Wenn Sie die Berechtigung zum Erstellen benutzerdefinierter Felder haben, können Sie Ad-hoc-benutzerdefinierte Gruppen für Dimensionen erstellen, ohne logische Funktionen in Looker-Ausdrücken zu verwenden oderCASE WHEN-Logik insql-Parametern odertype: case-Feldern zu entwickeln.
Sie können auch Ad-hoc-benutzerdefinierte Klassen für Dimensionen des numerischen Typs erstellen, ohne logische Funktionen in Looker-Ausdrücken verwenden oder type: tier LookML-Felder entwickeln zu müssen, wenn Sie berechtigt sind, benutzerdefinierte Felder zu erstellen.
Bucketing kann sehr nützlich sein, um benutzerdefinierte Gruppierungsdimensionen in Looker zu erstellen.
Es gibt drei Möglichkeiten, Bucket in Looker zu erstellen:
tier-dimension-Typ verwenden- Parameter
caseverwenden - SQL-
CASE WHEN-Anweisung im ParameterSQLeines LookML-Felds verwenden
tier für Bucketing verwenden
Um Ganzzahl-Buckets zu erstellen, können wir den dimension-Typ einfach als tier definieren:
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
Mit dem Parameter style können Sie anpassen, wie die Stufen in explorativen Datenanalysen dargestellt werden. Für style sind vier Optionen vorhanden:
Beispiel:
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
Der Parameter style classic ist der Standardparameter und hat das Format Tx[x,x]. Dabei gibt Tx die Stufennummer und [x,x] den Bereich an. Auf der folgenden Abbildung ist eine Explore-Datentabelle mit der Anzahl der Nutzer zu sehen, die nach Alter der Nutzer gruppiert ist:
![Die höchste verfügbare Stufe für das Alter der Nutzer in der Datentabelle ist T02[10,20], was einer Anzahl von 808 Nutzern im Alter von 10 bis 20 Jahren entspricht.](https://cloud.google.com/static/looker/docs/images/bucketing-in-looker-1-2210.png?hl=de)
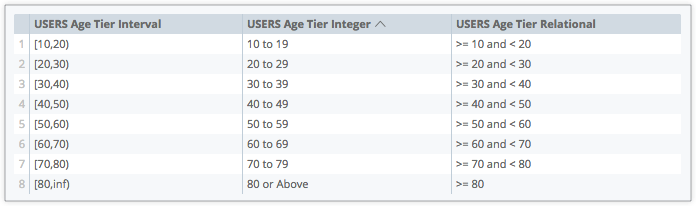
Die folgende Abbildung zeigt Beispiele für die anderen Parameteroptionen für style:
-
interval– im Format[x,x], wobei der niedrigste und der höchste Wert einer Stufe angegeben wird -
integer– im Formatx to x, das den niedrigsten und den höchsten Wert einer Stufe angibt -
relational– im Format>= x and <x, was bedeutet, dass ein Wert größer oder gleich dem Wert der niedrigsten Stufe und kleiner als der Wert der höchsten Stufe ist
Wichtige Punkte
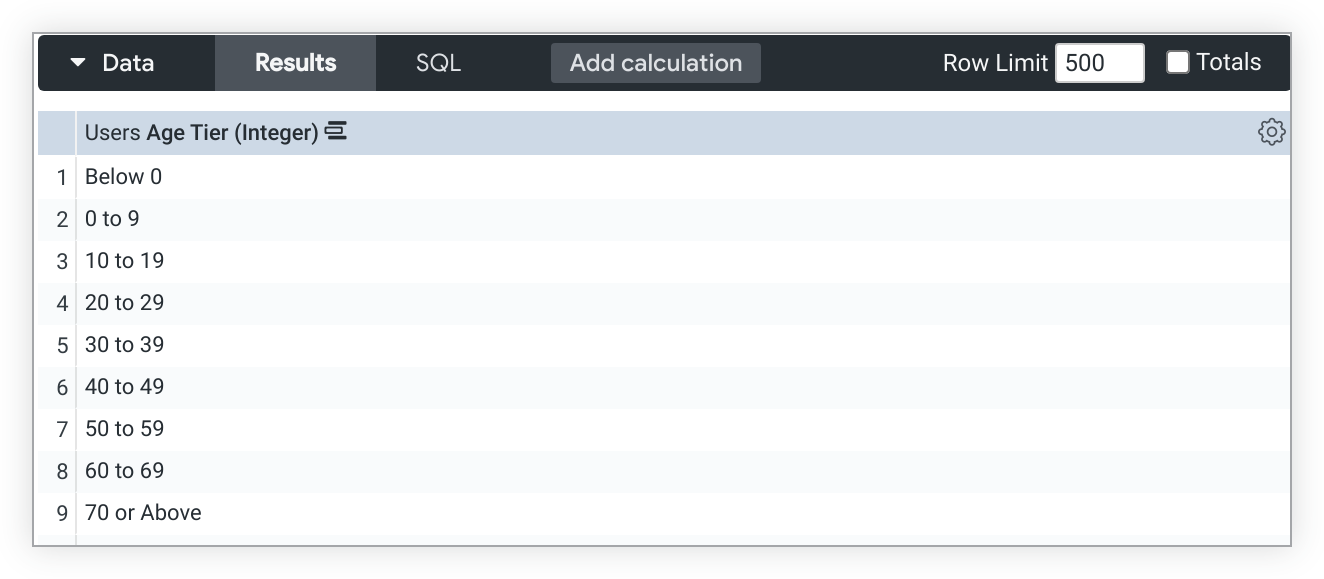
Die Verwendung von tier in Verbindung mit der Dimensionsergänzung kann zu unerwarteten Stufen-Buckets führen.
