Vertex AI Feature Store は、Vertex AI に不可欠なクラウドネイティブのマネージド Feature Store サービスです。このサービスでは、ML の特徴管理とオンライン サービング プロセスが合理化されます。特徴データを BigQuery のテーブルまたはビューで管理し、BigQuery データソースから直接オンラインで提供することができます。
Vertex AI Feature Store は、特徴データソースを指定してオンライン サービングを設定できるリソースをプロビジョニングします。その後、BigQuery データソースとやり取りするメタデータ レイヤとして機能します。最新の特徴値を BigQuery から直接提供し、低レイテンシでオンライン予測を実現します。
Vertex AI Feature Store では、特徴データを含む BigQuery テーブルまたはビューがまとまってオフライン ストアを形成します。過去の特徴データを含む特徴値をオフライン ストアで維持できます。すべての特徴データが BigQuery で保持されるため、Vertex AI Feature Store で Vertex AI 内に別のオフライン ストアをプロビジョニングする必要はありません。また、オフライン ストアのデータを使用して ML モデルをトレーニングする場合は、BigQuery の API と機能を使用して、データをエクスポートまたは取得できます。
Vertex AI Feature Store を使用してオンライン サービングを設定し、開始するワークフローは次のようになります。
BigQuery でデータソースを準備します。
省略可: 特徴グループと特徴を作成してデータソースを登録します。
オンライン ストア リソースと特徴ビューのリソースを設定して、特徴データソースをオンライン サービング クラスタに接続します。
特徴ビューから最新の特徴値をオンラインで提供します。
Vertex AI Feature Store のデータモデルとリソース
このセクションでは、Vertex AI Feature Store の次の側面に関連するデータモデルとリソースについて説明します。
BigQuery でのデータソースの準備
Vertex AI Feature Store は、オンライン サービング中に BigQuery データソースの特徴データを使用します。特徴レジストリまたはオンライン サービング リソースを設定する前に、特徴データが 1 つ以上の BigQuery テーブルまたはビューに保存されている必要があります。
BigQuery のテーブルまたはビュー内の各列は 1 つの特徴を表します。各行には一意の ID に対応する特徴値が含まれます。BigQuery で特徴データを準備する詳しい方法については、データソースを準備するをご覧ください。
たとえば、図 1 の BigQuery テーブルには次の列があります。
f1とf2: 特徴列entity_id: 特徴レコードを識別する一意の ID を含む ID 列。feature_timestamp: タイムスタンプ列。

データソースは Vertex AI ではなく BigQuery で準備します。この段階で Vertex AI リソースを作成する必要はありません。
特徴レジストリの設定
BigQuery でデータソースを準備したら、それらのデータソース(特定の特徴列を含む)を特徴レジストリに登録できます。
