Questo documento illustra le strategie di disaster recovery (DR) per Microsoft SQL Server per architetti e responsabili tecnici incaricati di progettare e implementare il disaster recovery su Google Cloud.
I database possono non essere disponibili per vari motivi, ad esempio guasti hardware o della rete. Per fornire accesso continuo al database in caso di errori, viene mantenuto un database secondario che è una replica di un database principale. Avere il database secondario in una località diversa aumenta le probabilità che sia disponibile quando il database principale non è disponibile.
Se il database principale non è disponibile, l'app mission-critical si connette a un database secondario, continuando dall'ultimo stato dei dati coerenti noto per fornire servizi agli utenti con tempi di inattività minimi o nulli.
La procedura per rendere disponibile un database secondario in caso di guasto del database principale è chiamata disaster recovery (DR) del database. Il database secondario si riprende dalla mancata disponibilità del database principale. Idealmente, il database secondario ha lo stesso stato coerente del database principale quando non è disponibile o manca solo un insieme minimo di transazioni recenti del database principale.
Il DR di un database è una funzionalità essenziale per i clienti aziendali. Il fattore principale è la continuità operativa per le app mission-critical. Ad esempio, un'app mission-critical genera entrate (e-commerce), fornisce servizi affidabili e continui (gestione di voli o impianti di produzione di energia) o supporta funzionalità salvavita (monitoraggio dei pazienti). In tutti questi esempi, è di fondamentale importanza che l'app sia disponibile continuamente perché è considerata mission-critical.
La maggior parte dei sistemi di gestione di database fornisce funzionalità di disaster recovery, incluso Microsoft SQL Server. Questo documento sull'architettura illustra come le funzionalità di DR fornite da SQL Server vengono implementate nel contesto di Google Cloud.
Terminologia
Le sezioni seguenti spiegano i termini utilizzati in tutto il documento.
Architettura generale di DR
Il seguente diagramma illustra la topologia generale dell'architettura di DR.
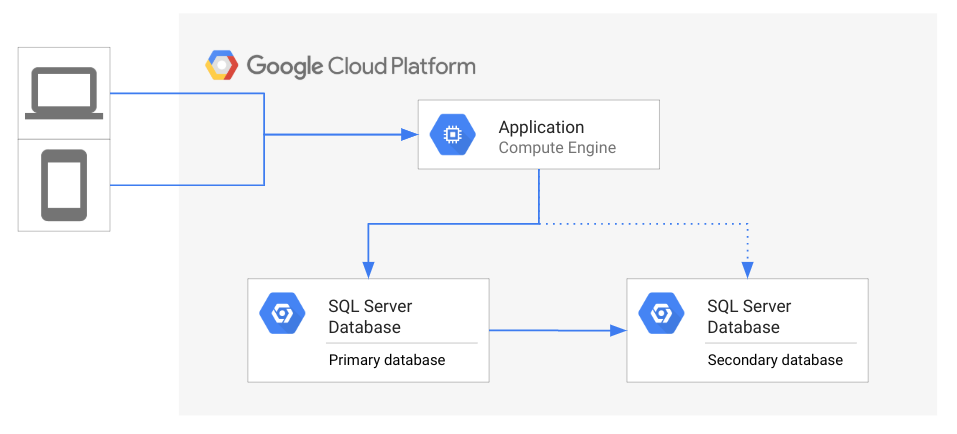
Nel diagramma precedente, un'app accede a un database principale mentre un database secondario è in attesa ed esegue il mirroring dello stato del database principale. I clienti accedono all'app che viene eseguita su Google Cloud.
Se il database principale non è disponibile, gli amministratori del database o il team operativo devono decidere di avviare il processo di disaster recovery. Se viene avviato il disaster recovery del database, l'app viene ricollegata al database secondario. Una volta collegata, l'app può tornare a fornire servizi ai clienti. In una situazione ideale, l'app è disponibile nel database secondario il prima possibile, quindi i client potrebbero persino non riscontrare un'interruzione del servizio. Un'alternativa è attendere che il database principale diventi di nuovo accessibile, anziché avviare il disaster recovery. Ad esempio, se l'emergenza si verifica in maniera intermittente, potrebbe essere più rapido risolvere il problema anziché eseguire il failover.
Database principali e secondari
Un database principale viene utilizzato da una o più app per fornire servizi di persistenza per la gestione dello stato dell'app. Un database secondario è correlato a un database principale e contiene una replica del database principale. Idealmente, i contenuti del database secondario corrispondono esattamente a quelli del database principale in qualsiasi momento. In molti casi, il database secondario è in ritardo rispetto al database principale a causa di ritardi nell'applicazione delle modifiche transazionali apportate al database principale. È possibile associare più di un database secondario a un database principale, a seconda della tecnologia del database. SQL Server supporta l'associazione di più database secondari a un database principale.
Disaster recovery
Se un database principale non è disponibile, il DR modifica il ruolo del database secondario in modo che diventi il database principale. Se sono presenti più database secondari, uno di questi viene selezionato manualmente o in base a un elenco di failover preferito. Le app devono ricollegarsi al nuovo database principale per continuare ad accedere al loro stato. Se il nuovo database principale non era sincronizzato con lo stato conosciuto più recente del precedente database principale, l'app si avvia da uno stato passato (noto anche come flashback).
È importante avere sempre almeno un database secondario per ogni database principale. Dopo un disaster recovery, assicurati di configurare un nuovo database secondario per gestire futuri scenari di questo tipo.
Failover, switchover e fallback
Esistono diversi scenari per cambiare il ruolo tra i database principale e secondario:
- Failover: la procedura di modifica del ruolo di un database secondario per farlo diventare il nuovo database principale e di connessione di tutte le app. Il failover è involontario perché viene attivato dalla mancata disponibilità di un database principale. Puoi configurare il failover in modo che venga attivato automaticamente o manualmente.
- Switchover: a differenza del failover, lo switchover da un database principale a un database secondario (nuovo database principale) viene attivato intenzionalmente per i test iniziali e la manutenzione pianificata. Testa il sistema di DR con uno switchover periodico regolare per garantire la continuità dell'affidabilità del disaster recovery.
- Fallback: il fallback consiste nell'invertire il processo in cui il nuovo database principale diventa il database secondario dopo la riparazione del database principale. Viene attivato intenzionalmente un fallback per ristabilire lo stato prima dell'avvio del failover o dello switchover. Non è strettamente necessario, ma può essere eseguito in base ai requisiti di disaster recovery, ad esempio la località o le risorse disponibili.
Google Cloud zone e regioni
Risorse come i database si trovano in Google Cloud zone e regioni, dove ogni zona appartiene a una regione. Una zona è un dominio single point of failure. Ti consigliamo di eseguire il deployment di una risorsa ad alta affidabilità e a tolleranza di errore in più zone all'interno di una regione.
Per proteggerti dall'interruzione del servizio in un'intera regione, definisci strategie in più regioni per il disaster recovery. Ad esempio, il database principale si trova in una regione e il database secondario corrispondente si trova in un'altra regione.
Modalità attive: attiva/passiva e attiva/attiva
Un database principale è un database aperto per le operazioni di lettura e scrittura (operazioni DML) per far sì che le app che vi accedono possano gestire il proprio stato. Il database principale è chiamato database attivo. Il database secondario corrispondente è passivo perché replica il database principale, ma non è disponibile per nessuna app per le operazioni di modifica dello stato. Dopo un failover o uno switchover, il database secondario diventa il nuovo database principale e diventa un database attivo.
Il database principale e quello secondario possono essere entrambi database attivi se la tecnologia del database supporta questa funzionalità, chiamata modalità attiva-attiva. In questo caso, le app possono connettersi a uno o all'altro perché entrambi i database sono disponibili per la gestione dello stato. Il disaster recovery in modalità attiva-attiva non richiede un failover se solo uno dei database attivi diventa disponibile. Se un database attivo non è disponibile, l'altro database attivo continuerà a essere disponibile. La modalità attiva-attiva non rientra nell'ambito di questo articolo perché SQL Server non la supporta.
