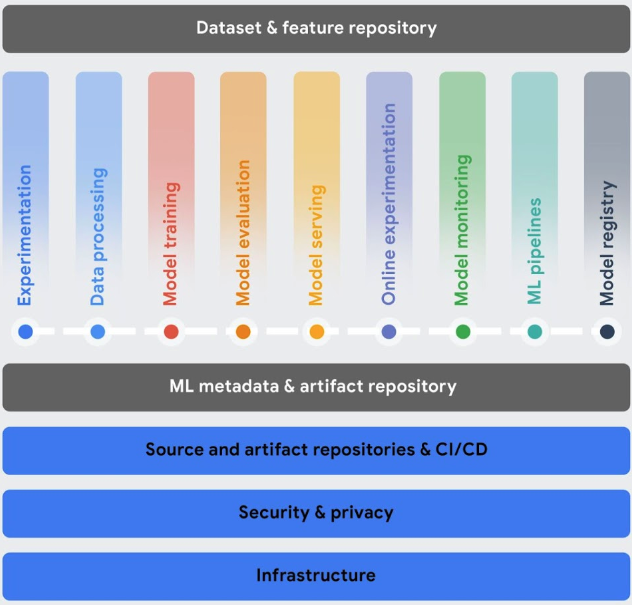
Orchestrare i flussi di lavoro: l'addestramento e la pubblicazione manuali dei modelli possono richiedere molto tempo ed essere soggetti a errori, soprattutto se devi ripetere le procedure molte volte.
- Vertex AI Pipelines ti aiuta ad automatizzare, monitorare e gestire i tuoi flussi di lavoro ML.
Tieni traccia dei metadati utilizzati nel tuo sistema ML: nella data science è importante tenere traccia dei parametri, degli artefatti e delle metriche utilizzati nel flusso di lavoro di ML, soprattutto quando lo ripeti più volte.
- Vertex ML Metadata ti consente di registrare i metadati, i parametri e gli artefatti utilizzati nel tuo sistema ML. Puoi quindi eseguire query sui metadati per analizzare, eseguire il debug e controllare le prestazioni del tuo sistema ML o degli artefatti che produce.
Identifica il modello migliore per un caso d'uso: quando provi nuovi algoritmi di addestramento, devi sapere quale modello addestrato offre le prestazioni migliori.
Vertex AI Experiments ti consente di monitorare e analizzare diverse architetture di modelli, iperparametri e ambienti di addestramento per identificare il modello migliore per il tuo caso d'uso.
Vertex AI TensorBoard ti aiuta a monitorare, visualizzare e confrontare gli esperimenti di machine learning per misurare le prestazioni dei tuoi modelli.
Gestisci le versioni del modello: l'aggiunta di modelli a un repository centrale ti aiuta a tenere traccia delle versioni del modello.
- Vertex AI Model Registry fornisce una panoramica dei tuoi modelli, in modo da poter organizzare, monitorare e addestrare meglio le nuove versioni. Dal registro dei modelli, puoi valutare i modelli, eseguirne il deployment in un endpoint, creare inferenze batch e visualizzare i dettagli di modelli e versioni specifici.
Gestisci le caratteristiche: quando riutilizzi le caratteristiche ML in più team, hai bisogno di un modo rapido ed efficiente per condividerle e pubblicarle.
- Vertex AI Feature Store fornisce un repository centralizzato per l'organizzazione, l'archiviazione e la distribuzione di caratteristiche di ML. L'utilizzo di un archivio di caratteristiche centrale consente a un'organizzazione di riutilizzare le caratteristiche di ML su larga scala e aumentare la velocità di sviluppo e deployment di nuove applicazioni di ML.
Monitorare la qualità del modello: un modello di cui è stato eseguito il deployment in produzione ha il rendimento migliore con dati di input di inferenza simili ai dati di addestramento. Quando i dati di input si discostano da quelli utilizzati per addestrare il modello, le prestazioni del modello possono peggiorare, anche se il modello stesso non è cambiato.
- Vertex AI Model Monitoring monitora i modelli per il disallineamento tra addestramento e gestione e la deviazione dell'inferenza e ti invia avvisi quando i dati di inferenza in entrata si discostano troppo dalla baseline di addestramento. Puoi utilizzare gli avvisi e le distribuzioni delle caratteristiche per valutare se è necessario riaddestrare il modello.
Scalare le applicazioni AI e Python: Ray è un framework open source per scalare le applicazioni AI e Python. Ray fornisce l'infrastruttura per eseguire il computing distribuito e l'elaborazione parallela per il flusso di lavoro di machine learning (ML).
- Ray su Vertex AI è progettato per consentirti di utilizzare lo stesso codice Ray open source per scrivere programmi e sviluppare applicazioni su Vertex AI con modifiche minime. Puoi quindi utilizzare le integrazioni di Vertex AI con altri servizi Google Cloud , come Vertex AI Inference e BigQuery, nell'ambito del tuo flusso di lavoro di machine learning (ML).