本页面介绍如何创建、管理和解释部署到在线预测端点的模型的模型监控作业结果。Vertex AI 模型监控支持分类和数值输入特征的特征偏差和偏移检测。
如果模型部署在生产环境中并启用了模型监控,则传入的预测请求会记录在 Google Cloud 项目的 BigQuery 表中。然后系统会分析记录的请求中包含的输入特征值,以查找偏差或偏移。
如果您为模型提供原始训练数据集,则可以启用偏差检测;否则,您应启用偏移检测。如需了解详情,请参阅 Vertex AI 模型监控简介。
前提条件
要使用模型监控,请完成以下操作:
在 Vertex AI 中准备好可用的模型,可以是表格 AutoML 或导入的表格自定义训练类型。
- 如果您使用的是现有端点,请确保在该端点下部署的所有模型都是 AutoML 表格模型或导入的自定义训练类型。
如果要启用偏差检测,请将训练数据上传到 Cloud Storage 或 BigQuery,并获取指向该数据的 URI 链接。 对于偏移检测,不需要训练数据。
可选:对于自定义训练模型,请将模型的分析实例架构上传到 Cloud Storage。Model Monitoring 要求架构开始监控过程并计算偏差检测的基准分布。如果您在作业创建期间未提供架构,则作业会保持待处理状态,直到 Model Monitoring 可以自动解析模型收到的前 1,000 个预测请求中的架构。
创建模型监控作业
如需设置偏差检测或偏移检测,请创建模型部署监控作业:
控制台
如需使用 Google Cloud 控制台创建模型部署监控作业,请创建端点:
在 Google Cloud 控制台中,转到 Vertex AI 端点页面。
点击创建端点。
在新建端点窗格中,为您的端点命名并设置区域。
点击继续。
在模型名称字段中,选择导入的自定义训练或表格 AutoML 模型。
在版本字段中,选择模型的版本。
点击继续。
在模型监控窗格中,确保为此端点启用模型监控功能处于开启状态。您配置的任何监控设置都会应用于部署到端点的所有模型。
输入监控作业显示名称。
输入监控时长。
在通知电子邮件地址部分,输入一个或多个以英文逗号分隔的电子邮件地址,以便在模型超出提醒阈值时接收提醒。
(可选)在通知渠道部分,添加 Cloud Monitoring 渠道,以便在模型超出提醒阈值时接收提醒。您可以选择现有的 Cloud Monitoring 渠道,也可以通过点击管理通知渠道来创建一个新的 Cloud Monitoring 渠道。控制台支持 PagerDuty、Slack 和 Pub/Sub 通知渠道。
输入采样率。
可选:输入预测输入架构和分析输入架构。
点击继续。此时系统会打开监控目标窗格,其中包含偏差或偏移检测选项:
偏差检测
- 选择训练-应用偏差检测。
- 在训练数据源下,提供训练数据源。
- 在目标列下,输入要训练模型以进行预测的训练数据中的列名称。此字段已从监控分析中排除。
- 可选:在提醒阈值下,指定触发提醒的阈值。如需了解如何设置阈值的格式,请将鼠标指针放在 帮助图标上。
- 点击创建。
偏移检测
- 选择预测偏移检测。
- 可选:在提醒阈值下,指定触发提醒的阈值。如需了解如何设置阈值的格式,请将鼠标指针放在 帮助图标上。
- 点击创建。
gcloud
如需使用 gcloud CLI 创建模型部署监控作业,请先将模型部署到端点。
监控作业配置适用于某个端点下所有已部署的模型。
运行 gcloud ai model-monitoring-jobs create 命令。
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ [--feature-thresholds=FEATURE_1=THRESHOLD_1, FEATURE_2=THRESHOLD_2] \ [--prediction-sampling-rate=SAMPLING_RATE] \ [--monitoring-frequency=MONITORING_FREQUENCY] \ [--analysis-instance-schema=ANALYSIS_INSTANCE_SCHEMA] \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
其中:
PROJECT_ID 是您的 Google Cloud 项目的 ID。 例如
my-project。REGION 是监控作业的位置。 例如
us-central1。MONITORING_JOB_NAME 是监控作业的名称。 例如
my-job。EMAIL_ADDRESS 是您要接收模型监控提醒的电子邮件地址。 例如
example@example.com。ENDPOINT_ID 是在其下部署模型的端点的 ID。例如
1234567890987654321。可选:FEATURE_1=THRESHOLD_1 是您要监控的每个特征的提醒阈值。例如,如果您指定
Age=0.4,当Age特征的输入分布和基准分布之间的统计距离超过 0.4 时,模型监控会记录提醒。默认情况下,每个分类和数值特征都会受监控,并且阈值为 0.3。可选:SAMPLING_RATE 是您要记录的传入预测请求的比例。例如
0.5。如果未指定,则模型监控会记录所有预测请求。可选:MONITORING_FREQUENCY 是您希望监控作业在最近记录的输入上运行的频率。最小粒度为 1 小时。默认值为 24 小时。例如
2。可选:ANALYSIS_INSTANCE_SCHEMA 是描述输入数据格式的架构文件的 Cloud Storage URI。例如
gs://test-bucket/schema.yaml。(只有偏差检测才需要)TARGET_FIELD 是模型正在预测的字段。此字段已从监控分析中排除。例如
housing-price。(只有偏差检测才需要)BIGQUERY_URI 是存储在 BigQuery 中的训练数据集的链接,格式如下:
bq://\PROJECT.\DATASET.\TABLE
例如
bq://\my-project.\housing-data.\san-francisco。您可以将
bigquery-uri标志替换为训练数据集的备用链接:对于存储在 Cloud Storage 存储桶中的 CSV 文件,请使用
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME。对于存储在 Cloud Storage 存储桶中的 TFRecord 文件,请使用
