このページでは、Service、Ingress、Gateway リソースを使用して Google Kubernetes Engine(GKE)クラスタでのロード バランシングに関連する問題を解決する方法について説明します。
BackendConfig が見つからない
このエラーは、Service のアノテーションで Service ポートの BackendConfig が指定されているにもかかわらず BackendConfig リソースが見つからなかった場合に発生します。
Kubernetes イベントを評価するには、次のコマンドを実行します。
kubectl get event
次の出力例は、BackendConfig が見つからなかったことを示します。
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: error getting BackendConfig for port 80 on service "default/my-service":
no BackendConfig for service port exists
この問題を解決するには、誤った Namespace に BackendConfig リソースが作成されていないことや、Service アノテーションの参照にスペルミスがないことを確認します。
Ingress セキュリティ ポリシーが見つからない
Ingress オブジェクトが作成された後で、セキュリティ ポリシーが LoadBalancer Service と適切に関連付けられていない場合は、Kubernetes イベントを評価して構成ミスがないか調べてください。BackendConfig が存在しないセキュリティ ポリシーを指定している場合は、警告イベントが定期的に発生します。
Kubernetes イベントを評価するには、次のコマンドを実行します。
kubectl get event
次の出力例は、セキュリティ ポリシーが見つからなかったことを示します。
KIND ... SOURCE
