次の目標セクションには、データ要件、入出力スキーマ ファイル、スキーマが定義するデータ インポート ファイル(JSON Lines と CSV)の形式に関する情報が含まれています。
権限
Cloud Storage バケットのイメージを使用するには、バケットに対する Storage Object Viewer ロールを Vertex AI サービス エージェントに付与する必要があります。サービス エージェントは、Vertex AI がユーザーの代わりにデータにアクセスするために使用する Google マネージド サービス アカウントです。詳細については、サービス エージェントをご覧ください。
オブジェクト検出
データ要件
| 画像の一般的な要件 | |
|---|---|
| サポートされているファイル形式 |
|
| 画像の種類 | AutoML モデルは、現実世界にある物体の写真に対して最も効果的に動作します。 |
| トレーニング画像ファイルのサイズ(MB) | サイズ 30 MB 以下 |
| 予測画像ファイル* サイズ(MB) | サイズ 1.5 MB 以下 |
| 画像サイズ(ピクセル) | 推奨サイズ 1024 x 1024 ピクセル以下 1024 × 1024 ピクセルを大幅に超える画像の場合、Vertex AI の画像正規化処理で画質が低下する可能性があります。 |
| ラベルと境界ボックスの要件 | |
|---|---|
| 次の要件は、AutoML モデルのトレーニングに使用されるデータセットに適用されます。 | |
| トレーニング用のインスタンスにラベルを付ける | 10 個以上のアノテーション(インスタンス)。 |
| アノテーションの要件 | ラベルごとに、少なくとも 10 個の画像が必要です。また、それぞれの画像に 1 つ以上のアノテーション(境界ボックスとラベル)が必要です。 ただし、モデルのトレーニングでは、ラベルごとに約 1,000 個のアノテーションを使用することをおすすめします。一般に、ラベルあたりの画像が多いほど、モデルのパフォーマンスが向上します。 |
| ラベル比率(最も一般的なラベルから最も一般的でないラベルまで) | モデルは、最も一般的なラベルの画像数が、最も一般的でないラベルの画像数よりも最大で 100 倍存在する場合に最適に動作します。 モデルのパフォーマンスを向上させるため、頻度の非常に低いラベルを削除することをおすすめします。 |
| 境界ボックスの辺の長さ | 0.01 * 画像の一辺の長さ以上。たとえば、1,000 x 900 ピクセルの画像では、少なくとも 10 x 9 ピクセルの境界ボックスが必要です。 境界ボックスの最小サイズ: 8 x 8 ピクセル |
| AutoML またはカスタム トレーニング済みモデルのトレーニングに使用されるデータセットには、次の要件が適用されます。 | |
| 個別の画像の境界ボックス | 最大 500 |
| 予測リクエストから返される境界ボックス | 100(デフォルト)、最大 500 |
| トレーニング データとデータセットの要件 | |
|---|---|
| 次の要件は、AutoML モデルのトレーニングに使用されるデータセットに適用されます。 | |
| トレーニング画像の特徴 | トレーニング用のデータは、予測を行うデータにできる限り近いものである必要があります。 たとえば、ユースケースに低解像度のぼやけた画像(セキュリティ カメラの画像など)が含まれている場合、トレーニング用のデータも低解像度でぼやけた画像から構成する必要があります。一般に、複数の視点、解像度、背景を持つトレーニング画像を用意することも検討します。 一般的に、Vertex AI モデルは、人間が割り当てることができないラベルを予測することはできません。そのため、画像を 1~2 秒間見てラベルを割り当てるように人間をトレーニングすることができなければ、モデルもそのようにトレーニングすることはできません。 |
| 内部画像の前処理 | 画像がインポートされると、Vertex AI がデータの前処理を行います。前処理された画像は、モデルのトレーニングに使用される実際のデータです。 画像の前処理(サイズ変更)は、画像の小さい辺が 1,024 ピクセルよりも大きい場合に行われます。画像の小さい辺が 1,024 ピクセルより大きい場合、その辺は 1,024 ピクセルに縮小されます。大きい側と指定された境界ボックスはいずれも、小さい側と同じ割合で縮小されます。その結果、縮小されたアノテーション(境界ボックスとラベル)が 8 x 8 ピクセル未満の場合、このアノテーションは削除されます。 画像の小さい辺が 1,024 ピクセルより小さい場合、サイズ変更の前処理の影響はありません。 |
| AutoML またはカスタム トレーニング済みモデルのトレーニングに使用されるデータセットには、次の要件が適用されます。 | |
| 各データセット内の画像 | 最大 150,000 |
| 各データセット内のアノテーション付き境界ボックスの合計数 | 最大 1,000,000 |
| 各データセットのラベル数 | 最小 1、最大 1,000 |
YAML スキーマ ファイル
画像オブジェクト検出アノテーション(境界ボックスとラベル)をインポートするには、一般公開されている次のスキーマ ファイルを使用します。このスキーマ ファイルにより、データ入力ファイルの形式が決まります。このファイルの構造は OpenAPI スキーマに準拠しています。
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
完全なスキーマ ファイル
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
入力ファイル
JSON Lines
各行の JSON:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}フィールドに関する注意事項:
imageGcsUri- 必須フィールドです。annotationResourceLabels- 任意の数の Key-Value の文字列ペアを含めることができます。システム予約の Key-Value ペアは次のとおりです。- "aiplatform.googleapis.com/annotation_set_name" : "value"
value は、データセット内の既存のアノテーション セットの表示名の 1 つです。
dataItemResourceLabels- 任意の数の Key-Value の文字列ペアを含めることができます。システム予約の Key-Value ペアは次のとおりです。これにより、機械学習が使用するデータ項目のセットが指定されます。- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
JSON Lines の例 - object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
CSV 形式:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(省略可)。モデルをトレーニングする場合のデータ分割に使用します。TRAINING、TEST、または VALIDATION を使用します。手動データ分割の詳細については、AutoML モデルのデータ分割についてをご覧ください。GCS_FILE_PATH- このフィールドには、画像の Cloud Storage URI が含まれます。Cloud Storage URI では大文字と小文字が区別されます。LABEL- ラベルは文字で始まり、文字、数字、アンダースコア以外を含まないようにする必要があります。BOUNDING_BOX- 画像内のオブジェクトの境界ボックス。境界ボックスを指定する際は、複数の列を指定します。
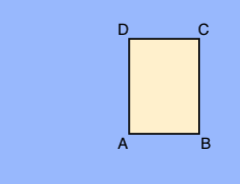
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAXそれぞれの頂点は、x と y の座標値で指定します。座標は、正規化された浮動小数点数 [0,1] です。0.0 は X_MIN または Y_MIN、1.0 は X_MAX または Y_MAX です。
たとえば、画像全体の境界ボックスは (0.0,0.0,,,1.0,1.0,,) または (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0) として表します。
オブジェクトの境界ボックスは、次のいずれかの方法で指定できます。
- 長方形の対角線上の 2 つの頂点(x と y の座標のセット)
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
この例の場合:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,, - 以下に示す 4 つの頂点をすべて指定します。
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
指定された 4 つの頂点では画像の縁に平行に沿う四角形が形成されない場合、Vertex AI は、このような四角形を形成する頂点を指定します。
- 長方形の対角線上の 2 つの頂点(x と y の座標のセット)
CSV の例 - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...