Vertex AI モデルは、デフォルトで独自の仮想マシン(VM)インスタンスにデプロイされます。Vertex AI は同じ VM 上でモデルを共同ホスティングでき、次のようなメリットがあります。
- 複数のデプロイ間でのリソース共有。
- 費用対効果の高いモデル サービング。
- メモリと計算リソースの使用率の改善。
このガイドでは、Vertex AI の複数のデプロイでリソースを共有する方法について説明します。
概要
モデルの共同ホスティングのサポートには DeploymentResourcePool のコンセプトが導入されています。これにより、単一の VM 内のリソースを共有するモデルのデプロイをグループ化します。複数のエンドポイントを DeploymentResourcePool 内の同じ VM にデプロイできます。各エンドポイントには 1 つ以上のモデルがデプロイされます。特定のエンドポイントにデプロイされたモデルは、同じまたは異なる DeploymentResourcePool にグループ化できます。
次の例では、4 つのモデルと 2 つのエンドポイントがあります。
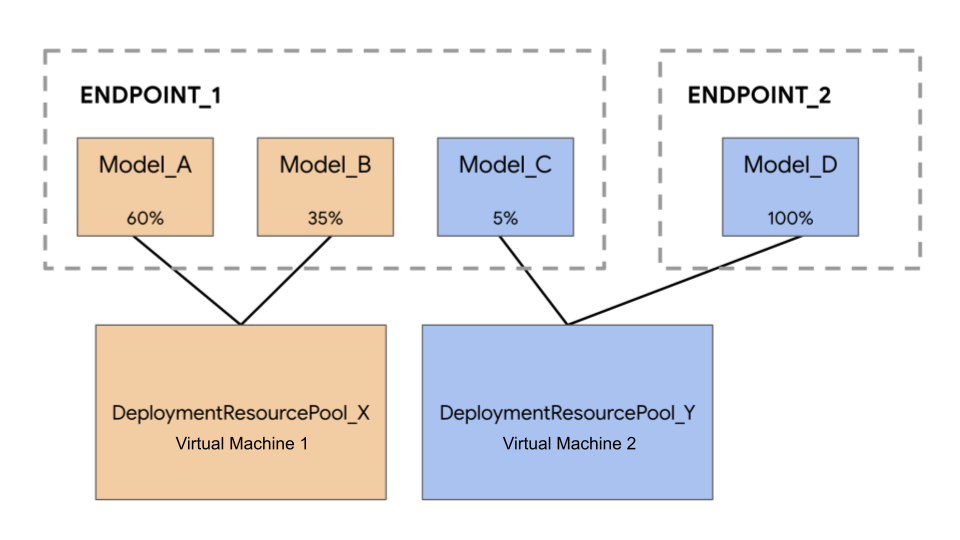
Model_A、Model_B、Model_C は、Endpoint_1 にデプロイされ、これらのすべてにトラフィックがルーティングされます。Model_D は Endpoint_2 にデプロイされます。これは、そのエンドポイントのトラフィックをすべて受信します。各モデルを別々の VM に割り当てる代わりに、次のいずれかの方法でモデルをグループ化できます。
Model_AとModel_Bをグループ化して VM を共有し、DeploymentResourcePool_Xの一部にします。Model_CとModel_D(現時点で同じエンドポイントにない)をグループ化して VM を共有し、DeploymentResourcePool_Yの一部にします。
異なるデプロイ リソース プールが VM を共有することはできません。
考慮事項
1 つのデプロイ リソース プールにデプロイできるモデルの数に上限はありません。選択した VM シェイプ、モデルサイズ、トラフィック パターンによって異なります。共同ホスティングは、低トラフィックで多くのデプロイ済みモデルを使用している場合に有効に機能するため、各デプロイ済みモデルに専用マシンを割り当てると、リソースを効果的に利用することができません。
同じデプロイ リソース プールにモデルを同時にデプロイできます。ただし、同時に実施できるデプロイ リクエストの数は 20 までです。
空のデプロイ リソース プールは、リソースの割り当てを消費しません。リソースは、最初のモデルがデプロイされるとデプロイ リソース プールにプロビジョニングされ、最後のモデルがデプロイ解除されると解放されます。
単一のデプロイ リソース プール内のモデルは互いに分離されておらず、CPU とメモリの競合が発生する可能性があります。別のモデルが推論リクエストを同時に処理している場合、1 つのモデルのパフォーマンスが低下する可能性があります。
制限事項
リソース共有を有効にしてモデルをデプロイする場合、次の制限があります。
- この機能は、次の構成でのみサポートされています。
- TensorFlow のビルド済みコンテナを使用する TensorFlow モデルのデプロイ
- PyTorch のビルド済みコンテナを使用する PyTorch モデルのデプロイ
- その他のモデルのフレームワークとカスタム コンテナはサポートされていません。
- カスタム トレーニング済みモデルとインポートされたモデルのみがサポートされています。AutoML モデルはサポートされていません。
- 同じデプロイ リソース プールでデプロイできるのは、TensorFlow または PyTorch の予測用の Vertex AI ビルド済みコンテナの同じコンテナ イメージ(フレームワーク バージョンを含む)を使用するモデルのみです。
- Vertex Explainable AI はサポートされていません。
モデルをデプロイ
モデルを DeploymentResourcePool にデプロイするには、次の操作を行います。
- 必要に応じて、デプロイ リソース プールを作成します。
- 必要に応じてエンドポイントを作成します。
- エンドポイント ID を取得します。
- デプロイ リソース プールのエンドポイントにモデルをデプロイします。
デプロイ リソース プールを作成する
既存の DeploymentResourcePool にモデルをデプロイする場合は、この手順をスキップします。
CreateDeploymentResourcePool を使用してリソースプールを作成します。
Cloud コンソール
Google Cloud コンソールで、Vertex AI の [Deployment リソースプール] ページに移動します。
[作成] をクリックし、フォームに入力します(下を参照)。

REST
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION_ID: Vertex AI を使用するリージョン。
- PROJECT_ID: 実際のプロジェクト ID。
-
MACHINE_TYPE: 省略可。このデプロイの各ノードで使用するマシンリソース。デフォルトの設定は
n1-standard-2です。マシンタイプの詳細をご覧ください。 - ACCELERATOR_TYPE: マシンに接続するアクセラレータのタイプ。ACCELERATOR_COUNT が指定されていない場合、またはゼロの場合は省略できます。AutoML モデルや、GPU 以外のイメージを使用するカスタム トレーニング モデルでは、推奨されません。詳細。
- ACCELERATOR_COUNT: 各レプリカで使用するアクセラレータの数。省略可。GPU 以外のイメージを使用する AutoML モデルまたはカスタム トレーニング モデルの場合、0 を指定するか何も指定しないかのどちらかにしてください。