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME。对于表格 AutoML 代管式数据集,请使用
--dataset=DATASET_ID。
Python SDK
如需了解完整的端到端 Model Monitoring API 工作流,请参阅示例笔记本。
REST API
如果您尚未将模型部署到端点,请执行此操作。在执行模型部署说明中的获取端点 ID 步骤期间,记下 JSON 响应中的
deployedModels.id值以备后用:创建模型监控作业请求。以下说明介绍了如何为偏移检测创建基本的监控作业。如需自定义 JSON 请求,请参阅监控作业参考。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:您的 Google Cloud 项目的 ID。例如
my-project。 - LOCATION:监控作业的位置。例如
us-central1。 - MONITORING_JOB_NAME:监控作业的名称。例如
my-job。 - PROJECT_NUMBER:您的 Google Cloud 项目的编号。例如
1234567890。 - ENDPOINT_ID:部署了模型的端点的 ID。例如
1234567890。 - DEPLOYED_MODEL_ID:已部署模型的 ID。
- FEATURE:VALUE:您要监控的每个特征的提醒阈值。例如,如果您指定
"Age": {"value": 0.4},当Age特征的输入分布和基准分布之间的统计距离超过 0.4 时,模型监控会记录提醒。默认情况下,每个分类和数值特征都会受监控,并且阈值为 0.3。 - EMAIL_ADDRESS:您要接收模型监控提醒的电子邮件地址。例如
example@example.com。 - NOTIFICATION_CHANNELS:您要在其中接收模型监控提醒的 Cloud Monitoring 通知渠道列表。使用通知渠道的资源名称,您可以通过列出项目中的通知渠道进行检索。例如
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"。 - 可选:ANALYSIS_INSTANCE_SCHEMA 是描述输入数据格式的架构文件的 Cloud Storage URI。例如
gs://test-bucket/schema.yaml。
请求 JSON 正文:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, }, }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] }, "analysisInstanceSchemaUri": ANALYSIS_INSTANCE_SCHEMA }如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }- PROJECT_ID:您的 Google Cloud 项目的 ID。例如
创建监控作业后,模型监控功能会将传入的预测请求记录在系统生成的名为 PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict 的 BigQuery 表中。如果启用了请求-响应日志记录,则模型监控功能会将传入请求记录到用于请求-响应日志记录的同一 BigQuery 表中。
(可选)为模型监控作业配置提醒
您可以通过提醒监控和调试模型监控作业。Model Monitoring 会自动通过电子邮件通知您作业更新,但您也可以通过 Cloud Logging 和 Cloud Monitoring 通知渠道设置提醒。
电子邮件
对于以下事件,Model Monitoring 会向您在创建 Model Monitoring 作业时指定的每个电子邮件地址发送电子邮件通知:
- 每次设置偏差或偏移检测时。
- 每次更新现有模型监控作业配置时。
- 计划的监控流水线运行每次失败时。
Cloud Logging
如需为计划的监控流水线运行启用日志,请将 modelDeploymentMonitoringJobs 配置中的 enableMonitoringPipelineLogs 字段设置为 true。在设置监控作业时以及在每个监控间隔,调试日志都会写入 Cloud Logging。
调试日志会写入 Cloud Logging,日志名称为 model_monitoring。例如:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring" resource.labels.model_deployment_monitoring_job=6680511704087920640
以下是作业进度日志条目的示例:
{ "insertId": "e2032791-acb9-4d0f-ac73-89a38788ccf3@a1", "jsonPayload": { "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringPipelineLogEntry", "statusCode": { "message": "Scheduled model monitoring pipeline finished successfully for job projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-04T15:33:54.778883Z", "severity": "INFO", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring", "receiveTimestamp": "2022-02-04T15:33:56.343298321Z" }
通知渠道
每当计划的监控流水线运行失败时,Model Monitoring 都会向您在创建 Model Monitoring 作业时指定的 Cloud Monitoring 通知渠道发送通知。
为特征异常值配置提醒
如果超过为特征设置的阈值,模型监控会检测到异常值。Model Monitoring 会自动通过电子邮件通知您检测到的异常,但您也可以通过 Cloud Logging 和 Cloud Monitoring 通知渠道设置提醒。
电子邮件
在每个监控间隔中,如果至少一个特征的阈值超过规定的阈值,则 Model Monitoring 会向您在创建 Model Monitoring 作业时指定的每个电子邮件地址发送电子邮件提醒。该电子邮件包含以下内容:
