이 페이지에서는 온라인 예측 엔드포인트에 배포된 모델의 Model Monitoring 작업 결과를 생성, 관리, 해석하는 방법을 설명합니다. Vertex AI Model Monitoring에서는 범주형 및 숫자 입력 특성에 대한 특성 편향과 드리프트 감지를 지원합니다.
Model Monitoring이 사용 설정된 상태에서 모델이 프로덕션에 배포되면 수신되는 예측 요청은 Google Cloud 프로젝트의 BigQuery 테이블에 로깅됩니다. 그런 다음 로깅된 요청에 포함된 입력 특성 값이 편향 또는 드리프트에 대해 분석됩니다.
모델의 원래 학습 데이터 세트를 제공하면 편향 감지를 사용 설정할 수 있습니다. 이를 제공하지 않을 경우 드리프트 감지를 사용 설정해야 합니다. 자세한 내용은 Vertex AI Model Monitoring 소개를 참조하세요.
기본 요건
Model Monitoring을 사용하려면 다음을 완료하세요.
테이블 형식 AutoML 또는 가져온 테이블 형식 커스텀 학습 유형의 사용할 수 있는 모델이 Vertex AI에 있어야 합니다.
- 기존 엔드포인트를 사용하는 경우 엔드포인트 아래에 배포된 모든 모델이 테이블 형식 AutoML 또는 가져온 커스텀 학습 유형이어야 하는 점에 유의하세요.
편향 감지를 사용 설정하는 경우 학습 데이터를 Cloud Storage 또는 BigQuery에 업로드하고 데이터의 URI 링크를 가져옵니다. 드리프트 감지의 경우에는 학습 데이터가 필요하지 않습니다.
(선택사항) 커스텀 학습 모델의 경우 모델의 분석 인스턴스 스키마를 Cloud Storage에 업로드합니다. Model Monitoring에서 모니터링 프로세스를 시작하고 편향 감지의 기준 분포를 계산하려면 스키마가 필요합니다. 작업 생성 중 스키마를 제공하지 않으면 Model Monitoring에서 모델이 수신하는 처음 1,000개의 예측 요청에서 스키마를 자동으로 파싱할 수 있을 때까지 작업이 대기 중 상태로 유지됩니다.
Model Monitoring 작업 만들기
편향 감지 또는 드리프트 감지를 설정하려면 모델 배포 모니터링 작업을 만듭니다.
콘솔
Google Cloud 콘솔을 사용하여 모델 배포 모니터링 작업을 만들려면 엔드포인트를 만듭니다.
Google Cloud 콘솔에서 Vertex AI 엔드포인트 페이지로 이동합니다.
엔드포인트 만들기를 클릭합니다.
새 엔드포인트 창에서 엔드포인트의 이름을 지정하고 리전을 설정합니다.
계속을 클릭합니다.
모델 이름 필드에서 가져온 커스텀 학습 또는 테이블 형식 AutoML 모델을 선택합니다.
버전 필드에서 모델 버전을 선택합니다.
계속을 클릭합니다.
Model Monitoring 창에서 이 엔드포인트에 Model Monitoring 사용 설정이 켜져 있는지 확인합니다. 구성한 모니터링 설정이 엔드포인트에 배포된 모든 모델에 적용됩니다.
모니터링 작업 표시 이름을 입력합니다.
모니터링 기간 길이를 입력합니다.
알림 이메일의 경우 모델이 알림 기준을 초과하면 알림을 받을 하나 이상의 이메일 주소를 쉼표로 구분하여 입력합니다.
(선택사항) 알림 채널의 겨우 모델이 알림 기준점을 초과할 때 알림을 수신할 Cloud Monitoring 채널을 추가합니다. 기존 Cloud Monitoring 채널을 선택하거나 알림 채널 관리를 클릭하여 새 채널을 만들 수 있습니다. 콘솔에서는 PagerDuty, Slack, Pub/Sub 알림 채널이 지원됩니다.
샘플링 레이트를 입력합니다.
(선택사항) 예측 입력 스키마 및 분석 입력 스키마를 입력합니다.
