예시 기반 설명을 사용하려면 Model 리소스를 Model Registry에 가져올 때 explanationSpec을 지정하여 설명을 구성해야 합니다.
그러면 온라인 설명을 요청할 때 요청에 ExplanationSpecOverride를 지정하여 구성값의 일부를 재정의할 수 있습니다. 일괄 설명은 지원되지 않으므로 요청할 수 없습니다.
이 페이지에서는 이러한 옵션을 구성하고 업데이트하는 방법을 설명합니다.
모델을 가져오거나 업로드할 때 설명 구성
시작하기 전에 다음 사항이 있는지 확인하세요.
모델 아티팩트가 포함된 Cloud Storage 위치가 있어야 합니다. 모델은 레이어 이름을 제공하거나 출력을 잠재 공간으로 사용할 수 있는 서명을 제공하는 심층신경망(DNN)이어야 합니다. 또는 임베딩(잠재 공간 표현)을 직접 출력하는 모델을 제공해도 됩니다. 이 잠재 공간은 설명을 생성하는 데 사용되는 예시 표현을 캡처합니다.
최근접 이웃 검색을 위해 색인을 생성할 인스턴스가 포함된 Cloud Storage 위치가 있어야 합니다. 자세한 내용은 입력 데이터 요구사항을 참조하세요.
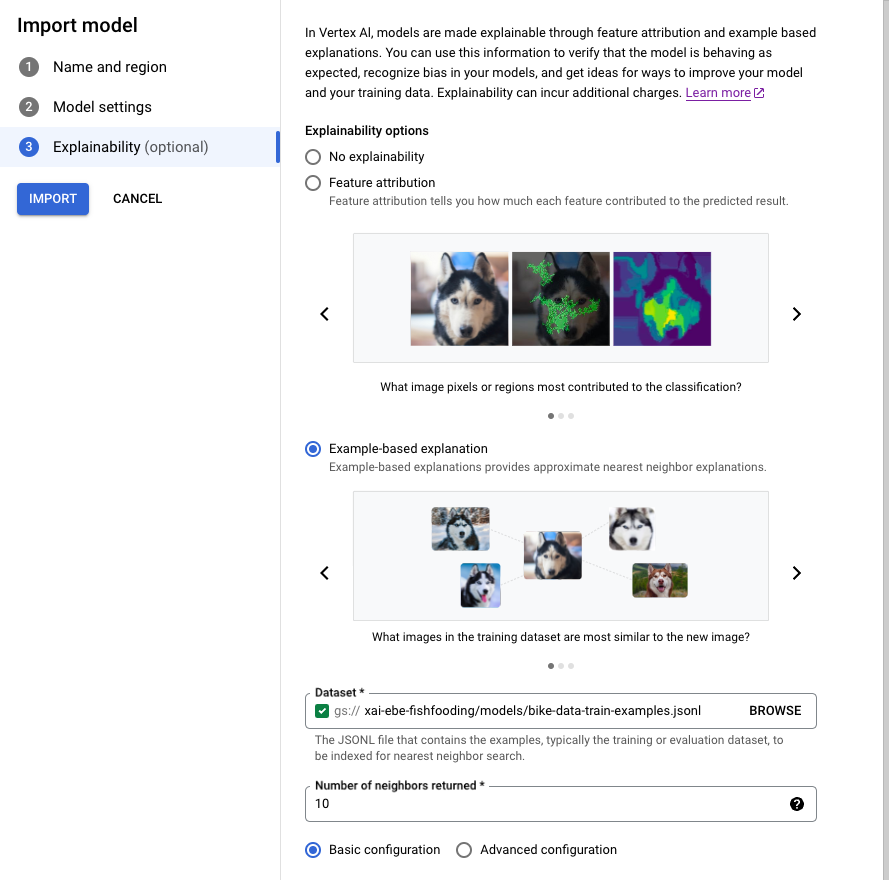
콘솔
Google Cloud 콘솔을 사용하여 모델 가져오기 가이드를 따르세요.
설명 기능 탭에서 예시 기반 설명을 선택하고 내용을 입력합니다.
각 필드에 대한 자세한 내용은 Google Cloud 콘솔(아래 참조)의 팁과 Example 및 ExplanationMetadata의 참고 문서를 확인하세요.
gcloud CLI
- 다음
ExplanationMetadata를 로컬 환경의 JSON 파일에 작성합니다. 파일 이름은 중요하지 않지만 이 예시에서는 파일 이름을explanation-metadata.json으로 지정합니다.
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (선택사항) 전체
NearestNeighborSearchConfig를 지정하는 경우, 로컬 환경의 JSON 파일에 다음을 씁니다. 파일 이름은 중요하지 않지만 이 예시에서는 파일 이름을search_config.json으로 지정합니다.
