이 문서에서는 다양한 요구사항을 충족하기 위해 Vertex AI에서 Ray 클러스터를 설정하는 방법을 안내합니다. 예를 들어 이미지를 빌드하려면 커스텀 이미지를 참고하세요. 일부 기업에서는 비공개 네트워킹을 사용할 수 있습니다. 이 문서에서는 Vertex AI 기반 Ray용 Private Service Connect 인터페이스에 대해 설명합니다. 다른 사용 사례는 원격 파일을 로컬 파일처럼 액세스하는 것입니다(Vertex AI 네트워크 파일 시스템 기반 Ray 참고).
개요
여기에서 다루는 주제는 다음과 같습니다.
- Vertex AI 기반 Ray 클러스터 만들기
- Ray 클러스터의 수명 주기 관리
- 커스텀 이미지 만들기
- 비공개 및 공개 연결 설정(VPC)
- Vertex AI 기반 Ray용 Private Service Connect 인터페이스 사용
- Vertex AI 네트워크 파일 시스템(NFS) 기반 Ray 설정
- VPC-SC + VPC 피어링을 사용한 Ray 대시보드 및 대화형 셸 설정
Ray 클러스터 만들기
Google Cloud 콘솔 또는 Vertex AI SDK for Python을 사용하여 Ray 클러스터를 만들 수 있습니다. 클러스터에는 최대 2,000개의 노드가 있을 수 있습니다. 하나의 작업자 풀에는 최대 1,000개의 노드가 있을 수 있습니다. 작업자 풀 수에는 제한이 없지만 노드가 각각 하나씩 있는 1,000개의 작업자 풀을 보유하는 등 작업자 풀 수가 많으면 클러스터 성능에 부정적인 영향을 미칠 수 있습니다.
시작하기 전에 Vertex AI의 Ray 개요를 읽고 필요한 모든 기본 요건 도구를 설정해야 합니다.
Vertex AI의 Ray 클러스터를 만든 후 이를 시작하려면 10~20분 정도 걸릴 수 있습니다.
콘솔
OSS Ray 권장사항에 따라 Ray 헤드 노드에서 논리적 CPU 수를 0으로 설정하면 헤드 노드에서 워크로드가 강제로 실행되지 않습니다.
Google Cloud 콘솔에서 Vertex AI 기반 Ray 페이지로 이동합니다.
클러스터 만들기를 클릭하여 클러스터 만들기 패널을 엽니다.
클러스터 만들기 패널의 각 단계에서 기본 클러스터 정보를 검토하거나 바꿉니다. 계속을 클릭하여 각 단계를 완료합니다.
이름 및 리전에서 이름을 지정하고 클러스터의 위치를 선택합니다.
컴퓨팅 설정에서 머신 유형, 가속기 유형 및 수, 디스크 유형 및 크기, 복제본 수를 포함하여 Vertex AI의 헤드 노드에서 Ray 클러스터 구성을 지정합니다. 원하는 경우 커스텀 이미지 URI를 추가하여 커스텀 컨테이너 이미지를 지정하여 기본 컨테이너 이미지에서 제공하지 않는 Python 종속 항목을 추가할 수 있습니다. 커스텀 이미지를 참조하세요.
고급 옵션에서 다음 작업을 할 수 있습니다.
- 자체 암호화 키를 지정합니다.
- 커스텀 서비스 계정을 지정합니다.
- 학습 중에 워크로드의 리소스 통계를 모니터링할 필요가 없는 경우 측정항목 수집을 사용 중지합니다.
(선택사항) 클러스터의 비공개 엔드포인트를 배포하려면 Private Service Connect를 사용하는 것이 좋습니다. 자세한 내용은 Vertex AI 기반 Ray용 Private Service Connect 인터페이스를 참고하세요.
만들기를 클릭합니다.
Vertex AI SDK의 Ray
OSS Ray 권장사항에 따라 Ray 헤드 노드에서 논리적 CPU 수를 0으로 설정하면 헤드 노드에서 워크로드가 강제로 실행되지 않습니다.
