A Entrada de vários clusters é um controlador hospedado na nuvem para clusters do Google Kubernetes Engine (GKE). É um serviço hospedado pelo Google compatível com a implantação de recursos de balanceamento de carga compartilhados entre clusters e regiões. Para implantar a entrada de vários clusters em vários clusters, conclua Como configurar a entrada de vários clusters e consulte Como implantar a entrada em vários clusters.
Para uma comparação detalhada entre Ingress de vários clusters (MCI), Gateway de vários clusters (MCG) e balanceador de carga com grupos de endpoints de rede independentes (LB e NEGs independentes), consulte Escolher sua API de balanceamento de carga de vários clusters para o GKE.
Rede de vários clusters
Muitos fatores impulsionam as topologias de vários clusters, incluindo a proximidade do usuário para apps, alta disponibilidade de cluster e regional, segurança e separação organizacional, migração de clusters e localidade de dados. Esses casos de uso raramente são isolados. À medida que os motivos para vários clusters aumentam, a necessidade de uma plataforma de vários clusters formal e produtiva se torna mais urgente.
A entrada de vários clusters foi projetada para atender às necessidades de balanceamento de carga de ambientes de vários clusters e multirregionais. É um controlador para o balanceador de carga HTTP(S) externo que fornece entrada para o tráfego proveniente da Internet em um ou mais clusters.
O suporte a vários clusters da entrada atende a muitos casos de uso, inclusive:
- Um IP virtual (VIP, na sigla em inglês) único e consistente para um app, independentemente de onde o app seja implantado globalmente
- Disponibilidade multirregional e de vários clusters por meio de verificação de integridade e failover de tráfego
- Roteamento por proximidade por meio de VIPs Anycast públicos para baixa latência do cliente
- Migração de cluster transparente para upgrades ou recriações de cluster.
Cotas padrão
A entrada de vários clusters tem as seguintes cotas padrão:
- Para ver detalhes sobre os limites de membros em frotas, consulte Cotas de gerenciamento de frotas. Para saber quantos membros são permitidos em uma frota.
- 100 recursos
MultiClusterIngresse 100 recursosMultiClusterServicepor projeto. É possível criar até 100 recursosMultiClusterIngresse 100 recursosMultiClusterServiceem um cluster de configuração para qualquer número de clusters de back-end até o máximo de clusters por projeto.
Preços e avaliações
Para saber mais sobre os preços da entrada de vários clusters, consulte Preços da entrada de vários clusters.
Como a entrada de vários clusters funciona
O Ingress de vários clusters usa a arquitetura do balanceador de carga de aplicativo externo global. O balanceador de carga de aplicativo externo global é um balanceador de carga distribuído globalmente com proxies implantados em mais de 100 pontos de presença (PoPs, na sigla em inglês) do Google em todo o mundo. Esses proxies, chamados de Google Front Ends (GFEs, na sigla em inglês), ficam na borda da rede do Google, posicionados perto dos clientes. O Ingress de vários clusters cria balanceadores de carga de aplicativo externos no nível Premium. Esses balanceadores de carga usam endereços IP externos globais anunciados usando anycast. As solicitações são exibidas por GFEs e pelo cluster mais próximo do cliente. O tráfego da Internet vai para o PoP do Google mais próximo e usa o backbone do Google para chegar a um cluster do GKE. Essa configuração de balanceamento de carga resulta em latência menor do cliente para o GFE. É possível reduzir a latência entre os clusters do GKE e os GFEs. Basta executar os clusters do GKE em regiões mais próximas aos seus clientes.
O encerramento de conexões HTTP e HTTPS no perímetro permite que o balanceador de carga do Google decida para onde direcionar o tráfego determinando a disponibilidade do back-end antes que o tráfego entre em um data center ou região. Isso dá ao tráfego o caminho mais eficiente do cliente para o back-end, considerando a integridade e a capacidade dos back-ends.
A entrada de vários clusters é um controlador da entrada que programa o balanceador de carga
HTTP(S) externo usando grupos de endpoints da rede (NEGs, na sigla em inglês).
Quando você cria um recurso MultiClusterIngress, o GKE implanta
recursos do balanceador de carga do Compute Engine e configura os pods
adequados nos clusters como back-ends. Os NEGs são usados para rastrear os endpoints do pod dinamicamente para que o balanceador de carga do Google tenha o conjunto certo de back-ends íntegros.