Modalità di standby: hot, warm, cold, e no standby
Affinché il database principale sia il database attivo, deve essere in esecuzione e in grado di eseguire istruzioni DML. Il database secondario non deve essere in esecuzione; può essere arrestato. Se non è in esecuzione, il tempo necessario riprendersi dopo un disaster recovery aumenta perché il nuovo database principale deve prima essere portato a uno stato di esecuzione per poter assumere il ruolo del nuovo database principale.
Esistono diverse varianti per configurare il database secondario:
- Hot standby: il database secondario è attivo e pronto per essere collegato dai client. La modifica più recente disponibile dal database principale viene sempre applicata non appena diventa disponibile.
- Warm standby: un database secondario è attivo e funzionante, ma non tutte le modifiche del database principale sono state necessariamente applicate.
- Cold standby: un database secondario non è in esecuzione. Innanzitutto, deve essere avviato e poi sincronizzato con lo stato più recente disponibile.
- No standby: il software del database deve essere installato e successivamente avviato prima che tutte le modifiche del database principale vengano applicate. Questa modalità è la meno costosa perché non consuma risorse quando non è necessaria, ma rispetto alle altre modalità richiede più tempo per diventare un nuovo database principale.
Strategie di DR
Nelle sezioni seguenti vengono descritte le strategie di DR supportate da Microsoft SQL Server.
Dimensioni della strategia di recovery
Esistono diverse dimensioni chiave da considerare quando si seleziona o implementa una strategia di disaster recovery del database. Ogni dimensione ha uno spettro e il comportamento e le aspettative della strategia di disaster recovery dipendono dalla selezione dei punti dello spettro. Le dimensioni principali sono le seguenti:
- Recovery Point Objective (RPO): il periodo di tempo massimo accettabile durante il quale i dati potrebbero andare persi da un'app a causa di un incidente grave. Questa dimensione varia in base ai modi in cui vengono utilizzati i dati. L'RPO può essere espresso in durata (secondi, minuti o ore) dal momento della mancata disponibilità del database principale o in stati di elaborazione identificabili (ultimo backup completo o ultimo backup incrementale). Indipendentemente da come viene specificato l'RPO, la strategia di disaster recovery deve implementare la misura specifica in modo che il requisito RPO possa essere soddisfatto. Il caso più impegnativo è l'ultima transazione di cui è stato eseguito il commit, il che significa che non deve verificarsi alcuna perdita dal database principale al database secondario.
- Recovery Time Objective (RTO). Il periodo di tempo massimo accettabile per cui la tua app può essere offline. Questo valore viene solitamente specificato nell'ambito di un accordo sul livello del servizio più ampio. L'RTO viene solitamente espresso in termini di durata dal momento della non disponibilità del database principale, ad esempio l'app deve essere completamente operativa entro 5 minuti. Il caso più impegnativo è quello immediato, in modo che gli utenti dell'app non notino che si è verificato un disaster recovery.
- Dominio single point of failure. Sta a te decidere se una regione è considerata un dominio single point of failure per i tuoi requisiti di disaster recovery. Se una regione è un dominio single point of failure per te, il disaster recovery deve essere configurato in modo che due o più regioni siano coinvolte nella configurazione effettiva. Se la regione contenente il database principale non funziona, il database secondario in un'altra regione diventa il nuovo database principale. Se si presume che il dominio single point of failure sia una zona, il disaster recovery può essere configurato in più zone all'interno di una singola regione. Se una zona non funziona, il disaster recovery utilizza una seconda zona e rende disponibile il nuovo database principale al suo interno.
La scelta di queste dimensioni chiave comporta una decisione tra costo e qualità. Più bassi sono RTO e RPO, più costosa può diventare la soluzione di disaster recovery man mano che vengono utilizzate più risorse attive. Nelle sezioni seguenti vengono descritte diverse strategie di DR alternative che rappresentano punti sulle dimensioni nel contesto del database Microsoft SQL Server.
Strategie di DR per SQL Server
Continuità operativa e recovery del database - SQL Server descrive le funzionalità di disponibilità che puoi utilizzare per implementare le strategie di disaster recovery.
Turni preliminari
SQL Server viene eseguito sia su Windows che su Linux. Tuttavia, non tutte le funzionalità di disponibilità sono presenti su Linux. SQL Server è disponibile in diverse versioni, ma non tutte le funzionalità di disponibilità sono presenti in ogni versione.
SQL Server distingue le istanze dai database. Un'istanza è il software SQL Server in esecuzione, mentre un database è l'insieme di dati gestito da un'istanza SQL Server.
Gruppi di disponibilità Always On
I gruppi di disponibilità Always On offrono protezione a livello di database. Un gruppo di disponibilità ha due o più repliche. Una replica è la quella principale con accesso in lettura e scrittura e le altre repliche sono repliche secondarie che possono fornire l'accesso in lettura. Ogni replica del database è gestita da un'istanza SQL Server autonoma. Un gruppo di disponibilità può contenere uno o più database. Il numero di database che possono essere inclusi in un gruppo di disponibilità e il numero di repliche secondarie supportate dipendono dalla versione di SQL Server. Tutti i database di un gruppo di disponibilità subiscono contemporaneamente le stesse modifiche del ciclo di vita. I gruppi di disponibilità implementano la modalità attiva-passiva perché solo il database principale supporta l'accesso in scrittura.
Quando si verifica un failover, una replica secondaria diventa la nuova replica principale. Poiché un gruppo di disponibilità include istanze SQL Server autonome, tutte le operazioni acquisite nei log delle transazioni sono disponibili nelle repliche. Qualsiasi variazione non acquisita in un log delle transazioni deve essere sincronizzata manualmente, ad esempio gli accessi a livello di istanza SQL Server o i job dell'agente SQL Server. Per fornire protezione a livello di database e protezione delle istanze SQL Server, devi configurare le istanze del cluster di failover (FCI). Questa architettura di deployment è discussa più avanti nella sezione relativa all'istanza del cluster di failover Always On.
Puoi proteggere le app dalle modifiche ai ruoli utilizzando un ascoltatore. Un listener supporta le app che si connettono al gruppo di disponibilità. Le app non sono a conoscenza di quali istanze SQL Server gestiscono il database principale o le repliche secondarie in un determinato momento. I listener richiedono che i client utilizzino una versione .NET minima di 3.5 con un aggiornamento o 4.0 e versioni successive, come descritto in Continuità operativa e recovery del database - SQL Server.
I gruppi di disponibilità si basano su livelli di astrazione sottostanti per fornire la loro funzionalità. I gruppi di disponibilità vengono eseguiti in un cluster di failover di Windows Server (WSFC) come descritto in Clustering di failover di Windows Server con SQL Server. Tutti i nodi che eseguono istanze di SQL Server devono far parte dello stesso WSFC.
Le transazioni vengono inviate dal database principale a tutte le repliche secondarie. Esistono due modalità di invio per le transazioni: sincrona e asincrona. Puoi configurare in modo indipendente ogni replica in modo che utilizzi una o l'altra modalità. Nella modalità di invio sincrono, la transazione nel database principale va a buon fine solo se va a buon fine in tutte le repliche secondarie collegate in modo sincrono. In modalità asincrona, la transazione sul database principale può andare a buon fine anche se non a tutte le repliche secondarie è stata applicata la transazione.
La scelta della modalità di invio influisce sui possibili RTO, RPO e sulla modalità di standby. Ad esempio, se le transazioni vengono inviate a tutte le repliche in modalità sincrona, tutte le repliche sono nello stesso stato esatto. L'RPO più impegnativo (la transazione più recente) viene soddisfatto poiché tutte le repliche sono completamente sincronizzate. Le repliche secondarie sono hot standby, quindi possono essere utilizzate immediatamente come database principale.