- 监控作业运行的时间。
- 有偏差或偏移的特征的名称。
- 提醒阈值以及记录的统计距离测量值。
Cloud Logging
如需启用 Cloud Logging 提醒,请将 ModelMonitoringAlertConfig 配置的 enableLogging 字段设置为 true。
在每个监控间隔中,如果至少一个特征的分布超过该特征的阈值,则异常值日志会写入 Cloud Logging。您可以将日志转发到 Cloud Logging 支持的任何服务,例如 Pub/Sub。
异常值会写入 Cloud Logging,日志名称为 model_monitoring_anomaly。例如:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring_anomaly" resource.labels.model_deployment_monitoring_job=6680511704087920640
以下是异常值日志条目的示例:
{ "insertId": "b0e9c0e9-0979-4aff-a5d3-4c0912469f9a@a1", "jsonPayload": { "anomalyObjective": "RAW_FEATURE_SKEW", "endTime": "2022-02-03T19:00:00Z", "featureAnomalies": [ { "featureDisplayName": "age", "deviation": 0.9, "threshold": 0.7 }, { "featureDisplayName": "education", "deviation": 0.6, "threshold": 0.3 } ], "totalAnomaliesCount": 2, "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringAnomaliesLogEntry", "startTime": "2022-02-03T18:00:00Z", "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640", "deployedModelId": "1645828169292316672" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-03T19:00:00Z", "severity": "WARNING", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring_anomaly", "receiveTimestamp": "2022-02-03T19:59:52.121398388Z" }
通知渠道
在每个监控间隔中,如果至少一个特征的阈值超过规定的阈值,则 Model Monitoring 会向您在创建 Model Monitoring 作业时指定的 Cloud Monitoring 通知渠道发送提醒。提醒包括有关触发提醒的 Model Monitoring 作业的信息。
更新模型监控作业
您可以查看、更新、暂停和删除模型监控作业。您必须先暂停作业,然后才能将其删除。
控制台
Google Cloud 控制台不支持暂停和删除;请改用 gcloud CLI。
如需更新模型监控作业的参数,请执行以下操作:
在 Google Cloud 控制台中,转到 Vertex AI 端点页面。
点击要修改的端点的名称。
点击修改设置。
在修改端点窗格中,选择模型监控或监控目标。
更新您要更改的字段。
点击更新。
如需查看模型的指标、提醒和监控属性,请执行以下操作:
在 Google Cloud 控制台中,转到 Vertex AI 端点页面。
点击端点的名称。
在要查看的模型对应的监控列中,点击已启用。
gcloud
运行以下命令:
gcloud ai model-monitoring-jobs COMMAND MONITORING_JOB_ID \ --PARAMETER=VALUE --project=PROJECT_ID --region=LOCATION
其中:
COMMAND 是您要对监控作业执行的命令。例如,
update、pause、resume或delete。如需了解详情,请参阅 gcloud CLI 参考文档。MONITORING_JOB_ID 是监控作业的 ID。例如
123456789。您可以通过 [检索端点信息][检索 ID] 或在 Google Cloud 控制台中查看模型的监控属性来找到该 ID。该 ID 包含在监控作业的资源名称中,格式为projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_ID。(可选)PARAMETER=VALUE 是要更新的参数。此标志仅在使用
update命令时需要。例如monitoring-frequency=2。如需查看您可以更新的参数列表,请参阅 gcloud CLI 参考。PROJECT_ID 是您的 Google Cloud 项目的 ID。例如
my-project。LOCATION 是监控作业的位置。 例如
us-central1。
REST API
暂停作业
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_NUMBER:您的 Google Cloud 项目的编号。例如
1234567890。 - LOCATION:监控作业的位置。例如
us-central1。 - MONITORING_JOB_ID:监控作业的 ID。例如
0987654321。
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{}
删除作业
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_NUMBER:您的 Google Cloud 项目的编号。例如
my-project。 - LOCATION:监控作业的位置。例如
us-central1。 - MONITORING_JOB_ID:监控作业的 ID。例如
0987654321。
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/operations/MONITORING_JOB_ID",
...
