このページでは、Vertex AI Model Monitoring の概要について説明します。
モニタリングの概要
Vertex AI Model Monitoring を使用すると、必要に応じて、または定期的にモニタリング ジョブを実行して、表形式モデルの品質を追跡できます。アラートを設定している場合、指標が指定されたしきい値を超えると、Vertex AI Model Monitoring から通知が届きます。
たとえば、顧客のライフタイム バリューを予測するモデルがあるとします。顧客の習慣が変化すると、顧客の支出を予測する要因も変化します。そのため、モデルのトレーニングに以前使用した特徴と特徴値は、現在の予測には関連がない可能性があります。データのこの偏差はドリフトと呼ばれます。
Vertex AI Model Monitoring では、偏差が指定されたしきい値を超えるタイミングを追跡し、アラートを送信できます。その後、モデルの再評価や再トレーニングを行い、モデルが意図したとおりに動作することを確認できます。
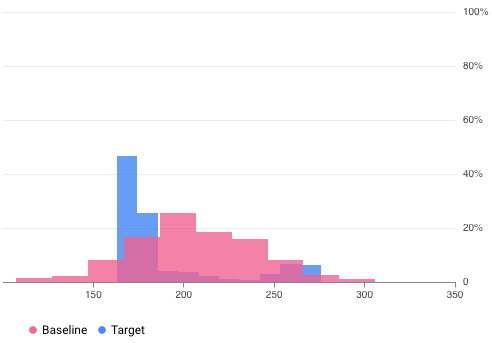
たとえば、Vertex AI Model Monitoring では、次の図のように 2 つのデータセットの 2 つのグラフを重ねて可視化できます。この可視化により、2 つのデータセットの差異を簡単に比較、確認できます。
Vertex AI Model Monitoring のバージョン
Vertex AI Model Monitoring には、v2 と v1 の 2 つのサービスがあります。
Model Monitoring v2 は、プレビュー版であり、すべてのモニタリング タスクをモデル バージョンに関連付ける最新のサービスです。一方、Model Monitoring v1 は一般提供で、Vertex AI エンドポイントで構成されます。
本番環境レベルのサポートが必要で、Vertex AI エンドポイントにデプロイされたモデルをモニタリングする場合は、Model Monitoring v1 を使用します。他のすべてのユースケースでは、Model Monitoring v1 にさらに機能が追加されている Model Monitoring v2 を使用してください。詳細については、各バージョンの概要をご覧ください。
既存の Model Monitoring v1 ユーザーの場合、Model Monitoring v1 はそのまま維持されます。Model Monitoring v2 に移行する必要はありません。移行する場合は、Model Monitoring v2 に完全に移行するまで、両方のバージョンを同時に使用することで、移行で生じるモニタリングの空白期間を回避できます。