- MIN_REPLICA_COUNT: このデプロイの最小ノード数。ノード数は、予測負荷に応じてノードの最大数まで増減できますが、この数より少なくすることはできません。1 以上の値を指定してください。
- MAX_REPLICA_COUNT: このデプロイの最大ノード数。ノード数は、予測負荷に応じてこのノード数まで増減できますが、最小ノード数より少なくなることはありません。
-
DEPLOYMENT_RESOURCE_POOL_ID:
DeploymentResourcePoolの名前。最大文字数は 63 文字で、有効な文字は /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/ です。
HTTP メソッドと URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
リクエストの本文(JSON):
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
レスポンスに "done": true が表示されるまで、オペレーションのステータスをポーリングできます。
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
次のように置き換えます。
DEPLOYMENT_RESOURCE_POOL_ID:DeploymentResourcePoolの名前。最大文字数は 63 文字で、有効な文字は /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/ です。MACHINE_TYPE: 省略可。このデプロイの各ノードで使用するマシンリソース。デフォルト値はn1-standard-2です。マシンタイプの詳細をご覧ください。MIN_REPLICA_COUNT: このデプロイの最小ノード数。ノード数は、予測負荷に応じてノードの最大数まで増減できますが、この数より少なくすることはできません。1 以上の値を指定してください。MAX_REPLICA_COUNT: このデプロイの最大ノード数。ノード数は、予測負荷に応じてこのノード数まで増減できますが、最小ノード数より少なくなることはありません。
エンドポイントを作成する
エンドポイントを作成するには、エンドポイントにモデルをデプロイするをご覧ください。この手順は、単一モデルのデプロイと同じです。
エンドポイント ID を取得する
エンドポイント ID を取得するには、エンドポイントにモデルをデプロイするをご覧ください。この手順は、単一モデルのデプロイと同じです。
デプロイ リソース プールにモデルをデプロイする
DeploymentResourcePool とエンドポイントを作成したら、DeployModel API メソッドを使用してデプロイできる状態になります。このプロセスは、単一モデルのデプロイに似ています。DeploymentResourcePool が存在する場合は、デプロイする DeploymentResourcePool のリソース名を指定して DeployModel の shared_resources を指定します。
Cloud コンソール
Google Cloud コンソールで、Vertex AI の [Model Registry] ページに移動します。
モデルを見つけて、[エンドポイントにデプロイ] をクリックします。
[モデル設定](下を参照)で、[共有デプロイ リソースプールへのデプロイ] を選択します。
![トラフィック分割を 100 に設定し、[共有デプロイ リソースプールへのデプロイ] を選択したモデル設定フォーム](https://cloud.google.com/static/vertex-ai/docs/predictions/images/deploy-to-pool.png?authuser=0&hl=ja)
REST
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION_ID: Vertex AI を使用するリージョン。
- PROJECT: 実際のプロジェクト ID。
- ENDPOINT_ID: エンドポイントの ID。
- MODEL_ID: デプロイするモデルの ID。
-
DEPLOYED_MODEL_NAME:
DeployedModelの名前。DeployedModelのModelの表示名を使用することもできます。 -
DEPLOYMENT_RESOURCE_POOL_ID:
DeploymentResourcePoolの名前。最大文字数は 63 文字で、有効な文字は /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/ です。 - TRAFFIC_SPLIT_THIS_MODEL: このオペレーションでデプロイするモデルにルーティングされる、このエンドポイントへの予測トラフィックの割合。デフォルトは 100 です。すべてのトラフィックの割合の合計は 100 になる必要があります。トラフィック分割の詳細
- DEPLOYED_MODEL_ID_N: 省略可。他のモデルがこのエンドポイントにデプロイされている場合は、すべての割合の合計が 100 になるように、トラフィック分割の割合を更新する必要があります。
- TRAFFIC_SPLIT_MODEL_N: デプロイされたモデル ID キーのトラフィック分割の割合値。
- PROJECT_NUMBER: プロジェクトに自動生成されたプロジェクト番号
HTTP メソッドと URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
リクエストの本文(JSON):
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
MODEL_ID は、デプロイするモデルの ID に置き換えます。
同じ共有リソースを持つ異なるモデルに対して上記のリクエストを繰り返し、複数のモデルを同じデプロイ リソース プールにデプロイします。
予測を取得する
Vertex AI にデプロイされた他のモデルに対して行う場合と同様に、DeploymentResourcePool のモデルに予測リクエストを送信できます。