En esta página, se describe cómo crear, administrar y, también, interpretar los resultados de los trabajos de Model Monitoring para modelos implementados en los extremos de predicción en línea. Vertex AI Model Monitoring admite el sesgo de atributos y la detección de desvíos para atributos de entrada categóricos y numéricos.
Cuando un modelo está en producción con Model Monitoring habilitado, sus solicitudes de predicción entrantes se registran en una tabla de BigQuery en tu proyecto de Google Cloud. Luego, los valores del atributo de entrada contenidos en las solicitudes registradas se analizan en busca de sesgos o desvíos.
Puedes habilitar la detección de sesgo si proporcionas el conjunto de datos de entrenamiento original para tu modelo. De lo contrario, deberás habilitar la detección de desvío. Para obtener más información, consulta Introducción a Vertex AI Model Monitoring.
Requisitos previos
Para usar Model Monitoring, completa lo siguiente:
Ten un modelo disponible en Vertex AI que sea un tipo de entrenamiento personalizado tabular importado o AutoML tabular.
- Si usas un extremo existente, asegúrate de que todos los modelos implementados en el extremo sean AutoML tabulares o tipos de entrenamiento personalizados importados.
Si habilitas la detección de sesgo, sube los datos de entrenamiento a Cloud Storage o BigQuery y obtén el vínculo del URI a los datos. Para la detección de desvíos, no se requieren datos de entrenamiento.
Opcional: Para los modelos con entrenamiento personalizado, sube el esquema de instancia de análisis de tu modelo a Cloud Storage. El modelo de Monitoring requiere que el esquema comience el proceso de supervisión y calcule la distribución de referencia para la detección de sesgos. Si no proporcionas el esquema durante la creación del trabajo, este permanece en estado pendiente hasta que la supervisión del modelo pueda analizar de forma automática el esquema de las primeras 1,000 solicitudes de predicción que recibe el modelo.
Crea un trabajo de Model Monitoring
Para configurar la detección de sesgo o de desvío, crea un trabajo de supervisión de la implementación del modelo:
Console
Para crear un trabajo de supervisión de la implementación del modelo con la consola de Google Cloud, crea un extremo:
En la consola de Google Cloud, ve a la página Extremos de Vertex AI.
Haz clic en Crear extremo.
En el panel Nuevo extremo, asigna un nombre al extremo y configura una región.
Haz clic en Continuar.
En el campo Nombre del modelo, selecciona un entrenamiento personalizado importado o un modelo tabular de AutoML.
En el campo Versión, selecciona una versión para tu modelo.
Haz clic en Continuar.
En el panel Supervisión del modelo, asegúrate de que la opción Habilitar la supervisión de modelos para este extremo esté activada. Cualquier configuración de supervisión que establezcas se aplica a todos los modelos implementados en el extremo.
Ingresa un nombre visible de trabajo de supervisión.
Ingresa una longitud de ventana de supervisión.
En Notificaciones por correo electrónico, ingresa una o más direcciones de correo electrónico separadas por comas para recibir alertas cuando un modelo supere un umbral de alertas.
En los Canales de notificaciones, agrega canales de Cloud Monitoring para recibir alertas cuando un modelo exceda un umbral de alertas (opcional). Puedes seleccionar canales existentes de Cloud Monitoring o crear uno nuevo haciendo clic en Administrar canales de notificaciones. La consola es compatible con los canales de notificaciones de PagerDuty, Slack y Pub/Sub.
Ingresa una Tasa de muestreo.
Opcional: Ingresa el Esquema de entrada de predicción y el Esquema de entrada de análisis.
Haz clic en Continuar. Se abrirá el panel Objetivo de supervisión con opciones para la detección de desvíos o sesgos:
Detección de sesgos
- Selecciona Detección de sesgos entre el entrenamiento y la entrega.
- En Fuente de datos de entrenamiento, proporciona una fuente de datos de entrenamiento.