Conforme você implanta aplicativos em clusters no GKE, a entrada de vários clusters garante que o balanceador de carga esteja em sincronia com os eventos que ocorrem no cluster:
- Uma implantação é criada com os rótulos correspondentes à direita.
- O processo de um pod morre e falha na verificação de integridade.
- Um cluster é removido do pool de back-ends.
A entrada de vários clusters atualiza o balanceador de carga, mantendo-o consistente com o ambiente e o estado pretendido dos recursos do Kubernetes.
Arquitetura da entrada de vários clusters
A entrada de vários clusters usa um servidor centralizado da API Kubernetes para implantar a entrada
de vários clusters. Esse servidor de API centralizado é chamado de cluster de configuração. Qualquer cluster do GKE pode atuar como o cluster de configuração. O cluster de configuração usa dois tipos de recursos personalizados: MultiClusterIngress e MultiClusterService.
Ao implantar esses recursos no cluster de configuração, o controlador de Entrada de vários
clusters implanta balanceadores de carga em vários clusters.
Os conceitos e componentes a seguir compõem a entrada de vários clusters:
Controlador de Entrada de vários clusters: um plano de controle distribuído globalmente que é executado como um serviço fora dos clusters. Isso permite que o ciclo de vida e as operações do controlador sejam independentes dos clusters do GKE.
Cluster de configuração: é um cluster do GKE escolhido em execução no Google Cloud em que os recursos
MultiClusterIngresseMultiClusterServicesão implantados. Esse é um ponto de controle centralizado para esses recursos de vários clusters. Esses recursos de vários clusters existem e são acessíveis por meio de uma API lógica para manter a consistência em todos os clusters. O controlador de entrada observa o cluster de configuração e reconcilia a infraestrutura de balanceamento de carga.Uma frota permite agrupar e normalizar logicamente clusters do GKE, facilitando a administração da infraestrutura e permitindo o uso de recursos de vários clusters, como a Entrada em vários clusters. Saiba mais sobre os benefícios dos frotas e como criá-los na documentação de gerenciamento de frota. Um cluster só pode ser membro de uma frota.
Cluster de membros: os clusters registrados em uma frota são chamados de clusters de membros. Os clusters de membro na frota compreendem o escopo completo dos back-ends que a entrada de vários clusters conhece. A visualização de gerenciamento de cluster do Google Kubernetes Engine fornece um console seguro para ver o estado de todos os clusters registrados.

Fluxo de trabalho de implantação
As etapas a seguir ilustram um fluxo de trabalho de alto nível para usar a entrada de vários clusters em vários clusters.
Registrar clusters do GKE em uma frota no projeto escolhido.
Configure um cluster do GKE como o cluster de configuração central. Esse cluster pode ser um plano de controle dedicado ou executar outras cargas de trabalho.
Implante aplicativos nos clusters do GKE em que eles precisam ser executados.
Implante um ou mais recursos
MultiClusterServiceno cluster de configuração com correspondências de rótulo e cluster para selecionar clusters, namespaces e pods considerados back-ends para um determinado serviço. Isso cria os NEGs no Compute Engine, que começa a registrar e gerenciar os endpoints do serviço.Implante um recurso
MultiClusterIngressno cluster de configuração que referencia um ou mais recursosMultiClusterServicecomo back-ends para o balanceador de carga. Isso implanta os recursos externos do balanceador de carga do Compute Engine e expõe os endpoints em clusters por meio de um único balanceador de carga VIP.
Conceitos do Ingress
A entrada de vários clusters usa um servidor centralizado da API Kubernetes para implantar a entrada em vários clusters. As seções a seguir descrevem o modelo de recursos da entrada de vários clusters, como implantar a entrada e conceitos importantes para gerenciar esse plano de controle de rede altamente disponível.
Recursos MultiClusterService
Um MultiClusterService é um recurso personalizado usado pela entrada de vários clusters
para representar serviços de compartilhamento nos clusters. Um recurso MultiClusterService
seleciona pods, semelhante ao recurso Serviço, mas um
MultiClusterService também pode selecionar rótulos e clusters. O pool de clusters que um
MultiClusterService seleciona é chamado de clusters de membro. Todos os
clusters registrados na frota são clusters de membros.