Model Monitoring v2 の概要
Model Monitoring v2 を使用すると、モデルモニターを構成してモニタリング ジョブを実行した後、指標を継続的に追跡できます。モニタリング ジョブは、オンデマンドで実行するか、実行するスケジュールを設定できます。スケジュール設定による実行を使用すると、Model Monitoring は定義したスケジュールに基づいてモニタリング ジョブを自動的に実行します。
モニタリングの目的
モニタリングする指標としきい値は、モニタリングの目的にマッピングされます。モニタリングの目的は、各モデル バージョンに 1 つ以上を指定できます。次の表に、各目的の詳細を示します。
| 目的 | 説明 | 特徴のデータ型 | サポートされている指標 |
|---|---|---|---|
| 入力特徴データのドリフト |
ベースライン データ分布と比較して、入力特徴値の分布を測定します。 |
カテゴリ: ブール値、文字列、カテゴリ |
|
| 数値: 浮動小数点数、整数 | Jensen-Shannon ダイバージェンス | ||
| 出力予測データドリフト |
ベースライン データ分布と比較して、モデルの予測データ分布を測定します。 |
カテゴリ: ブール値、文字列、カテゴリ |
|
| 数値: 浮動小数点数、整数 | Jensen-Shannon ダイバージェンス | ||
| 特徴アトリビューション |
ベースラインと比較して、モデルの予測に対する特徴の寄与度の変化を測定します。たとえば、非常に重要な特徴の重要度が突然低下した場合に追跡できます。 |
すべてのデータ型 | SHAP 値(SHapley Additive exPlanations) |
入力特徴と出力予測のドリフト
モデルを本番環境にデプロイした後、入力データがモデルのトレーニングに使用されたデータと異なる場合や、本番環境での特徴データの分布が時間の経過とともに大きく変化する場合があります。Model Monitoring v2 では、トレーニング データと比較した本番環境データの分布の変化をモニタリングすることや、時間の経過に伴う本番環境データの分布の変化を追跡することが可能です。
同様に、予測データの場合、Model Monitoring v2 では、予測結果の分布の変化を、トレーニング データまたは本番環境データの分布と比較して、継続的にモニタリングできます。
特徴アトリビューション
