Os hosts locais podem acessar um endpoint de previsão on-line da Vertex AI pela Internet pública ou particular por uma arquitetura de rede híbrida que usa o Private Service Connect (PSC) pelo Cloud VPN ou Cloud Interconnect. As duas opções oferecem criptografia SSL/TLS. No entanto, a opção privada oferece um desempenho muito melhor e, portanto, é recomendada para aplicativos essenciais.
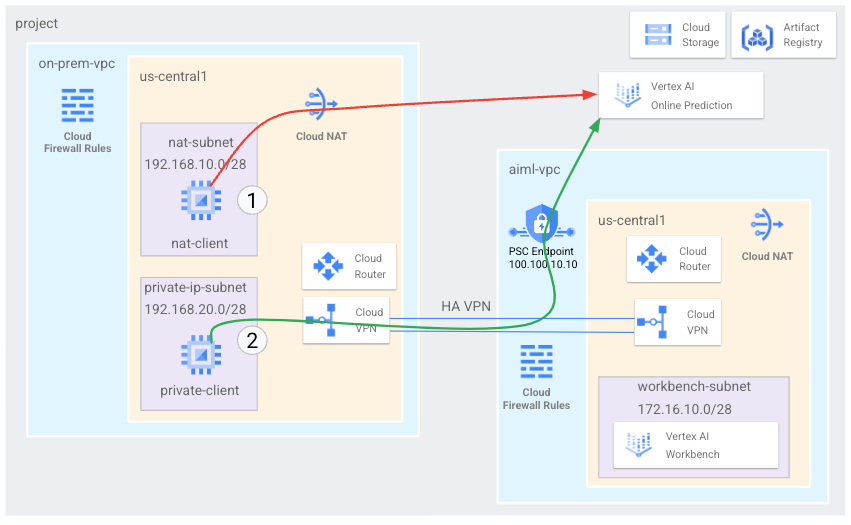
Neste tutorial, você usa a VPN de alta disponibilidade (VPN de alta disponibilidade) para acessar um endpoint de previsão on-line publicamente, por meio do Cloud NAT, e de modo particular, entre duas redes de nuvem privada virtual que podem servir como uma base para conectividade particular em várias nuvens e no local.
Este tutorial é destinado a administradores de redes empresariais, cientistas de dados e pesquisadores que estão familiarizados com a Vertex AI, a nuvem privada virtual (VPC), o console do Google Cloud e o Cloud Shell. Conhecer o Vertex AI Workbench é útil, mas não é obrigatório.
Objetivos
- Criar duas redes de nuvem privada virtual (VPC), conforme mostrado no diagrama
anterior:
- Uma (
on-prem-vpc) representa uma rede local. - A outra (
aiml-vpc) é para criar e implantar um modelo de previsão on-line da Vertex AI.
- Uma (
- Implante gateways de VPN de alta disponibilidade, túneis do Cloud VPN e
Cloud Routers para conectar
aiml-vpceon-prem-vpc. - Criar e implantar um modelo de previsão on-line da Vertex AI.
- Crie um endpoint do Private Service Connect (PSC) para encaminhar solicitações de previsão on-line particulares para o modelo implantado.
- Ative o modo de divulgação personalizada do Cloud Router em
aiml-vpcpara anunciar rotas do endpoint do Private Service Connect paraon-prem-vpc. - Crie duas instâncias de VM do Compute Engine em
on-prem-vpcpara representar aplicativos clientes:- Uma (
nat-client) envia solicitações de previsão on-line pela Internet pública (por meio do Cloud NAT). Esse método de acesso é indicado por uma seta vermelha e o número 1 no diagrama. - A outra (
private-client) envia solicitações de previsão de maneira privada pela VPN de alta disponibilidade. Esse método de acesso é indicado por uma seta verde e o número 2.
- Uma (
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na sua projeção de uso,
use a calculadora de preços.
Ao concluir as tarefas descritas neste documento, é possível evitar o faturamento contínuo excluindo os recursos criados. Saiba mais em Limpeza.
Antes de começar
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Abra o Cloud Shell para executar os comandos listados neste tutorial. O Cloud Shell é um ambiente shell interativo para o Google Cloud que permite gerenciar projetos e recursos a partir do navegador da Web.
- No Cloud Shell, defina o projeto atual como o
ID do projeto Google Cloud e armazene o mesmo
ID do projeto na variável de shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
Crie as redes VPC
Nesta seção, você criará duas redes VPC: uma para gerar um modelo de previsão on-line e implantá-lo em um endpoint e a outra para acesso particular a esse endpoint. Em cada uma das duas redes VPC, você cria um Cloud Router e um gateway do Cloud NAT. Um gateway do Cloud NAT fornece conectividade de saída para instâncias de máquina virtual (VM) do Compute Engine sem endereços IP externos.
Criar a rede VPC do endpoint de previsão on-line (aiml-vpc)
Crie a rede VPC:
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=customCrie uma sub-rede chamada
workbench-subnet, com um intervalo IPv4 principal de172.16.10.0/28:gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrie um Cloud Router regional chamado
cloud-router-us-central1-aiml-nat:gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1Adicione um gateway do Cloud NAT ao Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Criar a rede VPC "local" (on-prem-vpc)
Crie a rede VPC:
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=customCrie uma sub-rede chamada
nat-subnet, com um intervalo IPv4 principal de192.168.10.0/28:gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1Crie uma sub-rede chamada
private-ip-subnet, com um intervalo IPv4 principal de192.168.20.0/28:gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1Crie um Cloud Router regional chamado
cloud-router-us-central1-on-prem-nat:gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1Adicione um gateway do Cloud NAT ao Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Criar o endpoint do Private Service Connect (PSC)
Nesta seção, você cria o endpoint do Private Service Connect (PSC)
que as instâncias de VM na rede on-prem-vpc usam para acessar o
endpoint de previsão on-line por meio da API Vertex AI.
O endpoint do Private Service Connect (PSC) é um endereço IP interno na rede on-prem-vpc que pode ser acessado diretamente pelos clientes
nessa rede. Esse endpoint é criado com a implantação de uma regra de encaminhamento
que direciona o tráfego de rede correspondente ao endereço IP do endpoint do PSC
para um pacote de APIs do Google.
O endereço IP do endpoint
do PSC (100.100.10.10) será anunciado no
aiml-cr-us-central1 Cloud Router como uma divulgação de roteador personalizada para a
rede on-prem-vpc em uma etapa posterior.
Reserve endereços IP para o endpoint do PSC:
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpcCrie o endpoint do PSC:
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apisListe os endpoints do PSC configurados e verifique se o endpoint
pscvertexfoi criado:gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --globalEncontre os detalhes do endpoint do PSC configurado e verifique se o endereço IP é
100.100.10.10:gcloud compute forwarding-rules describe pscvertex \ --global
Configurar conectividade híbrida
Nesta seção, você cria dois gateways (VPN de alta disponibilidade) conectados entre si. Cada gateway contém um Cloud Router e um par de túneis VPN.
Crie o gateway de VPN de alta disponibilidade para a rede VPC
aiml-vpc:gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1Crie o gateway de VPN de alta disponibilidade para a rede VPC
on-prem-vpc:gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1No Console do Google Cloud, acesse a página VPN.
Na página VPN, clique na guia Gateways do Cloud VPN.
Na lista de gateways do VPN, verifique se há dois gateways e se cada um tem dois endereços IP.
No Cloud Shell, crie um Cloud Router para a rede
aiml-vpcde nuvem privada virtual:gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001Crie um Cloud Router para a rede de nuvem privada virtual
on-prem-vpc:gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
Crie os túneis VPN para aiml-vpc
Crie um túnel VPN chamado
aiml-vpc-tunnel0:gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0Crie um túnel VPN chamado
aiml-vpc-tunnel1:gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
Crie os túneis VPN para on-prem-vpc
Crie um túnel VPN chamado
on-prem-vpc-tunnel0:gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0Crie um túnel VPN chamado
on-prem-vpc-tunnel1:gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1No Console do Google Cloud, acesse a página VPN.
Na página VPN, clique na guia Túneis do Cloud VPN.
Na lista de túneis de VPN, verifique se quatro túneis de VPN foram estabelecidos.
Criar sessões do BGP
O Cloud Router usa o protocolo de gateway de borda (BGP) para trocar rotas entre
sua rede VPC (neste caso, aiml-vpc) e sua
rede local (representada por on-prem-vpc). No Cloud Router,
você configura uma interface e um peering do BGP para seu roteador local.
A interface e a configuração de peering do BGP formam uma sessão do BGP.
Nesta seção, você cria duas sessões do BGP para aiml-vpc e duas para on-prem-vpc.
Estabeleça sessões do BGP para aiml-vpc
No Cloud Shell, crie a primeira interface do BGP:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1Crie o primeiro peering do BGP:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1Criar a segunda interface do BGP:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central1Crie o segundo peering do
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
Estabeleça sessões do BGP para on-prem-vpc
Crie a primeira interface do BGP:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1Crie o primeiro peering do BGP:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1Criar a segunda interface do BGP:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central1Crie o segundo peering do
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
Valide a criação da sessão do BGP
No Console do Google Cloud, acesse a página VPN.
Na página VPN, clique na guia Túneis do Cloud VPN.
Na lista de túneis VPN, agora você notará que o valor na coluna Status da sessão do BGP para cada um dos quatro túneis mudou de Configurar sessão do BGP para BGP estabelecido. Talvez seja necessário atualizar a guia do navegador do Google Cloud console para conferir os novos valores.
Verifique se aiml-vpc aprendeu as rotas de sub-rede pela VPN de alta disponibilidade
No Console do Google Cloud, acesse a página Redes VPC.
Na lista de redes VPC, clique em
aiml-vpc.Clique na guia Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Visualizar.
Na coluna Intervalo de IP de destino, verifique se a rede VPC
aiml-vpcaprendeu rotas das sub-redesnat-subnet(192.168.10.0/28) eprivate-ip-subnet(192.168.20.0/28) das redes VPCon-prem-vpc.
Verifique se on-prem-vpc aprendeu as rotas de sub-rede pela VPN de alta disponibilidade
No Console do Google Cloud, acesse a página Redes VPC.
Na lista de redes VPC, clique em
on-prem-vpc.Clique na guia Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Visualizar.
Na coluna Intervalo de IP de destino, verifique se a rede VPC
on-prem-vpcaprendeu rotas da sub-redeworkbench-subnet(172.16.10.0/28) das redes VPCaiml-vpc.
Criar uma rota divulgada personalizada para aiml-vpc
O endereço IP do endpoint do Private Service Connect não é divulgado automaticamente
pelo Cloud Router aiml-cr-us-central1 porque a sub-rede
não está configurada na rede VPC.
Portanto, você precisará criar uma rota divulgada personalizada do Cloud Router aiml-cr-us-central para o endereço IP 100.100.10.10 do endpoint que é anunciado para o ambiente local por meio do BGP para o on-prem-vpc.
No console do Google Cloud, acesse a página do Cloud Routers.
Na lista de Cloud Routers, clique em
aiml-cr-us-central1.Na página Detalhes do Router, clique em Editar.
Na seção Rotas divulgadas, para Rotas, selecione Criar rotas personalizadas.
Clique em Adicionar uma rota personalizada.
Em Origem, selecione Intervalo de IP personalizado.
Em Intervalo de endereços IP, insira
100.100.10.10.Em Descrição, insira
Private Service Connect Endpoint IP.Clique em Concluído e depois em Salvar.
Verifique se on-prem-vpc aprendeu o endereço IP do endpoint do PSC pela VPN de alta disponibilidade.
No Console do Google Cloud, acesse a página Redes VPC.
Na lista de redes VPC, clique em
on-prem-vpc.Clique na guia Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Visualizar.
Na coluna Intervalo de IP de destino, verifique se a rede VPC
on-prem-vpcaprendeu o endereço IP do endpoint do PSC (100.100.10.10).
Criar uma rota divulgada personalizada para on-prem-vpc
O Cloud Router on-prem-vpc divulga todas as sub-redes por padrão, mas apenas a sub-rede private-ip-subnet é necessária.
Na seção a seguir, atualize as divulgações de rota do Cloud Router on-prem-cr-us-central1.
No Console do Google Cloud, acesse a página do Cloud Routers.
Na lista de Cloud Routers, clique em
on-prem-cr-us-central1.Na página Detalhes do Router, clique em Editar.
Na seção Rotas divulgadas, para Rotas, selecione Criar rotas personalizadas.
Se a caixa de seleção Divulgar todas as sub-redes visíveis para o Cloud Router estiver marcada, desmarque-a.
Clique em Adicionar uma rota personalizada.
Em Origem, selecione Intervalo de IP personalizado.
Em Intervalo de endereços IP, insira
192.168.20.0/28.Em Descrição, insira
Private Service Connect Endpoint IP subnet (private-ip-subnet).Clique em Concluído e depois em Salvar.
Confirme se aiml-vpc aprendeu a rota private-ip-subnet de on-prem-vpc.
No Console do Google Cloud, acesse a página Redes VPC.
Na lista de redes VPC, clique em
aiml-vpc.Clique na guia Rotas.
Selecione us-central1 (Iowa) na lista Região e clique em Visualizar.
Na coluna Intervalo de IP de destino, verifique se a rede VPC
aiml-vpcaprendeu a rotaprivate-ip-subnet(192.168.20.0/28).
Criar as instâncias de VM de teste
Crie uma conta de serviço gerenciada pelo usuário
Se você tiver aplicativos que precisam chamar APIs Google Cloud , o Google recomenda anexar uma conta de serviço gerenciada pelo usuário à VM em que o aplicativo ou a carga de trabalho está sendo executado. Assim, nesta seção, você criará uma conta de serviço gerenciada pelo usuário para ser aplicada às instâncias de VM criadas posteriormente neste tutorial.
No Cloud Shell, crie a conta de serviço:
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"Atribua o papel do IAM Administrador da instância da computação (v1) (
roles/compute.instanceAdmin.v1) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"Atribua o papel do IAM de usuário da Vertex AI (
roles/aiplatform.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
Criar as instâncias de VM de teste
Nesta etapa, você cria instâncias de VM de teste para validar diferentes métodos e acessar as APIs da Vertex AI, especificamente:
- A instância
nat-clientusa o Cloud NAT para resolver a Vertex AI e acessar o endpoint de previsão on-line pela Internet pública. - A instância
private-clientusa o endereço IP100.100.10.10do Private Service Connect para acessar o endpoint de previsão on-line pela VPN de alta disponibilidade.
Para permitir que o Identity-Aware Proxy (IAP) se conecte às instâncias de VM, crie uma regra de firewall que:
- Se aplica a todas as instâncias de VM que você quer tornar acessíveis por meio do IAP.
- Permite o tráfego TCP pela porta 22 do intervalo de IP
35.235.240.0/20. Esse intervalo contém todos os endereços IP que o IAP usa para o encaminhamento de TCP.
Crie a instância de VM
nat-client:gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crie a instância de VM
private-client:gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crie a regra de firewall do IAP:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
crie uma instância do Vertex AI Workbench
Criar uma conta de serviço gerenciada pelo usuário para o Vertex AI Workbench
Quando você cria uma instância do Vertex AI Workbench, o Google recomenda que você especifique uma conta de serviço gerenciada pelo usuário em vez de usar a conta de serviço padrão do Compute Engine.
Caso sua organização não aplique a
iam.automaticIamGrantsForDefaultServiceAccounts,
a restrição da política da organização, a conta de serviço padrão do Compute Engine
(e, portanto, qualquer pessoa que você especificar
como usuário da instância) receberá o papel de Editor (roles/editor) no seu
projetoGoogle Cloud . Para desativar esse comportamento, consulte
Desativar concessões automáticas de papéis para contas de serviço padrão.
No Cloud Shell, crie uma conta de serviço chamada
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Atribua o papel do IAM Administrador de armazenamento (
roles/storage.admin) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Atribua o papel do IAM de usuário da Vertex AI (
roles/aiplatform.user) à conta de serviço:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Atribua o papel do IAM Administrador do Artifact Registry à conta de serviço:
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
Criar a instância do Vertex AI Workbench
No Cloud Shell, crie uma instância do Vertex AI Workbench, especificando a conta de serviço
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
Crie e implante um modelo de previsão on-line
Prepare o ambiente
No console do Google Cloud, acesse a guia Instâncias na página do Vertex AI Workbench.
Ao lado do nome da instância do Vertex AI Workbench (
workbench-tutorial), clique em Abrir JupyterLab.Sua instância do Vertex AI Workbench abre o JupyterLab.
No restante desta seção, até a implantação do modelo, você vai trabalhar no Jupyterlab, e não no console do Google Cloud ou no Cloud Shell.
Selecione Arquivo > Novo > Terminal.
No terminal JupyterLab (não no Cloud Shell), defina uma variável de ambiente para o projeto. Substitua PROJECT_ID pelo código do projeto:
PROJECT_ID=PROJECT_IDCrie um novo diretório chamado
cpr-codelabecdnele (ainda no terminal JupyterLab):mkdir cpr-codelab cd cpr-codelabNo Navegador de arquivos , clique duas vezes na nova pasta
cpr-codelab.Se essa pasta não aparecer no navegador de arquivos, atualize a guia do navegador do console Google Cloud e tente novamente.
Selecione File -> New -> Notebook.
No menu Selecionar kernel, selecione Python [conda env:base] * (Local) e clique em Selecionar.
Renomeie o novo arquivo de notebook da seguinte maneira:
No Navegador de arquivos , clique com o botão direito do mouse no ícone do arquivo
Untitled.ipynbe insiratask.ipynb.Seu diretório
cpr-codelabdeverá ficar assim:+ cpr-codelab/ + task.ipynbNas etapas a seguir, você cria seu modelo no notebook do Jupyterlab criando novas células do notebook, colando código nelas e executando as células.
Instale as dependências da seguinte maneira.
Ao abrir o novo notebook, você encontrará uma célula de código padrão em que é possível inserir o código. Ela tem o formato
[ ]:, seguido por um campo de texto. Esse campo de texto é onde você cola seu código.Cole o código a seguir na célula e clique em Executar as células selecionadas e avançar para criar um arquivo
requirements.txta ser usado como entrada para a etapa a seguir:%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2Nesta etapa e em cada uma das seguintes, adicione uma célula de código clicando em Inserir uma célula abaixo, cole o código na célula e clique em Executar as células selecionadas e avançar.
Use
Pippara instalar dependências na instância dos notebooks:!pip install -U --user -r requirements.txtQuando a instalação estiver concluída, selecione Kernel -> Reiniciar kernel para reiniciar o kernel e garantir que a biblioteca esteja disponível para importação.
Cole o seguinte código em uma nova célula do notebook para criar os diretórios em que serão armazenados os artefatos de pré-processamento e modelo:
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
No Navegador de arquivos , sua estrutura de diretórios
cpr-codelabficará assim:+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
Treine o modelo
Continue adicionando células de código ao notebook task.ipynb. Depois, cole e execute o seguinte código em cada célula nova:
Importe as bibliotecas:
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)Defina as variáveis abaixo, substituindo PROJECT_ID pelo ID do projeto:
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"Crie um bucket do Cloud Storage:
!gcloud storage buckets create $BUCKET_NAME --location=us-central1Carregue os dados da biblioteca do Seaborn e crie dois data frames, um com os atributos e outro com o rótulo:
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])Analise os dados de treinamento e verifique se cada linha representa um diamante.
x_train.head()Confira os rótulos, que são os preços correspondentes.
y_train.head()Defina uma transformação de coluna do sklearn para codificar em one-hot os atributos categóricos e escalonar os recursos numéricos:
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))Defina o modelo de floresta aleatória:
regr = RandomForestRegressor(max_depth=10, random_state=0)Crie um pipeline sklearn. Esse pipeline usa os dados de entrada, os codifica e escalona e os transmite para o modelo.
my_pipeline = make_pipeline(column_transform, regr)Treinar o modelo:
my_pipeline.fit(x_train, y_train)Chame o método de previsão no modelo, transmitindo um exemplo de teste.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])Talvez apareçam avisos como
"X does not have valid feature names, but", mas você pode ignorá-los.Salve o pipeline no diretório
model_artifactse o copie para o bucket do Cloud Storage:joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Salve um artefato de pré-processamento
Crie um artefato de pré-processamento. Esse artefato será carregado no contêiner personalizado quando o servidor de modelo for iniciado. O artefato de pré-processamento pode ter quase qualquer forma (como um arquivo Pickle), mas nesse caso você gravará um dicionário em um arquivo JSON:
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
Crie um contêiner de veiculação personalizado usando o servidor do modelo de CPR
O recurso
claritynos nossos dados de treinamento sempre estava na forma abreviada (ou seja, "FL" em vez de "Flawless"). No momento da disponibilização, queremos verificar se os dados desse atributo também são abreviados. Isso ocorre porque nosso modelo sabe como fazer uma codificação one-hot "FL", mas não "Flawless". Você escreverá essa lógica de pré-processamento personalizada mais tarde. Mas, por enquanto, salve essa tabela de consulta em um arquivo JSON e, em seguida, grave-a no seu bucket do Cloud Storage:import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/No Navegador de arquivos , sua estrutura de diretórios ficará assim:
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynbNo notebook, cole e execute o código a seguir para criar uma subclasse do
SklearnPredictore gravá-la em um arquivo Python emsrc_dir/. Neste exemplo, estamos apenas personalizando os métodos de carregamento, pré-processamento e pós-processamento, e não o método de previsão.%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}Use o SDK da Vertex AI para Python para criar a imagem usando rotinas de previsão personalizadas. O Dockerfile é gerado e uma imagem é criada para você.
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )Escreva um arquivo de teste com dois exemplos para previsão. Uma das instâncias tem o nome abreviado, mas a outra precisa ser convertida primeiro.
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)Teste o contêiner localmente implantando um modelo local.
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()Para conferir os resultados da previsão, use:
predict_response.contentA saída será assim:
b'{"predictions": ["$479.0", "$586.0"]}'
Implante o modelo no endpoint do modelo de previsão on-line
Agora que você testou o contêiner localmente, é hora de enviar a imagem para o Artifact Registry e fazer upload do modelo para o Vertex AI Model Registry.
Configure o Docker para acessar o Artifact Registry.
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quietEnvie a imagem.
local_model.push_image()Faça o upload do modelo.
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)Implante o modelo:
endpoint = model.deploy(machine_type="n1-standard-2")Aguarde até que seu modelo seja implantado antes de prosseguir para a próxima etapa. Isso deve levar de 10 a 15 minutos.
Para testar o modelo implantado, receba uma previsão:
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])A saída será assim:
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
Valide o acesso à Internet pública nas APIs Vertex AI
Nesta seção, você faz login na instância da VM nat-client
em uma guia de sessão do Cloud Shell e usa outra
guia de sessão para validar a conectividade com as APIs da Vertex AI
executando comandos dig e tcpdump no domínio
us-central1-aiplatform.googleapis.com.