Wenn beispielsweise die Dimensionsfüllung für die type: tier-Dimension Altersgruppe aktiviert ist, werden die Stufen Unter 0 und 0 bis 9 angezeigt, obwohl die Daten keine Alterswerte für diese Stufen enthalten:
Wenn die Dimensionsfüllung für Altersgruppe deaktiviert ist, spiegeln die Buckets die in den Daten verfügbaren Alterswerte genauer wider, beginnend mit dem Bucket 10 bis 19:
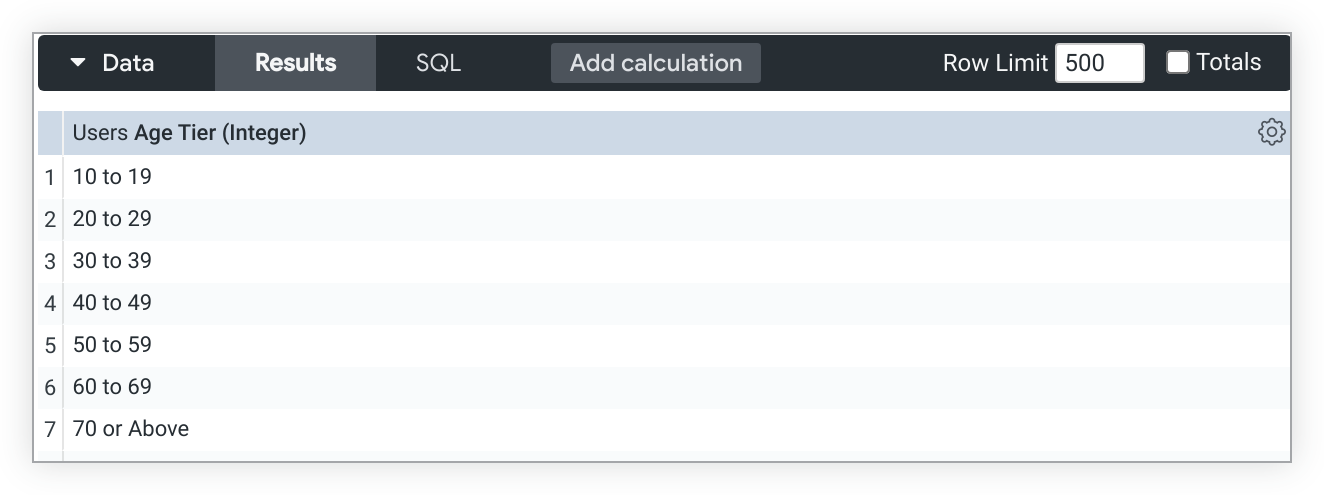
Sie können die Dimensionsfüllung aktivieren oder deaktivieren, indem Sie im Explore den Mauszeiger auf den Namen der Dimension bewegen, auf das Zahnradsymbol auf Feldebene klicken und entweder Ausgefüllte Stufenwerte entfernen auswählen, um die Funktion zu deaktivieren, oder Fehlende Stufenwerte ausfüllen, um sie zu aktivieren.
Weitere Informationen zu Looker tiers finden Sie auf der Dokumentationsseite Dimensionen, Filter und Parametertypen.
case für Bucketing verwenden
Mit dem Parameter case können Sie benutzerdefinierte Buckets mit benutzerdefinierter Sortierung erstellen. Der Parameter case wird für eine feste Anzahl von Bucket empfohlen, da er die Darstellung, Sortierung und Verwendung von Werten in UI-Filtern und -Visualisierungen beeinflussen kann. Mit case kann ein Nutzer beispielsweise nur die definierten Bucket-Werte in einem Filter auswählen.
Wenn Sie Buckets mit case erstellen möchten, können Sie eine Dimension definieren, z. B. einen Bucket für Bestellbeträge:
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Mit dem Parameter case werden Werte in der Regel in der Reihenfolge sortiert, in der die Buckets aufgeführt sind. Bei der Dimension order_amount_bucket ist die Reihenfolge der Bucket Small, Medium und Large:

Wenn Sie die Daten nach dem Alphabet sortieren möchten, fügen Sie der Dimension den Parameter alpha_sort hinzu:
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Bei Dimensionen, für die in der Ausgabe viele verschiedene Werte gewünscht sind (wodurch jede Ausgabe mit einer WHEN- oder ELSE-Anweisung definiert werden müsste), oder wenn Sie eine komplexere ELSE-Anweisung implementieren möchten, empfehlen wir die Verwendung einer SQL-CASE WHEN, die im nächsten Abschnitt beschrieben wird.
Weitere Informationen zum Parameter case finden Sie auf der Dokumentationsseite Feldparameter.
SQL CASE WHEN für das Bucketing verwenden
Eine SQL-CASE WHEN-Anweisung wird für komplexeres Bucketing oder für die Implementierung einer differenzierteren CASE WHEN-Anweisung empfohlen.ELSE
So können Sie beispielsweise je nach Zielort einer Bestellung unterschiedliche Bucketing-Methoden verwenden. Mit einer SQL-CASE WHEN-Anweisung können Sie eine zusammengesetzte Bucket-Dimension erstellen, bei der die THEN-Anweisung Dimensionen anstelle von Strings zurückgibt:
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}