特徴アトリビューションは、モデル内の各特徴が各インスタンスの予測にどの程度影響を及ぼしたかを示します。アトリビューション スコアは、モデルの予測に対する特徴の寄与度に比例します。これらは通常プラスマイナスの符号が付いており、ある特徴が予測の確度を上げたか下げたかを示します。すべての特徴にわたるアトリビューションは、モデルの予測スコアに加算されなければなりません。
Model Monitoring v2 は、特徴アトリビューションをモニタリングすることで、モデルの予測に対する特徴の影響の推移を追跡します。多くの場合、主要な特徴アトリビューション スコアの変化は、モデルの予測の正確さに影響する変化があった可能性を示します。
特徴アトリビューションと指標の詳細については、特徴ベースの説明とサンプリングされたシャープレイ法をご覧ください。
Model Monitoring v2 を設定する方法
まず、Vertex AI Model Registry にモデルを登録する必要があります。Vertex AI の外部でモデルを用意する場合は、モデル アーティファクトをアップロードする必要はありません。次に、モデル バージョンに関連付けるモデルモニターを作成し、モデルスキーマを定義します。AutoML モデルなど、一部のモデルではスキーマが提供されます。
Model Monitor では、モニタリングの目的、トレーニング データセット、モニタリング出力場所、通知設定などのデフォルト構成を必要に応じて指定できます。詳細については、モデル モニタリングを設定するをご覧ください。
モデルモニターを作成した後は、モニタリング ジョブをオンデマンドで実行するか、継続的なモニタリング用に定期的なジョブをスケジュール設定できます。ジョブを実行するときに、別のモニタリング構成を指定しない場合、Model Monitoring はモデルモニターのデフォルト構成セットを使用します。たとえば、異なるモニタリングの目的や比較データセットを指定すると、Model Monitoring はモデルモニタのデフォルト構成ではなく、ジョブの構成を使用します。詳細については、モニタリング ジョブの実行をご覧ください。
料金
プレビュー期間中は、Model Monitoring v2 に対して課金されません。Cloud Storage、BigQuery、Vertex AI バッチ予測、Vertex Explainable AI、Cloud Logging などの他のサービスの使用量に対しては、引き続き課金されます。
ノートブック チュートリアル
次のチュートリアルでは、Vertex AI SDK for Python を使用して、モデル用に Model Monitoring v2 を設定する方法について説明します。
