NVIDIA Triton no Vertex AI
A Vertex AI suporta a implementação de modelos no servidor de inferência Triton em execução num contentor personalizado publicado pela NVIDIA GPU Cloud (NGC) – imagem do servidor de inferência NVIDIA Triton. As imagens do Triton da NVIDIA têm todos os pacotes e configurações necessários que cumprem os requisitos do Vertex AI para imagens de contentores de publicação personalizadas. A imagem contém o servidor de inferência Triton com suporte para modelos TensorFlow, PyTorch, TensorRT, ONNX e OpenVINO. A imagem também inclui o back-end FIL (Forest Inference Library) que suporta a execução de frameworks de ML, como XGBoost, LightGBM e Scikit-Learn.
O Triton carrega os modelos e expõe pontos finais REST de inferência, estado e gestão de modelos que usam protocolos de inferência padrão. Ao implementar um modelo no Vertex AI, o Triton reconhece os ambientes do Vertex AI e adota o protocolo de inferência do Vertex AI para verificações de estado e pedidos de inferência.
A lista seguinte descreve as principais funcionalidades e exemplos de utilização do servidor de inferência NVIDIA Triton:
- Suporte para várias frameworks de aprendizagem profunda e aprendizagem automática: o Triton suporta a implementação de vários modelos e uma combinação de frameworks e formatos de modelos: TensorFlow (SavedModel e GraphDef), PyTorch (TorchScript), TensorRT, ONNX, OpenVINO e backends FIL para suportar frameworks como XGBoost, LightGBM, Scikit-Learn e quaisquer formatos de modelos Python ou C++ personalizados.
- Execução simultânea de vários modelos: o Triton permite que vários modelos, várias instâncias do mesmo modelo ou ambos sejam executados em simultâneo no mesmo recurso de computação com zero ou mais GPUs.
- Agregação de modelos (encadeamento ou pipeline): o conjunto do Triton suporta exemplos de utilização em que vários modelos são compostos como um pipeline (ou um DAG, um gráfico acíclico orientado) com tensores de entrada e saída que estão ligados entre si. Além disso, com um back-end Python do Triton, pode incluir qualquer lógica de pré-processamento, pós-processamento ou fluxo de controlo definida por scripts de lógica empresarial (BLS).
- Execução em backends de CPU e GPU: o Triton suporta a inferência para modelos implementados em nós com CPUs e GPUs.
- Processamento em lote dinâmico de pedidos de inferência: para modelos que suportam o processamento em lote, o Triton tem algoritmos de agendamento e processamento em lote incorporados. Estes algoritmos combinam dinamicamente pedidos de inferência individuais em lotes no lado do servidor para melhorar o débito de inferência e aumentar a utilização da GPU.
Para mais informações sobre o servidor de inferência NVIDIA Triton, consulte a documentação do Triton.
Imagens de contentores NVIDIA Triton disponíveis
A tabela seguinte mostra as imagens de Docker do Triton disponíveis no catálogo NVIDIA NGC. Escolha uma imagem com base na estrutura do modelo, no back-end e no tamanho da imagem do contentor que usa.
xx e yy referem-se às versões principais e secundárias do Triton, respetivamente.
| Imagem NVIDIA Triton | Compatibilidade |
|---|---|
xx.yy-py3 |
Contentor completo com suporte para modelos TensorFlow, PyTorch, TensorRT, ONNX e OpenVINO |
xx.yy-pyt-python-py3 |
Apenas backends do PyTorch e Python |
xx.yy-tf2-python-py3 |
Apenas backends do TensorFlow 2.x e Python |
xx.yy-py3-min |
Personalize o contentor do Triton conforme necessário |
Comece a usar: publicação de inferências com o NVIDIA Triton
A figura seguinte mostra a arquitetura de alto nível do Triton na Vertex AI Inference:
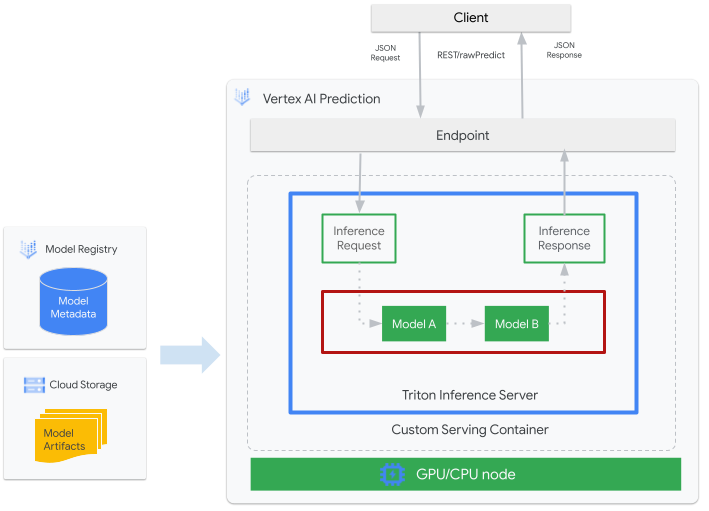
- Um modelo de ML a ser apresentado pelo Triton está registado no Registo de modelos Vertex AI. Os metadados do modelo fazem referência a uma localização dos artefactos do modelo no Cloud Storage, ao contentor de publicação personalizado e à respetiva configuração.