Ingress ... loadbalancer-controller
MESSAGE
Error during sync: The given security policy "my-policy" does not exist.
この問題を解決するには、BackendConfig に正しいセキュリティ ポリシー名を指定します。
GKE でワークロードのスケーリング中に発生した NEG 関連の 500 シリーズエラーへの対処
症状:
GKE でプロビジョニングされた NEG をロード バランシングに使用すると、ワークロードのスケールダウン中にサービスで 502 エラーまたは 503 エラーが発生する可能性があります。502 エラーは既存の接続が閉じる前に Pod が終了した場合に発生します。一方、503 エラーは、削除された Pod にトラフィックが転送された場合に発生します。
Gateway、Ingress、スタンドアロン NEG など、NEG を使用する GKE マネージド ロード バランシング プロダクトを使用している場合、この問題はクラスタに影響する可能性があります。ワークロードを頻繁にスケーリングすると、クラスタが影響を受けるリスクが高くなります。
診断:
エンドポイントをドレインして NEG から削除することなく、Kubernetes で Pod を削除すると、500 シリーズエラーが発生します。Pod の終了時に問題が発生しないようにするには、オペレーションの順序を考慮する必要があります。次の図は、BackendService Drain Timeout が設定されておらず、BackendService Drain Timeout が BackendConfig に設定されている場合のシナリオを示しています。
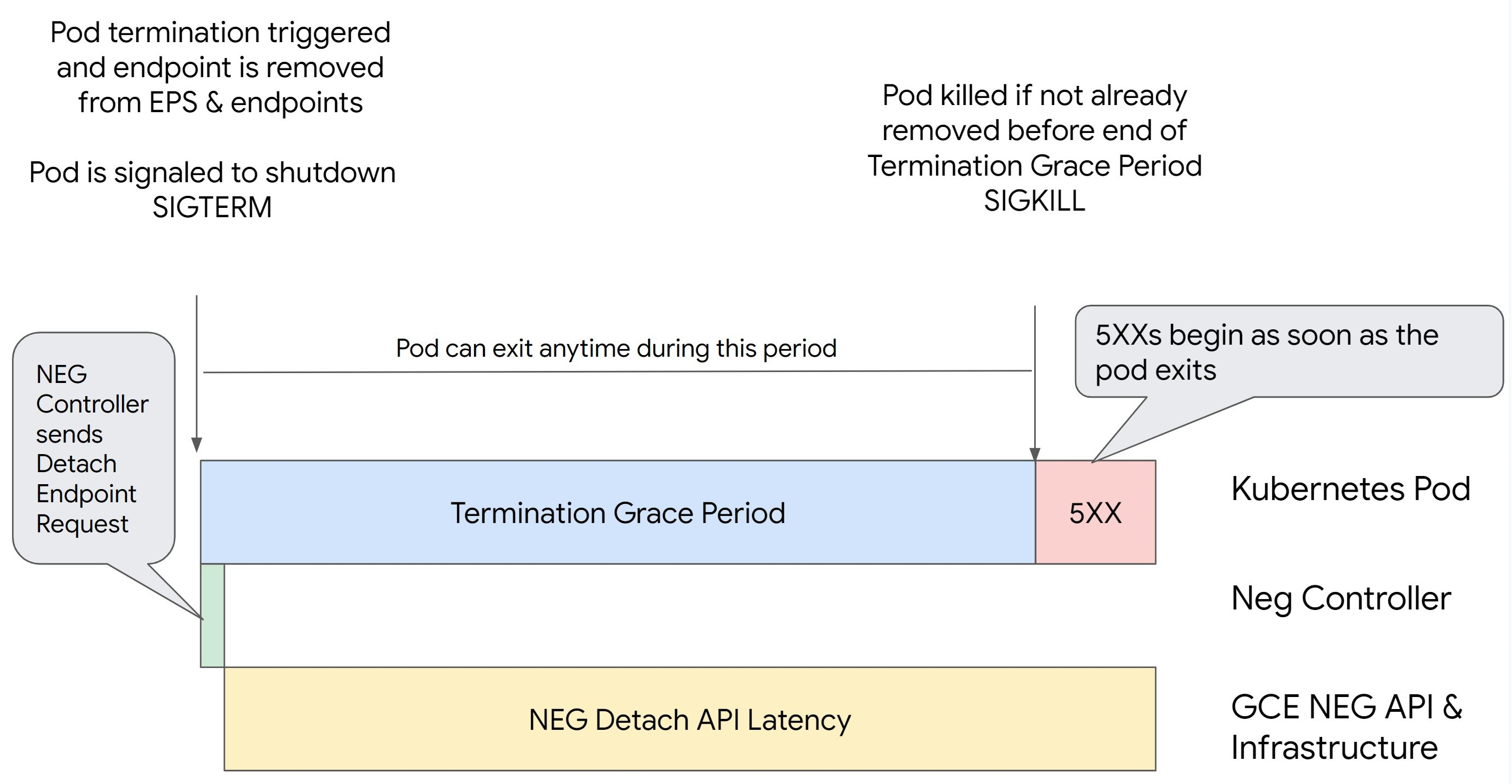
シナリオ 1: BackendService Drain Timeout が設定されていない。
次の図は、BackendService Drain Timeout が設定されていないシナリオを示しています。
