モデル トレーニング用の特徴データを取得するには、バッチ サービングを使用します。アーカイブまたはアドホック分析のために特徴値をエクスポートする必要がある場合は、代わりに特徴値をエクスポートします。
モデル トレーニングの特徴値を取得する
モデルのトレーニングには、予測タスクの例が入ったトレーニング データセットが必要です。これらの例は、特徴とラベルを含むインスタンスで構成されています。そのインスタンスが、予測を行う対象です。たとえば、インスタンスが住宅で、その市場価値が知りたいとします。その特徴には、立地、経年数、最近販売された付近の住宅の平均価格などがあります。ラベルとは、その住宅は最終的に $100,000 で販売されます、といった予測タスクの答えのことです。
各ラベルは特定の時点での観測情報となるため、観測が行われた時点での対応する特徴値(特定の住宅が販売されたとき、その周辺にある住宅の価格など)を取得する必要があります。時間をかけてラベルと特徴値が収集されるにつれて、そうした特徴値は変化します。Vertex AI Feature Store(従来版)では、時間指定ルックアップを実行でき、特定の時点における特徴値を取得できます。
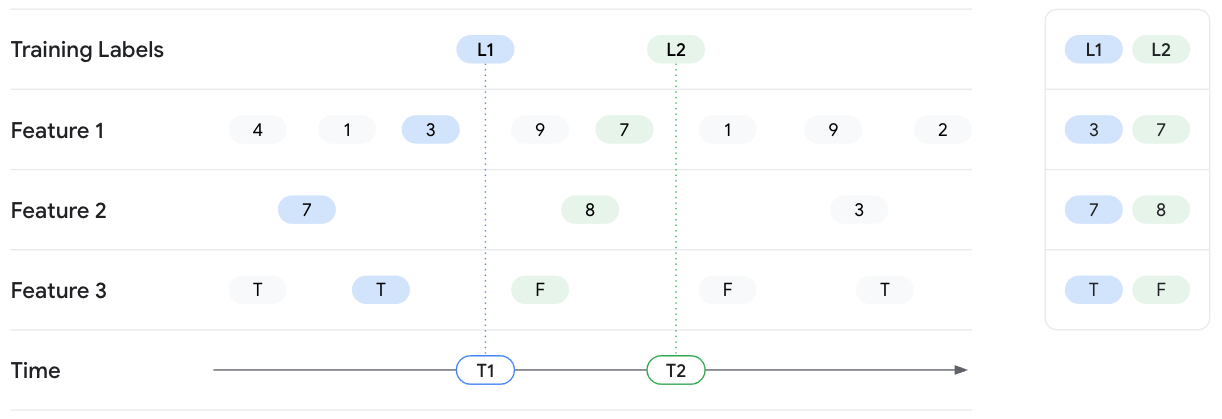
時間指定ルックアップの例
次の例では、L1 と L2 というラベルを持つ 2 つのトレーニング インスタンスの特徴値を取得します。2 つのラベルは、それぞれ T1 と T2 の時点で観測されます。そうした時刻に特徴値の状態を凍結させるとします。したがって、T1 でのポイントインタイム ルックアップでは、Vertex AI Feature Store(従来版)により T1 時点までの Feature 1、Feature 2、Feature 3 の最新の特徴値が返され、T1 より後の値は露出しません。特徴値は時間の経過とともに変化し、それによってラベルも変化します。したがって、T2 の時点では、その時点での異なる特徴値が Feature Store から返されます。
バッチ サービングの入力
バッチ サービング リクエストには、次の情報を含める必要があります。
- 値を取得する既存の特徴のリスト。
- 各トレーニング サンプルの情報を含む読み取りインスタンス リスト。特定の時点における観察値を列挙したものです。これは、CSV ファイルか BigQuery テーブルのいずれかです。このリストには、次の情報を含める必要があります。
- タイムスタンプ: ラベルが観測または測定された時刻。タイムスタンプは、Vertex AI Feature Store(従来版)が時間指定ルックアップを実行できるようにするために必要です。
- エンティティ ID: エンティティの 1 つ以上の ID。ラベルに対応します。
- 出力の書き込み先の URI と形式。Vertex AI Feature Store(従来版)の出力では基本的に、読み取りインスタンス リストからのテーブルと featurestore からの特徴値が結合されます。出力には、次のいずれかの形式と場所を指定します。
- リージョンまたはマルチリージョン データセット内の BigQuery テーブル。
- リージョンまたはマルチリージョンの Cloud Storage バケットにある CSV ファイル。ただし、特徴値に配列が含まれている場合は、別の形式を選択する必要があります。
- Cloud Storage バケット内の Tfrecord ファイル
リージョンの要件
読み取りインスタンスと宛先の両方で、ソース データセットまたはバケットが featurestore と同じリージョンまたは同じマルチリージョン ロケーションに存在する必要があります。たとえば、us-central1 の featurestore は、us-central1 または米国のマルチリージョン ロケーションにある Cloud Storage バケットまたは BigQuery データセットに対してのみ、データの読み取りとエクスポートを行うことができます。us-east1 などからのデータは使用できません。また、デュアルリージョン バケットを使用したデータの読み取りと提供はサポートされていません。
読み取りインスタンス リスト
読み取りインスタンス リストは、取得する特徴値のエンティティとタイムスタンプを指定します。CSV ファイルまたは BigQuery テーブルには、次の列を任意の順序で含める必要があります。各列には、列見出しが必要です。
- タイムスタンプ列を含める必要があります。ここで、ヘッダー名は
timestamp、列の値は RFC 3339 形式のタイムスタンプです。 - エンティティ タイプの列を 1 列以上含める必要があります。ここで、ヘッダーはエンティティ タイプ ID、列の値はエンティティ ID です。
- 省略可: そのまま出力に渡されるパススルー値(追加の列)を含めることができます。これは、Vertex AI Feature Store(従来版)にないデータがあり、そのデータを出力に含める場合に役立ちます。
例(CSV)
ここでは、エンティティ タイプ users および movies と、それらの特徴を含む featurestore があるとします。たとえば、users の特徴に age と gender が含まれ、movies の特徴に ratings と genre が含まれる場合があります。
この例では、ユーザーの映画の好みに関するトレーニング データを収集します。2 つのユーザー エンティティ alice と bob の特徴値を、ユーザーが視聴している映画の特徴とともに取得します。別のデータセットから、alice さんが movie_01 を視聴して高く評価したことがわかります。bob さんは movie_02 を視聴しましたが、低く評価しました。そのため、読み取りインスタンス リストは次の例のようになります。