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- 다음 명령어를 실행하여
Model을 업로드합니다.
Preset 검색 구성을 사용하는 경우 --explanation-nearest-neighbor-search-config-file 플래그를 삭제하세요. NearestNeighborSearchConfig를 지정하는 경우 --explanation-modality 및 --explanation-query 플래그를 삭제합니다.
예시 기반 설명과 가장 관련성이 높은 플래그는 굵게 표시됩니다.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
자세한 내용은 gcloud ai 모델 업로드를 참조하세요.
-
업로드 작업에서 작업이 완료되었는지 확인하는 데 사용할 수 있는
OPERATION_ID를 반환합니다. 응답에"done": true가 포함될 때까지 작업 상태를 폴링할 수 있습니다. gcloud ai operations describe 명령어를 사용하여 상태를 폴링합니다. 예를 들면 다음과 같습니다.gcloud ai operations describe <operation-id>작업이 완료될 때까지 설명을 요청할 수 없습니다. 데이터 세트 및 모델 아키텍처의 크기에 따라 이 단계는 예시의 쿼리에 사용되는 색인을 빌드하는 데 몇 시간이 걸릴 수 있습니다.
REST
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT
- LOCATION
다른 자리표시자에 대해 알아보려면 Model, explanationSpec, Examples을 참조하세요ㅗ.
모델 업로드에 대한 상세 설명은 upload 메서드와 모델 가져오기를 참조하세요.
아래 JSON 요청 본문은 Preset 검색 구성을 지정합니다. 또는 전체 NearestNeighborSearchConfig를 지정해도 됩니다.
HTTP 메서드 및 URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
JSON 요청 본문:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
업로드 작업에서 작업이 완료되었는지 확인하는 데 사용할 수 있는 OPERATION_ID를 반환합니다. 응답에 "done": true가 포함될 때까지 작업 상태를 폴링할 수 있습니다. gcloud ai operations describe 명령어를 사용하여 상태를 폴링합니다. 예를 들면 다음과 같습니다.
gcloud ai operations describe <operation-id>
작업이 완료될 때까지 설명을 요청할 수 없습니다. 데이터 세트 및 모델 아키텍처의 크기에 따라 이 단계는 예시의 쿼리에 사용되는 색인을 빌드하는 데 몇 시간이 걸릴 수 있습니다.
Python
이미지 분류 예시 기반 설명 노트북에서 모델 업로드 섹션을 참고하세요.
NearestNeighborSearchConfig
다음 JSON 요청 본문에서는 upload 요청에서 사전 설정 대신 전체 NearestNeighborSearchConfig를 지정하는 방법을 보여줍니다.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
이 표에는 NearestNeighborSearchConfig의 필드가 나열되어 있습니다.
| 필드 | |
|---|---|
dimensions |
필수 항목입니다. 입력 벡터의 차원 수입니다. 밀집 임베딩에만 사용됩니다. |
approximateNeighborsCount |
tree-AH 알고리즘을 사용하는 경우 필수입니다. 정확한 순서 변경이 수행되기 전에 유사 검색을 통해 찾을 이웃의 기본 개수입니다. 정확한 순서 변경은 유사 검색 알고리즘에서 반환하는 결과가 비용이 더 많이 드는 거리 계산을 이용해 재정렬되는 절차입니다. |
ShardSize |
ShardSize
각 샤드의 크기. 색인이 크면 지정된 샤드 크기를 기준으로 샤딩됩니다. 서빙 중에 각 샤드는 별도의 노드에서 제공되며 독립적으로 확장됩니다. |
distanceMeasureType |
최근접 이웃 검색에 사용되는 거리 측정입니다. |
featureNormType |
각 벡터에서 수행될 정규화 유형입니다. |
algorithmConfig |
oneOf:
벡터 검색에서 효율적인 검색에 사용하는 알고리즘의 구성입니다. 밀집 임베딩에만 사용됩니다.
|
DistanceMeasureType
| 열거형 | |
|---|---|
SQUARED_L2_DISTANCE |
유클리드(L2) 거리 |
L1_DISTANCE |
맨해튼(L1) 거리 |
DOT_PRODUCT_DISTANCE |
기본값 스칼라곱의 음수로 정의됩니다. |
COSINE_DISTANCE |
코사인 거리입니다. 코사인 거리 대신 DOT_PRODUCT_Distance + UNIT_L2_NORM을 사용하는 것이 좋습니다. Google의 알고리즘은 DOT_PRODUCT 거리를 기준으로 최적화되었으며, UNIT_L2_NORM과 결합하면 코사인 거리와 동일한 순위 및 수학적 등가를 제공합니다. |
FeatureNormType
| 열거형 | |
|---|---|
UNIT_L2_NORM |
단위 L2 정규화 유형입니다. |
NONE |
기본값 지정된 정규화 유형이 없습니다. |
TreeAhConfig
tree-AH 알고리즘(Shallow tree + Asymmetric Hashing)에 선택할 수 있는 필드입니다.