Il failover può essere automatico o manuale. È possibile un failover automatico se tutte le repliche sono completamente sincronizzate. Nell'esempio precedente, questo è possibile perché tutte le repliche sono sempre completamente sincronizzate.
La figura seguente mostra un gruppo di disponibilità Always On in una singola regione.
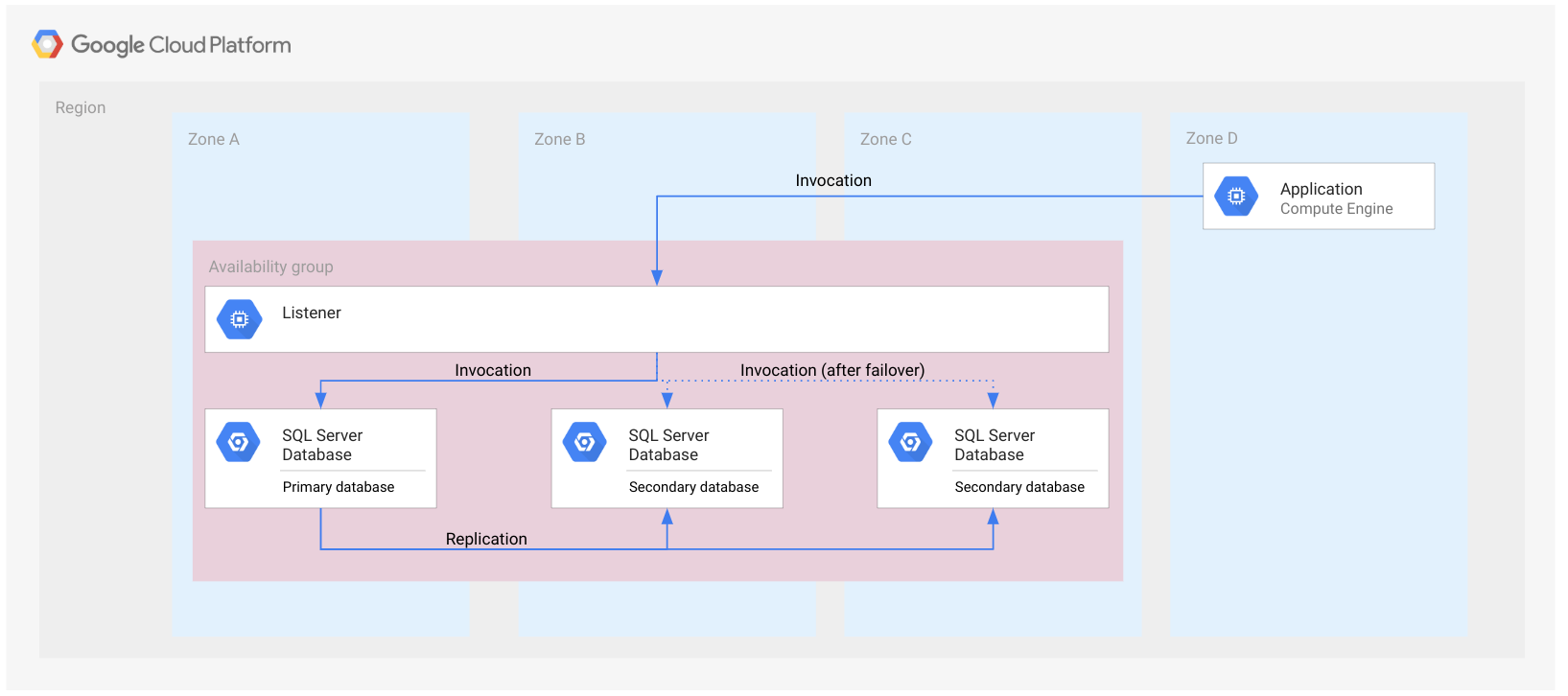
Il gruppo di disponibilità è rappresentato da un rettangolo che si estende su più zone. Questo è solo a scopo illustrativo per indicare che tutti i database appartengono allo stesso gruppo di disponibilità. Il gruppo di disponibilità non è una risorsa cloud e, come tale, non è implementato in un nodo o in qualsiasi altro tipo di risorsa.
Istanza del cluster di failover Always On
Per proteggerti dai guasti dei nodi, puoi utilizzare le istanze del cluster di failover (FCI) anziché le istanze SQL Server autonome. Sono presenti due o più nodi che eseguono istanze SQL Server per gestire un database (principale o secondario). I nodi che gestiscono un database formano un cluster di failover. Un nodo del cluster esegue attivamente un'istanza SQL Server, mentre gli altri nodi non eseguono istanze SQL Server. Quando il nodo che esegue l'istanza SQL Server non funziona, un altro nodo del cluster avvia un'istanza SQL Server, assumendo la gestione del database (failover del nodo). Questa procedura di avvio automatico di un'istanza SQL Server fornisce funzionalità di alta affidabilità.
Il cluster FCI viene visualizzato come una singola unità e i client che accedono al cluster non vedono il failover tra i nodi, tranne forse per un breve periodo di non disponibilità. Non c'è alcuna perdita di dati quando si verifica un failover del nodo. Tutto ciò che viene eseguito all'interno dell'istanza SQL Server non riuscita viene spostato in un'altra istanza SQL Server nello stesso cluster. Ad esempio, i job dell'agente SQL Server o i server collegati vengono spostati in un'altra istanza.
I nodi del cluster FCI possono essere configurati in zone Google Cloud diverse. Questa architettura non solo fornisce alta affidabilità in caso di errore del nodo, ma anche in caso di errori di zona. Un esempio di deployment di questa strategia è descritto nella sezione sulle alternative di deployment del DR.
Anche se diversi nodi gestiscono e condividono lo stesso database, non è richiesto spazio di archiviazione comune tra i nodi di un cluster FCI. SQL Server utilizza la funzionalità Storage Spaces Direct (S2D) per gestire i database sui dischi dei nodi dedicati. Per ulteriori informazioni, consulta Configurazione delle istanze del cluster di failover SQL Server.
L'esempio della sezione precedente Gruppi di disponibilità Always On con istanze del cluster di failover anziché istanze SQL Server autonome è mostrato nella seguente figura. Ogni FCI ha un'istanza SQL Server attiva che gestisce il database.