特徴の登録は任意です。BigQuery データソースを特徴レジストリに追加しなくても、オンラインで特徴を提供できます。ただし、次のような場合は、特徴を登録したほうが便利です。
データに同じエンティティ ID のインスタンスが複数含まれている可能性がある。この場合は、タイムスタンプ列を含む時系列形式でデータを準備する必要があります。特徴を登録すると、Vertex AI Feature Store がタイムスタンプを検索し、最新の特徴値のみを提供します。
データソースから特定の特徴列を登録したい。
複数のデータソースから特定の列を集約して、特徴ビューのインスタンスを定義したい。
特徴レジストリのリソース
特徴データを特徴レジストリに登録するには、次の Vertex AI Feature Store リソースを作成する必要があります。
特徴グループ(
FeatureGroup):FeatureGroupリソースが特定の BigQuery ソーステーブルまたはビューに関連付けられます。これは、特徴列の論理グループで、Featureリソースで表されます。特徴グループの作成方法については、特徴グループを作成するをご覧ください。特徴(
Feature):Featureリソースは、親のFeatureGroupリソースに関連付けられている特徴データソースの特徴値を含む特定の列を表します。特徴グループに特徴を作成する方法については、特徴を作成するをご覧ください。
たとえば、図 2 は特徴列 f1 と f2 を含む特徴グループを表しています。特徴グループに関連付けられた BigQuery テーブルがソースになっています。BigQuery データソースに 4 つの特徴列があり、2 つの列を集計して特徴グループを形成しています。
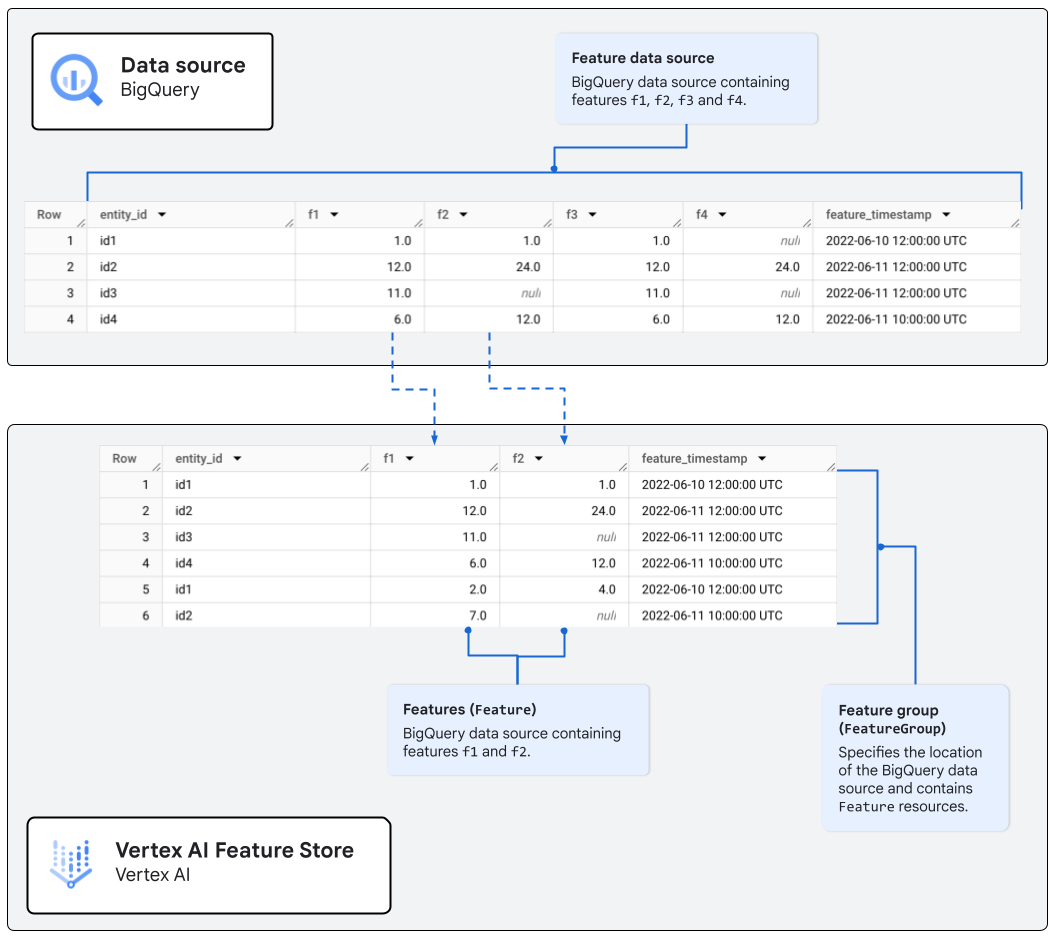
Feature 列を含む FeatureGroup の例。オンライン サービングの設定
オンライン予測に特徴を提供するには、少なくとも 1 つのオンライン サービング クラスタを定義して構成し、特徴データソースまたは特徴レジストリ リソースに関連付ける必要があります。Vertex AI Feature Store では、オンライン サービング クラスタをオンライン ストア インスタンスと呼んでいます。オンライン ストア インスタンスには複数の特徴ビューが含まれている場合があります。その場合、それぞれの特徴ビューが特徴データソースと関連付けられています。
オンライン サービング リソース
オンライン サービングを設定するには、次の Vertex AI Feature Store リソースを作成する必要があります。
オンライン ストア(
FeatureOnlineStore):FeatureOnlineStoreリソースはオンライン サービング クラスタ インスタンスを表します。ここには、オンライン サービング ノードの数など、オンライン サービスの構成が含まれます。オンライン ストア インスタンスには特徴データのソースが指定されていませんが、BigQuery または特徴レジストリのいずれかで特徴データソースを特定できるFeatureViewリソースが含まれている必要があります。オンライン ストア インスタンスの作成方法については、オンライン ストア インスタンスを作成するをご覧ください。特徴ビュー(