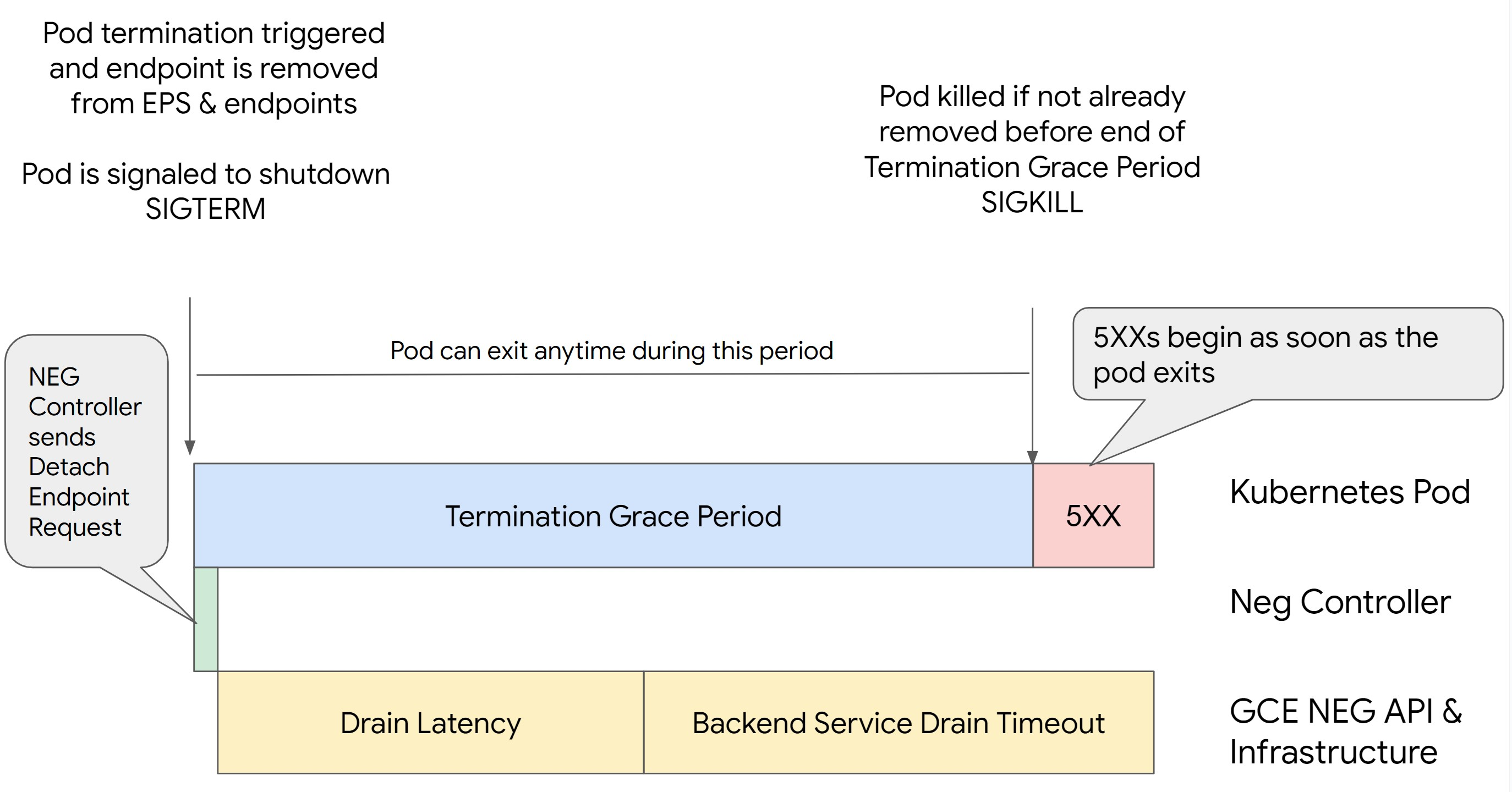
シナリオ 2: BackendService Drain Timeout が設定されている。
次の図は、BackendService Drain Timeout が設定されているシナリオを示しています。
500 シリーズエラーが発生するタイミングは次の要因によって決まります。
NEG API の接続解除レイテンシ: NEG API の接続解除レイテンシは、 Google Cloudで接続解除オペレーションが完了するのにかかる時間です。これは、ロードバランサの種類や特定のゾーンなど、Kubernetes 以外のさまざまな要因の影響を受けます。
ドレイン レイテンシ: ドレイン レイテンシは、ロードバランサがシステムの特定の部分からトラフィックを送信するのに要する時間を表します。ドレインが開始されると、ロードバランサはエンドポイントへの新しいリクエストの送信を停止しますが、ドレインのトリガーにはレイテンシ(ドレイン レイテンシ)があり、Pod が存在しない場合は一時的な 503 エラーが発生する可能性があります。
ヘルスチェックの構成: ヘルスチェックのしきい値の感度を高くすると、接続解除オペレーションが完了していなくてもロードバランサにエンドポイントへのリクエストの送信を停止するように通知できるため、503 エラーの持続を回避できます。
終了猶予期間: 終了猶予期間により、Pod が終了するまでの最大時間が決まります。ただし、終了猶予期間が完了する前に Pod が終了する場合もあります。Pod の存続期間がこの期間よりも長い場合は、この期間の終了時に Pod は強制的に終了します。これは Pod の設定であり、ワークロード定義で構成する必要があります。
考えられる解決策:
このような 5XX エラーを防ぐには、次の設定を適用します。タイムアウト値はあくまでも目安であり、アプリケーションに合わせて調整する必要があります。次のセクションでは、カスタマイズ プロセスについて説明します。