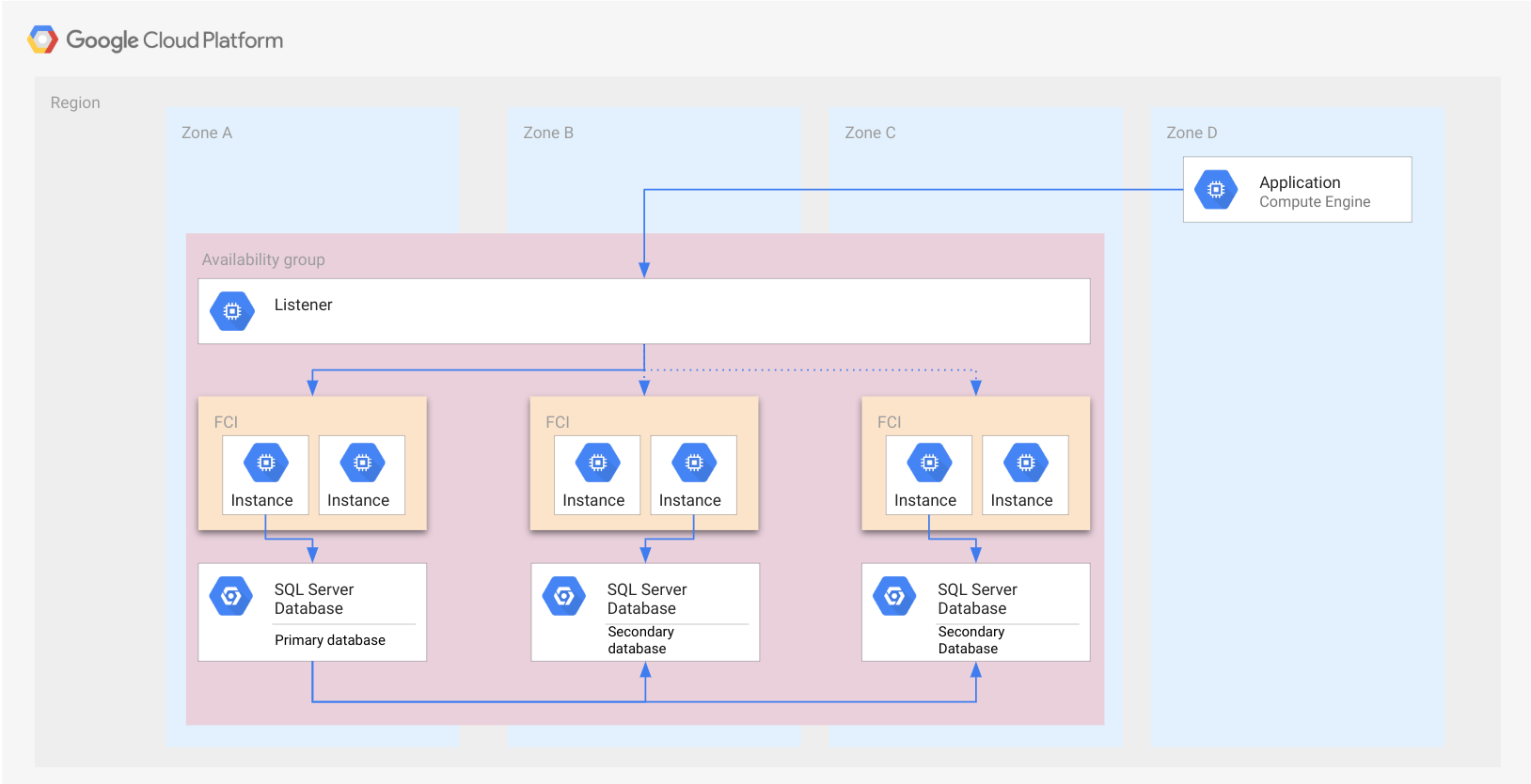
Come nel caso del gruppo di disponibilità, un gruppo di istanze flessibili è rappresentato da un rettangolo. Questo è solo a scopo illustrativo per indicare che tutti i nodi appartengono alla stessa FCI. Un gruppo di istanze flessibili non è una risorsa cloud e, pertanto, non è implementato in un nodo o in qualsiasi altro tipo di risorsa.
Per una discussione più dettagliata, consulta Istanze del cluster di failover Always On (SQL Server).
Gruppi di disponibilità distribuiti
I gruppi di disponibilità distribuiti sono un tipo speciale di gruppo di disponibilità. Un gruppo di disponibilità distribuito si estende su due gruppi di disponibilità, uno nel ruolo del gruppo di disponibilità principale e uno nel ruolo del gruppo di disponibilità secondario. I gruppi di disponibilità distribuita possono inoltrare le transazioni in modalità sia sincrona sia asincrona dal gruppo di disponibilità principale al gruppo di disponibilità secondario.
Anche se ciascuno dei gruppi di disponibilità ha il proprio database principale, non si tratta di un deployment attivo-attivo. Solo il database principale del gruppo di disponibilità principale può ricevere operazioni di scrittura. Il database principale del gruppo di disponibilità secondario è chiamato agente di inoltro. L'agente di inoltro riceve le transazioni dal gruppo di disponibilità principale e le inoltra ai database secondari del gruppo di disponibilità secondario. Un failover dal gruppo di disponibilità principale al gruppo di disponibilità secondario renderebbe accessibile il database principale del nuovo gruppo di disponibilità principale per le operazioni di scrittura.
I gruppi di disponibilità principali e secondari non devono trovarsi nella stessa posizione e non devono essere sullo stesso sistema operativo. Tuttavia, in ogni gruppo di disponibilità deve essere installato un listener. Il gruppo di disponibilità distribuito stesso non ha un listener. I gruppi di disponibilità distribuita non richiedono che i due gruppi di disponibilità si trovino nello stesso WSFC. Tutte le funzionalità richieste per il funzionamento dei gruppi di disponibilità distribuiti sono contenute nella funzionalità di SQL Server e non richiedono l'installazione aggiuntiva di componenti sottostanti.
Un gruppo di disponibilità distribuito si estende su esattamente due gruppi di disponibilità. Un gruppo di disponibilità può far parte di due gruppi di disponibilità distribuiti. Questa possibilità supporta diverse topologie. Una topologia è quella daisy chain da un gruppo di disponibilità all'altro in più località. Un'altra topologia è la struttura ad albero in cui il gruppo di disponibilità principale fa parte di due gruppi di disponibilità distribuiti diversi e separati.
I gruppi di disponibilità distribuiti sono il mezzo principale per implementare il disaster recovery su più sistemi operativi. Ad esempio, il gruppo di disponibilità principale può essere configurato su Windows e un secondo gruppo di disponibilità corrispondente su Linux, con entrambi i gruppi di disponibilità che formano un gruppo di disponibilità distribuito.
Il seguente diagramma mostra due gruppi di disponibilità che fanno parte di un gruppo di disponibilità distribuito.
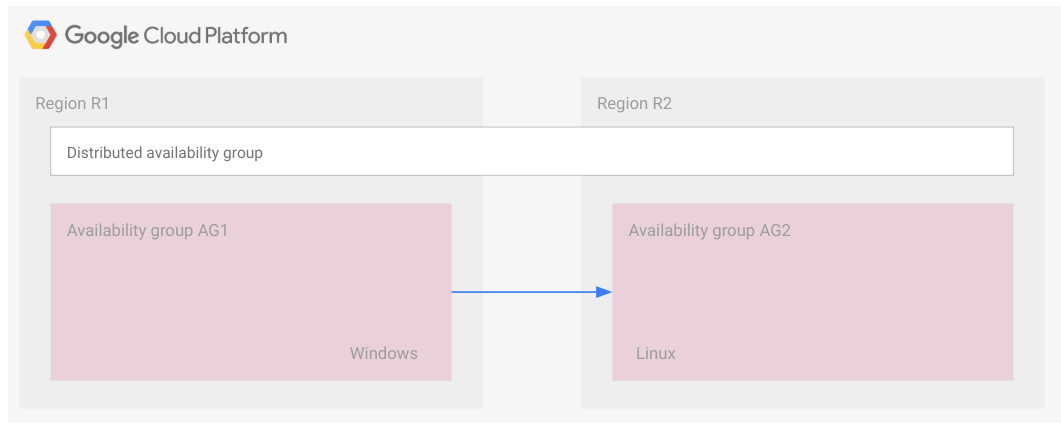
Il gruppo di disponibilità 1 è il gruppo di disponibilità principale e il gruppo di disponibilità 2 è il gruppo di disponibilità secondario.
Come nel caso degli FCI, un gruppo di disponibilità distribuito è rappresentato come un rettangolo. Questo esempio è solo a scopo illustrativo per indicare che tutti i gruppi di disponibilità appartengono allo stesso gruppo di disponibilità distribuito. Un gruppo di disponibilità distribuito, come un gruppo di disponibilità, non è una risorsa cloud e, come tale, non è implementato in un nodo o in qualsiasi altro tipo di risorsa.
Per ulteriori informazioni, consulta Gruppi di disponibilità distribuiti.