- O modelo do Registo de modelos Vertex AI é implementado num ponto final de inferência da Vertex AI que está a executar o servidor de inferência Triton como um contentor personalizado em nós de computação com CPU e GPU.
- Os pedidos de inferência chegam ao servidor de inferência do Triton através de um ponto final de inferência do Vertex AI e são encaminhados para o programador adequado.
- O back-end realiza a inferência através das entradas fornecidas nos pedidos em lote e devolve uma resposta.
- O Triton fornece pontos finais de verificação do estado de funcionamento e de atividade, que permitem a integração do Triton em ambientes de implementação, como o Vertex AI.
Este tutorial mostra como usar um contentor personalizado que está a executar o servidor de inferência NVIDIA Triton para implementar um modelo de aprendizagem automática (ML) no Vertex AI, que apresenta inferências online. Implementa um contentor que está a executar o Triton para publicar inferências a partir de um modelo de deteção de objetos do TensorFlow Hub que foi pré-preparado no conjunto de dados COCO 2017. Em seguida, pode usar o Vertex AI para detetar objetos numa imagem.
Para executar este tutorial no formato de bloco de notas:
Abrir no Colab | Abrir no Colab Enterprise | Ver no GitHub | Abrir no Vertex AI Workbench |Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Siga a documentação do Artifact Registry para instalar o Docker.
- LOCATION_ID: a região do seu repositório do Artifact Registry, conforme especificado numa secção anterior
- PROJECT_ID: o ID do seu projeto do Google Cloud
Para executar a imagem do contentor localmente, execute o seguinte comando na shell:
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=falseSubstitua o seguinte, tal como fez na secção anterior:
- LOCATION_ID: a região do seu repositório do Artifact Registry, conforme especificado numa secção anterior.
- PROJECT_ID: o ID do seu Google Cloud. projeto
- MODEL_ARTIFACTS_REPOSITORY: O caminho do Cloud Storage onde se encontram os artefactos do modelo.
Este comando executa um contentor no modo desanexado, mapeando a porta
8000do contentor para a porta8000do ambiente local. A imagem do Triton do NGC configura o Triton para usar a porta8000.Para enviar um health check ao servidor do contentor, execute o seguinte comando na shell:
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/readySe for bem-sucedido, o servidor devolve o código de estado como
200.Execute o seguinte comando para enviar um pedido de inferência ao servidor do contentor usando o payload gerado anteriormente e receber respostas de inferência:
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'Este pedido usa uma das imagens de teste incluídas no exemplo de deteção de objetos do TensorFlow.
Se for bem-sucedido, o servidor devolve a seguinte inferência:
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}Para parar o contentor, execute o seguinte comando na shell:
docker stop local_object_detectorPara conceder à sua instalação local do Docker autorização para enviar conteúdo para o Artifact Registry na região escolhida, execute o seguinte comando na sua shell:
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- Substitua LOCATION_ID pela região onde criou o repositório numa secção anterior.
Para enviar a imagem do contentor que acabou de criar para o Artifact Registry, execute o seguinte comando na shell:
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inferenceSubstitua o seguinte, tal como fez na secção anterior:
- LOCATION_ID: a região do seu repositório do Artifact Registry, conforme especificado numa secção anterior.
- PROJECT_ID: o ID do seu Google Cloud projeto.
- LOCATION_ID: a região onde está a usar o Vertex AI.
- PROJECT_ID: o ID do seu Google Cloud projeto
-
DEPLOYED_MODEL_NAME: um nome para o
DeployedModel. Também pode usar o nome a apresentar doModelpara oDeployedModel. - LOCATION_ID: a região onde está a usar o Vertex AI.
- ENDPOINT_NAME: o nome a apresentar do ponto final.