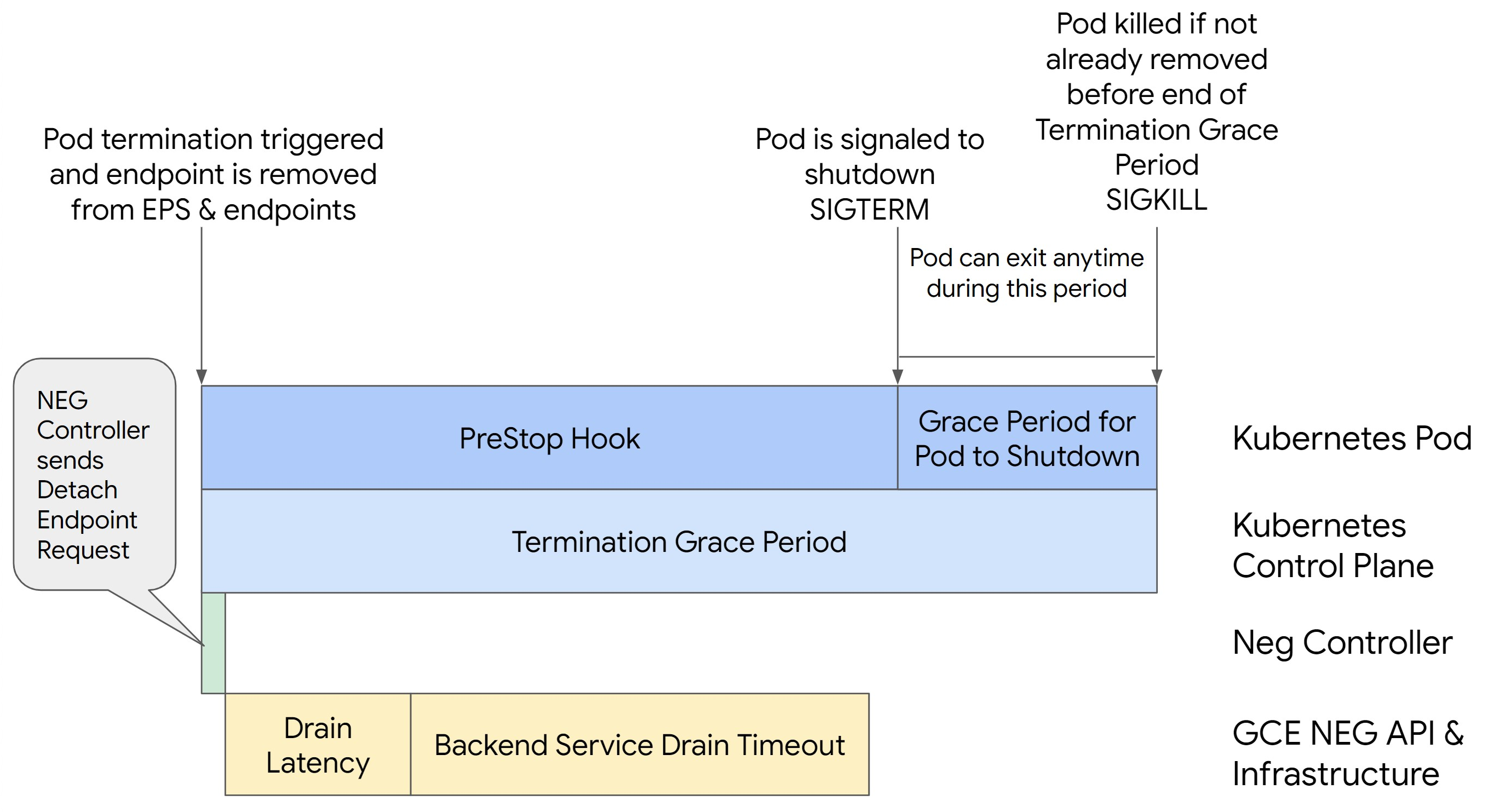
次の図は、preStop フックを使用して Pod を存続させる方法を示しています。
500 シリーズエラーを回避するには、次の操作を行います。
サービスの
BackendService Drain Timeoutを 1 分に設定します。Ingress ユーザーの場合は、BackendConfig でタイムアウトを設定するをご覧ください。
Gateway ユーザーの場合は、GCPBackendPolicy でタイムアウトを構成するをご覧ください。
スタンドアロン NEG を使用して BackendService を直接管理する場合は、Backend Service でタイムアウトを直接設定するをご覧ください。
Pod で
terminationGracePeriodを拡張します。Pod の
terminationGracePeriodSecondsを 3.5 分に設定します。推奨設定と組み合わせると、Pod のエンドポイントが NEG から削除されてから、Pod に 30~45 秒の猶予期間が与えられます。正常なシャットダウンにさらに時間が必要な場合は、猶予期間を延長するか、タイムアウトをカスタマイズするの説明に従ってください。次の Pod マニフェストでは、コネクション ドレインのタイムアウトを 210 秒(3.5 分)に指定しています。
spec: terminationGracePeriodSeconds: 210 containers: - name: my-app ... ...すべてのコンテナに
preStopフックを適用します。preStopフックを適用します。これにより、Pod のエンドポイントがロードバランサでドレインされ、エンドポイントが NEG から削除され、Pod の存続期間が 120 秒に延長されます。spec: containers: - name: my-app ... lifecycle: preStop: exec: command: ["/bin/sh", "-c", "sleep 120s"] ...
