Vertex AI 上の NVIDIA Triton
Vertex AI は、Triton 推論サーバー(NVIDIA Triton 推論サーバー イメージ)へのモデルのデプロイをサポートしています。このサーバーは、NVIDIA GPU Cloud(NGC)に公開されているカスタム コンテナ上で実行されます。NVIDIA の Triton イメージには、カスタム サービング コンテナ イメージの Vertex AI 要件を満たす、必要なパッケージと構成がすべて含まれています。このイメージには、TensorFlow、PyTorch、TensorRT、ONNX、OpenVINO の各モデルをサポートする Triton 推論サーバーが含まれています。また、このイメージには XGBoost、LightGBM、Scikit-Learn などの ML フレームワークの実行をサポートする FIL(フォレスト推論ライブラリ)バックエンドも含まれています。
Triton は、モデルを読み込み、標準の推論プロトコルを使用する推論、ヘルスチェック、モデル管理の REST エンドポイントを公開します。Vertex AI にモデルをデプロイすると、Triton は Vertex AI 環境を認識し、ヘルスチェックと推論リクエストに Vertex AI Inference プロトコルを使用します。
NVIDIA Triton 推論サーバーの主な機能とユースケースの概要は次のとおりです。
- 複数のディープ ラーニング フレームワークと機械学習フレームワークのサポート: Triton は、複数のモデルのデプロイと、フレームワークとモデル形式の組み合わせをサポートしています。TensorFlow(SavedModel と GraphDef)、PyTorch(TorchScript)、TensorRT、ONNX、OpenVINO、FIL バックエンドを使用して、XGBoost、LightGBM、Scikit-Learn などのフレームワークや、カスタム Python または C++ モデル形式をサポートします。
- 複数モデルの同時実行: Triton では、0 個以上の GPU を使用して、同じコンピューティング リソース上で複数のモデルまたは同じモデルの複数のインスタンスを同時に実行できます。
- モデルのアンサンブル(チェーンまたはパイプライン処理): Triton のアンサンブルは、複数のモデルをパイプライン(DAG、有向非巡回グラフ)として作成し、その間を入力テンソルと出力テンソルで接続するユースケースをサポートしています。また、Triton Python バックエンドでは、ビジネス ロジック スクリプティング(BLS)で定義された前処理、後処理、制御フローのロジックを含めることができます。
- CPU と GPU バックエンドで実行: Triton は、CPU と GPU を使用するノードにデプロイされたモデルの推論をサポートしています。
- 推論リクエストの動的バッチ処理: バッチ処理をサポートするモデル用に、Triton にはスケジューリング アルゴリズムとバッチ処理アルゴリズムが組み込まれています。これらのアルゴリズムは、個々の推論リクエストをサーバー側で動的に結合し、推論スループットを向上させ、GPU の使用効率を高めます。
NVIDIA Triton 推論サーバーの詳細については、Triton のドキュメントをご覧ください。
利用可能な NVIDIA Triton コンテナ イメージ
次の表に、NVIDIA NGC カタログで利用可能な Triton Docker イメージを示します。モデルのフレームワーク、バックエンド、使用するコンテナ イメージのサイズに基づいてイメージを選択してください。
xx と yy は、それぞれ Triton のメジャー バージョンとマイナー バージョンを表します。
| NVIDIA Triton イメージ | サポート |
|---|---|
xx.yy-py3 |
TensorFlow、PyTorch、TensorRT、ONNX、OpenVINO の各モデルをサポートするフルコンテナ |
xx.yy-pyt-python-py3 |
PyTorch バックエンドと Python バックエンドのみ |
xx.yy-tf2-python-py3 |
TensorFlow 2.x と Python のバックエンドのみ |
xx.yy-py3-min |
必要に応じて Triton コンテナをカスタマイズ |
スタートガイド: NVIDIA Triton を使用した推論の提供
次の図は、Vertex AI Inference 上の Triton アーキテクチャの概要を示しています。
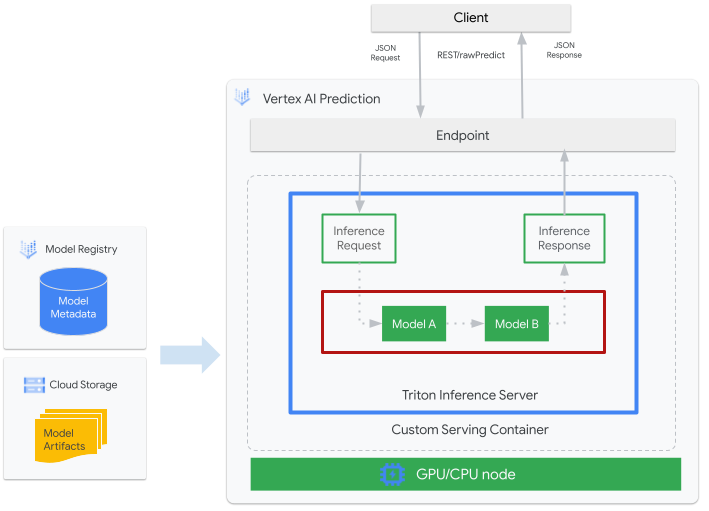
- Triton によって提供される ML モデルは、Vertex AI Model Registry に登録されます。モデルのメタデータは、Cloud Storage 内でのモデル アーティファクトの場所、カスタム サービング コンテナ、その構成を参照します。
- Vertex AI Model Registry のモデルは、CPU と GPU を使用するコンピューティング ノード上で、Triton 推論サーバーをカスタム コンテナとして実行する Vertex AI 推論エンドポイントにデプロイされます。
- 推論リクエストは、Vertex AI 推論エンドポイントを介して Triton 推論サーバーに到達し、適切なスケジューラに転送されます。
- バックエンドは、バッチ リクエストで指定された入力を使用して推論を行い、レスポンスを返します。
- Triton は readiness / liveness ヘルス エンドポイントを提供します。これにより、Triton を Vertex AI などのデプロイ環境に統合できます。