FeatureView):FeatureViewリソースは、オンライン ストア インスタンスにある特徴の論理的なコレクションです。特徴ビューを作成するときに、次のいずれかの方法で特徴データソースの場所を指定できます。特徴レジストリから 1 つ以上の特徴グループと特徴を関連付けます。特徴グループは、BigQuery データソースのロケーションを示しています。特徴グループ内の特徴は、そのデータソース内の特定の特徴列を指しています。
または、BigQuery のソーステーブルまたはビューを関連付けます。
オンライン ストア内で特徴ビュー インスタンスを作成する方法については、特徴ビューを作成するをご覧ください。
たとえば、図 3 は特徴列 f2 と f4 を含む特徴ビューを示しています。これらの特徴列は、BigQuery テーブルに関連付けられた 2 つの別々の特徴グループをソースとしています。
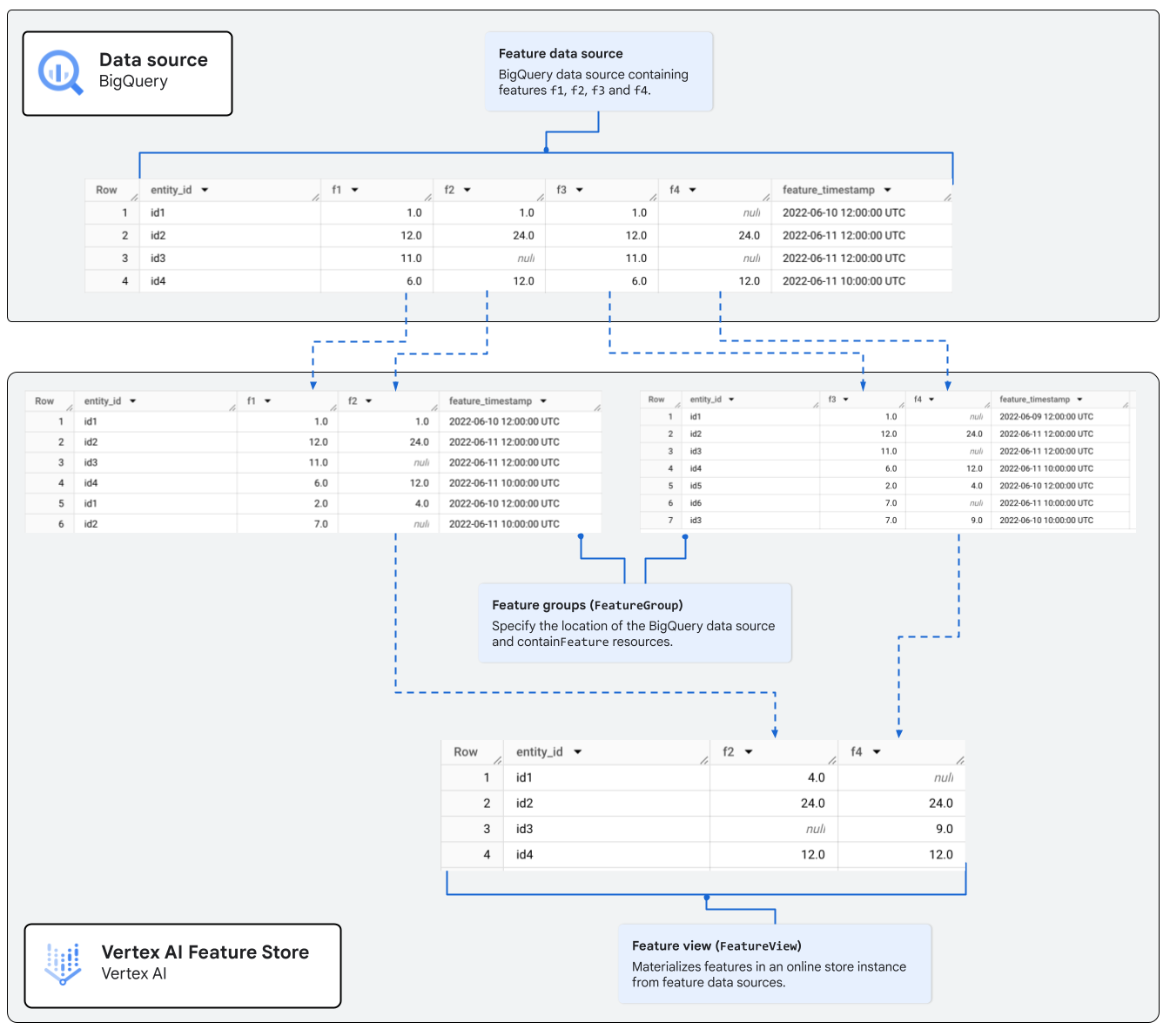
FeatureView の例。オンライン サービング
Vertex AI Feature Store は、リアルタイムのオンライン予測に次のタイプのオンライン サービングを行います。
Bigtable オンライン サービングは、大量のデータ(数テラバイトのデータ)を提供する場合に便利です。これは Vertex AI Feature Store(レガシー)のオンライン サービングと似ています。また、ホットスポット化を軽減するため、キャッシュ機能が改善されています。Bigtable オンライン サービングはエンベディングをサポートしていません。
最適化されたオンライン サービングでは、特徴のオンライン サービングを非常に低いレイテンシで行います。オンライン サービングのレイテンシはワークロードによって異なりますが、最適化されたオンライン サービングでは Bigtable オンライン サービングよりもレイテンシが低くなるため、ほとんどのシナリオで推奨されます。最適化されたオンライン サービングは、エンベディング管理もサポートしています。ただし、頻繁に更新される大量のデータを提供する必要があっても、エンベディングを提供する必要がない場合は、Bigtable オンライン サービングを使用してください。
最適化されたオンライン サービングを使用するには、パブリック エンドポイントまたは専用の Private Service Connect エンドポイントを構成する必要があります。
特徴の設定後に Vertex AI Feature Store でオンライン サービングを設定する方法については、オンライン サービングのタイプをご覧ください。
バッチ予測またはモデル トレーニングのオフライン サービング
BigQuery から Vertex AI の別のオフライン ストアに特徴データをコピーまたはインポートする必要がないため、BigQuery のデータ マネジメント機能とエクスポート機能を使用して次のことができます。
特定の時点の過去のデータなどの特徴データをクエリします。
BigQuery を使用した ML の詳細については、BigQuery ML の概要をご覧ください。
Vertex AI Feature Store の用語
特徴量エンジニアリングに関連する用語
特徴量エンジニアリング
- 特徴量エンジニアリングとは、機械学習(ML)の元データを ML モデルのトレーニングや予測に使用できる特徴量に変換するプロセスです。
特徴
- 機械学習(ML)において、特徴とは、ML モデルのトレーニングや予測の入力として使用されるインスタンスまたはエンティティの特性(属性)のことです。
特徴値