タイムアウトをカスタマイズする
Pod の継続性を確保しながら 500 シリーズエラーを防ぐには、エンドポイントが NEG から削除されるまで Pod が存続している必要があります。特に 502 エラーと 503 エラーを防ぐには、タイムアウトと preStop フックを組み合わせて実装することを検討してください。
シャットダウン プロセス中に Pod を長く存続させるには、preStop フックを Pod に追加します。Pod に終了シグナルが送信される前に preStop フックを実行することで、preStop フックを使用して、対応するエンドポイントが NEG から削除されるまで Pod を維持できます。
シャットダウン プロセス中に Pod がアクティブである期間を延長するには、次のように Pod 構成に preStop フックを挿入します。
spec:
containers:
- name: my-app
...
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep <latency time>"]
タイムアウトと関連設定を構成することで、ワークロードのスケールダウン中に Pod が正常にシャットダウンされるように管理できます。タイムアウトは、特定のユースケースに応じて調整できます。最初の段階ではタイムアウトを長めに設定し、その後、必要に応じて短くすることをおすすめします。タイムアウト関連のパラメータと preStop フックを次のように構成することで、タイムアウトをカスタマイズできます。
Backend Service のドレイン タイムアウト
デフォルトでは、Backend Service Drain Timeout パラメータは設定されておらず、効果はありません。Backend Service Drain Timeout パラメータを設定して有効にすると、ロードバランサはエンドポイントへの新しいリクエストの転送を停止し、タイムアウトを待ってから既存の接続を終了します。
Backend Service Drain Timeout パラメータを設定するには、BackendConfig(Ingress の場合)または GCPBackendPolicy(Gateway の場合)を使用します。スタンドアロン NEG の場合は、BackendService に手動で設定します。タイムアウトは、リクエストの処理時間の 1.5~2 倍にする必要があります。これにより、ドレインが開始される直前にリクエストが到着したときに、タイムアウトの前にリクエストが完了するようになります。Backend Service Drain Timeout パラメータを 0 より大きい値に設定すると、削除が予定されているエンドポイントに新しいリクエストが送信されないため、503 エラーが軽減されます。このタイムアウトを有効にするには、preStop フックと併用し、ドレインが発生している間も Pod がアクティブな状態を維持できるようにする必要があります。この組み合わせを使用しないと、完了しなかった既存のリクエストは 502 エラーを受け取ります。
preStop フックの実行時間
preStop フックには、ドレイン レイテンシとバックエンド サービスのドレイン タイムアウトの両方が完了するまで Pod のシャットダウンを遅らせるのに十分な値を設定する必要があります。これにより、Pod がシャットダウンされる前に適切なコネクション ドレインと NEG からのエンドポイントの削除が確実に行われるようになります。
最適な結果を得るには、preStop フックの実行時間が Backend Service Drain Timeout とドレイン レイテンシの合計と同じか、それよりも長くなるようにします。
理想的な preStop フックの実行時間は、次の式で計算できます。
preStop hook execution time >= BACKEND_SERVICE_DRAIN_TIMEOUT + DRAIN_LATENCY
次のように置き換えます。
BACKEND_SERVICE_DRAIN_TIMEOUT:Backend Service Drain Timeoutに構成した時間。DRAIN_LATENCY: ドレイン レイテンシの推定時間。推定時間として 1 分を使用することをおすすめします。
500 エラーが引き続き発生する場合は、合計の発生時間を見積もり、その時間の 2 倍をドレイン レイテンシの推定値に追加します。これにより、Pod がサービスから削除される前に、正常にドレインするための十分な時間が確保されます。特定のユースケースでこの値が長すぎる場合は、値を調整します。
Cloud Audit Logs で、Pod から削除されたときのタイムスタンプと、エンドポイントが NEG から削除されたときのタイムスタンプを調べることで、タイミングを見積もることもできます。
終了猶予期間パラメータ
preStop フックが終了し、Pod が正常なシャットダウンを完了するのに十分な時間を確保できるように、terminationGracePeriod パラメータを構成する必要があります。
明示的に設定されていない場合、terminationGracePeriod はデフォルトの 30 秒になります。最適な terminationGracePeriod は次の式で計算できます。
terminationGracePeriod >= preStop hook time + Pod shutdown time
Pod の構成で terminationGracePeriod を定義するには、次のようにします。
spec:
terminationGracePeriodSeconds: <terminationGracePeriod>
containers:
- name: my-app
...