このチュートリアルでは、NVIDIA Triton 推論サーバーを実行するカスタム コンテナを使用して、Vertex AI に機械学習(ML)モデルをデプロイし、オンライン推論を行う方法について説明します。Triton を実行しているコンテナをデプロイして、COCO 2017 データセットで事前トレーニング済みの TensorFlow Hub のオブジェクト検出モデルから推論を提供します。その後、Vertex AI を使用して画像内のオブジェクトを検出します。
このチュートリアルをノートブック形式で実行するには:
Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench で開く |始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Artifact Registry のドキュメントに従って、Docker をインストールします。
- LOCATION_ID: 前のセクションで指定した Artifact Registry リポジトリのリージョン
- PROJECT_ID: Google Cloudプロジェクトの ID
コンテナ イメージをローカルで実行するには、シェルで次のコマンドを実行します。
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=false前のセクションと同様に、次のよう置き換えます。
- LOCATION_ID: 前のセクションで指定した Artifact Registry リポジトリのリージョン
- PROJECT_ID: Google Cloudの ID。project
- MODEL_ARTIFACTS_REPOSITORY: モデル アーティファクトが配置されている Cloud Storage パス
このコマンドは分離モードでコンテナを実行し、コンテナのポート
8000をローカル環境のポート8000にマッピングします。NGC の Triton イメージは、ポート8000を使用するように Triton を構成します。コンテナのサーバーにヘルスチェックを送信するには、シェルで次のコマンドを実行します。
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/ready成功すると、サーバーはステータス コードとして
200を返します。次のコマンドを実行して、以前に生成したペイロードを使用してコンテナのサーバーに推論リクエストを送信し、推論レスポンスを取得します。
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'このリクエストでは、TensorFlow オブジェクト検出の例に含まれているテストイメージのいずれかが使用されます。
成功すると、サーバーは次の推論を返します。
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}コンテナを停止するには、シェルで次のコマンドを実行します。
docker stop local_object_detectorローカルの Docker インストール権限を選択したリージョンの Artifact Registry に push するには、シェルで次のコマンドを実行します。
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- LOCATION_ID は、前のセクションでリポジトリを作成したリージョンに置き換えます。
ビルドしたコンテナ イメージを Artifact Registry に push するには、シェルで次のコマンドを実行します。
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference前のセクションと同様に、次のよう置き換えます。
- LOCATION_ID: 前のセクションで指定した Artifact Registry リポジトリのリージョン
- PROJECT_ID: Google Cloudプロジェクトの ID。
- LOCATION_ID: Vertex AI を使用するリージョン。
- PROJECT_ID: Google Cloudプロジェクトの ID
-
DEPLOYED_MODEL_NAME:
DeployedModelの名前。DeployedModelのModelの表示名を使用することもできます。 - LOCATION_ID: Vertex AI を使用するリージョン。
- ENDPOINT_NAME: エンドポイントの表示名。
- LOCATION_ID: Vertex AI を使用するリージョン。
- ENDPOINT_NAME: エンドポイントの表示名。
-
DEPLOYED_MODEL_NAME:
DeployedModelの名前。DeployedModelのModelの表示名を使用することもできます。 -
MACHINE_TYPE: 省略可。このデプロイの各ノードで使用するマシンリソース。デフォルトの設定は
n1-standard-2です。マシンタイプの詳細。 - MIN_REPLICA_COUNT: このデプロイの最小ノード数。ノード数は、推論負荷に応じてノードの最大数まで増減できますが、この数より少なくすることはできません。
- MAX_REPLICA_COUNT: このデプロイの最大ノード数。ノード数は、推論負荷に応じてこのノード数まで増減できますが、最小ノード数より少なくなることはありません。
ACCELERATOR_COUNT: ジョブを実行している各マシンに接続するアクセラレータの数。通常は 1 です。指定しない場合、デフォルト値は 1 です。
ACCELERATOR_TYPE: GPU サービングのアクセラレータ構成を管理します。Compute Engine マシンタイプでモデルをデプロイする場合、GPU アクセラレータも選択できます。その場合は、タイプを指定する必要があります。選択肢は
nvidia-tesla-a100、nvidia-tesla-p100、nvidia-tesla-p4、nvidia-tesla-t4、nvidia-tesla-v100です。- LOCATION_ID: Vertex AI を使用するリージョン。