계속을 클릭합니다. 편향 또는 드리프트 감지 옵션이 있는 모니터링 목표 창이 열립니다.
편향 감지
- 학습-서빙 편향 감지를 선택하세요.
- 학습 데이터 소스에서 학습 데이터 소스를 제공합니다.
- 타겟 열에서 모델이 예측하도록 학습시킨 학습 데이터의 열 이름을 입력합니다. 이 필드는 모니터링 분석에서 제외됩니다.
- (선택사항) 알림 기준 아래에서 알림을 트리거할 기준점을 지정합니다. 기준점의 형식을 지정하는 방법에 대한 자세한 내용은 도움말 아이콘 위에 마우스 포인터를 올려놓으세요.
- 만들기를 클릭합니다.
드리프트 감지
- 예측 드리프트 감지를 선택하세요.
- (선택사항) 알림 기준 아래에서 알림을 트리거할 기준점을 지정합니다. 기준점의 형식을 지정하는 방법에 대한 자세한 내용은 도움말 아이콘 위에 마우스 포인터를 올려놓으세요.
- 만들기를 클릭합니다.
gcloud
gcloud CLI를 사용하여 모델 배포 모니터링 작업을 만들려면 먼저 모델을 엔드포인트에 배포합니다.
모니터링 작업 구성이 엔드포인트의 배포된 모든 모델에 적용됩니다.
gcloud ai model-monitoring-jobs create 명령어를 실행합니다.
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ [--feature-thresholds=FEATURE_1=THRESHOLD_1, FEATURE_2=THRESHOLD_2] \ [--prediction-sampling-rate=SAMPLING_RATE] \ [--monitoring-frequency=MONITORING_FREQUENCY] \ [--analysis-instance-schema=ANALYSIS_INSTANCE_SCHEMA] \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
각 항목의 의미는 다음과 같습니다.
PROJECT_ID는 Google Cloud 프로젝트 ID입니다. 예를 들면
my-project입니다.REGION은 모니터링 작업 위치입니다. 예를 들면
us-central1입니다.MONITORING_JOB_NAME은 모니터링 작업 이름입니다. 예를 들면
my-job입니다.EMAIL_ADDRESS는 Model Monitoring에서 알림을 받을 이메일 주소입니다. 예를 들면
example@example.com입니다.ENDPOINT_ID는 모델이 배포되는 엔드포인트의 ID입니다. 예를 들면
1234567890987654321입니다.(선택사항) FEATURE_1=THRESHOLD_1은 모니터링할 각 특성의 알림 기준점입니다. 예를 들어
Age=0.4를 지정하면 모델 모니터링에서Age특성의 입력 및 기준 분포 간의 통계 거리가 0.4를 초과하면 알림을 로깅합니다. 기본적으로 모든 범주형 특성 및 숫자형 특성이 모니터링되며 기준점은 0.3입니다.(선택사항) SAMPLING_RATE는 로깅할 수신 예측 요청의 비율입니다. 예를 들면
0.5입니다. 지정하지 않으면 Model Monitoring이 모든 예측 요청을 로깅합니다.(선택사항) MONITORING_FREQUENCY는 최근에 로깅된 입력에서 모니터링 작업을 실행할 빈도입니다. 최소 단위는 1시간입니다. 기본값은 24시간입니다. 예를 들면
2입니다.(선택사항) ANALYSIS_INSTANCE_SCHEMA는 입력 데이터의 형식을 설명하는 스키마 파일의 Cloud Storage URI입니다. 예를 들면
gs://test-bucket/schema.yaml입니다.(편향 감지에만 필수) TARGET_FIELD는 모델에서 예측하는 필드입니다. 이 필드는 모니터링 분석에서 제외됩니다. 예를 들면
housing-price입니다.(편향 감지에만 필수) BIGQUERY_URI는 다음 형식을 사용하여 BigQuery에 저장된 학습 데이터 세트의 링크입니다.
bq://\PROJECT.\DATASET.\TABLE
예를 들면
bq://\my-project.\housing-data.\san-francisco입니다.bigquery-uri플래그를 학습 데이터 세트의 대체 링크로 바꾸면 됩니다.Cloud Storage 버킷에 저장된 CSV 파일의 경우
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME을 사용합니다.Cloud Storage 버킷에 저장된 TFRecord 파일의 경우
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME을 사용합니다.테이블 형식 AutoML 관리형 데이터 세트의 경우
--dataset=DATASET_ID를 사용합니다.