...
内部 Ingress リソースの作成時に NEG が見つからない
GKE で内部 Ingress を作成すると、次のエラーが発生することがあります。
Error syncing: error running backend syncing routine: googleapi: Error 404: The resource 'projects/PROJECT_ID/zones/ZONE/networkEndpointGroups/NEG' was not found, notFound
このエラーは、内部アプリケーション ロードバランサ用の Ingress がバックエンドとしてネットワーク エンドポイント グループ(NEG)を必要とするために発生します。
共有 VPC 環境またはネットワーク ポリシーが有効なクラスタでは、アノテーション cloud.google.com/neg: '{"ingress": true}' を Service マニフェストに追加します。
504 Gateway Timeout: アップストリーム リクエストのタイムアウト
GKE の内部 Ingress から Service にアクセスすると、次のエラーが発生することがあります。
HTTP/1.1 504 Gateway Timeout
content-length: 24
content-type: text/plain
upsteam request timeout
このエラーは、内部アプリケーション ロードバランサに送信されたトラフィックが、プロキシ専用サブネット範囲内の Envoy プロキシによってプロキシされるために発生します。
プロキシ専用サブネット範囲からのトラフィックを許可するには、Service の targetPort でファイアウォール ルールを作成します。
エラー 400: フィールド「resource.target」の値が無効です
GKE の内部 Ingress から Service にアクセスすると、次のエラーが発生することがあります。
Error syncing:LB_NAME does not exist: googleapi: Error 400: Invalid value for field 'resource.target': 'https://www.googleapis.com/compute/v1/projects/PROJECT_NAME/regions/REGION_NAME/targetHttpProxies/LB_NAME. A reserved and active subnetwork is required in the same region and VPC as the forwarding rule.
この問題を解決するには、プロキシ専用サブネットを作成します。
同期中のエラー: ロードバランサ同期ルーチンの実行中のエラー: ロードバランサが存在しません
GKE コントロール プレーンをアップグレードするか、Ingress オブジェクトを変更すると、次のいずれかのエラーが発生する可能性があります。
"Error during sync: error running load balancer syncing routine: loadbalancer
INGRESS_NAME does not exist: invalid ingress frontend configuration, please
check your usage of the 'kubernetes.io/ingress.allow-http' annotation."