Um MultiClusterService existe apenas no cluster de configuração e não encaminha
nada como um ClusterIP, LoadBalancer ou serviço NodePort. Em vez disso,
ele permite que o controlador de entrada de vários clusters se refira a um recurso distribuído singular.
O manifesto de exemplo abaixo descreve um MultiClusterService para um
aplicativo chamado foo:
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Esse manifesto implanta um serviço em todos os clusters de membros com o seletor app:
foo. Se houver pods app: foo nesse cluster, esses endereços IP de pod serão
adicionados como back-ends para MultiClusterIngress.
O mci-zone1-svc-j726y6p1lilewtu7 a seguir é um serviço derivado
gerado em um dos clusters de destino. Esse serviço cria um NEG que rastreia endpoints de pods para todos os pods que correspondem ao seletor de rótulos especificado nesse cluster. Um serviço derivado e o NEG existirão em cada cluster de destino para cada
MultiClusterService (a menos que você use seletores de cluster). Se não houver pods correspondentes
em um cluster de destino, o serviço e o NEG estarão vazios. Os serviços
derivados são totalmente gerenciados pelo MultiClusterService e não são gerenciados diretamente pelos
usuários.
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/neg: '{"exposed_ports":{"8080":{}}}'
cloud.google.com/neg-status: '{"network_endpoint_groups":{"8080":"k8s1-a6b112b6-default-mci-zone1-svc-j726y6p1lilewt-808-e86163b5"},"zones":["us-central1-a"]}'
networking.gke.io/multiclusterservice-parent: '{"Namespace":"default","Name":"zone1"}'
name: mci-zone1-svc-j726y6p1lilewtu7
namespace: blue
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
Algumas observações sobre o serviço derivado:
- A função dele é um agrupamento lógico de endpoints como back-ends para a entrada de vários clusters.
- Ele gerencia o ciclo de vida do NEG para um determinado cluster e aplicativo.
- Ele é criado como um serviço sem comando. Apenas os campos
SelectorePortssão transferidos doMultiClusterServicepara o serviço derivado. - O controlador de Entrada gerencia o próprio ciclo de vida.
Recurso MultiClusterIngress
Um recurso MultiClusterIngress se comporta de maneira idêntica ao
recurso principal do Ingress. Os dois têm a mesma especificação para definir hosts, caminhos, encerramento de protocolo e back-ends.
O manifesto a seguir descreve um MultiClusterIngress que encaminha o tráfego para
os back-ends foo e bar, dependendo dos cabeçalhos do host HTTP:
apiVersion: networking.gke.io/v1
kind: MultiClusterIngress
metadata:
name: foobar-ingress
namespace: blue
spec:
template:
spec:
backend:
serviceName: default-backend
servicePort: 80
rules:
- host: foo.example.com
backend:
serviceName: foo
servicePort: 80
- host: bar.example.com
backend:
serviceName: bar
servicePort: 80
Esse recurso MultiClusterIngress faz a correspondência do tráfego com o endereço IP virtual em
foo.example.com e bar.example.com ao enviar esse tráfego para os
recursos MultiClusterService chamados foo e bar. Essa MultiClusterIngress
tem um back-end padrão que corresponde a todo o outro tráfego e o envia
para o MultiClusterService de back-end padrão.
O diagrama a seguir mostra como o tráfego flui de uma entrada para um cluster:

No diagrama, há dois clusters, gke-us e gke-eu. O tráfego flui
de foo.example.com para os pods que têm o rótulo app:foo em ambos os
clusters. De bar.example.com, o tráfego flui para os pods que têm o rótulo
app:bar em ambos os clusters.
Recursos de entrada em clusters
O cluster de configuração é o único que pode ter recursos
MultiClusterIngress e MultiClusterService. Cada cluster de destino que tem pods que correspondem
aos seletores de rótulo MultiClusterService também terá um serviço derivado
correspondente programado neles. Se um cluster não for selecionado explicitamente por um
MultiClusterService, um serviço derivado correspondente não será criado
nesse cluster.

Semelhança de namespace
A semelhança de namespace é uma propriedade de clusters do Kubernetes em que um namespace se estende nos clusters e é considerado o mesmo namespace.