Python SDK
완전한 엔드 투 엔드 Model Monitoring API 워크플로에 대한 자세한 내용은 예시 노트북을 참조하세요.
REST API
아직 엔드포인트에 모델을 배포하지 않았다면 배포합니다. 모델 배포 안내의 엔드포인트 ID 가져오기 단계에서 나중에 사용할 수 있도록 JSON 응답의
deployedModels.id값을 기록해 둡니다.모델 모니터링 작업 요청을 만듭니다. 다음 안내에서는 드리프트 감지를 위한 기본 모니터링 작업을 만드는 방법을 보여줍니다. JSON 요청을 맞춤설정하려면 Monitoring 작업 참조를 확인하세요.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 예를 들면
my-project입니다. - LOCATION: 모니터링 작업 위치입니다. 예를 들면
us-central1입니다. - MONITORING_JOB_NAME: 모니터링 작업 이름입니다. 예를 들면
my-job입니다. - PROJECT_NUMBER: Google Cloud 프로젝트의 번호입니다. 예를 들면
1234567890입니다. - ENDPOINT_ID: 모델이 배포된 엔드포인트의 ID입니다. 예를 들면
1234567890입니다. - DEPLOYED_MODEL_ID: 배포된 모델의 ID입니다.
- FEATURE:VALUE: 모니터링할 각 특성의 알림 기준점입니다. 예를 들어
"Age": {"value": 0.4}를 지정하면 모델 모니터링에서Age특성의 입력 및 기준 분포 간의 통계 거리가 0.4를 초과하면 알림을 로깅합니다. 기본적으로 모든 범주형 특성 및 숫자형 특성이 모니터링되며 기준점은 0.3입니다. - EMAIL_ADDRESS: Model Monitoring에서 알림을 받을 이메일 주소입니다. 예를 들면
example@example.com입니다. - NOTIFICATION_CHANNELS: Model Monitoring에서 알림을 수신하려는 Cloud Monitoring 알림 채널 목록입니다. 프로젝트의 알림 채널 나열로 검색할 수 있는 알림 채널의 리소스 이름을 사용합니다. 예를 들면
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568"입니다. - (선택사항) ANALYSIS_INSTANCE_SCHEMA는 입력 데이터의 형식을 설명하는 스키마 파일의 Cloud Storage URI입니다. 예를 들면
gs://test-bucket/schema.yaml입니다.
JSON 요청 본문:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, }, }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] }, "analysisInstanceSchemaUri": ANALYSIS_INSTANCE_SCHEMA }요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 예를 들면
모니터링 작업이 생성된 후 Model Monitoring이 PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict라는 생성된 BigQuery 테이블에 수신되는 예측 요청을 로깅합니다.
요청-응답 로깅이 사용 설정된 경우 Model Monitoring이 요청-응답 로깅에 사용된 동일한 BigQuery 테이블에 수신되는 요청을 로깅합니다.
(선택사항) Model Monitoring 작업 알림 구성
알림을 통해 Model Monitoring 작업을 모니터링하고 디버깅할 수 있습니다. Model Monitoring은 이메일을 통해 작업 업데이트 알림을 자동으로 표시하지만 Cloud Logging 및 Cloud Monitoring 알림 채널을 통해 알림을 설정할 수도 있습니다.
이메일
다음 이벤트의 경우 Model Monitoring은 Model Monitoring 작업을 만들 때 지정한 각 이메일 주소로 이메일 알림을 전송합니다.