- ENDPOINT_NAME: エンドポイントの表示名。
エンドポイントからモデルのデプロイを解除してエンドポイントを削除するには、シェルで次のコマンドを実行します。
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietLOCATION_ID は、前のセクションでモデルを作成したリージョンに置き換えます。
モデルを削除するには、シェルで次のコマンドを実行します。
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietLOCATION_ID は、前のセクションでモデルを作成したリージョンに置き換えます。
Artifact Registry リポジトリとその中のコンテナ イメージを削除するには、シェルで次のコマンドを実行します。
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietLOCATION_ID は、前のセクションで Artifact Registry リポジトリを作成したリージョンに置き換えます。
- Triton カスタム コンテナは Vertex Explainable AI または Vertex AI Model Monitoring と互換性がありません。
- Vertex AI での NVIDIA Triton 推論サーバーを使用したデプロイ パターンの詳細については、NVIDIA Triton ノートブック チュートリアルをご覧ください。
このチュートリアル全体を通して、Cloud Shell を使用して Google Cloudを操作することをおすすめします。Cloud Shell の代わりに別の Bash シェルを使用する場合は、次の追加の構成を行います。
コンテナ イメージをビルドして push する
カスタム コンテナを使用するには、カスタム コンテナの要件を満たす Docker コンテナ イメージを指定する必要があります。このセクションでは、コンテナ イメージを作成して Artifact Registry に push する方法について説明します。
モデル アーティファクトをダウンロードする
モデル アーティファクトとは、推論の提供に使用できる ML トレーニングによって作成されたファイルです。これには、少なくとも、トレーニング済み ML モデルの構造と重みが含まれます。モデル アーティファクトの形式は、トレーニングに使用する ML フレームワークによって異なります。
このチュートリアルでは、オブジェクトのトレーニングをゼロから行うのではなく、COCO 2017 データセットでトレーニング済みのオブジェクト検出モデルを TensorFlow Hub から取得します。Triton は、TensorFlow SavedModel 形式を提供するため、モデル リポジトリが次の構造で編成されていることを前提としています。
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
config.pbtxt ファイルには、モデルのモデル構成が記述されています。デフォルトでは、必要な設定を含むモデル構成ファイルを指定する必要があります。ただし、Triton を --strict-model-config=false オプションで開始した場合、モデル構成が Triton によって自動的に生成されることがあります。その場合は、明示的に指定する必要はありません。特に、TensorRT、TensorFlow SavedModel、ONNX モデルでは、必要な設定がすべて自動的に取得されるため、モデル構成ファイルは必要ありません。これ以外のモデルタイプの場合は、モデル構成ファイルを指定する必要があります。
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
モデルをローカルにダウンロードすると、モデル リポジトリは次のように編成されます。
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
モデル アーティファクトを Cloud Storage バケットにコピーする
ダウンロードしたモデル アーティファクト(モデル構成ファイルを含む)は、MODEL_ARTIFACTS_REPOSITORY で指定された Cloud Storage バケットに push されます。これは、Vertex AI モデルリソースを作成するときに使用できます。
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Artifact Registry リポジトリを作成する
Artifact Registry リポジトリを作成して、次のセクションで作成するコンテナ イメージを保存します。
プロジェクトで Artifact Registry API サービスを有効にします。
gcloud services enable artifactregistry.googleapis.com
シェルで次のコマンドを実行して、Artifact Registry リポジトリを作成します。
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
LOCATION_ID は、Artifact Registry がコンテナ イメージを保存するリージョンに置き換えます。後で、このリージョンと一致するロケーション エンドポイントに Vertex AI モデルリソースを作成する必要があります。そのため、Vertex AI にロケーション エンドポイントがあるリージョンを選択してください(例: us-central1)。
オペレーションが完了すると、コマンドによって次の出力が表示されます。
Created repository [getting-started-nvidia-triton].