- LOCATION_ID: a região onde está a usar o Vertex AI.
- ENDPOINT_NAME: o nome a apresentar do ponto final.
-
DEPLOYED_MODEL_NAME: um nome para o
DeployedModel. Também pode usar o nome a apresentar doModelpara oDeployedModel. -
MACHINE_TYPE: opcional. Os recursos da máquina usados para cada nó desta implementação. A predefinição é
n1-standard-2. Saiba mais sobre os tipos de máquinas. - MIN_REPLICA_COUNT: o número mínimo de nós para esta implementação. O número de nós pode ser aumentado ou diminuído conforme necessário pela carga de inferência, até ao número máximo de nós e nunca inferior a este número de nós.
- MAX_REPLICA_COUNT: o número máximo de nós para esta implementação. O número de nós pode ser aumentado ou diminuído conforme necessário pela carga de inferência, até este número de nós e nunca inferior ao número mínimo de nós.
ACCELERATOR_COUNT: o número de aceleradores a associar a cada máquina que executa a tarefa. Normalmente, é 1. Se não for especificado, o valor predefinido é 1.
ACCELERATOR_TYPE: faça a gestão da configuração do acelerador para a publicação em GPUs. Quando implementa um modelo com tipos de máquinas do Compute Engine, também pode selecionar um acelerador de GPU e o tipo tem de ser especificado. As opções são
nvidia-tesla-a100,nvidia-tesla-p100,nvidia-tesla-p4,nvidia-tesla-t4envidia-tesla-v100.- LOCATION_ID: a região onde está a usar o Vertex AI.
- ENDPOINT_NAME: o nome a apresentar do ponto final.
Para anular a implementação do modelo a partir do ponto final e eliminar o ponto final, execute o seguinte comando na shell:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietSubstitua LOCATION_ID pela região onde criou o modelo numa secção anterior.
Para eliminar o seu modelo, execute o seguinte comando na shell:
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietSubstitua LOCATION_ID pela região onde criou o modelo numa secção anterior.
Para eliminar o repositório do Artifact Registry e a imagem de contentor no mesmo, execute o seguinte comando na shell:
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietSubstitua LOCATION_ID pela região onde criou o repositório do Artifact Registry numa secção anterior.
- O contentor personalizado do Triton não é compatível com o Vertex Explainable AI nem com o Vertex AI Model Monitoring.
- Para saber mais sobre os padrões de implementação com o servidor de inferência NVIDIA Triton no Vertex AI, consulte os tutoriais do bloco de notas do NVIDIA Triton.
Ao longo deste tutorial, recomendamos que use a Cloud Shell para interagir com o Google Cloud. Se quiser usar um shell Bash diferente em vez do Cloud Shell, faça a seguinte configuração adicional:
Crie e envie a imagem de contentor
Para usar um contentor personalizado, tem de especificar uma imagem de contentor Docker que cumpra os requisitos de contentores personalizados. Esta secção descreve como criar a imagem do contentor e enviá-la para o Artifact Registry.
Transfira artefactos do modelo
Os artefactos do modelo são ficheiros criados pela preparação de ML que pode usar para publicar inferências. Contêm, no mínimo, a estrutura e os pesos do seu modelo de ML preparado. O formato dos artefactos do modelo depende da framework de ML que usa para a preparação.
Para este tutorial, em vez de preparar um modelo de raiz, transfira o modelo de deteção de objetos do TensorFlow Hub que foi preparado no conjunto de dados COCO 2017.
O Triton espera que o
repositório de modelos
esteja organizado na seguinte estrutura para publicação no formato
TensorFlow SavedModel:
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
O ficheiro config.pbtxt descreve a
configuração do modelo
para o modelo. Por predefinição, tem de fornecer o ficheiro de configuração do modelo que contém as definições necessárias. No entanto, se o Triton for iniciado com a opção --strict-model-config=false, em alguns casos, a configuração do modelo pode ser gerada automaticamente pelo Triton e não precisa de ser fornecida explicitamente.
Especificamente, os modelos TensorRT, TensorFlow SavedModel e ONNX não requerem um ficheiro de configuração do modelo porque o Triton pode derivar automaticamente todas as definições necessárias. Todos os outros tipos de modelos têm de fornecer um ficheiro de configuração do modelo.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
Depois de transferir o modelo localmente, o repositório de modelos é organizado da seguinte forma:
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Copie artefactos do modelo para um contentor do Cloud Storage
Os artefactos do modelo transferidos, incluindo o ficheiro de configuração do modelo, são enviados para um contentor do Cloud Storage especificado por MODEL_ARTIFACTS_REPOSITORY, que pode ser usado quando cria o recurso do modelo do Vertex AI.