| 필드 | |
|---|---|
fractionLeafNodesToSearch |
double |
| 쿼리를 검색할 수 있는 리프 노드의 기본 비율입니다. 범위는 0.0~1.0 미만이어야 합니다. 설정하지 않으면 기본값은 0.05입니다. | |
leafNodeEmbeddingCount |
int32 |
| 각 리프 노드의 임베딩 수입니다. 설정하지 않으면 기본값은 1000입니다. | |
leafNodesToSearchPercent |
int32 |
지원 중단됨, fractionLeafNodesToSearch를 사용하세요.쿼리를 검색할 수 있는 리프 노드의 기본 비율입니다. 1~100 범위 내에 있어야 합니다. 설정되지 않으면 기본값은 10(즉, 10%)입니다. |
|
BruteForceConfig
이 옵션은 데이터베이스에서 각 쿼리의 표준 선형 검색을 구현합니다. 무차별 검색을 위해 구성할 필드가 없습니다. 이 알고리즘을 선택하려면 BruteForceConfig의 빈 객체를 algorithmConfig에 전달합니다.
입력 데이터 요구사항
데이터 세트를 Cloud Storage 위치에 업로드하세요. 파일이 JSON 줄 형식인지 확인하세요.
파일은 JSON Lines 형식이어야 합니다. 다음 샘플은 이미지 분류 예시 기반 설명 노트북에서 가져온 것입니다.
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
색인 또는 구성 업데이트
Vertex AI를 사용하면 모델의 최근접 이웃 색인이나 Example 구성을 업데이트할 수 있습니다. 이는 데이터 세트의 색인을 재생성하지 않고 모델을 업데이트하려는 경우에 유용합니다. 예를 들어 모델의 색인에 1,000개의 인스턴스가 포함되어 있고 인스턴스 500개를 더 추가하려는 경우 UpdateExplanationDataset를 호출하면 원래의 인스턴스 1,000개를 다시 처리하지 않고 색인에 추가할 수 있습니다.
설명 데이터 세트를 업데이트하려면 다음 안내를 따르세요.
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
사용 참고사항:
model_id는UpdateExplanationDataset작업 후에도 그대로 유지됩니다.UpdateExplanationDataset작업은Model리소스에만 영향을 주며, 연결된DeployedModel는 업데이트되지 않습니다. 즉,deployedModel의 색인에 배포 당시의 데이터 세트가 포함됩니다.deployedModel의 색인을 업데이트하려면 업데이트한 모델을 엔드포인트로 재배포해야 합니다.
온라인 설명을 가져올 때 구성 재정의
설명을 요청할 때 ExplanationSpecOverride 필드를 지정하여 즉석에서 일부 매개변수를 재정의할 수 있습니다.
애플리케이션에 따라서는 반환되는 설명 유형에 일부 제약 조건을 적용하는 것이 적합할 수 있습니다. 예를 들어, 다양한 설명을 보장하기 위해 사용자가 설명에 단일 유형의 예시가 설명에서 과도하게 표현되지 않음을 나타내는 크라우딩 매개변수를 지정할 수 있습니다. 구체적으로는 모델에서 새가 비행기로 라벨이 지정된 이유를 파악하려고 할 때 근본 원인을 효과적으로 조사하기 위해 너무 많은 새 예시를 설명으로 표시하는 것을 원하지 않을 수 있습니다.
다음 표에는 예제 기반 설명 요청에 대해 재정의할 수 있는 매개변수가 요약되어 있습니다.
| 속성 이름 | 속성 값 | 설명 |
|---|---|---|
| neighborCount | int32 |
설명으로 반환할 예시 수입니다. |
| crowdingCount | int32 |
동일한 크라우딩 태그로 반환할 최대 예시 수입니다. |
| allow | String Array |
설명에 허용되는 태그입니다. |
| deny | String Array |
설명에 허용되지 않는 태그입니다. |
벡터 검색 필터링에서는 이러한 매개변수를 자세히 설명합니다.
다음은 재정의가 포함된 JSON 요청 본문의 예시입니다.
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
다음 단계
다음은 예시 기반 explain 요청의 응답 예입니다.
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
가격 책정
가격 책정 페이지에서 예시 기반 설명에 대한 섹션 살펴보기