または
Error during sync: error running load balancer syncing routine: loadbalancer LOAD_BALANCER_NAME does not exist:
googleapi: Error 400: Invalid value for field 'resource.IPAddress':'INGRESS_VIP'. Specified IP address is in-use and would result in a conflict., invalid
これらの分析情報を解決するには、次のことを試してください。
- Ingress マニフェストの
tlsセクションにhostsフィールドを追加してから、Ingress を削除します。GKE が未使用の Ingress リソースを削除するまで 5 分待ちます。その後、Ingress を再作成します。詳細については、Ingress オブジェクトの hosts フィールドをご覧ください。 - Ingress に加えた変更を元に戻します。次に、アノテーションまたは Kubernetes Secret を使用して証明書を追加します。
外部 Ingress により HTTP 502 エラーが発生する
外部 Ingress リソースの HTTP 502 エラーのトラブルシューティングを行うには、次のガイダンスに従ってください。
- Ingress によって参照される各 GKE Service に関連付けられている各バックエンド サービスのログを有効にします。
- ステータスの詳細を使用して、HTTP 502 レスポンスの原因を特定します。バックエンドからの HTTP 502 レスポンスを示すステータスの詳細には、ロードバランサではなく、処理 Pod 内でのトラブルシューティングが必要です。
非マネージド インスタンス グループ
外部 Ingress が非マネージド インスタンス グループ バックエンドを使用している場合、外部 Ingress リソースで HTTP 502 エラーが発生することがあります。この問題は、次のすべての条件が満たされている場合に発生します。
- クラスターでは、すべてのノードプール内に多数のノードが含まれています。
- Ingress によって参照される 1 つ以上の Service の処理 Pod が、少数のノードにのみ配置されています。
- Ingress が参照する Service が
externalTrafficPolicy: Localを使用します。
外部 Ingress が非マネージド インスタンス グループのバックエンドを使用しているかどうかを判断するには、次の操作を行います。
Google Cloud コンソールの [Ingress] ページに移動します。
外部 Ingress の名前をクリックします。
ロードバランサの名前をクリックします。ロード バランシングの詳細ページが表示されます。
[バックエンド サービス] セクションの表で、外部 Ingress が NEG またはインスタンス グループのどちらを使用しているかを確認します。
この問題を解決するには、次のいずれかの解決策を使用します。
- VPC ネイティブ クラスタを使用します。
- 外部 Ingress が参照する Service ごとに
externalTrafficPolicy: Clusterを使用します。この解決策では、パケットの送信元で元のクライアント IP アドレスが失われます。 node.kubernetes.io/exclude-from-external-load-balancers=trueアノテーションを使用します。クラスタ内の外部 Ingress またはLoadBalancerService によって参照される Service の処理 Pod を実行していないノードまたはノードプールに、アノテーションを追加します。
ロードバランサのログを使用してトラブルシューティングを行う
内部パススルー ネットワーク ロードバランサのログと外部パススルー ネットワーク ロードバランサのログを使用して、ロードバランサに関する問題のトラブルシューティングを行い、ロードバランサから GKE リソースへのトラフィックを関連付けることができます。
ログは接続ごとに集約され、ほぼリアルタイムでエクスポートされます。ログは、LoadBalancer Service のデータパスに関連する GKE ノードごとに、上り(内向き)トラフィックと下り(外向き)トラフィックの両方に対して生成されます。ログエントリには、次のような GKE リソースの追加フィールドが含まれます。
- クラスタ名
- クラスタのロケーション
- サービス名
- サービスの Namespace
- Pod 名
- Pod の Namespace
料金
ログの使用に追加料金はかかりません。ログの取り込み方法に基づいて、Cloud Logging、BigQuery、または Pub/Sub の標準料金が適用されます。ログを有効にしても、ロードバランサのパフォーマンスに影響はありません。
診断ツールを使用してトラブルシューティングを行う
check-gke-ingress 診断ツールは、一般的な構成の間違いについて Ingress リソースを検査します。check-gke-ingress ツールは次の方法で使用できます。
- クラスタで
gcpdiagコマンドライン ツールを実行します。Ingress の結果がチェックルールgke/ERR/2023_004セクションに表示されます。 check-gke-ingressツールを単独で使用するか、または check-gke-ingress の手順に沿って kubectl プラグインとして使用します。
次のステップ
このドキュメントで問題を解決できない場合は、サポートを受けるで、次のトピックに関するアドバイスなど、詳細なヘルプをご覧ください。
- Cloud カスタマーケアに問い合わせて、サポートケースを登録する。
- StackOverflow で質問する、
google-kubernetes-engineタグを使用して類似の問題を検索するなどして、コミュニティからサポートを受ける。#kubernetes-engineSlack チャネルに参加して、コミュニティ サポートを利用することもできます。 - 公開バグトラッカーを使用して、バグの報告や機能リクエストの登録を行う。