- 特徴値は、インスタンスまたはエンティティの特徴(属性)の実際の測定可能な値に対応します。一意のエンティティの特徴値のコレクションが、エンティティに対応する特徴レコードを表します。
特徴のタイムスタンプ
- 特徴のタイムスタンプは、エンティティの特定の特徴レコードから特徴値のセットが生成された時刻を示します。
特徴レコード
- 特徴レコードは、特定の時点での一意のエンティティの属性を表すすべての特徴値を集約したものです。
特徴レジストリに関連する用語
特徴レジストリ
- 特徴レジストリは、オンライン予測に使用する特徴データソースを記録するための中心的なインターフェースです。詳細については、特徴レジストリの設定をご覧ください。
特徴グループ
- 特徴グループは、BigQuery のソーステーブルまたは特徴データを含むビューに対応する特徴レジストリ リソースです。特徴ビューには特徴が含まれることがあり、データソース内の特徴列の論理グループと考えることができます。
特徴のサービングに関連する用語
特徴のサービング
- 特徴のサービングは、トレーニングまたは推論のために保存されている特徴値をエクスポートまたは取得するプロセスです。Vertex AI には、オンライン サービングとオフライン サービングの 2 種類の特徴のサービングがあります。オンライン サービングでは、オンライン予測用に特徴データソースのサブセットの最新の特徴値を取得します。オフラインまたはバッチ サービングでは、ML モデルのトレーニングなどのオフライン処理用に大量の特徴データをエクスポートします。
オフライン ストア
- オフライン ストアは、最近と過去の特徴データを保存するストレージ設備で、通常は ML モデルのトレーニングに使用されます。オフライン ストアには最新の特徴値も含まれており、オンライン予測にも使用できます。
オンライン ストア
- 特徴管理において、オンライン ストアはオンライン予測のために提供される最新の特徴値を保存するストレージ設備です。
特徴ビュー
- 特徴ビューは、BigQuery データソースからオンライン ストア インスタンスに具体化された特徴の論理的なコレクションです。特徴ビューは、顧客の特徴データを保存し、定期的に更新します。この特徴データは、BigQuery ソースから定期的に更新されます。特徴ビューは、直接、または特徴レジストリ リソースとの関連付けを通じて特徴データ ストレージに関連付けられます。
ロケーションの制約
Vertex AI Feature Store のすべてのリソースは、BigQuery データソースと同じリージョンまたは同じマルチリージョン ロケーションに配置する必要があります。たとえば、特徴データソースが us-central1 にある場合、FeatureOnlineStore インスタンスは us-central1 または US マルチリージョン ロケーションにのみ作成する必要があります。
特徴メタデータ
Vertex AI Feature Store は Dataplex と統合され、特徴メタデータなど、特徴のガバナンス機能を提供します。オンライン ストア インスタンス、特徴ビュー、特徴グループは Data Catalog にデータアセットとして自動的に登録されます。Data Catalog は、これらのリソースからメタデータをカタログ化する Dataplex の機能です。登録後、Dataplex のメタデータ検索機能を使用して、これらのリソースのメタデータの検索、表示、管理を行うことができます。Dataplex で Vertex AI Feature Store リソースを検索する方法については、Data Catalog でリソース メタデータを検索するをご覧ください。