- En Columna objetivo, ingresa el nombre de la columna de los datos de entrenamiento que el modelo está entrenado para predecir. Este campo se excluye del análisis de supervisión.
- Opcional: En Límites de alerta, especifica los límites para activar las alertas. Para obtener información sobre cómo dar formato a los umbrales, mantén el puntero sobre el ícono de ayuda .
- Haga clic en Crear.
Detección de desvíos
- Selecciona Detección de desvío de predicción.
- Opcional: En Límites de alerta, especifica los límites para activar las alertas. Para obtener información sobre cómo dar formato a los umbrales, mantén el puntero sobre el ícono de ayuda .
- Haga clic en Crear.
gcloud
Para crear un trabajo de supervisión de la implementación del modelo con la CLI de gcloud, primero implementa tu modelo en un extremo.
La configuración de un trabajo de supervisión se aplica a todos los modelos implementados en un extremo.
Ejecuta el comando gcloud ai model-monitoring-jobs create.
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ [--feature-thresholds=FEATURE_1=THRESHOLD_1, FEATURE_2=THRESHOLD_2] \ [--prediction-sampling-rate=SAMPLING_RATE] \ [--monitoring-frequency=MONITORING_FREQUENCY] \ [--analysis-instance-schema=ANALYSIS_INSTANCE_SCHEMA] \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
Donde:
PROJECT_ID es el ID de tu proyecto de Google Cloud. Por ejemplo,
my-project.REGION es la ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1.MONITORING_JOB_NAME es el nombre de tu trabajo de supervisión. Por ejemplo,
my-job.EMAIL_ADDRESS es la dirección de correo electrónico en la que deseas recibir alertas de Model Monitoring. Por ejemplo,
example@example.com.ENDPOINT_ID es el ID del extremo en el que se implementa el modelo. Por ejemplo,
1234567890987654321.Opcional: FEATURE_1=THRESHOLD_1 es el umbral de alertas de cada función que deseas supervisar. Por ejemplo, si especificas
Age=0.4, Model Monitoring registra una alerta cuando la distancia estadística entre las distribuciones de entrada y del modelo de referencia para el atributoAgesupera 0.4. De forma predeterminada, se supervisa cada atributo categórico y numérico, con valores de umbral de 0.3.Opcional: SAMPLING_RATE es la fracción de las solicitudes de predicción entrantes que deseas registrar. Por ejemplo,
0.5. Si no se especifica, Model Monitoring registra todas las solicitudes de predicción.Opcional: MONITORING_FREQUENCY es la frecuencia con la que deseas que el trabajo de supervisión se ejecute en las entradas registradas recientemente. El nivel de detalle mínimo es 1 hora. El valor predeterminado es de 24 horas. Por ejemplo,
2.Opcional: ANALYSIS_INSTANCE_SCHEMA es el URI de Cloud Storage para el archivo de esquema que describe el formato de tus datos de entrada. Por ejemplo,
gs://test-bucket/schema.yaml.(obligatorio para la detección de sesgo) TARGET_FIELD es el campo que predice el modelo. Este campo se excluye del análisis de supervisión. Por ejemplo,
housing-price.(obligatorio para la detección de sesgo) BIGQUERY_URI es obligatorio para el conjunto de datos de entrenamiento almacenado en BigQuery y usa el siguiente formato:
bq://\PROJECT.\DATASET.\TABLE
Por ejemplo,
bq://\my-project.\housing-data.\san-francisco.Puedes reemplazar la marca
bigquery-uripor vínculos alternativos a tu conjunto de datos de entrenamiento:Para un archivo CSV almacenado en un bucket de Cloud Storage, usa
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para un archivo TFRecord almacenado en un bucket de Cloud Storage, usa
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAME.Para un conjunto de datos administrado de AutoML tabular, usa
--dataset=DATASET_ID.
Python SDK
Para obtener información sobre el flujo de trabajo de la API de Model Monitoring de modelo de extremo a extremo, consulta el notebook de ejemplo.