- 편향 또는 드리프트 감지가 설정될 때마다
- 기존 Model Monitoring 작업 구성이 업데이트될 때마다
- 예약된 모니터링 파이프라인 실행이 실패할 때마다
Cloud Logging
예약된 모니터링 파이프라인 실행에 대해 로그를 사용 설정하려면 modelDeploymentMonitoringJobs 구성에서 enableMonitoringPipelineLogs 필드를 true로 설정합니다. 디버깅 로그는 모니터링 작업이 설정되면 각 모니터링 간격으로 Cloud Logging에 기록됩니다.
디버깅 로그는 로그 이름 model_monitoring으로 Cloud Logging에 기록됩니다. 예를 들면 다음과 같습니다.
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring" resource.labels.model_deployment_monitoring_job=6680511704087920640
다음은 작업 진행 상태 로그 항목의 예시입니다.
{ "insertId": "e2032791-acb9-4d0f-ac73-89a38788ccf3@a1", "jsonPayload": { "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringPipelineLogEntry", "statusCode": { "message": "Scheduled model monitoring pipeline finished successfully for job projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-04T15:33:54.778883Z", "severity": "INFO", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring", "receiveTimestamp": "2022-02-04T15:33:56.343298321Z" }
알림 채널
예약된 모니터링 파이프라인 실행이 실패할 때마다 Model Monitoring은 Model Monitoring 작업을 만들 때 지정한 Cloud Monitoring 알림 채널에 알림을 전송합니다.
특성 이상치 알림 구성
Model Monitoring은 특성에 설정된 기준점이 초과되면 이상치를 감지합니다. Model Monitoring은 이메일을 통해 감지된 이상치 알림을 자동으로 표시하지만 Cloud Logging 및 Cloud Monitoring 알림 채널을 통해 알림을 설정할 수도 있습니다.
이메일
특성 기준점 최소 하나 이상이 기준점을 초과하면 Model Monitoring은 각 모니터링 간격으로 Model Monitoring 작업을 만들 때 지정한 각 이메일 주소로 이메일 알림을 전송합니다. 이메일 메시지에는 다음이 포함됩니다.
- 모니터링 작업이 실행된 시간
- 편향 또는 드리프트가 있는 특성의 이름
- 알림 기준점과 기록된 통계 거리 측정
Cloud Logging
Cloud Logging 알림을 사용 설정하려면 ModelMonitoringAlertConfig 구성의 enableLogging 필드를 true로 설정합니다.
특성 분포 최소 하나 이상이 해당 특성의 기준점을 초과하면 각 모니터링 간격에서 이상 로그가 Cloud Logging에 기록됩니다. Pub/Sub와 같이 Cloud Logging에서 지원하는 모든 서비스에 로그를 전달할 수 있습니다.
이상은 로그 이름 model_monitoring_anomaly를 사용하여 Cloud Logging에 기록됩니다. 예를 들면 다음과 같습니다.
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring_anomaly" resource.labels.model_deployment_monitoring_job=6680511704087920640
다음은 이상 로그 항목의 예시입니다.
{ "insertId": "b0e9c0e9-0979-4aff-a5d3-4c0912469f9a@a1", "jsonPayload": { "anomalyObjective": "RAW_FEATURE_SKEW", "endTime": "2022-02-03T19:00:00Z", "featureAnomalies": [ { "featureDisplayName": "age", "deviation": 0.9, "threshold": 0.7 }, { "featureDisplayName": "education", "deviation": 0.6, "threshold": 0.3 } ], "totalAnomaliesCount": 2, "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringAnomaliesLogEntry", "startTime": "2022-02-03T18:00:00Z", "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640", "deployedModelId": "1645828169292316672" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-03T19:00:00Z", "severity": "WARNING", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring_anomaly", "receiveTimestamp": "2022-02-03T19:59:52.121398388Z" }
알림 채널
각 모니터링 간격에서 최소 하나 이상의 기능이 기준점을 초과하면 Model Monitoring이 Model Monitoring 작업을 만들 때 지정한 Cloud Monitoring 알림 채널에 알림을 전송합니다. 알림에는 알림을 트리거한 Model Monitoring 작업 정보가 포함됩니다.