特徴ラベル
リソースの作成中または作成後に、リソースにラベルを追加できます。既存の Vertex AI Feature Store リソースにラベルを追加する方法については、ラベルを更新するをご覧ください。
リソース バージョン メタデータ
Vertex AI Feature Store では、特徴のバージョン 0 のみがサポートされます。
エンベディング管理とベクトル検索
Vertex AI Feature Store の最適化されたオンライン サービングでは、エンベディング管理がサポートされています。エンベディングは通常の double 配列として BigQuery に保存できます。Vertex AI Feature Store のエンベディング管理機能を使用してベクトル類似度検索を行い、指定したエンティティまたはエンベディング値に対して近似最近傍のエンティティを取得できます。
Vertex AI Feature Store でエンベディング管理を使用するには、次の操作を行う必要があります。
embedding列を追加して、エンベディングをサポートするように BigQuery データソースを設定します。必要に応じて、フィルタリング列とクラウディング列を追加します。詳細については、データソースの準備のガイドラインをご覧ください。特徴ビューの作成時に
embedding列を指定します。エンベディングをサポートする特徴ビューを作成する方法については、特徴ビューのベクトル取得を構成するをご覧ください。
Vertex AI Feature Store でベクトル類似性検索を行う方法については、エンティティのベクトル検索を行うをご覧ください。
データの保持
Vertex AI Feature Store は、データソース内の特徴値に関連付けられているタイムスタンプに基づいて、一意の ID に対して最新の特徴値を保持します。オンライン ストアにデータ保持の上限はありません。
オフライン ストアは BigQuery によってプロビジョニングされるため、履歴の特徴値など、BigQuery のデータ保持期間や割り当てが特徴データソースに適用される場合があります。BigQuery の割り当てと上限の詳細
割り当てと上限
Vertex AI Feature Store では割り当てと上限が適用されます。使用量の上限を設定すること、リソースを管理するだけでなく、予期しない使用量の急増から Google Cloud ユーザーのコミュニティを保護できます。これらの制約に達しないように Vertex AI Feature Store リソースを効率的に使用するには、Vertex AI Feature Store の割り当てと上限をご覧ください。
料金
Vertex AI Feature Store のリソース使用料金については、Vertex AI Feature Store の料金をご覧ください。
ノートブック チュートリアル
次のサンプルとチュートリアルを使用して、Vertex AI Feature Store の詳細をご覧ください。
Vertex AI Feature Store Bigtable オンライン サービングを使用した、BigQuery データのオンライン特徴サービングと取得
|
|