Model Monitoring v2: カスタムモデルのバッチ予測ジョブ
Model Monitoring v2: カスタムモデルのオンライン予測
Model Monitoring v2: Vertex AI 以外のモデル
Model Monitoring v1 の概要
モデルのパフォーマンスを維持するため、Model Monitoring v1 はモデルの予測入力データをモニタリングし、特徴のスキューとドリフトをモニタリングします。
トレーニング / サービング スキューは、本番環境での特徴データの分布が、モデルのトレーニングに使用される特徴データの分布と異なる場合に発生します。元のトレーニング データを利用できる場合は、スキュー検出を有効にして、モデルのトレーニング / サービング スキューをモニタリングできます。
予測ドリフトは、本番環境において特徴データの分布が時間の経過とともに大きく変化した場合に発生します。元のトレーニング データが利用できない場合は、ドリフト検出を有効にして、時間の経過に伴う入力データの変化をモニタリングします。
スキュー検出とドリフト検出の両方を有効にできます。
Model Monitoring v1 では、カテゴリ特徴と数値特徴に対する特徴のスキューとドリフトを検出できます。
カテゴリ特徴は取り得る値の数によって制限されるデータで、通常は定性的性質によって分類されます。たとえば、商品タイプ、国、顧客タイプなどのカテゴリがあります。
数値特徴とは、任意の数値を持つことができるデータです。たとえば、重量や高さなどです。
モデルの特徴のスキューまたはドリフトが、設定したアラートのしきい値を超えると、Model Monitoring v1 はメール通知アラートを送信します。また、時間の経過に伴う各特徴の分布を表示して、モデルの再トレーニングが必要かどうかを評価することもできます。
ドリフトを計算する
v1 のドリフトを検出するため、Vertex AI Model Monitoring は TensorFlow Data Validation(TFDV)を使用して、分布と距離スコアを計算します。
ベースラインの統計的分布を計算します。
スキュー検出の場合、ベースラインはトレーニング データ内の特徴が持つ値の統計的分布です。
ドリフト検出の場合、ベースラインは過去に本番環境で確認された特徴値の統計的分布です。
カテゴリ特徴と数値特徴の分布は次のように計算されます。
カテゴリ特徴の場合、計算される分布は、特徴が取り得る値それぞれのインスタンスの数か割合になります。