Spedizione dei log
La spedizione dei log delle transazioni è una funzionalità di disponibilità di SQL Server quando RTO e RPO non sono così rigidi (RTO basso e/o RPO recente) perché la discrepanza di stato tra un database principale e il relativo database secondario è molto più grande. La discrepanza è maggiore in termini di stato perché un file di log delle transazioni contiene molte modifiche dello stato. La discrepanza è maggiore anche in termini di tempo di latenza perché i file di log delle transazioni vengono trasportati in modo asincrono e devono essere applicati nella loro interezza a un database secondario.
I file di log delle transazioni vengono creati dal database principale e viene eseguito il loro backup, ad esempio, in Cloud Storage. Ogni file di log delle transazioni viene copiato in ogni database secondario e applicato. Poiché il database secondario è in ritardo rispetto al database principale, sono in modalità warm standby. Gli oggetti e le modifiche che non vengono acquisiti dai log delle transazioni devono essere applicati manualmente ai database secondari per stabilire una sincronizzazione completa senza perdita.
L'agente SQL Server automatizza il processo complessivo di creazione, copia e applicazione dei log delle transazioni. La spedizione dei log deve essere configurata singolarmente per ogni database. Se un gruppo di disponibilità gestisce più di un database, devono essere configurate altrettante procedure di spedizione dei log.
In caso di errore, la procedura di disaster recovery deve essere avviata manualmente perché non è disponibile il supporto automatico. Inoltre, l'accesso dei client non viene astratto dal database principale e dai database secondari da un listener. In caso di failover, i client devono essere in grado di gestire autonomamente la modifica del ruolo di un database dal ruolo secondario al nuovo ruolo principale collegandosi al nuovo database principale dopo un disaster recovery. È possibile creare astrazioni separate indipendentemente dalle istanze di SQL Server, ad esempio gli indirizzi IP mobili come descritto nella sezione Best practice per gli indirizzi IP mobili.
Poiché la spedizione dei log è in parte una procedura manuale, puoi ritardare intenzionalmente l'applicazione dei file di log copiati ai database secondari (a differenza dei gruppi di disponibilità e dei gruppi di disponibilità distribuiti, in cui le modifiche vengono applicate immediatamente). Un possibile caso d'uso è impedire che gli errori di modifica dei dati nel database principale vengano applicati ai database secondari finché non vengono risolti. In questo caso, un database secondario a cui non è stato ancora applicato un errore di modifica dei dati potrebbe diventare il database principale finché l'errore non viene risolto. Dopodiché, l'elaborazione normale può riprendere.
Come nel caso dei gruppi di disponibilità distribuiti, puoi utilizzare la spedizione di log per le soluzioni multipiattaforma in cui, ad esempio, il database principale è in esecuzione su Linux, mentre i database secondari sono su Linux e Windows.
Il seguente diagramma illustra un deployment multipiattaforma con spedizione dei log. Tieni presente che in questa topologia non esiste una configurazione comune tra le regioni, come un gruppo di disponibilità distribuito.
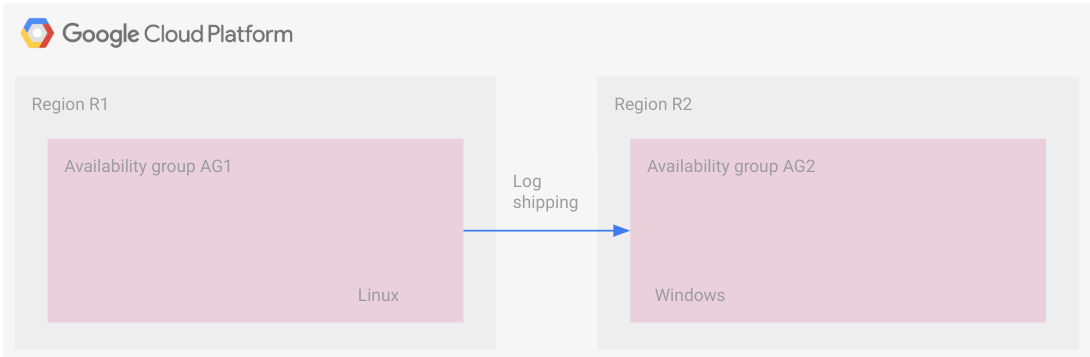
I gruppi di disponibilità si trovano in regioni separate, uno su Linux e l'altro su Windows.
Per ulteriori informazioni sulla spedizione dei log di SQL Server, consulta Informazioni sulla spedizione dei log (SQL Server).
Combinazione delle funzionalità di disponibilità di SQL Server
Puoi eseguire il deployment delle funzionalità di disponibilità di SQL Server in combinazioni diverse. Ad esempio, nel caso d'uso precedente, è stata utilizzata la spedizione dei log con gruppi di disponibilità diversi installati su altri sistemi operativi.
Di seguito è riportato un elenco di possibili combinazioni di funzionalità di disponibilità di SQL Server:
- Utilizzare la spedizione dei log tra gruppi di disponibilità installati sullo stesso sistema operativo.
- Avere un gruppo di disponibilità principale che utilizza FCI con un gruppo di disponibilità secondario che utilizza solo istanze autonome di SQL Server.
- Utilizzare un gruppo di disponibilità distribuito tra regioni vicine e spedizione dei log tra regioni situate in continenti diversi.
Queste sono solo alcune delle possibili combinazioni di funzionalità di disponibilità di SQL Server.
La flessibilità offerta dalle funzionalità di disponibilità di SQL Server supporta la messa a punto di una strategia di disaster recovery in base ai requisiti dichiarati.
Replica di SQL Server
La replica di SQL Server non è generalmente considerata una funzionalità di disponibilità, ma questa sezione descrive brevemente come può essere utilizzata per il disaster recovery.
La funzionalità di replica supporta la creazione e la manutenzione delle repliche dei database. Diversi tipi di agenti SQL Server collaborano per acquisire le modifiche, trasmetterle e applicarle alle repliche. Questa procedura è asincrona e le repliche in genere sono in ritardo rispetto al database sottoposto a replica in vari gradi.
Ad esempio, è possibile avere una replica di un database di produzione. In termini di disaster recovery, il database di produzione è il database principale e la replica è il database secondario. La funzionalità di replica di SQL Server non sa che i database assumono ruoli diversi nel contesto del disaster recovery. Di conseguenza, la replica non dispone di operazioni che supportano il processo di disaster recovery, ad esempio le modifiche dei ruoli. Il processo di disaster recovery deve essere implementato separatamente dalla funzionalità di SQL Server ed eseguito dall'organizzazione che lo implementa perché non sono presenti astrazioni per l'accesso client.
Spedizione del file di backup
L'invio di file di backup è un'altra strategia di implementazione del disaster recovery. Un approccio standard per configurare e aggiornare continuamente un database secondario consiste nell'eseguire un backup completo iniziale del database principale e successivamente backup incrementali. Tutti i backup incrementali vengono applicati ai database secondari nell'ordine corretto. Esistono molte varianti di questo approccio a seconda della frequenza dei backup incrementali e della località di archiviazione dei file di backup (località globale o copia effettiva tra posizioni).
Questa strategia non prevede alcuna funzionalità di disponibilità di SQL Server quando si replicano le modifiche dello stato dal database principale a qualsiasi database secondario. Non utilizza l'agente SQL Server utilizzato nel caso della spedizione dei log.
Per ulteriori informazioni, consulta la sezione Esempio: strategia di DR di il backup e il ripristino.
Rispetto all'approccio di replica discusso nella sezione precedente, sia la replica sia l'invio dei file di backup hanno in comune il fatto che il processo di disaster recovery viene implementato al di fuori e separatamente dall'insieme di funzionalità di SQL Server. Dal punto di vista dell'invio delle modifiche acquisite, la replica di SQL Server è più comoda in quanto implementa questa parte automaticamente tramite gli agenti SQL Server.
Nota sull'interazione tra il ciclo di vita del database e il ciclo di vita dell'app
Il failover di un database non è completamente separato e indipendente dalle app che accedono al database. In linea di principio, esistono due scenari di errore.