API de REST
Si aún no lo hiciste, implementa tu modelo en un extremo. Durante el paso Obtén el ID de extremo en las instrucciones de implementación del modelo, anota el valor
deployedModels.iden la respuesta JSON para su uso posterior:Crea una solicitud de trabajo de supervisión de modelo. En las instrucciones que aparecen a continuación, se muestra cómo crear un trabajo de supervisión básico para la detección de desvío. Para personalizar la solicitud JSON, consulta la referencia del trabajo de Monitoring.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_ID: es el ID de tu proyecto de Google Cloud. Por
ejemplo,
my-project - LOCATION: es la ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1. - MONITORING_JOB_NAME: es el nombre de tu trabajo de supervisión. Por
ejemplo,
my-job - PROJECT_NUMBER: es el número de tu proyecto de Google Cloud. Por
ejemplo,
1234567890 - ENDPOINT_ID es el ID para el extremo en el que se implementa tu modelo. Por
ejemplo,
1234567890 - DEPLOYED_MODEL_ID es el ID del modelo implementado.
- FEATURE:VALUE es el umbral de alertas de cada función que deseas supervisar. Por ejemplo, si especificas
"Age": {"value": 0.4}, la supervisión de modelos registra una alerta cuando la distancia estadística entre las distribuciones de entrada y modelo de referencia para el atributoAgeexcede 0.4. De forma predeterminada, se supervisa cada atributo categórico y numérico, con valores de umbral de 0.3. - EMAIL_ADDRESS: es la dirección de correo electrónico en la que deseas recibir alertas de Model Monitoring. Por ejemplo,
example@example.com. - NOTIFICATION_CHANNELS:
Una lista de
canales de notificación de Cloud Monitoring
en los que deseas recibir alertas de Model Monitoring. Usa los nombres de los recursos
para los canales de notificaciones, que puedes recuperar si
enumeras los canales de notificaciones
en tu proyecto. Por ejemplo,
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568". - Opcional: ANALYSIS_INSTANCE_SCHEMA es el URI de Cloud Storage para el archivo de esquema que describe el formato de tus datos de entrada. Por ejemplo,
gs://test-bucket/schema.yaml.
Cuerpo JSON de la solicitud:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, }, }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] }, "analysisInstanceSchemaUri": ANALYSIS_INSTANCE_SCHEMA }Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }- PROJECT_ID: es el ID de tu proyecto de Google Cloud. Por
ejemplo,
Luego de que se crea el trabajo de supervisión, Model Monitoring registra las solicitudes de predicción entrantes en una tabla de BigQuery generada con el nombre PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Si el registro de solicitudes y respuestas está habilitado, Model Monitoring registra las solicitudes entrantes en la misma tabla de BigQuery que se usa para el registro de solicitudes y respuestas.
(Opcional) Configura alertas para el trabajo de Model Monitoring
Puedes supervisar y depurar tu trabajo de Model Monitoring mediante alertas. Model Monitoring te notifica automáticamente sobre las actualizaciones de trabajos a través de correo electrónico, pero también puedes configurar alertas a través de Cloud Logging y canales de notificaciones de Cloud Monitoring.
Para los siguientes eventos, Model Monitoring envía una notificación por correo electrónico a cada dirección de correo electrónico que especificaste cuando creaste el trabajo de Model Monitoring:
- Cada vez que se configura la detección de sesgo o desvío
- Cada vez que se actualiza una configuración de trabajo de Model Monitoring existente
- Cada vez que falla una ejecución de canalización de supervisión programada
Cloud Logging
Para habilitar los registros de las ejecuciones programadas de canalización de supervisión, establece el campo enableMonitoringPipelineLogs en tu configuración de modelDeploymentMonitoringJobs en true. Los registros de depuración se escriben en Cloud Logging cuando se configura el trabajo de supervisión y en cada intervalo de supervisión.