数値特徴の場合、Vertex AI Model Monitoring は取り得る特徴値の範囲を等間隔に分割し、各間隔に該当する特徴値の数や割合を計算します。
ベースラインは Vertex AI Model Monitoring ジョブの作成時に計算され、ジョブのトレーニング データセットを更新した場合にのみ再計算されます。
本番環境で確認された最新の特徴値の統計的分布を計算します。
距離スコアを計算して、本番環境の最新の特徴値の分布をベースライン分布と比較します。
カテゴリ特徴の場合、距離スコアはチェビシェフ距離を使用して計算されます。
数値特徴の場合、距離スコアは Jensen-Shannon ダイバージェンスを使用して計算されます。
2 つの統計的分布間の距離スコアが指定のしきい値を超えると、Vertex AI Model Monitoring は異常をスキューまたはドリフトと判断します。
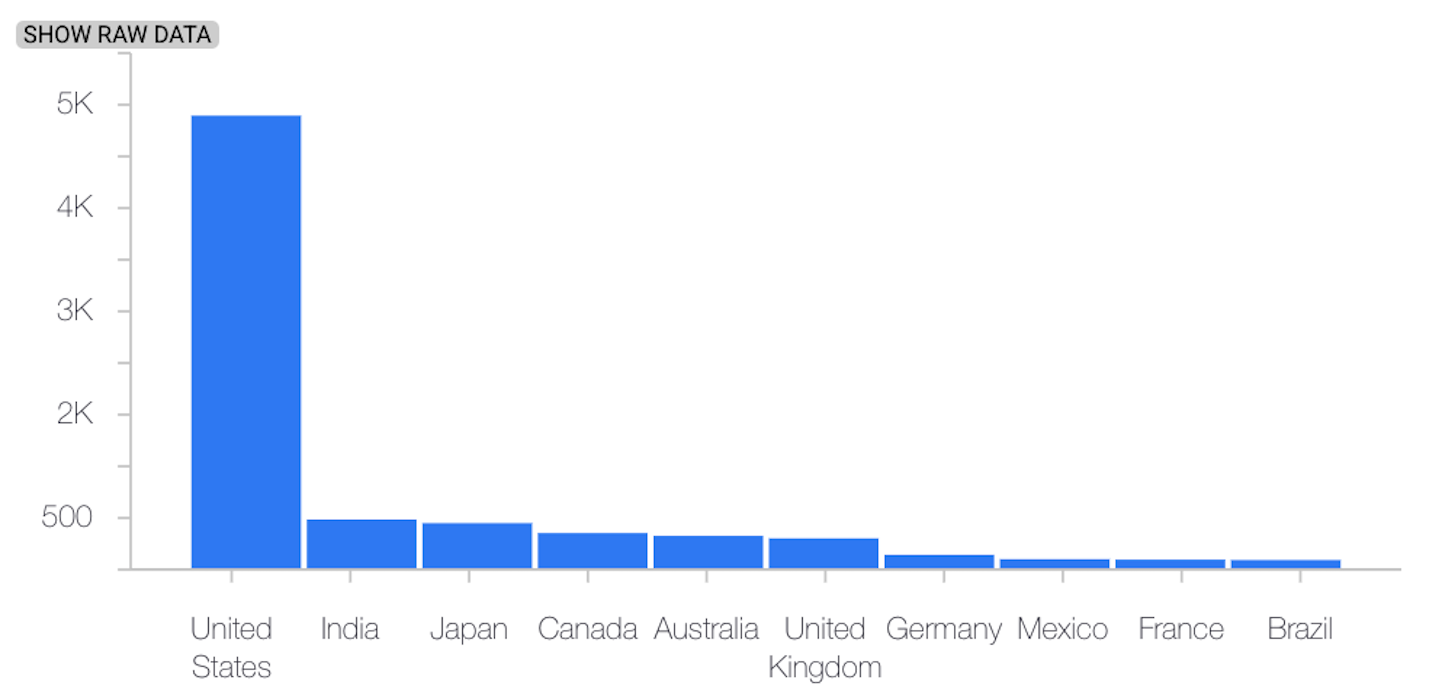
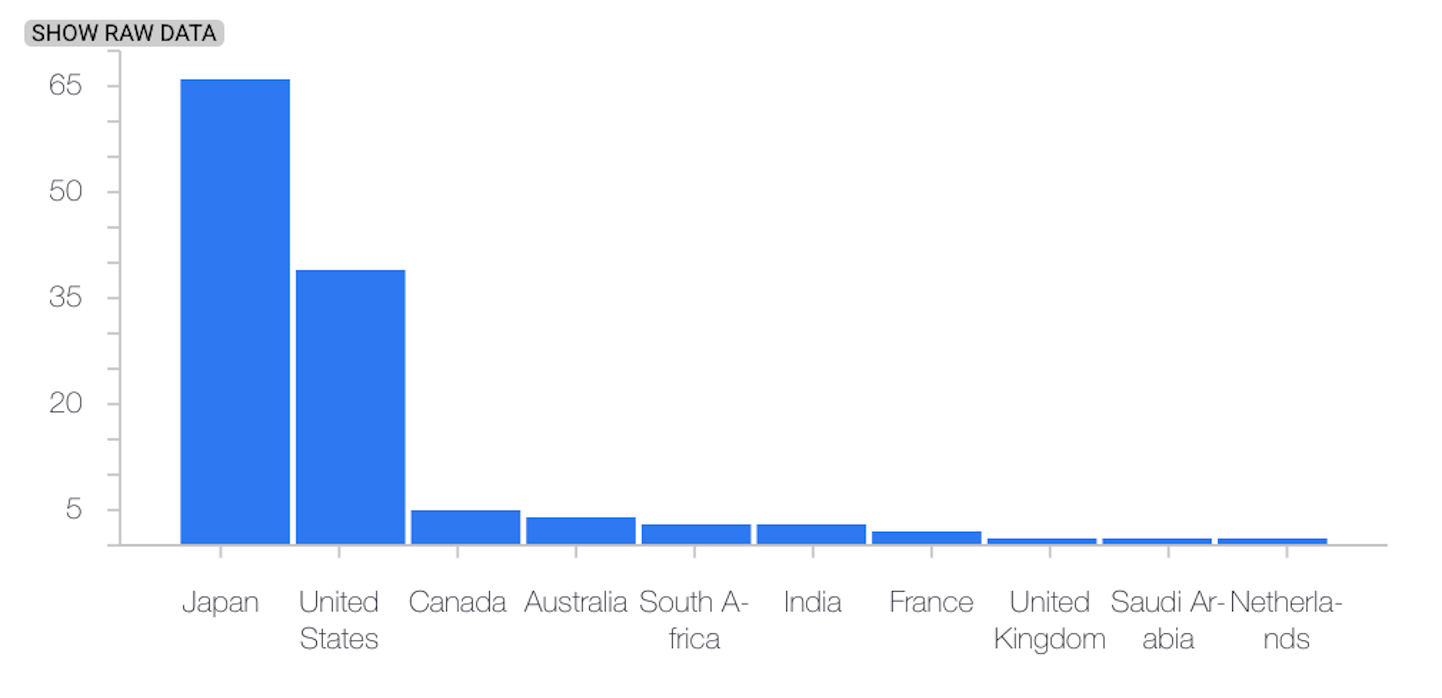
次の例は、カテゴリ特徴のベースライン分布と最新の分布の間のスキューまたはドリフトを示しています。
ベースライン分布
最新の分布
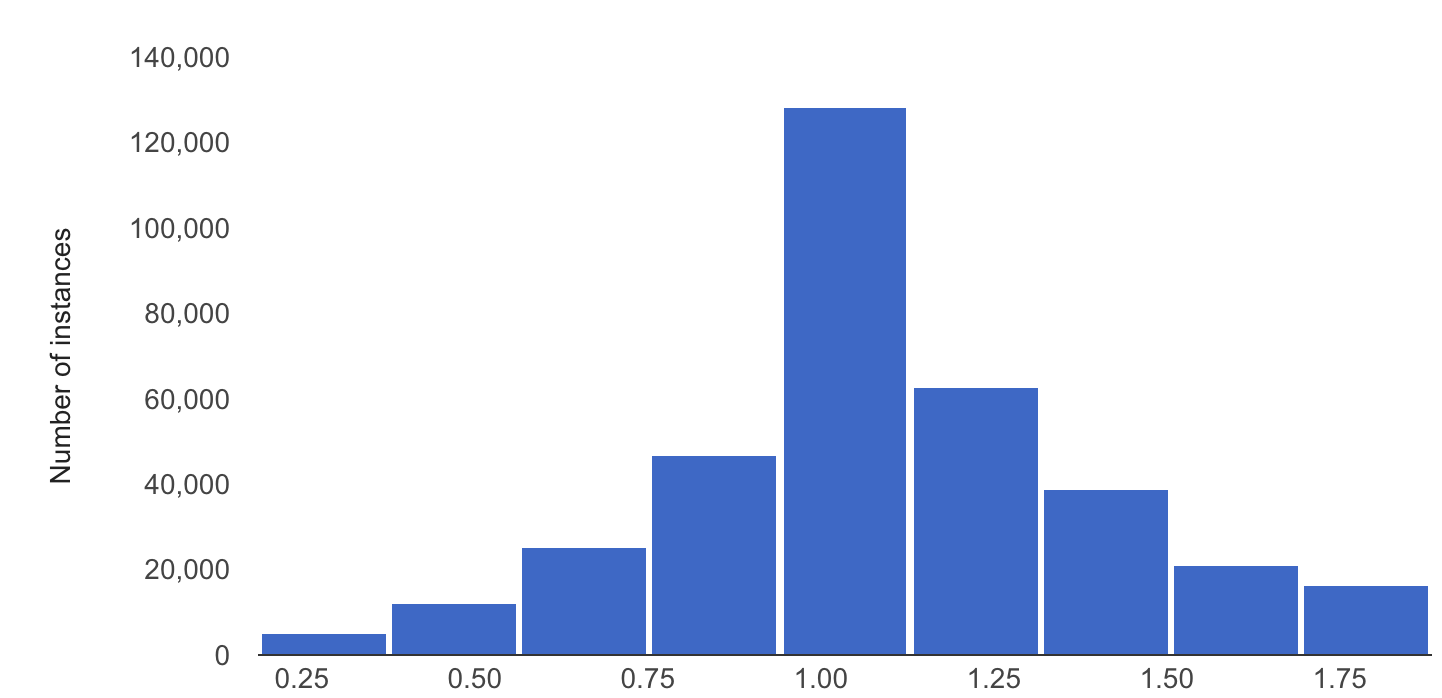
次の例は、数値特徴のベースライン分布と最新の分布の間のスキューまたはドリフトを示しています。
ベースライン分布
最新の分布
Model Monitoring を使用する際の考慮事項
コスト効率を高めるために、予測リクエストのサンプリング レートを設定して、モデルに対する本番環境の入力のサブセットをモニタリングできます。
デプロイされたモデルに最近記録された入力のスキューまたはドリフトをモニタリングする頻度を設定できます。モニタリングの頻度によって、各モニタリング実行で分析されるログデータの期間(モニタリング ウィンドウ サイズ)が決まります。
モニタリング対象の特徴ごとにアラートのしきい値を指定できます。入力特徴の分布と対応するベースライン間の統計的距離が指定のしきい値を超えると、アラートがログに記録されます。デフォルトでは、すべてのカテゴリ特徴と数値特徴がモニタリングされ、しきい値は 0.3 になります。
オンライン予測エンドポイントは、複数のモデルをホストできます。エンドポイントでスキューまたはドリフトの検出を有効にすると、そのエンドポイントでホストされているすべてのモデルで、次の構成パラメータが共有されます。
- 検出のタイプ
- モニタリング頻度
- モニタリングされた入力リクエストの割合
その他の構成パラメータでは、モデルごとに異なる値を設定できます。