Innanzitutto, l'app rimane operativa durante il failover del database. Dal momento in cui il database principale non è disponibile fino al momento in cui il nuovo database principale è operativo, le app non possono accedere al database. Le connessioni esistenti non vanno a buon fine e non vengono stabilite nuove connessioni. Durante questo periodo, l'app non è in grado di fornire servizi ai propri clienti, almeno nella misura in cui la funzionalità richiede l'accesso al database. Le app devono riconoscere quando è disponibile il nuovo database principale per poter riprendere l'elaborazione normale.
Le app potrebbero avere uno stato esterno al database, ad esempio nelle cache della memoria principale. L'app assicura che la cache sia coerente (sincronizzata) con il nuovo database principale. Se non si è verificata alcuna perdita di transazioni durante il failover, la cache potrebbe essere coerente senza ulteriore manutenzione. Tuttavia, se si è verificata una perdita di transazioni (dati) durante il failover, la cache potrebbe non essere coerente rispetto al nuovo database principale. La discussione analoga si applica allo stato condiviso quando, ad esempio, alcuni dei dati nel database fanno parte anche dei messaggi nelle code o dei file nel file system. Questo aspetto della coerenza dei dati non rientra nell'ambito di questo documento perché non è direttamente correlato al disaster recovery del database.
In secondo luogo, una o più app potrebbero non essere più disponibili contemporaneamente al database principale. Ad esempio, se una regione viene messa offline, un sistema di applicazioni in esecuzione in quella regione non sarà disponibile, così come non sarà disponibile neanche il database principale nella stessa regione. In questo caso, deve essere recuperata anche l'app, non solo il sistema di database principale. Oltre alla procedura di disaster recovery del database in caso di calamità, devi avviare una procedura di recovery dell'app simile. L'app sottoposta a recovery deve connettersi al nuovo database principale ed essere riconfigurata (ad esempio, indirizzi IP mobili). Il recovery delle app non rientra nell'ambito di questo documento.
Relazione tra backup e ripristino per il disaster recovery
Il backup di un database è indipendente e ortogonale al disaster recovery del database. Lo scopo del backup del database è poter ripristinare uno stato coerente, ad esempio nel caso in cui un database venga perso o danneggiato oppure debba essere recuperato uno stato precedente a causa di errori o arresti anomali dell'app.
La sezione seguente illustra come utilizzare i backup come possibile metodo per implementare il disaster recovery del database. In questo scenario, copi i file di backup nella posizione del database secondario in modo che possa essere ripristinato. Tuttavia, i file di backup non sono un prerequisito per il disaster recovery. La discussione precedente sulle funzionalità di disponibilità ha presentato delle alternative.
Alta affidabilità e disaster recovery
Sia l'alta affidabilità sia il disaster recovery hanno in comune il fatto che forniscono soluzioni per la non disponibilità del database. Se un database principale diventa non disponibile, un database secondario diventa il nuovo database principale, coerente e disponibile.
La differenza tra l'alta affidabilità e il disaster recovery è il dominio single point of failure. L'alta affidabilità risolve un'interruzione all'interno di una regione, ad esempio quando si verifica un errore in una singola zona o in un nodo. Una soluzione ad alta affidabilità fornisce un nuovo database principale in un'altra zona della stessa regione. Inoltre, l'alta affidabilità risolve i guasti dei nodi, non solo quelli del database. Se un nodo che esegue un'istanza SQL Server non funziona, viene reso disponibile un nuovo nodo che esegue una nuova istanza SQL Server (consulta la sezione Istanza del cluster di failover Always On).
Il disaster recovery coinvolge almeno due regioni. Risolve il caso in cui un'intera regione non è più disponibile. Il disaster recovery può fornire un nuovo database principale in una regione diversa.
Le funzionalità di alta affidabilità di SQL Server supportano contemporaneamente soluzioni per l'alta affidabilità e il disaster recovery. Un singolo gruppo di disponibilità può includere le zone all'interno di una regione e le regioni stesse. Un gruppo di disponibilità può contenere istanze di cluster di failover per garantire un'alta affidabilità.
SQL Server può stabilire gruppi di disponibilità all'interno di una regione per l'alta affidabilità e i guasti delle zone e combinarli con la spedizione dei log tra regioni per gestire il disaster recovery.
Alternative di deployment per il DR
Nelle sezioni seguenti sono riportate alcune possibili topologie di disaster recovery, oltre a quelle discusse finora. Queste topologie soddisfano diversi requisiti RPO e RTO. L'elenco non è esaustivo.
DR e alta affidabilità tra regioni
Questo deployment è una variante di un gruppo di disponibilità contenente FCI all'interno di una regione composta da tre zone. In questo scenario, le zone sono considerate il dominio single point of failure.
Rispetto al deployment mostrato in precedenza, ogni gruppo di istanze flessibili è costituito da tre nodi in cui ogni nodo è in esecuzione in una zona diversa. Il vantaggio di questa configurazione è che una o due zone possono non funzionare senza richiedere una procedura di disaster recovery.
Il seguente diagramma mostra questa configurazione.
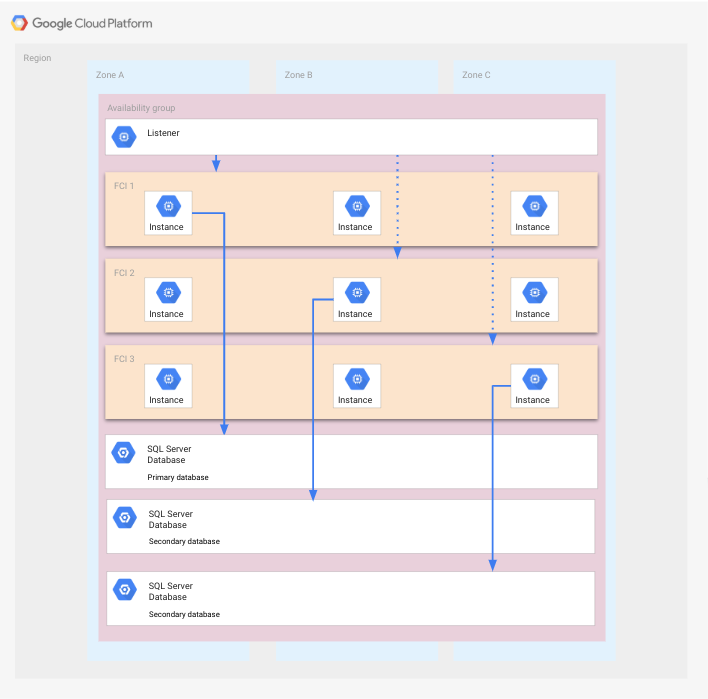
Le FCI coprono tutte le zone e ogni FCI ha un'istanza SQL Server in esecuzione che accede al database corrispondente. In ogni gruppo di istanze flessibili sono presenti altre due istanze SQL Server non in esecuzione che possono essere avviate in caso di guasto di una zona. I database vengono visualizzati nelle varie zone perché ogni database utilizza i dischi di tutti i nodi di un determinato gruppo di istanze flessibili. Un'app non viene mostrata per chiarezza.
DR tra regioni: gruppo di disponibilità che si estende su più regioni
In questo scenario, un gruppo di disponibilità viene eseguito su un cluster di failover di Windows Server e si estende su due regioni. Le regioni sono considerate un dominio single point of failure.
Il seguente diagramma illustra questa configurazione.

Per risolvere potenziali problemi di latenza, puoi configurare le repliche all'interno della regione R1 in modo che utilizzino la propagazione delle transazioni sincrone, mentre le repliche nella regione R2 sono configurate per utilizzare la propagazione delle transazioni asincrone.
DR tra regioni: trasferimento dei file di backup
Questo scenario utilizza il trasferimento dei file di backup. Due gruppi di disponibilità in due regioni sono collegati. Ogni gruppo di disponibilità ha le proprie repliche che ricevono le transazioni in modo sincrono, pertanto le repliche secondarie di ogni regione sono in una configurazione di hot standby.