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Crie um repositório do Artifact Registry
Crie um repositório do Artifact Registry para armazenar a imagem do contentor que vai criar na secção seguinte.
Ative o serviço da API Artifact Registry para o seu projeto.
gcloud services enable artifactregistry.googleapis.com
Execute o seguinte comando na shell para criar o repositório do Artifact Registry:
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
Substitua LOCATION_ID pela região onde o Artifact Registry
armazena a sua imagem de contentor. Posteriormente, tem de criar um recurso de modelo do Vertex AI num ponto final de localização que corresponda a esta região. Por isso, escolha uma região onde o Vertex AI tenha um ponto final de localização, como us-central1.
Após a conclusão da operação, o comando imprime o seguinte resultado:
Created repository [getting-started-nvidia-triton].
Crie a imagem de contentor
A NVIDIA fornece
imagens do Docker
para criar uma imagem de contentor que esteja a executar o Triton
e esteja alinhada com os
requisitos de contentores personalizados da Vertex AI para
a publicação. Pode extrair a imagem usando docker e etiquetar o caminho do Artifact Registry para o qual a imagem vai ser enviada.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
Substitua o seguinte:
O comando pode ser executado durante vários minutos.
Prepare o ficheiro de payload para testar pedidos de inferência
Para enviar um pedido de inferência ao servidor do contentor, prepare a carga útil com um ficheiro de imagem de exemplo que use Python. Execute o seguinte script Python para gerar o ficheiro de payload:
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
O script do Python gera o payload e imprime a seguinte resposta:
Payload generated at instances.json
Execute o contentor localmente (opcional)
Antes de enviar a imagem do contentor para o Artifact Registry para a usar com o Vertex AI, pode executá-la como um contentor no seu ambiente local para verificar se o servidor funciona como esperado:
{kind=link}
Envie a imagem do contentor para o Artifact Registry
Configure o Docker para aceder ao Artifact Registry. Em seguida, envie a imagem do contentor para o repositório do Artifact Registry.
Implemente o modelo
Nesta secção, cria um modelo e um ponto final e, em seguida, implementa o modelo no ponto final.
Criar um modelo
Para criar um recurso Model que use um contentor personalizado que execute o Triton, use o comando gcloud ai models upload.
Antes de criar o modelo, leia o artigo
Definições para contentores personalizados
para saber se
tem de especificar os campos opcionais sharedMemorySizeMb, startupProbe e
healthProbe para o seu contentor.
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
O argumento --container-args='--strict-model-config=false' permite que o Triton gere automaticamente a configuração do modelo.
Crie um ponto final
Tem de implementar o modelo num ponto final antes de o poder usar para publicar inferências online. Se estiver a implementar um modelo num ponto final existente, pode ignorar este passo. O exemplo seguinte usa o comando
gcloud ai endpoints create:
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
Substitua o seguinte:
A ferramenta Google Cloud CLI pode demorar alguns segundos a criar o ponto final.
Implemente o modelo no ponto final
Quando o ponto final estiver pronto, implemente o modelo no ponto final. Quando implementa um modelo num ponto final, o serviço associa recursos físicos ao modelo que executa o Triton para publicar inferências online.
O exemplo seguinte usa o comando gcloud ai endpoints deploy-model
para implementar o Model
num endpoint que executa o Triton em GPUs para acelerar a publicação de inferências
e sem dividir o tráfego entre vários recursos DeployedModel
:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
Substitua o seguinte:
A CLI Google Cloud pode demorar alguns segundos a implementar o modelo no ponto final. Quando o modelo é implementado com êxito, este comando imprime o seguinte resultado:
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
Obtenha inferências online do modelo implementado
Para invocar o modelo através do ponto final da inferência da Vertex AI, formate o pedido de inferência usando um objeto JSON de pedido de inferência padrão
ou um objeto JSON de pedido de inferência com uma extensão binária
e envie um pedido para o ponto final REST rawPredict da Vertex AI.
O exemplo seguinte usa o comando gcloud ai endpoints raw-predict:
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
Substitua o seguinte:
O ponto final devolve a seguinte resposta para um pedido válido:
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
Limpar
Para evitar incorrer em mais cobranças do Vertex AI e cobranças do Artifact Registry, elimine os Google Cloud recursos que criou durante este tutorial: