Para buscar dados de recursos no treinamento do modelo, use a disponibilização em lote. Se precisar exportar valores de recursos para arquivamento ou análise ad hoc, exporte valores de atributos.
Buscar valores de atributos para o treinamento do modelo
Para o treinamento de modelo, você precisa de um conjunto de dados de treinamento que contenha exemplos da tarefa de previsão. Esses exemplos consistem em instâncias que incluem os recursos e rótulos. A instância é sobre o que você quer fazer uma previsão. Por exemplo, uma instância pode ser uma casa, e você quer determinar o valor de mercado dela. Os recursos podem incluir a localização, a idade e o preço médio de casas próximas que foram vendidas recentemente. Um rótulo é uma resposta para a tarefa de previsão, como a casa vendida por US $100 mil.
Como cada rótulo é uma observação em um momento específico, é preciso buscar valores de atributos correspondentes a esse momento em que a observação foi feita, como os preços de casas vizinhas quando uma casa específica foi vendida. labels medida que os valores de rótulos e recursos são coletados ao longo do tempo, eles são alterados. O Vertex AI Feature Store pode executar uma pesquisa pontual para que você possa buscar os valores dos recursos em um horário específico.
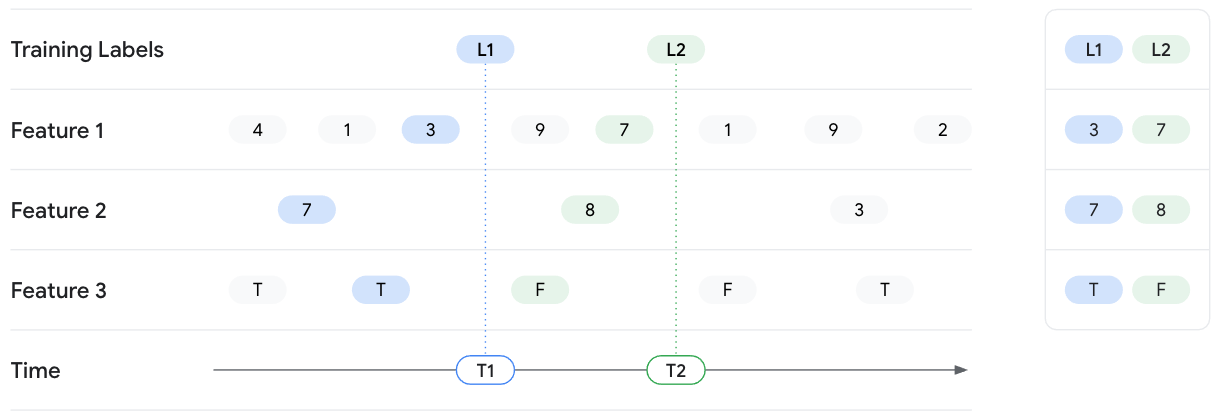
Exemplo de pesquisa pontual
O exemplo a seguir envolve a recuperação de valores de atributos para duas instâncias de
treinamento com os rótulos L1 e L2. Os dois rótulos são observados em T1 e
T2, respectivamente. Imagine congelar o estado dos valores do recurso nesses
carimbos de data/hora. Portanto, para a pesquisa do momento T1,
o Feature Store da Vertex AI retorna os valores de atributo mais recentes até o momento T1
para Feature 1, Feature 2 e Feature 3 e não vaza valores para além de
T1. Com o passar do tempo, os valores do atributo mudam e o rótulo também. Então, em T2, a Feature Store
retorna valores de recurso diferentes para esse momento.
Entradas de veiculação em lote
Como parte de uma solicitação de exibição em lote, as seguintes informações são necessárias:
- Uma lista de atributos atuais para os quais você vai receber valores.
- Uma lista de instâncias de leitura que contém informações para cada exemplo de treinamento.
Ela lista observações em um determinado momento. Pode ser um arquivo CSV ou uma tabela do BigQuery. A lista precisa incluir as seguintes informações:
- Carimbos de data/hora: os horários em que os rótulos foram observados ou medidos. Os carimbos de data/hora são obrigatórios para que o Vertex AI Feature Store possa executar uma pesquisa pontual.
- Códigos de entidade: um ou mais códigos das entidades que correspondem ao rótulo.
- O URI e o formato de destino em que a saída é gravada. Na saída,
o Vertex AI Feature Store basicamente junta a tabela da lista de instâncias
de leitura e os valores de recurso do featurestore. Especifique um dos formatos e locais a seguir para a saída:
- Tabela do BigQuery em um conjunto de dados regional ou multirregional.
- arquivo CSV em um bucket regional ou multirregional do Cloud Storage. No entanto, se os valores dos recursos incluírem matrizes, será necessário escolher outro formato.
- Tfrecord em um bucket do Cloud Storage
Requisitos de região
Para instâncias de leitura e destino, o conjunto de dados ou o intervalo de origem precisa estar na mesma região ou no mesmo local multirregional que o seu featurestore. Por exemplo, um featurestore em
us-central1 só pode ler ou exibir dados para buckets do Cloud Storage
ou conjuntos de dados do BigQuery que estejam em us-central1 ou no local multirregional
dos EUA. Não é possível ingerir dados de, por exemplo, us-east1. Além disso,
não há suporte para a leitura ou a exibição de dados usando buckets birregionais.