No diagrama a seguir, o namespace blue existe nos clusters do GKE gke-cfg, gke-eu e gke-us. A semelhança de namespace considera
o namespace blue como igual em todos os clusters. Isso significa que um determinado usuário
tem os mesmos privilégios para recursos no namespace blue em cada cluster.
A semelhança de namespace também significa que os recursos do serviço com o mesmo nome em vários
clusters no namespace blue são considerados como o mesmo serviço.
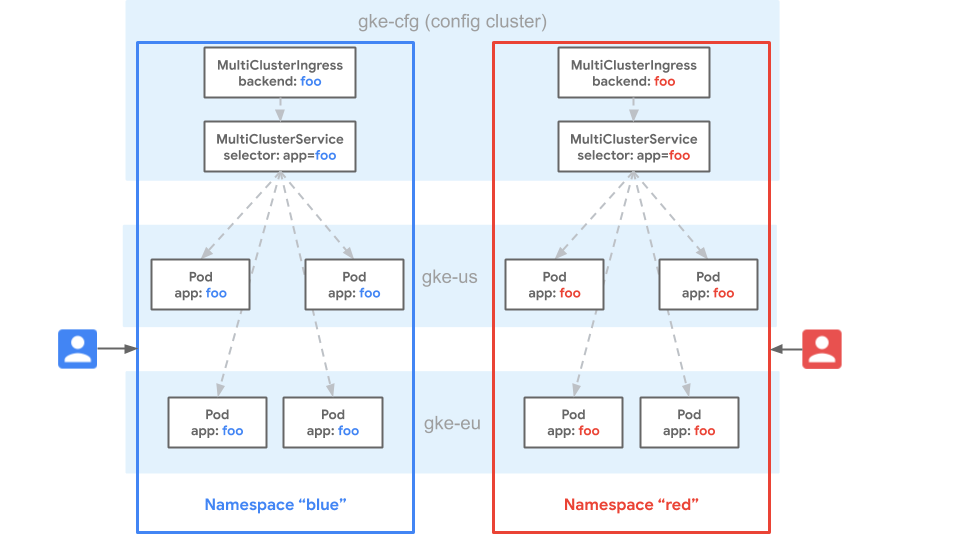
O gateway trata o serviço como um único pool de endpoints nos três
clusters. Como as rotas e os recursos e MultiClusterIngress podem encaminhar apenas para
serviços dentro do mesmo namespace, isso fornece multilocação consistente para
configuração em todos os clusters da frota. As frotas oferecem um alto grau de
portabilidade, já que os recursos podem ser implantados ou movimentados nos clusters sem qualquer
alteração na configuração. A implantação no mesmo namespace da frota fornece
consistência nos clusters.
Considere os seguintes princípios de design para a semelhança de namespace:
- os namespaces para finalidades diferentes não precisam ter o mesmo nome nos clusters;
- os namespaces precisam ser reservados explicitamente alocando um namespace, ou implicitamente, utilizando políticas fora da banda para equipes e clusters em uma frota;
- Os namespaces para a mesma finalidade nos clusters precisam compartilhar o mesmo nome.
- a permissão do usuário para namespaces em clusters precisa ser rigorosamente controlada para impedir o acesso não autorizado;
- não use o namespace padrão ou namespaces genéricos como "prod" ou "dev" para a implantação normal do aplicativo. É muito fácil para os usuários implantar recursos no namespace padrão acidentalmente e violar os princípios de segmentação dos namespaces;
- o mesmo namespace precisa ser criado em clusters sempre que uma determinada equipe ou grupo de usuários precisar implantar recursos.
Design do cluster de configuração
O cluster de configuração da entrada de vários clusters é um único cluster do GKE
que hospeda os recursos MultiClusterIngress e MultiClusterService e atua como
o único ponto de controle da Entrada
na frota de clusters do GKE de destino. Você escolhe o
cluster de configuração ao ativar a entrada de vários clusters. É possível escolher qualquer cluster do GKE como o cluster de configuração e alterá-lo a qualquer momento.
Disponibilidade do cluster de configuração
Como o cluster de configuração é um ponto de controle único, os recursos da entrada de vários clusters
não poderão ser criados ou atualizados se a API do cluster de configuração não estiver disponível. Os balanceadores
de carga e o tráfego veiculados por eles não serão afetados por uma interrupção
do cluster de configuração, mas as alterações nos recursos MultiClusterIngress e MultiClusterService
não serão reconciliadas pelo controlador até que esteja disponível novamente.