Il seguente diagramma illustra questa configurazione.
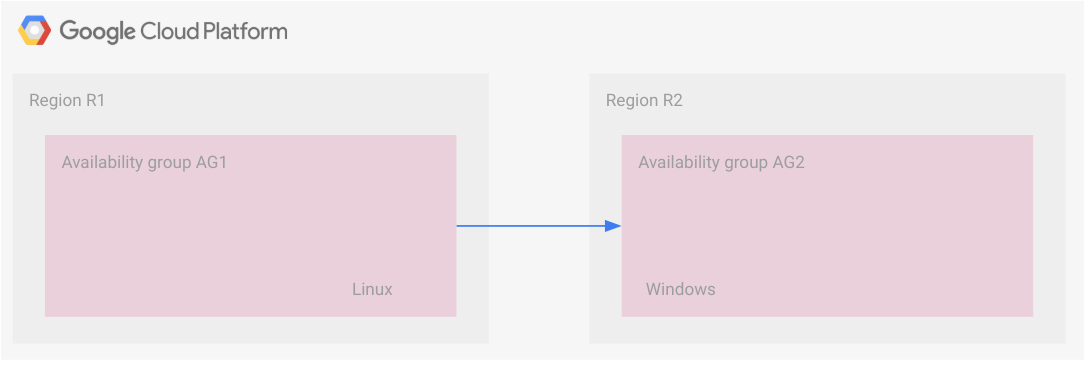
Tuttavia, i due gruppi di disponibilità sono collegati tramite il trasferimento dei file di backup. Il gruppo di disponibilità AG1 è il gruppo di disponibilità principale e il gruppo di disponibilità AG2 è il gruppo di disponibilità secondario. Poiché i file di backup vengono resi disponibili per il gruppo di disponibilità secondario, vengono applicati lì. Questo scenario è descritto in maggiore dettaglio nella sezione seguente, Esempio: strategia di DR per il backup e il ripristino.
Topologia di località doppia e terziaria
Se sono presenti solo due database, uno principale e uno secondario, ciascuno in una regione separata, dopo un failover esiste un periodo di tempo non protetto dal momento in cui il nuovo database principale è in esecuzione e il nuovo database secondario è pronto. Se il nuovo database principale non è disponibile mentre il database secondario non è ancora in esecuzione, si verifica un tempo di inattività forzato da cui è possibile recuperare solo quando viene stabilito un nuovo database principale. Lo stesso vale per i gruppi di disponibilità.
Una terza località che esegue un altro database secondario o un altro gruppo di disponibilità può eliminare la durata non protetta dopo un failover. Questa configurazione deve garantire che uno dei due database secondari rimanga un database secondario e venga riassegnato a un nuovo database principale in modo che non si verifichino perdite di dati. Come in precedenza, lo stesso vale per i gruppi di disponibilità.
Ciclo di vita del DR
Indipendentemente dalla soluzione di disaster recovery scelta, si applicano dei passaggi comuni del ciclo di vita.
In una situazione di disaster recovery reale, tutti gli stakeholder (proprietari di app, gruppi operativi e amministratori di database) devono essere disponibili e partecipare attivamente alla gestione del disaster recovery. Gli stakeholder devono decidere sull'autorità decisionale (a volte indicata come master of ceremony) e sulle procedure decisionali da seguire. Inoltre, gli stakeholder devono trovare un accordo sulla terminologia e sui metodi di comunicazione.
Decisione sull'avvio di un processo di failover
A meno che il failover non venga avviato automaticamente, gli stakeholder devono prendere la decisione di avviarlo. I vari stakeholder devono coordinarsi strettamente sulla decisione quando decidono di avviare il failover.
L'avvio di un processo di failover dipende da diversi fattori, principalmente dalla causa principale della mancata disponibilità del database principale.
Se la procedura di disaster recovery richiede più tempo del previsto per risolvere la non disponibilità del database principale, un failover sarebbe dannoso. Innanzitutto, devi valutare se il ripristino del database principale è un'opzione fattibile.
Più la strategia di disaster recovery è testata e più è rapida la sua implementazione, più è facile avviare il processo di failover perché si considera meno incertezza nella decisione.
Esecuzione del processo di failover
Idealmente, il processo di failover viene testato regolarmente ed è quindi ben noto ai vari stakeholder.
L'autorità decisionale deve essere a conoscenza di tutti i passaggi in corso e di tutti i problemi imprevisti che si verificano. L'autorità decisionale gestisce il processo di failover e gli stakeholder sono responsabili del supporto dell'autorità decisionale.
Devi conservare le statistiche per l'analisi post-mortem e il miglioramento del processo di failover, incluse le durate delle attività, i problemi riscontrati ed eventuali confusioni nei passaggi del processo di failover.
Protezione mancante
Se hai un solo database secondario, non esiste alcuna protezione di DR dal momento in cui il nuovo database principale è disponibile e operativo fino alla configurazione di un nuovo database secondario. Un'interruzione del servizio durante questo periodo potrebbe causare un tempo di riposo forzato perché non è possibile eseguire il failover su un altro database. Se si verifica questa situazione, è necessario configurare un altro database principale e l'RPA è l'ultimo punto che può essere ricostruito in base ai backup disponibili.
A meno che la strategia di disaster recovery non sia configurata in modo da garantire la protezione in qualsiasi momento, tutti gli stakeholder devono essere a conoscenza di questa durata della protezione mancante per adottare precauzioni aggiuntive durante la configurazione o le modifiche alla configurazione dell'ambiente.
Puoi evitare questo periodo di tempo non protetto se l'accesso dell'app al nuovo database principale viene ritardato fino a quando il nuovo database secondario non è attivo e funzionante. Non appena vengono applicate le modifiche del database principale, questo diventa disponibile per le applicazioni. Sebbene questo approccio eviti che le app non siano protette dal DR, ritarda il completamento della procedura di disaster recovery.
Evita situazioni di split-brain
È importante che le app non possano accedere contemporaneamente a un database principale e a un database secondario, emettendo operazioni DML. In questa situazione si verifica un'incoerenza dei dati quando sia il database principale sia quello secondario non concordano sui valori dei dati dello stesso elemento di dati (Split-brain). Questa architettura è particolarmente importante se il database principale diventa non disponibile mentre continua a funzionare e può ricevere operazioni di scrittura. Se la mancata disponibilità è causata dalla partizione della rete intermittente, la partizione può interrompersi in qualsiasi momento e un'app potrebbe avere di nuovo accesso. Se al momento è in corso un processo di failover, le modifiche al vecchio database principale potrebbero andare perse oppure alcune app potrebbero iniziare a operare sul nuovo database principale mentre altre accedono ancora al vecchio database principale.
Durante il processo di failover, l'accesso di tutte le app a qualsiasi database viene disattivato in modo che non si verifichino modifiche dello stato in nessuno dei database. Dopo il failover, per le operazioni di scrittura è disponibile un solo database, ovvero il nuovo database principale.
Dichiarazione di completamento
Al termine della procedura di failover, tutti gli stakeholder devono essere informati esplicitamente dall'autorità decisionale del completamento della procedura. Qualsiasi problema rilevato dopo il completamento deve essere trattato come un incidente separato che non fa più parte del processo di failover, ma dell'elaborazione regolare. Il problema potrebbe essere una conseguenza di un problema con il processo di failover o un problema indipendente. Tuttavia, l'approccio per risolvere il problema al termine del processo di failover potrebbe essere diverso da come viene risolto durante l'esecuzione del processo di failover.
Analisi e report post-mortem
Per riferimento futuro e per migliorare la procedura di failover, organizza immediatamente un'analisi post-mortem per prendere nota di aspetti, risultati e azioni importanti.