このチュートリアルでは、Vertex AI Feature Store で Bigtable オンライン サービングを使用して、BigQuery で特徴値のオンライン サービングと取得を行う方法について説明します。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
Vertex AI Feature Store Optimized オンライン サービングを使用した、BigQuery データのオンライン特徴サービングと取得
|
|
このチュートリアルでは、Vertex AI Feature Store で最適化されたオンライン サービングを使用して、BigQuery からの特徴値のサービングと取得を行う方法について説明します。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
Vertex AI Feature Store を使用した、BigQuery データのオンライン特徴サービングとベクトル取得
|
|
このチュートリアルでは、Vertex AI Feature Store を使用して BigQuery で特徴値のオンライン サービングとベクトル取得を行う方法を学習します。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
Vertex AI Feature Store 特徴ビュー サービス エージェント
|
|
このチュートリアルでは、特徴ビューのサービス エージェントを有効にして、特定のソースデータへのアクセス権を各特徴ビューに付与する方法について説明します。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
Vertex AI Feature Store ベースの LLM グラウンディングのチュートリアル。
|
|
このチュートリアルでは、ユーザー提供データをチャンクに分割し、エンベディング生成機能を持つ大規模言語モデル(LLM)を使用して各チャンクのエンベディング ベクトルを生成する方法を学習します。生成されたエンベディング ベクトル データセットは Vertex AI Feature Store に読み込むことができ、高速な特徴量取得と効率的なオンライン サービングが可能になります。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
Vertex AI Feature Store と BigQuery を使用して生成 AI RAG アプリケーションを作成する
|
|
このチュートリアルでは、BigQuery ベクトル検索と Vertex AI Feature Store を使用して、生成 AI アプリケーション用の低レイテンシのベクトル検索システムを構築する方法について説明します。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
Vertex AI Feature Store で IAM ポリシーを構成する
|
|
このチュートリアルでは、Vertex AI Feature Store 内に保存されているリソースとデータへのアクセスを制御する IAM ポリシーの構成方法について説明します。 Colab で開く | Colab Enterprise で開く | GitHub で表示する | Vertex AI Workbench ユーザー管理ノートブックで開く |
次のステップ
BigQuery でデータを設定する方法を学習する。
オンライン ストア インスタンスの作成方法を学習する。