No Cloud Shell (guia um), execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Faça login na instância de VM
nat-clientusando o IAP:gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapExecute o comando
dig:dig us-central1-aiplatform.googleapis.comNa VM
nat-client(guia um), execute o comando a seguir para validar a resolução de DNS quando enviar uma solicitação de previsão on-line para o endpoint.sudo tcpdump -i any port 53 -nAbra uma nova sessão do Cloud Shell (guia dois) clicando em abrir uma nova guia no Cloud Shell.
Na nova sessão do Cloud Shell (guia dois), execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Faça login na instância de VM
nat-client:gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"Na VM
nat-client(guia dois), use um editor de texto comovimounanopara criar um arquivoinstances.json. É necessário adicionar ao iníciosudopara ter permissão de gravação no arquivo, por exemplo:sudo vim instances.jsonAdicione a seguinte string de dados ao arquivo:
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Salve o arquivo da seguinte maneira:
- Se você estiver usando
vim, pressione a teclaEsce, em seguida, digite:wqpara salvar o arquivo e sair. - Se você estiver usando
nano, digiteControl+Oe pressioneEnterpara salvar o arquivo. Em seguida, digiteControl+Xpara sair.
- Se você estiver usando
Localize o ID do endpoint de previsão on-line do endpoint do PSC:
No console do Google Cloud, na seção da Vertex AI, acesse a guia Endpoints na página Previsão on-line.
Encontre a linha do endpoint que você criou, chamada
diamonds-cpr_endpoint.Localize e copie o ID do endpoint de 19 dígitos na coluna ID.
No Cloud Shell, na VM
nat-client(guia dois), execute os comandos a seguir, substituindo PROJECT_ID pelo ID do projeto e ENDPOINT_ID pelo ID do endpoint do PSC:projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_IDNa VM
nat-client(guia dois), execute o seguinte comando para enviar uma solicitação de previsão on-line:curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
Agora que você executou a previsão, notará que os resultados de tcpdump
(guia um) mostram a instância de VM nat-client (192.168.10.2) executando uma
consulta do Cloud DNS para o servidor DNS local (169.254.169.254) para o
domínio da API da Vertex AI (us-central1-aiplatform.googleapis.com).
A consulta DNS retorna endereços IP virtuais (VIPs) públicos para
APIs da Vertex AI.
Valide o acesso privado às APIs Vertex AI
Nesta seção, você faz login na instância de VM private-client usando
o Identity-Aware Proxy em uma nova sessão do Cloud Shell (guia três)
e valida a
conectividade com as APIs da Vertex AI executando o comando dig no domínio da
Vertex AI (us-central1-aiplatform.googleapis.com).
Abra uma nova sessão do Cloud Shell (guia três) clicando em abrir nova guia no Cloud Shell. Esta é a guia três.
Na nova sessão do Cloud Shell (guia três), execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Faça login na instância de VM
private-clientusando o IAP:gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapExecute o comando
dig:dig us-central1-aiplatform.googleapis.comNa instância de VM
private-client(guia três), use um editor de texto comovimounanopara adicionar a seguinte linha ao arquivo/etc/hosts:100.100.10.10 us-central1-aiplatform.googleapis.comEssa linha atribui o endereço IP do endpoint do PSC (
100.100.10.10) ao nome de domínio totalmente qualificado para a API da Vertex AI do Google (us-central1-aiplatform.googleapis.com). O arquivo editado deve ter esta aparência:127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleNa VM
private-client(guia três), dê um ping no endpoint da Vertex AI eControl+Cpara sair quando você visualizar a saída:ping us-central1-aiplatform.googleapis.comO comando
pingretorna a seguinte saída com o endereço IP de endpoint do PSC:PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.Na VM
private-client(guia três), usetcpdumppara executar o comando a seguir para validar a resolução de DNS e o caminho de dados IP ao enviar uma solicitação de previsão on-line para o endpoint:sudo tcpdump -i any port 53 -n or host 100.100.10.10Abra uma nova sessão do Cloud Shell (guia quatro) clicando em abrir uma nova guia no Cloud Shell.