"done": true,
...
}
分析偏差和偏移数据
您可以使用 Google Cloud 控制台来直观呈现每个受监控的特征的分布情况,并了解哪些更改随时间变化会导致偏差或偏移。您可以以直方图的形式查看特征值分布。
控制台
如需查看 Google Cloud 控制台中的特征分布直方图,请前往端点页面。
在端点页面上,点击要分析的端点。
在您选择的端点的详情页面上,将会显示在该端点上部署的所有模型的列表。点击要分析的模型的名称。
模型的详情页面列出了模型的输入特征以及相关信息,例如每个特征的提醒阈值以及该特征之前的提醒数量。
如需分析特征,请点击特征的名称。此时会显示一个页面,其中显示该特征的特征分布直方图。
对于每个受监控的特征,您可以在 Google Cloud 控制台中查看最近 50 个监控作业的分布。对于偏差检测,训练数据分布显示在输入数据分布的旁边:
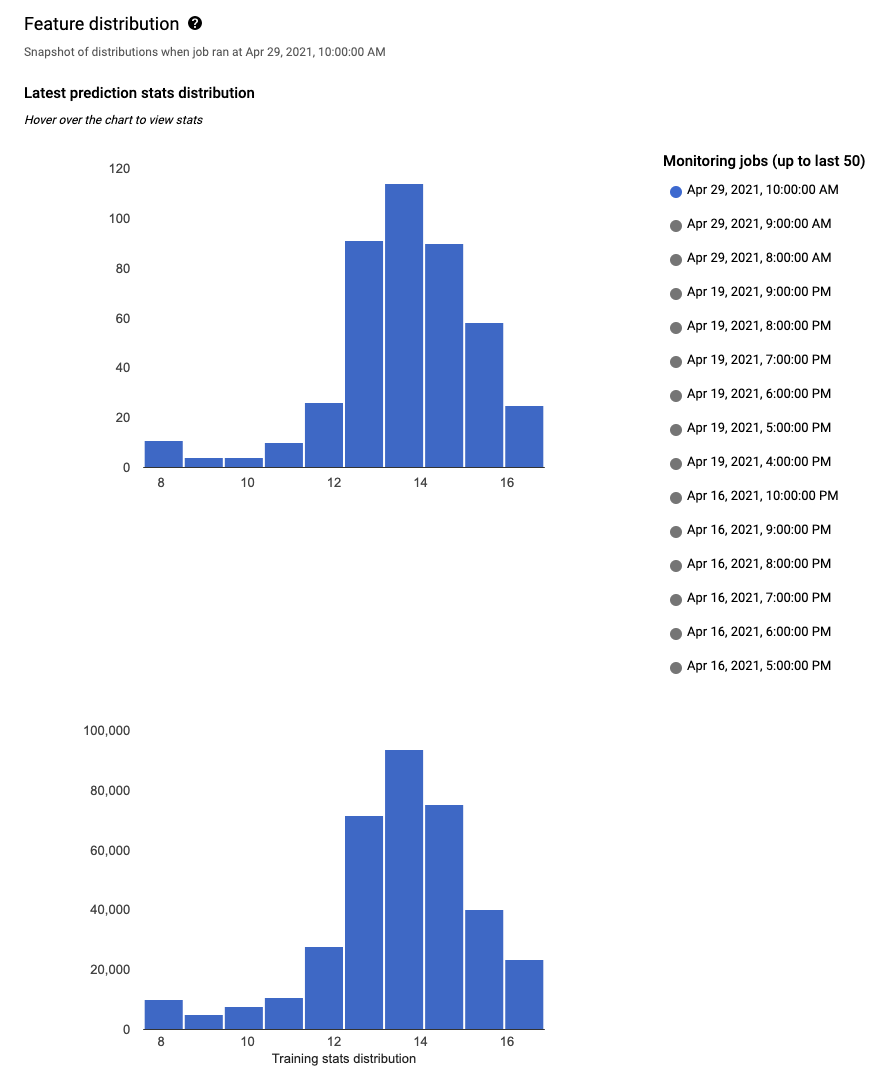
通过以直方图的形式直观呈现数据分布,您可以快速关注数据中发生的变化。之后,您可以决定调整特征生成流水线或重新训练模型。
后续步骤
- 按照 API 文档使用模型监控。
- 按照 gcloud CLI 文档使用模型监控。
- 在 Colab 中试用示例笔记本或在 GitHub 上查看示例笔记本。
- 了解模型监控如何计算训练-应用偏差和预测偏移。