Lista de instâncias de leitura
A lista de instâncias de leitura especifica as entidades e os carimbos de data/hora dos valores de recursos que você quer recuperar. O arquivo CSV ou a tabela do BigQuery precisa conter as colunas a seguir, em qualquer ordem. Cada coluna requer um cabeçalho de coluna.
- É preciso incluir uma coluna de carimbo de data/hora em que o nome do cabeçalho é
timestampe os valores da coluna são carimbos de data/hora no formato RFC 3339. - É necessário incluir uma ou mais colunas de tipo de entidade, em que o cabeçalho é o código do tipo de entidade e os valores da coluna são os códigos da entidade.
- Opcional: é possível incluir valores de passagem (colunas adicionais), que são transmitidos como estão para a saída. Isso é útil se você tem dados que não estão no Feature Store da Vertex AI, mas quer incluir esses dados na saída.
Exemplo (CSV)
Imagine um featurestore que contenha os tipos de entidade users e movies, além dos recursos. Por exemplo, os recursos do users podem incluir age e
gender, enquanto os recursos para movies podem incluir ratings e genre.
Neste exemplo, você quer coletar dados de treinamento sobre as preferências de filme dos usuários. Você recupera os valores dos recursos das duas entidades do usuário alice e
bob, além dos recursos dos filmes que eles assistiram. Em um conjunto de dados separado, você sabe que alice assistiu a movie_01 e gostou dele. bob assistiu movie_02
e não gostou. Assim, a lista de instâncias de leitura pode se parecer com o seguinte exemplo:
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
O Vertex AI Feature Store recupera valores de recursos para as entidades listadas nos carimbos de data/hora ou antes deles. Especifique os recursos específicos a serem exportados como parte da solicitação de disponibilização em lote, não na lista de instâncias de leitura.
Neste exemplo, também há uma coluna chamada liked, que indica se um usuário gostou ou não de um filme. Essa coluna não está incluída no featurestore, mas ainda é possível
transmitir esses valores para a saída de exibição em lote. Na saída, esses valores de passagem
são unidos com os valores da featurestore.
Valores nulos
Se, em um determinado carimbo de data/hora, o valor de um recurso for nulo, o Feature Store Vertex AI retornará o valor de recurso anterior não nulo. Se não houver valores anteriores, o Vertex AI Feature Store retornará nulo.
Valores do recurso de veiculação em lote
Disponibilize em lote valores de recurso de um featurestore para receber dados, conforme determinado pelo arquivo de lista de instâncias de leitura.
Se você quiser reduzir os custos de uso do armazenamento off-line lendo dados recentes de treinamento e excluindo dados antigos, especifique um horário de início. Para saber como reduzir o custo do uso do armazenamento off-line especificando um horário de início, consulte Especificar um horário de início para otimizar esses custos durante a exibição em lote e a exportação em lote.
IU da Web
Use outro método. Não é possível disponibilizar recursos em lote pelo console doGoogle Cloud .
REST
Para valores de recursos de disponibilização em lote, envie uma solicitação POST usando o método featurestores.batchReadFeatureValues.
O exemplo a seguir gera uma tabela do BigQuery que contém valores de recurso
para os tipos de entidade users e movies. Observe
que cada destino de saída pode ter alguns pré-requisitos antes de enviar
uma solicitação. Por exemplo, se você especificar um nome de tabela para o campo
bigqueryDestination, precisará ter um conjunto de dados atual. Esses
requisitos estão documentados na referência da API.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
- LOCATION_ID: região onde a featurestore é criada. Por exemplo,
us-central1. - PROJECT_ID: o ID do projeto.
- FEATURESTORE_ID: ID do featurestore.
- DATASET_NAME: nome do conjunto de dados de destino do BigQuery.
- TABLE_NAME: nome da tabela de destino do BigQuery.
- STORAGE_LOCATION: URI do Cloud Storage para o arquivo CSV de instâncias de leitura.
Método HTTP e URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
Corpo JSON da solicitação:
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
Será exibido um código semelhante a este. Use OPERATION_ID na resposta para ver o status da operação.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
Python
Para saber como instalar o SDK da Vertex AI para Python, consulte Instalar o SDK da Vertex AI para Python. Para mais informações, consulte a documentação de referência da API Python.
Outras linguagens
É possível instalar e usar as seguintes bibliotecas de cliente do Vertex AI para chamar a API Vertex AI. As bibliotecas de cliente do Cloud oferecem uma experiência otimizada aos desenvolvedores, usando as convenções e os estilos naturais de cada linguagem com suporte.
Ver jobs de exibição em lote
Use o console Google Cloud para ver os jobs de exibição em lote em um projetoGoogle Cloud .
IU da Web
- Na seção "Vertex AI" do console Google Cloud , acesse a página Recursos.
- Selecione uma região na lista suspensa Região.
- Na barra de ações, clique em Ver jobs de exibição em lote para listar os jobs de exibição em lote de todos os featurestores.
- Clique no ID de um job de disponibilização em lote para ver os detalhes, como a origem da instância de leitura usada e o destino da saída.
A seguir
- Saiba como processar valores de recurso em lote.
- Saiba como disponibilizar recursos por meio da exibição on-line.
- Veja a cota de jobs em lote simultâneos do Vertex AI Feature Store.
- Resolva problemas comuns da Feature Store da Vertex AI (legada).