대화형 Python 환경에서 다음을 사용하여 Vertex AI 기반 Ray 클러스터를 만듭니다.
import ray import vertex_ray from google.cloud import aiplatform from vertex_ray import Resources from vertex_ray.util.resources import NfsMount # Define a default CPU cluster, machine_type is n1-standard-16, 1 head node and 1 worker node head_node_type = Resources() worker_node_types = [Resources()] # Or define a GPU cluster. head_node_type = Resources( machine_type="n1-standard-16", node_count=1, custom_image="us-docker.pkg.dev/my-project/ray-custom.2-9.py310:latest", # Optional. When not specified, a prebuilt image is used. ) worker_node_types = [Resources( machine_type="n1-standard-16", node_count=2, # Must be >= 1 accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, custom_image="us-docker.pkg.dev/my-project/ray-custom.2-9.py310:latest", # When not specified, a prebuilt image is used. )] # Optional. Create cluster with Network File System (NFS) setup. nfs_mount = NfsMount( server="10.10.10.10", path="nfs_path", mount_point="nfs_mount_point", ) aiplatform.init() # Initialize Vertex AI to retrieve projects for downstream operations. # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, network=NETWORK, #Optional worker_node_types=worker_node_types, python_version="3.10", # Optional ray_version="2.47", # Optional cluster_name=CLUSTER_NAME, # Optional service_account=SERVICE_ACCOUNT, # Optional enable_metrics_collection=True, # Optional. Enable metrics collection for monitoring. labels=LABELS, # Optional. nfs_mounts=[nfs_mount], # Optional. )
각 항목의 의미는 다음과 같습니다.
CLUSTER_NAME: 프로젝트 전체에서 고유해야 하는 Vertex AI의 Ray 클러스터 이름입니다.
NETWORK: (선택사항)
projects/PROJECT_ID/global/networks/VPC_NAME형식의 VPC 네트워크의 전체 이름입니다. 클러스터의 공개 엔드포인트 대신 비공개 엔드포인트를 설정하려면 Vertex AI 기반 Ray과 함께 사용할 VPC 네트워크를 지정합니다. 자세한 내용은 비공개 및 공개 연결을 참고하세요.VPC_NAME: 선택사항: VM이 작동하는 VPC입니다.
PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 시작 페이지에서 찾을 수 있습니다.
SERVICE_ACCOUNT: 선택사항: 클러스터에서 Ray 애플리케이션을 실행할 서비스 계정입니다. 필수 역할을 부여합니다.
LABELS: (선택사항) Ray 클러스터를 구성하는 데 사용되는 사용자 정의 메타데이터가 있는 라벨입니다. 라벨 키와 값은 64자(유니코드 코드 포인트) 이하여야 하며 소문자, 숫자, 밑줄, 대시만 포함할 수 있습니다. 국제 문자는 허용됩니다. 라벨에 대한 자세한 내용과 예시는 https://goo.gl/xmQnxf를 참고하세요.
상태가 RUNNING으로 변경될 때까지 다음 출력이 표시되어야 합니다.
[Ray on Vertex AI]: Cluster State = State.PROVISIONING Waiting for cluster provisioning; attempt 1; sleeping for 0:02:30 seconds ... [Ray on Vertex AI]: Cluster State = State.RUNNING
다음에 유의하세요.
첫 번째 노드는 헤드 노드입니다.
TPU 머신 유형은 지원되지 않습니다.
수명 주기 관리
Vertex AI 기반 Ray 클러스터 수명 주기 동안 각 작업은 상태와 연결됩니다. 다음 표에는 각 상태의 청구 상태와 관리 옵션이 요약되어 있습니다. 참고 문서에서는 이러한 각 상태의 정의를 제공합니다.
| 작업 | 상태 | 청구 | 삭제 작업 가능 여부 | 취소 작업 가능 여부 |
|---|---|---|---|---|
| 사용자가 클러스터를 만듭니다. | PROVISIONING | 아니요 | 아니요 | 아니요 |
| 사용자가 수동으로 확대 또는 축소 | 업데이트 | 예, 실시간 사이즈에 따라 다름 | 예 | 아니요 |
| 클러스터가 실행됩니다. | 실행 중 | 예 | 예 | 해당 사항 없음 - 삭제할 수 있음 |
| 클러스터가 자동 확장 또는 축소됨 | 업데이트 | 예, 실시간 사이즈에 따라 다름 | 예 | 아니요 |
| 사용자가 클러스터를 삭제함 | 중지 중 | 아니요 | 아니요 | 해당 사항 없음 - 이미 중지하고 있음 |
| 클러스터가 오류 상태가 됩니다. | 오류 | 아니요 | 예 | 해당 사항 없음 - 삭제할 수 있음 |
| 해당 사항 없음 | STATE_UNSPECIFIED | 아니요 | 예 | 해당 사항 없음 |
커스텀 이미지(선택사항)
사전 빌드된 이미지는 대부분의 사용 사례에 적합합니다. 이미지를 빌드하려면 Vertex AI 기반 Ray 사전 빌드 이미지를 기본 이미지로 사용하세요. 기본 이미지에서 이미지를 빌드하는 방법은 Docker 문서를 참조하세요.