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
Vertex AI Feature Store(従来版)は、指定されたタイムスタンプ以前のすべてのエンティティの特徴値を取得します。取得する特徴は、読み取りインスタンス リストではなく、バッチ サービング リクエストの一部として指定します。
この例には、ユーザーが映画を高く評価したかどうかを示す liked という列も含まれています。この列は featurestore に含まれませんが、これらの値をバッチ サービング出力に渡すことは可能です。出力では、これらのパススルー値が featurestore の値と結合されています。
Null 値
特定のタイムスタンプにおける特徴値が Null の場合、Vertex AI Feature Store(従来版)は、その前にある Null 以外の特徴値を返します。それより前に値がなければ、Vertex AI Feature Store(従来版)は Null を返します。
特徴値をバッチ処理する
読み取りインスタンスのリストファイルに指定された featurestore から特徴値をバッチ処理してデータを取得します。
最近のトレーニング データを読み取り、古いデータを除外することで、オフライン ストレージの使用コストを削減するには、開始時間を指定します。開始時間を指定してオフライン ストレージの使用コストを削減する方法については、バッチ サービングとバッチ エクスポート中のオフライン ストレージ コストを最適化するために開始時間を指定するをご覧ください。
ウェブ UI
別の方法を使用してください。Google Cloud コンソールから特徴をバッチ処理することはできません。
REST
特徴値をバッチ処理するには、featurestores.batchReadFeatureValues メソッドを使用して POST リクエストを送信します。
次のサンプルは、users エンティティ タイプと movies エンティティ タイプの特徴値を含む BigQuery テーブルを出力します。なお、各出力先には、リクエストを送信する前に用意しなければならないものがあります。たとえば、bigqueryDestination フィールドにテーブル名を指定する場合は、データセットが存在する必要があります。こうした要件については、API リファレンスをご覧ください。
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION_ID: featurestore が作成されるリージョン。例:
us-central1 - PROJECT_ID: 実際のプロジェクト ID。
- FEATURESTORE_ID: featurestore の ID。
- DATASET_NAME: 出力先 BigQuery データセットの名前。
- TABLE_NAME: 出力先 BigQuery テーブルの名前。
- STORAGE_LOCATION: 読み取りインスタンス CSV ファイルの Cloud Storage URI。
HTTP メソッドと URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
リクエストの本文(JSON):
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
出力は次のようになります。レスポンスの OPERATION_ID を使用して、オペレーションのステータスを取得できます。
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
Vertex AI SDK for Python
Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。 詳細については、Vertex AI SDK for Python API のリファレンス ドキュメントをご覧ください。
その他の言語
次の Vertex AI クライアント ライブラリを使用してインストールすると、Vertex AI API を呼び出すことができます。Cloud クライアント ライブラリによって、サポートされている各言語の自然な規則やスタイルが使用され、デベロッパーに快適な利用環境が提供されます。
バッチ サービング ジョブの表示
Google Cloud コンソールを使用して、Google Cloud プロジェクトのバッチ サービング ジョブを表示します。
ウェブ UI
- Google Cloud Console の [Vertex AI] セクションで、[特徴] ページに移動します。
- [リージョン] プルダウン リストからリージョンを選択します。
- アクションバーで [バッチ サービング ジョブを表示] をクリックすると、すべての featurestore のバッチ サービング ジョブが一覧表示されます。
- バッチ サービング ジョブの ID をクリックして、使用された読み取りインスタンス ソースや出力先などの詳細を表示します。
次のステップ
- 特徴値のバッチ取り込みの方法を学習する。
- オンライン処理を通して特徴を処理する方法を確認する。
- Vertex AI Feature Store(従来版)の同時実行バッチジョブの割り当てを確認する。
- Vertex AI Feature Store(従来版)に関する一般的な問題のトラブルシューティングを行う。