Los registros de depuración se escriben en Cloud Logging con el nombre de registro: model_monitoring. Por ejemplo:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring" resource.labels.model_deployment_monitoring_job=6680511704087920640
Aquí hay un ejemplo de una entrada de registro de progreso del trabajo:
{
"insertId": "e2032791-acb9-4d0f-ac73-89a38788ccf3@a1",
"jsonPayload": {
"@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringPipelineLogEntry",
"statusCode": {
"message": "Scheduled model monitoring pipeline finished successfully for job projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640"
},
"modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640"
},
"resource": {
"type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob",
"labels": {
"model_deployment_monitoring_job": "6680511704087920640",
"location": "us-central1",
"resource_container": "projects/677687165274"
}
},
"timestamp": "2022-02-04T15:33:54.778883Z",
"severity": "INFO",
"logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring",
"receiveTimestamp": "2022-02-04T15:33:56.343298321Z"
}
Canales de notificaciones
Cada vez que falla una ejecución de canalización de supervisión programada, Model Monitoring envía una notificación a los canales de notificaciones de Cloud Monitoring que especificaste cuando creaste el trabajo de Model Monitoring.
Configura alertas de anomalías en las funciones
Model Monitoring detecta una anomalía cuando se excede el umbral establecido para una función. Model Monitoring te notifica de forma automática sobre las anomalías detectadas por correo electrónico, pero también puedes configurar alertas a través de Cloud Logging y los canales de notificaciones de Cloud Monitoring.
En cada intervalo de supervisión, si el umbral de al menos una función excede el umbral, Model Monitoring envía una alerta por correo electrónico a cada dirección de correo electrónico que especificaste cuando creaste el trabajo de Model Monitoring. El mensaje de correo electrónico incluye lo siguiente:
- La hora en la que se ejecutó el trabajo de supervisión.
- El nombre del atributo que tiene sesgo o desvío.
- El umbral de alertas y la medición de distancia estadística registrada.
Cloud Logging
Para habilitar las alertas de Cloud Logging, configura el campo enableLogging de la configuración de ModelMonitoringAlertConfig como true.
En cada intervalo de supervisión, se escribe un registro de anomalías en Cloud Logging si la distribución de al menos una función supera el umbral de esa función. Puedes reenviar registros a cualquier servicio compatible con Cloud Logging, como Pub/Sub.
Las anomalías se escriben en Cloud Logging con el nombre de registro: model_monitoring_anomaly. Por ejemplo:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring_anomaly" resource.labels.model_deployment_monitoring_job=6680511704087920640
Este es un ejemplo de una entrada de registro de anomalías:
{
"insertId": "b0e9c0e9-0979-4aff-a5d3-4c0912469f9a@a1",
"jsonPayload": {
"anomalyObjective": "RAW_FEATURE_SKEW",
"endTime": "2022-02-03T19:00:00Z",
"featureAnomalies": [
{
"featureDisplayName": "age",
"deviation": 0.9,
"threshold": 0.7
},
{
"featureDisplayName": "education",
"deviation": 0.6,
"threshold": 0.3
}
],
"totalAnomaliesCount": 2,
"@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringAnomaliesLogEntry",
"startTime": "2022-02-03T18:00:00Z",
"modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640",
"deployedModelId": "1645828169292316672"
},
"resource": {
"type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob",
"labels": {
"model_deployment_monitoring_job": "6680511704087920640",
"location": "us-central1",
"resource_container": "projects/677687165274"
}
},
"timestamp": "2022-02-03T19:00:00Z",
"severity": "WARNING",
"logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring_anomaly",
"receiveTimestamp": "2022-02-03T19:59:52.121398388Z"
}
Canales de notificaciones
En cada intervalo de supervisión, si el umbral de al menos una función excede el umbral, Model Monitoring envía una alerta a los canales de notificaciones de Cloud Monitoring que especificaste cuando creaste el trabajo de Model Monitoring. La alerta incluye información sobre el trabajo de Model Monitoring que activó la alerta.