이러한 기본 이미지에는 Python, Ubuntu, Ray 설치가 포함되어 있습니다. 또한 다음과 같은 종속 항목도 포함됩니다.
- python-json-logger
- google-cloud-resource-manager
- ca-certificates-java
- libatlas-base-dev
- liblapack-dev
- g++, libio-all-perl
- libyaml-0-2.
비공개 및 공개 연결
기본적으로 Vertex AI 기반 Ray는 Vertex AI 기반 Ray 클러스터에서 Ray 클라이언트를 사용하여 대화형 개발을 위한 공개적이고 안전한 엔드포인트를 만듭니다. 개발 또는 임시 사용 사례에는 공개 연결을 사용합니다. 이 공개 엔드포인트는 인터넷을 통해 액세스할 수 있습니다. Ray 클러스터의 사용자 프로젝트에 대해 최소한 Vertex AI 사용자 역할 권한이 있는 승인된 사용자만 클러스터에 액세스할 수 있습니다.
클러스터에 대한 비공개 연결이 필요하거나 VPC 서비스 제어를 사용하는 경우 Vertex AI 기반 Ray 클러스터에 대해 VPC 피어링이 지원됩니다. 비공개 엔드포인트가 있는 클러스터는 Vertex AI와 피어링된 VPC 네트워크 내의 클라이언트에서만 액세스할 수 있습니다.
Vertex AI 기반 Ray에 VPC 피어링을 사용하여 비공개 연결을 설정하려면 클러스터를 만들 때 VPC 네트워크를 선택합니다. VPC 네트워크를 사용하려면 VPC 네트워크와 Vertex AI 간에 비공개 서비스 연결이 필요합니다. 콘솔에서 Vertex AI 기반 Ray를 사용하는 경우 클러스터를 만들 때 비공개 서비스 액세스 연결을 설정할 수 있습니다.
Vertex AI에서 Ray 클러스터와 함께 VPC 서비스 제어 및 VPC 피어링을 사용하려면 Ray 대시보드 및 대화형 셸을 사용하기 위한 추가 설정이 필요합니다. Ray 대시보드 및 VPC-SC + VPC 피어링을 사용한 대화형 셸에 설명된 안내에 따라 사용자 프로젝트에서 VPC-SC 및 VPC 피어링을 사용한 대화형 셸 설정을 구성합니다.
Vertex AI에서 Ray 클러스터를 만든 후 Vertex AI SDK for Python을 사용하여 헤드 노드에 연결할 수 있습니다. 연결 환경(예: Compute Engine VM 또는 Vertex AI Workbench 인스턴스)이 Vertex AI와 피어링된 VPC 네트워크에 있어야 합니다. 비공개 서비스 연결에는 IP 주소가 제한되어 있으므로 IP 주소가 모두 소진될 수 있습니다. 따라서 장기 실행 클러스터에는 비공개 연결을 사용하는 것이 좋습니다.
Vertex AI 기반 Ray용 Private Service Connect 인터페이스
Private Service Connect 인터페이스 이그레스 및 Private Service Connect 인터페이스 인그레스는 Vertex AI 기반 Ray 클러스터에서 지원됩니다.
Private Service Connect 인터페이스 이그레스를 사용하려면 아래 안내를 따르세요. VPC 서비스 제어가 사용 설정되지 않은 경우 Private Service Connect 인터페이스 이그레스가 있는 클러스터는 Ray 클라이언트와의 인그레스에 보안 공개 엔드포인트를 사용합니다.
VPC 서비스 제어가 사용 설정된 경우 Private Service Connect 인터페이스 인그레스는 Private Service Connect 인터페이스 이그레스와 함께 기본적으로 사용됩니다. Private Service Connect 인터페이스 인그레스가 있는 클러스터의 노트북에서 Ray 클라이언트에 연결하거나 노트북에서 작업을 제출하려면 노트북이 사용자 프로젝트 VPC 및 서브네트워크 내에 있어야 합니다. VPC 서비스 제어를 설정하는 방법에 관한 자세한 내용은 Vertex AI를 통한 VPC 서비스 제어를 참조하세요.