Model Monitoring 작업 업데이트
Model Monitoring 작업을 업데이트, 일시중지, 삭제할 수 있습니다. 작업을 일시중지해야 삭제할 수 있습니다.
콘솔
Google Cloud 콘솔에서는 일시중지 및 삭제가 지원되지 않습니다. 대신 gcloud CLI를 사용하세요.
모델 모니터링 작업의 파라미터를 업데이트하려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 Vertex AI 엔드포인트 페이지로 이동합니다.
수정할 엔드포인트의 이름을 클릭합니다.
설정 수정을 클릭합니다.
엔드포인트 수정 창에서 Model Monitoring 또는 모니터링 목표를 선택합니다.
변경하려는 필드를 업데이트합니다.
업데이트를 클릭합니다.
모델의 측정항목, 알림, 모니터링 속성을 보려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 Vertex AI 엔드포인트 페이지로 이동합니다.
엔드포인트 이름을 클릭합니다.
보려는 모델의 Monitoring 열에서 사용 설정됨을 클릭합니다.
gcloud
다음 명령어를 실행합니다.
gcloud ai model-monitoring-jobs COMMAND MONITORING_JOB_ID \ --PARAMETER=VALUE --project=PROJECT_ID --region=LOCATION
각 항목의 의미는 다음과 같습니다.
COMMAND는 모니터링 작업에 수행할 명령어입니다. 예를 들면
update,pause,resume,delete입니다. 자세한 내용은 gcloud CLI 참조를 확인하세요.MONITORING_JOB_ID는 모니터링 작업의 ID입니다. 예를 들면
123456789입니다. [엔드포인트 정보를 검색][retrieve-id]하거나 Google Cloud 콘솔에서 모델의 Monitoring 속성을 확인하여 ID를 찾을 수 있습니다. ID는projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_ID형식의 모니터링 작업 리소스 이름에 포함됩니다.(선택사항) PARAMETER=VALUE는 업데이트할 파라미터입니다. 이 플래그는
update명령어를 사용할 때만 필요합니다. 예를 들면monitoring-frequency=2입니다. 업데이트할 수 있는 파라미터 목록은 gcloud CLI 참조를 확인하세요.PROJECT_ID는 Google Cloud 프로젝트의 ID입니다. 예를 들면
my-project입니다.LOCATION은 모니터링 작업 위치입니다. 예를 들면
us-central1입니다.
REST API
작업 일시중지
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_NUMBER: Google Cloud 프로젝트 수입니다. 예를 들면
1234567890입니다. - LOCATION: 모니터링 작업 위치입니다. 예를 들면
us-central1입니다. - MONITORING_JOB_ID: 모니터링 작업의 ID입니다. 예를 들면
0987654321입니다.
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{}
작업 삭제
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_NUMBER: Google Cloud 프로젝트 수입니다. 예를 들면
my-project입니다. - LOCATION: 모니터링 작업 위치입니다. 예를 들면
us-central1입니다. - MONITORING_JOB_ID: 모니터링 작업의 ID입니다. 예를 들면
0987654321입니다.
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/operations/MONITORING_JOB_ID",
...
"done": true,
...
}
편향 및 드리프트 데이터 분석
Google Cloud 콘솔을 사용하여 각 모니터링 특성의 분포를 시각화하고 시간 경과에 따라 편향 또는 드리프트를 유발한 변경사항을 확인할 수 있습니다. 히스토그램으로 특성 값 분포를 볼 수 있습니다.
콘솔
Google Cloud 콘솔에서 특성 배포 히스토그램으로 이동하려면 엔드포인트 페이지로 이동합니다.
엔드포인트 페이지에서 분석하려는 엔드포인트를 클릭합니다.
선택한 엔드포인트의 세부정보 페이지에 해당 엔드포인트에 배포된 모든 모델의 목록이 있습니다. 분석할 모델의 이름을 클릭합니다.
모델의 세부정보 페이지에는 모델의 입력 특성과 함께 각 특성의 알림 기준점 및 특성에 대한 이전 알림 수와 같은 관련 정보가 나열됩니다.
특성을 분석하려면 특성 이름을 클릭합니다. 페이지에 해당 특성의 특성 배포 히스토그램이 표시됩니다.