Actualiza un trabajo de Model Monitoring
Puedes ver, actualizar, pausar y borrar un trabajo de Model Monitoring. Debes pausar un trabajo para poder borrarlo.
Console
No se admiten las funciones de pausar y borrar en la consola de Google Cloud. Usa la CLI de gcloud en su lugar.
Para actualizar los parámetros de un trabajo de Model Monitoring, haz lo siguiente:
En la consola de Google Cloud, ve a la página Extremos de Vertex AI.
Haz clic en el nombre del extremo que deseas editar.
Haz clic en Editar la configuración.
En el panel Editar extremo, selecciona Objetivos de supervisión o Supervisión de modelos.
Actualiza los campos que deseas cambiar.
Haga clic en Update.
Para ver las métricas, las alertas y las propiedades de supervisión de un modelo, haz lo siguiente:
En la consola de Google Cloud, ve a la página Extremos de Vertex AI.
Haz clic en el nombre del extremo.
En la columna Monitoring del modelo que deseas ver, haz clic en Habilitado.
gcloud
Ejecuta el siguiente comando:
gcloud ai model-monitoring-jobs COMMAND MONITORING_JOB_ID \ --PARAMETER=VALUE --project=PROJECT_ID --region=LOCATION
Donde:
COMMAND es el comando que deseas ejecutar en el trabajo de supervisión. Por ejemplo:
update,pause,resumeodelete. Para obtener más información, consulta la referencia de la CLI de gcloud.MONITORING_JOB_ID es el ID de tu trabajo de supervisión. Por ejemplo,
123456789Para encontrar el ID, [recupera la información de extremo][retrieve-id] o consulta Propiedades de Monitoring para un modelo en la consola de Google Cloud. El ID se incluye en el nombre del recurso de trabajo de supervisión en el formatoprojects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_ID.(opcional) PARAMETER=VALUE es el parámetro que deseas actualizar. Esta marca solo es obligatoria cuando se usa el comando
update. Por ejemplo,monitoring-frequency=2. Para obtener una lista de los parámetros que puedes actualizar, consulta la referencia de gcloud CLI.PROJECT_ID es el ID de tu proyecto de Google Cloud. Por ejemplo,
my-project.LOCATION es la ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1.
API de REST
Pausa un trabajo
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_NUMBER: El número de tu proyecto de Google Cloud. Por ejemplo:
1234567890 - LOCATION: Ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1. - MONITORING_JOB_ID: ID de tu trabajo de supervisión. Por ejemplo:
0987654321
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{}
Borra un trabajo
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- PROJECT_NUMBER: El número de tu proyecto de Google Cloud. Por ejemplo:
my-project - LOCATION: Ubicación de tu trabajo de supervisión. Por ejemplo,
us-central1. - MONITORING_JOB_ID: ID de tu trabajo de supervisión. Por ejemplo:
0987654321
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/operations/MONITORING_JOB_ID",
...
"done": true,
...
}
Analiza datos de sesgo y desvío
Puedes usar la consola de Google Cloud para visualizar las distribuciones de cada atributo supervisado y conocer qué cambios generaron un sesgo o un desvío con el tiempo. Puedes ver las distribuciones de valores de atributos como un histograma.
Console
Para navegar a los histogramas de distribución de características en la consola de Google Cloud, ve a la página Extremos.
En la página Endpoints, haz clic en el extremo que deseas analizar.
En la página de detalles del extremo que seleccionaste, hay una lista de todos los modelos implementados en ese extremo. Haz clic en el nombre de un modelo para analizar.
La página de detalles del modelo enumera los atributos de entrada del modelo, junto con información pertinente, como el umbral de alertas para cada atributo y la cantidad de alertas anteriores del atributo.
Para analizar un atributo, haz clic en su nombre. En una página, se muestran los histogramas de distribución de atributos para ese atributo.