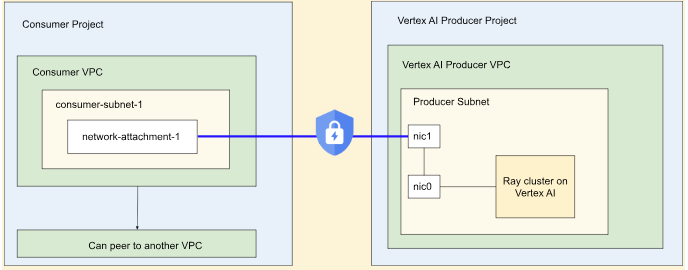
Private Service Connect 인터페이스 사용 설정
리소스 설정 가이드에 따라 Private Service Connect 인터페이스를 설정합니다. 리소스를 설정하면 Vertex AI 기반 Ray 클러스터에서 Private Service Connect 인터페이스를 사용 설정할 수 있습니다.
콘솔
클러스터를 만들면서 이름 및 리전과 컴퓨팅 설정을 지정하면 네트워킹 옵션이 표시됩니다.
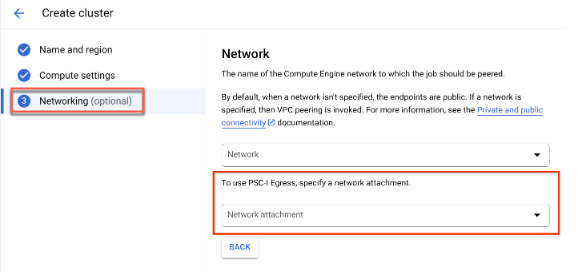
다음 중 하나를 수행하여 네트워크 연결을 설정합니다.
- Private Service Connect용 리소스를 설정할 때 지정한 NETWORK_ATTACHMENT_NAME 이름을 사용합니다.
- 드롭다운에 표시되는 네트워크 연결 만들기 버튼을 클릭하여 새 네트워크 연결을 만듭니다.
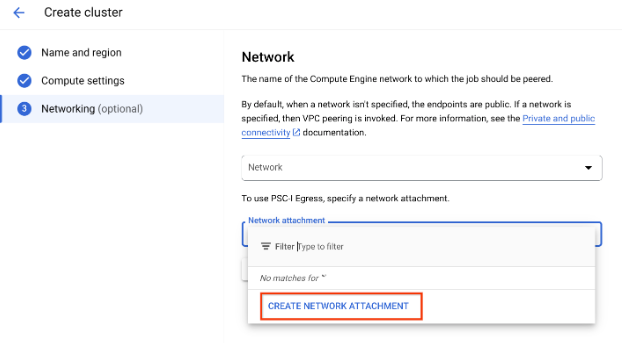
네트워크 연결 만들기를 클릭합니다.
표시되는 하위 작업에서 새 네트워크 연결의 이름, 네트워크 및 하위 네트워크를 지정합니다.
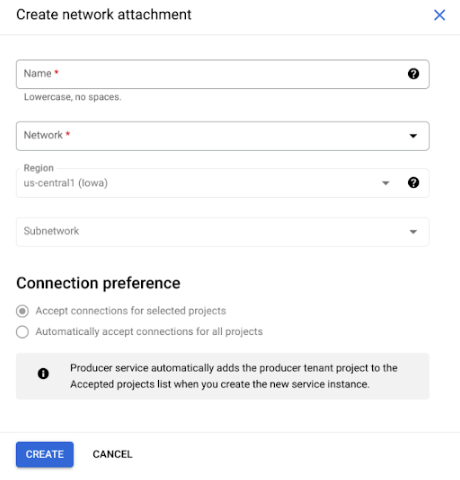
만들기를 클릭합니다.
Vertex AI SDK의 Ray
Vertex AI SDK 기반 Ray는 Vertex AI SDK for Python의 일부입니다. Vertex AI SDK for Python을 설치하거나 업데이트하는 방법은 Vertex AI SDK for Python 설치를 참조하세요. 자세한 내용은 Vertex AI SDK for Python API 참조 문서를 확인하세요.
from google.cloud import aiplatform import vertex_ray # Initialization aiplatform.init() # Create a default cluster with network attachment configuration psc_config = vertex_ray.PscIConfig(network_attachment=NETWORK_ATTACHMENT_NAME) cluster_resource_name = vertex_ray.create_ray_cluster( psc_interface_config=psc_config, )
각 항목의 의미는 다음과 같습니다.