각 모니터링 기능에 대해 Google Cloud 콘솔에서 최근 모니터링 작업 50개의 분포를 확인할 수 있습니다. 편향 감지의 경우 학습 데이터 분포는 입력 데이터 분포 옆에 표시됩니다.
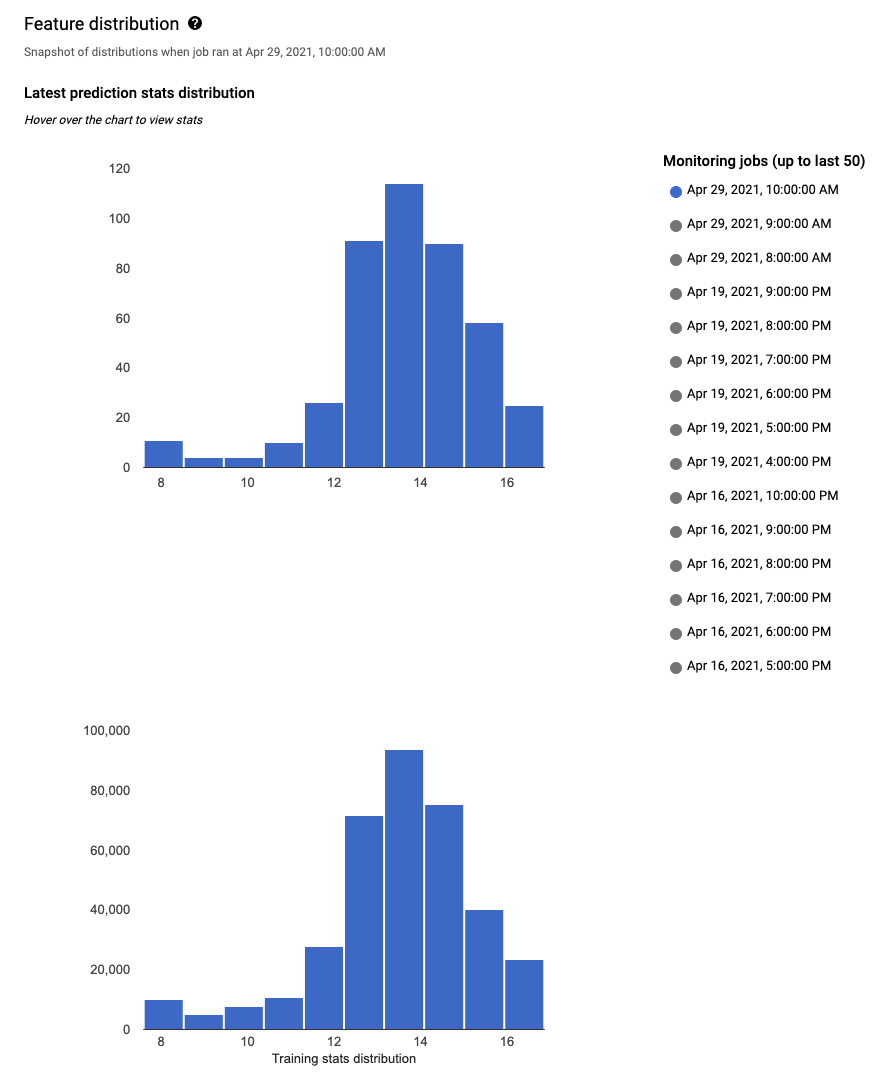
데이터 분포를 히스토그램으로 시각화하면 데이터에서 발생한 변경사항에 빠르게 집중할 수 있습니다. 이후 특성 생성 파이프라인을 조정하거나 모델을 다시 학습시킬 수 있습니다.
다음 단계
- API 문서에 따라 Model Monitoring 작업 수행하기
- gcloud CLI 문서에 따라 Model Monitoring 작업 수행하기
- Colab에서 노트북 예시를 사용해 보거나 GitHub에서 보기
- Model Monitoring에서 학습-제공 편향 및 예측 드리프트를 계산하는 방법 알아보기