Para cada función supervisada, puedes ver las distribuciones de los 50 trabajos de supervisión más recientes en la consola de Google Cloud. Para la detección de sesgos, la distribución de los datos de entrenamiento se muestra justo al lado de la distribución de datos de entrada:
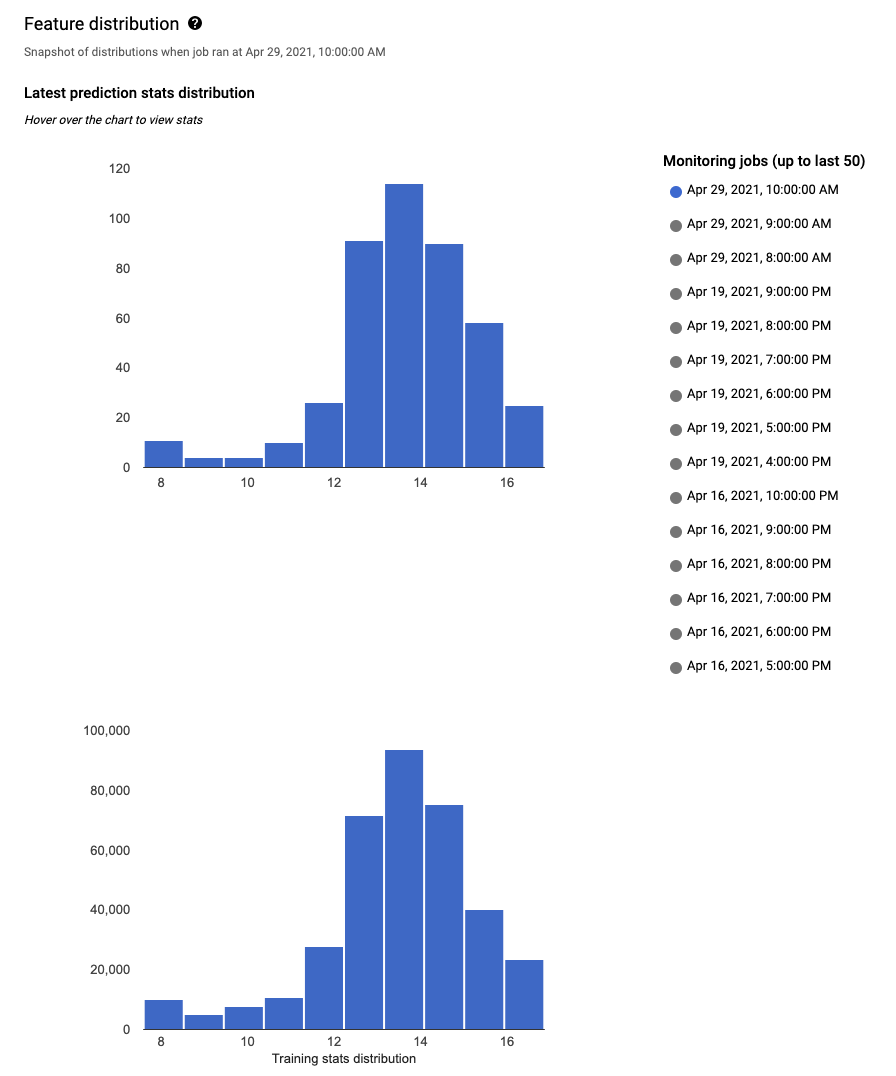
La visualización de la distribución de datos como histogramas te permite enfocarte con rapidez en los cambios que ocurrieron en los datos. Después, puedes decidir ajustar la canalización de generación de atributos o volver a entrenar el modelo.
¿Qué sigue?
- Trabaja con la supervisión de modelos según la documentación de la API.
- Trabaja con Model Monitoring según los documentos de la CLI de gcloud.
- Prueba la notebook de ejemplo en Colab o visualízala en GitHub.
- Obtén información sobre cómo Model Monitoring calcula el sesgo entre el entrenamiento y la entrega, y el desvío de predicción.