- NETWORK_ATTACHMENT_NAME: 사용자 프로젝트에서 Private Service Connect의 리소스를 설정할 때 지정한 이름입니다.
Vertex AI 네트워크 파일 시스템(NFS) 기반 Ray
클러스터에서 원격 파일을 사용할 수 있도록 하려면 네트워크 파일 시스템(NFS) 공유를 마운트합니다. 그러면 작업이 로컬처럼 원격 파일에 액세스하여 높은 처리량과 짧은 지연 시간을 지원할 수 있습니다.
VPC 설정
VPC를 설정하는 방법에는 두 가지 옵션이 있습니다.
NFS 인스턴스 설정
Filestore 인스턴스를 만드는 방법에 관한 자세한 내용은 인스턴스 만들기를 참조하세요. Private Service Connect 인터페이스 방법을 사용하는 경우 Filestore를 만들 때 비공개 서비스 액세스 모드를 선택하지 않아도 됩니다.
네트워크 파일 시스템(NFS) 사용
네트워크 파일 시스템을 사용하려면 네트워크 또는 네트워크 연결 (권장)을 지정하세요.
콘솔
만들기 페이지의 네트워킹 단계에서 네트워크 또는 네트워크 연결을 지정한 후 네트워크 파일 시스템(NFS) 섹션에서 NFS 마운트 추가를 클릭하고 NFS 마운트(서버, 경로, 마운트 지점)를 지정합니다.
필드 설명 serverNFS 서버의 IP 주소입니다. VPC에 있는 비공개 주소여야 합니다. pathNFS 공유 경로입니다. 이 경로는 /로 시작하는 절대 경로여야 합니다.mountPoint로컬 마운트 지점입니다. 올바른 UNIX 디렉터리 이름이어야 합니다. 예를 들어 로컬 마운트 지점이 sourceData면 학습 VM 인스턴스에서/mnt/nfs/ sourceData경로를 지정합니다.자세한 내용은 컴퓨팅 리소스 지정 위치를 참조하세요.
서버, 경로, 마운트 지점을 지정합니다.
만들기를 클릭합니다. 이렇게 하면 Ray 클러스터가 생성됩니다.
Ray 대시보드 및 VPC-SC + VPC 피어링을 사용한 대화형 셸
-
peered-dns-domains를 구성합니다.{ VPC_NAME=NETWORK_NAME REGION=LOCATION gcloud services peered-dns-domains create training-cloud \ --network=$VPC_NAME \ --dns-suffix=$REGION.aiplatform-training.cloud.google.com. # Verify gcloud beta services peered-dns-domains list --network $VPC_NAME; }
-
NETWORK_NAME: 피어링된 네트워크로 변경합니다.
-
LOCATION: 원하는 위치입니다(예:
us-central1).
-
-
DNS managed zone를 구성합니다.{ PROJECT_ID=PROJECT_ID ZONE_NAME=$PROJECT_ID-aiplatform-training-cloud-google-com DNS_NAME=aiplatform-training.cloud.google.com DESCRIPTION=aiplatform-training.cloud.google.com gcloud dns managed-zones create $ZONE_NAME \ --visibility=private \ --networks=https://www.googleapis.com/compute/v1/projects/$PROJECT_ID/global/networks/$VPC_NAME \ --dns-name=$DNS_NAME \ --description="Training $DESCRIPTION" }
-
PROJECT_ID: 프로젝트 ID입니다. Google Cloud 콘솔의 시작 페이지에서 이 ID를 찾을 수 있습니다.
-
-
DNS 트랜잭션을 기록합니다.
{ gcloud dns record-sets transaction start --zone=$ZONE_NAME gcloud dns record-sets transaction add \ --name=$DNS_NAME. \ --type=A 199.36.153.4 199.36.153.5 199.36.153.6 199.36.153.7 \ --zone=$ZONE_NAME \ --ttl=300 gcloud dns record-sets transaction add \ --name=*.$DNS_NAME. \ --type=CNAME $DNS_NAME. \ --zone=$ZONE_NAME \ --ttl=300 gcloud dns record-sets transaction execute --zone=$ZONE_NAME }
-
대화형 셸 + VPC-SC + VPC 피어링이 사용 설정된 학습 작업을 제출합니다.