Na nova sessão do Cloud Shell (guia quatro), execute os seguintes comandos, substituindo PROJECT_ID pelo ID do projeto:
projectid=PROJECT_ID gcloud config set project ${projectid}Na guia quatro, faça login na instância
private-client:gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"Na VM
private-client(guia quatro), usando um editor de texto comovimounano, crie um arquivoinstances.jsoncontendo a seguinte string de dados:{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Na VM
private-client(guia quatro), execute os seguintes comandos, substituindo PROJECT_ID pelo nome do projeto e ENDPOINT_ID pelo ID do endpoint do PSC:projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_IDNa VM
private-client(guia quatro), execute o seguinte comando para enviar uma solicitação de previsão on-line:curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.jsonNa VM
private-clientno Cloud Shell (guia três), verifique se o endereço IP do endpoint do PSC (100.100.10.10) foi usado para acessar as APIs da Vertex AI.No terminal
tcpdumpdeprivate-clientna guia três do Cloud Shell, é possível notar que uma busca DNS paraus-central1-aiplatform.googleapis.comnão é necessária, porque a linha adicionada ao arquivo/etc/hoststem precedência e o endereço IP do PSC100.100.10.10é usado no caminho de dados.
Limpar
Para evitar cobranças na sua Google Cloud conta pelos recursos usados neste tutorial, exclua o projeto que contém os recursos ou mantenha o projeto e exclua os recursos individuais.
É possível excluir os recursos individuais no projeto da seguinte maneira:
Exclua a instância do Vertex AI Workbench da seguinte maneira:
No console do Google Cloud, na seção Vertex AI, acesse a guia Instâncias na página Workbench.
Selecione a instância
workbench-tutorialdo Vertex AI Workbench e clique em Excluir.
Exclua a imagem do contêiner da seguinte maneira:
No console do Google Cloud, acesse a página do Artifact Registry.
Selecione o contêiner do Docker
diamondse clique em Excluir.
Exclua o bucket de armazenamento da seguinte maneira:
No Console do Google Cloud, acesse a página Cloud Storage.
Selecione o bucket de armazenamento e clique em Excluir.
Cancele a implantação do modelo do endpoint da seguinte maneira:
No console do Google Cloud, na seção Vertex AI, acesse a página Endpoints.
Clique em
diamonds-cpr_endpointpara acessar a página de detalhes do endpoint.Na linha do seu modelo,
diamonds-cpr, clique em Cancelar a implantação do modelo .Na caixa de diálogo Cancelar a implantação do modelo do endpoint, clique em Cancelar a implantação.
Exclua o modelo da seguinte maneira:
No console do Google Cloud, na seção Vertex AI, acesse a página Model Registry.
Selecione o modelo
diamonds-cpr.Para excluir o modelo, clique em Ações e, em seguida, em Excluir modelo.
Exclua o endpoint de previsão on-line da seguinte maneira:
No console do Google Cloud, na seção Vertex AI, acesse a página Previsão on-line.
Selecione o endpoint
diamonds-cpr_endpoint.Para excluir o endpoint, clique em Ações e, em seguida, clique em Excluir endpoint.
No Cloud Shell, exclua os recursos restantes executando os comandos a seguir.
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
A seguir
- Conheça as opções de rede empresarial para acessar endpoints e serviços da Vertex AI.
- Saiba como o Private Service Connect funciona e por que ele oferece benefícios significativos de desempenho.
- Saiba como usar o VPC Service Controls para criar perímetros seguros para permitir ou negar acesso à Vertex AI e a outras APIs do Google no endpoint de previsão on-line.
- Saiba como e por que
usar uma zona de encaminhamento de DNS
em vez de atualizar o arquivo
/etc/hostsem ambientes de grande escala e de produção.