Considere os seguintes princípios de design para clusters de configuração:
- O cluster de configuração precisa ser escolhido de modo que esteja altamente disponível. Os clusters regionais têm preferência sobre os clusters zonais.
- Para ativar a Entrada de vários clusters, o cluster de configuração não precisa ser
um cluster dedicado. O cluster de configuração pode hospedar cargas de trabalho administrativas
ou até mesmo de aplicativos, embora seja necessário garantir que os aplicativos hospedados não
afetem a disponibilidade do servidor da API do cluster de configuração. O cluster
de configuração pode ser um cluster de destino que hospeda back-ends para recursos
MultiClusterService. No entanto, se forem necessárias precauções extras, o cluster de configuração também poderá ser excluído como um back-end fazendo a seleção de cluster. - Os clusters de configuração precisam ter todos os namespaces usados pelos back-ends
de cluster de destino. Um recurso
MultiClusterServicesó pode referir-se a pods no mesmo namespace em clusters para que o namespace precise estar presente no cluster de configuração. - Os usuários que implantam o Ingress em vários clusters precisam ter acesso ao
cluster de configuração para implantar os recursos
MultiClusterIngresseMultiClusterService. No entanto, os usuários só precisam ter acesso aos namespaces que têm permissão para usar.
Como selecionar e migrar o cluster de configuração
Escolha o cluster de configuração ao ativar a entrada de vários clusters. Qualquer cluster
membro de uma frota pode ser selecionado como o cluster de configuração. Atualize o cluster de configuração a qualquer momento, mas tenha cuidado para garantir que ele não causará interrupções. O controlador de Entrada reconciliará todos os recursos existentes no
cluster de configuração. Ao migrar o cluster de configuração
do atual para o próximo, os recursos MultiClusterIngress e
MultiClusterService precisam ser idênticos.
Se os recursos não forem idênticos, os balanceadores de carga do Compute Engine poderão ser atualizados ou destruídos após a atualização do cluster de configuração.
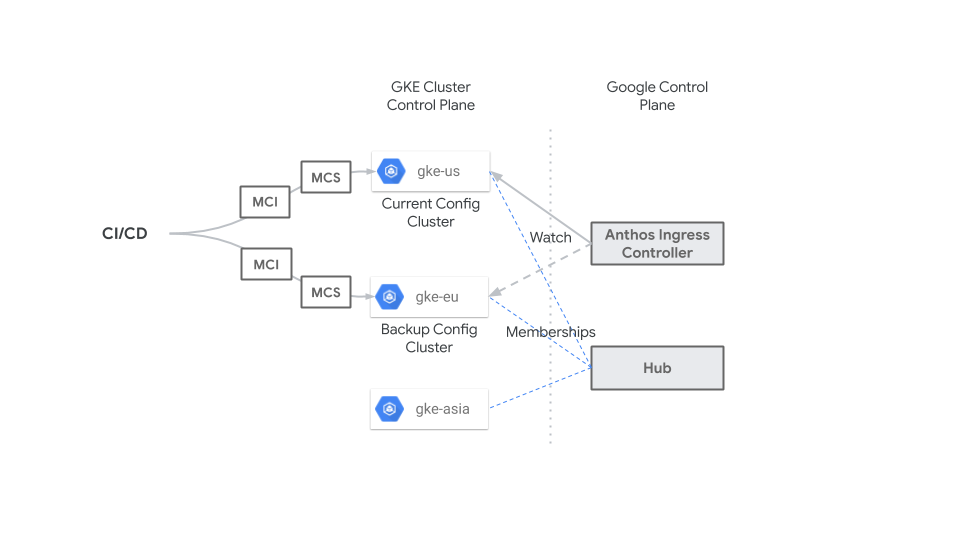
O diagrama a seguir mostra como um sistema de CI/CD centralizado aplica
recursos MultiClusterIngress e MultiClusterService ao
servidor da API GKE para o cluster de configuração (gke-us)
e um cluster de backup (gke-eu) o tempo todo para que os recursos sejam idênticos
nos dois clusters. É possível alterar o cluster de configuração para emergências ou
tempo de inatividade planejado a qualquer momento sem qualquer impacto, porque os recursos MultiClusterIngress e MultiClusterService
são idênticos.
