En tant que data scientist, voici mon workflow le plus courant : entraîner un modèle localement (dans mon notebook), consigner les paramètres, consigner les métriques de séries temporelles d'entraînement dans Vertex AI TensorBoard, puis consigner les métriques d'évaluation.
En tant que data scientist, je souhaite réutiliser le code de prétraitement des données que d'autres membres de mon entreprise ont écrit pour simplifier et standardiser tout le data wrangling complexe que nous effectuons. Je souhaite pouvoir :
- Utiliser une bibliothèque de prétraitement des données Python pour nettoyer un ensemble de données en mémoire (un DataFrame Pandas), dans un notebook.
- Entraîner un modèle à l'aide de Keras (également dans un notebook)
Notebook : Tests de modèles avec des données prétraitées
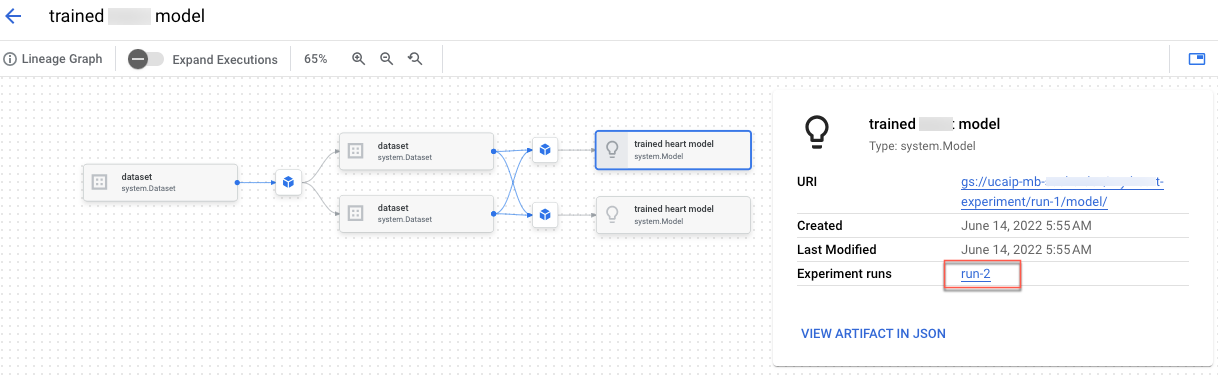
Dans le notebook "Créer la traçabilité des tests Vertex AI Experiments pour l'entraînement personnalisé", vous apprendrez à intégrer du code de prétraitement dans Vertex AI Experiments. Vous allez également créer la traçabilité des tests qui vous permettra d'enregistrer, d'analyser, de déboguer et d'auditer les métadonnées et les artefacts produits tout au long de votre exploration du ML.
Vous pouvez afficher la traçabilité des artefacts dans la console Google Cloud.