コンテナ イメージをビルドする
NVIDIA は、Triton を実行し、Vertex AI のカスタム コンテナ要件を満たすコンテナ イメージを構築するための Docker イメージを提供しています。docker を使用してイメージを pull し、イメージの push 先となる Artifact Registry パスにタグを付けます。
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
次のように置き換えます。
このコマンドの実行には、数分間かかる場合があります。
推論リクエストをテストするためのペイロード ファイルを準備する
コンテナのサーバーに推論リクエストを送信するには、Python を使用するサンプル イメージ ファイルを使用してペイロードを準備します。次の Python スクリプトを実行して、ペイロード ファイルを生成します。
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
Python スクリプトがペイロードを生成し、次のレスポンスを出力します。
Payload generated at instances.json
コンテナをローカルで実行する(省略可)
コンテナ イメージを Artifact Registry に push して Vertex AI で使用する前に、ローカル環境でコンテナとして実行し、サーバーが想定どおりに動作することを確認できます。
{kind=link}
コンテナ イメージを Artifact Registry に push する
Artifact Registry にアクセスできるように Docker を構成します。次に、コンテナ イメージを Artifact Registry リポジトリに push します。
モデルをデプロイする
このセクションでは、モデルとエンドポイントを作成し、モデルをエンドポイントにデプロイします。
モデルを作成する
Triton を実行するカスタム コンテナを使用する Model リソースを作成するには、gcloud ai models upload コマンドを使用します。
モデルを作成する前に、カスタム コンテナの設定を読んで、コンテナのオプションの sharedMemorySizeMb、startupProbe、healthProbe フィールドを指定する必要があるかどうかを確認してください。
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
引数 --container-args='--strict-model-config=false' を指定すると、モデルの構成が自動的に生成されます。
エンドポイントを作成する
モデルを使用してオンライン推論を行う前に、モデルをエンドポイントにデプロイする必要があります。既存のエンドポイントにモデルをデプロイする場合は、この手順を省略できます。次の例では、gcloud ai endpoints create コマンドを使用します。
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
次のように置き換えます。
Google Cloud CLI ツールがエンドポイントを作成するまでに数秒かかる場合があります。
モデルをエンドポイントにデプロイする
エンドポイントの準備が整ったら、モデルをエンドポイントにデプロイします。エンドポイントにモデルをデプロイすると、このサービスは物理リソースを Triton を実行しているモデルに関連付けて、オンライン推論を提供します。
次の例では、gcloud ai endpoints deploy-model コマンドを使用して、GPU 上で Triton を実行している endpoint に Model をデプロイし、推論の提供を高速化します。複数の DeployedModel リソース間のトラフィックは分割しません。
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
次のように置き換えます。
Google Cloud CLI でエンドポイントにモデルをデプロイする場合、処理に数秒かかることがあります。モデルが正常にデプロイされると、このコマンドは次の出力を返します。
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
デプロイされたモデルからオンライン推論を取得する
Vertex AI Inference エンドポイントを使用してモデルを呼び出すには、標準の推論リクエストの JSON オブジェクト
を作成するか、バイナリ拡張で推論リクエストの JSON オブジェクト
を作成し、Vertex AI の REST rawPredict エンドポイントにリクエストを送信します。
次の例では、gcloud ai endpoints raw-predict コマンドを使用します。
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
次のように置き換えます。
エンドポイントは、有効なリクエストに対して次のレスポンスを返します。
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
クリーンアップ
Vertex AI の料金と Artifact Registry の料金が発生しないように、このチュートリアルで作成した Google Cloud リソースを削除します。