Seleção de cluster
Os recursos MultiClusterService podem selecionar clusters. Por padrão, o
controlador programa um serviço derivado em cada cluster de destino. Se você não quiser
um serviço derivado em cada cluster de destino, defina uma lista de
clusters usando o campo spec.clusters no manifesto MultiClusterService.
Talvez você queira definir uma lista de clusters se precisar:
- isolar o cluster de configuração para impedir que recursos
MultiClusterServicesejam selecionados no cluster de configuração; - controlar o tráfego entre clusters para a migração de aplicativos;
- encaminhar para back-ends de aplicativos que existem apenas em um subconjunto de clusters;
- usar um único endereço IP virtual HTTP(S) para encaminhar para back-ends que estão em clusters diferentes.
É necessário garantir que os clusters de membro dentro da mesma frota e região tenham nomes exclusivos para evitar conflitos de nomenclatura.
Para saber como configurar a seleção de cluster, consulte Como configurar a Entrada de vários clusters.
O manifesto a seguir descreve um MultiClusterService que tem um campo clusters que referencia europe-west1-c/gke-eu e
asia-northeast1-a/gke-asia:
apiVersion: networking.gke.io/v1
kind: MultiClusterService
metadata:
name: foo
namespace: blue
spec:
template:
spec:
selector:
app: foo
ports:
- name: web
protocol: TCP
port: 80
targetPort: 80
clusters:
- link: "europe-west1-c/gke-eu"
- link: "asia-northeast1-a/gke-asia-1"
Esse manifesto especifica que os pods com os rótulos correspondentes nos clusters gke-asia e gke-eu podem ser incluídos como back-ends para o MultiClusterIngress.
Todos os outros clusters são excluídos, mesmo que tenham pods com o rótulo
app: foo.
O diagrama a seguir mostra um exemplo de configuração MultiClusterService usando
o manifesto anterior:
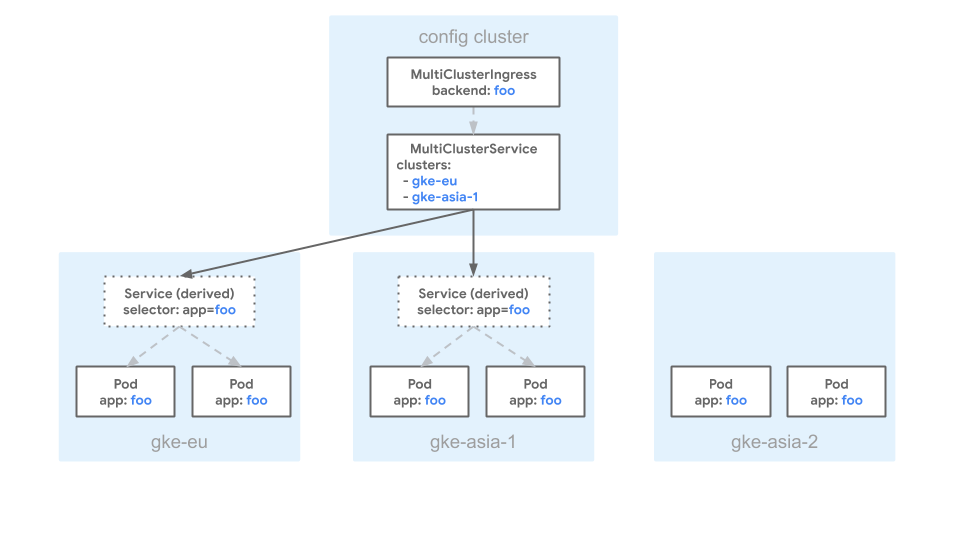
No diagrama, há três clusters: gke-eu, gke-asia-1 e
gke-asia-2. O cluster gke-asia-2 não está incluído como back-end, mesmo que
haja pods com rótulos correspondentes, porque o cluster não está incluído na
lista spec.clusters de manifesto. O cluster não recebe tráfego para
manutenção ou outras operações.
A seguir
- Saiba como configurar a Entrada de vários clusters.
- Saiba mais sobre Como implantar gateways de vários clusters.
- Saiba mais sobre Como implantar a Entrada de vários clusters.
- Implemente a entrada em vários clusters para balanceamento de carga externo.