Scrivi un report che riepiloghi l'evento di disaster recovery, le cause principali e tutte le azioni intraprese. Questo report potrebbe essere obbligatorio se stai implementando i requisiti previsti dalle normative.
Test e verifica del DR
Poiché il disaster recovery non fa parte delle normali operazioni quotidiane, la soluzione di DR deve essere testata regolarmente per assicurarne il corretto funzionamento quando è effettivamente necessaria.
La frequenza dei test dipende dai requisiti operativi e varia in base al database, all'app e all'azienda. Inoltre, le modifiche all'ambiente, come le modifiche alla configurazione di rete e gli aggiornamenti dei componenti dell'infrastruttura, devono attivare un test di disaster recovery se le modifiche vengono apportate ai sistemi su cui si basa la soluzione di disaster recovery scelta. Qualsiasi modifica potrebbe causare il fallimento della soluzione di disaster recovery o richiedere l'aggiustamento della procedura di disaster recovery.
Puoi eseguire il test manualmente avviando la procedura di switchover o automaticamente seguendo un approccio di chaos engineering come descritto in Chaos engineering. Con i test manuali, puoi ridurre al minimo l'impatto sull'attività nel caso in cui si preveda un tempo di inattività significativo.
Un aspetto importante dei test è la raccolta di statistiche ben definite. Di seguito sono riportate alcune statistiche importanti da considerare:
- Tempo di recupero effettivo: misura il tempo di recupero effettivo e confrontalo con l'RTO.
- Punto di recupero effettivo: osserva il punto di recupero effettivo e confrontalo con l'RPO (Recovery Point Objective).
- Tempo di rilevamento dell'errore: il tempo necessario ai DBA o al team operativo per rendersi conto della necessità del failover.
- Tempo di inizio del recupero: il tempo necessario per avviare il processo di failover dopo il rilevamento dell'errore.
- Affidabilità: con quale attenzione è stata seguita la procedura di failover o sono state necessarie deviazioni? Si sono verificati problemi imprevisti che devono essere esaminati, con possibile conseguente modifica della strategia di recupero?
In base alle statistiche raccolte, la procedura di failover potrebbe dover essere aggiustata o migliorata per soddisfare meglio le aspettative di RPO e RTO.
Esempio: strategia di DR per il backup e il ripristino
Le sezioni seguenti descrivono un esempio di strategia di disaster recovery per il backup e il ripristino. Questo scenario riduce al minimo l'utilizzo delle funzionalità di disponibilità di SQL Server per dimostrare lo sforzo necessario per specificare una strategia di backup e ripristino del piano di recupero dei disastri e per discutere di aspetti invisibili in configurazioni più automatizzate.
Caso d'uso
Un gruppo di disponibilità Always On principale è operativo nella regione R1. Il gruppo di disponibilità Always On secondario viene aggiunto nella regione R2 per una protezione tra regioni aggiuntiva ed è disponibile come destinazione di failover o switchover.
Strategia
La strategia di disaster recovery si basa sui backup del database. Viene eseguito un backup completo iniziale seguito da backup differenziali successivi. I backup vengono applicati al gruppo di disponibilità Always On secondario man mano che vengono eseguiti. Tutti i backup vengono archiviati in un bucket Cloud Storage.
In questo esempio, dopo il completamento del failover è accettabile che il nuovo gruppo di disponibilità Always On principale in R2 sia attivo e non protetto per un periodo di tempo limitato fino a quando il nuovo gruppo di disponibilità Always On secondario in R1 non è operativo.
Non è necessario eseguire il fallback perché il gruppo di disponibilità Always On in ciascuna delle regioni è ugualmente idoneo a fungere da gruppo di disponibilità Always On di produzione.
RTO e RPO (Recovery Point Objective)
In questo esempio, l'RPO (Recovery Point Objective) è definito come massimo 60 minuti, pertanto viene eseguito un backup differenziale ogni 60 minuti.
L'RTO non è impostato esplicitamente su una durata, ma deve essere il più breve possibile: l'opzione migliore è quella immediata. Il gruppo di disponibilità secondario deve essere impostato come hot standby. In caso di hot standby, tutti i backup vengono applicati immediatamente in modo che il failover non venga ritardato dall'applicazione dei backup.
Strategia di DR di alto livello
Le sezioni seguenti descrivono la strategia di RP. È volutamente breve per invitare a concentrarsi sui passaggi essenziali.
Configurazione iniziale
- Crea un gruppo di disponibilità Always On secondario nella regione R2.
- Impedisci all'app di accedere al gruppo di disponibilità secondario in modo che non si verifichi accidentalmente una situazione di split brain.
- Crea il bucket del file di backup B1 in Cloud Storage per contenere il backup completo iniziale del gruppo di disponibilità Always On in R1 e i backup differenziali orari successivi del gruppo di disponibilità Always On in R1. È necessario stabilire l'ordine corretto dei backup differenziali in modo che il processo di applicazione dei backup al gruppo di disponibilità secondario possa dedurre l'ordine corretto. Un approccio potrebbe essere una convenzione di denominazione che consente di stabilire l'ordine cronologico corretto in base alla data e all'ora che fanno parte dei vari nomi dei file.
Strategia di lancio
- Applica il backup completo al gruppo di disponibilità Always On secondario nella regione R2.
- Man mano che i backup differenziali diventano disponibili, applicali immediatamente al gruppo di disponibilità Always On secondario in R2. L'applicazione immediata è necessaria per quanto riguarda l'RTO.
- Dopo aver applicato il backup completo iniziale e tutti i backup incrementali, il gruppo di disponibilità Always On secondario è pronto.
- Testa la strategia di DR eseguendo il passaggio dal gruppo di disponibilità principale al gruppo di disponibilità secondario. Durante i test deve essere disponibile almeno un backup incrementale.
Richiesta di failover o switchover
In R2, i passaggi essenziali sono i seguenti:
- Assicurati che l'ultimo backup differenziale sia stato applicato al gruppo di disponibilità Always On secondario in R2.
- Designa R2 come nuovo gruppo di disponibilità Always On principale.
- Crea un nuovo bucket B2, esegui un backup completo come riferimento e apri il nuovo gruppo di disponibilità principale per l'accesso alle app.
- Inizia a eseguire backup differenziali.
In R1, i passaggi essenziali sono i seguenti:
- Rimuovi il bucket B1 perché non è più necessario.
- Quando il gruppo di disponibilità Always On in R1 diventa di nuovo disponibile (come nuovo gruppo di disponibilità Always On secondario), impedisci l'accesso alle app e rimuovi tutti i dati dal database o reimpostalo allo stato iniziale (vuoto) (a meno che non debba essere creato di nuovo).
- Applica il backup completo dal nuovo gruppo di disponibilità Always On principale in R2 e continua ad applicare i backup differenziali subito non appena diventano disponibili (archiviati nel bucket B2).
Possibili miglioramenti
Un possibile miglioramento della strategia di DR è evitare di eseguire un backup completo dopo un failover o uno switchover, pur essendo in grado di configurare rapidamente il nuovo gruppo di disponibilità secondario. Anziché un singolo backup completo e i backup differenziali successivi, esegui un backup completo ogni settimana e crea un bucket settimanale contenente il backup completo della settimana e tutti i backup differenziali successivi per quella settimana. Il nuovo gruppo di disponibilità principale deve creare backup differenziali solo dopo il failover (e non un backup completo) e aggiungerli al bucket. Il nuovo gruppo di disponibilità secondario applica semplicemente tutti i backup nel bucket della settimana corrente. Se viene utilizzato questo approccio settimanale, devi implementare una strategia di pulizia o eliminazione definitiva per rimuovere i backup obsoleti.
Un altro miglioramento si basa sul fatto che il nuovo gruppo di disponibilità secondario era l'ex gruppo di disponibilità principale. Se il database esiste ed è operativo dopo essere tornato disponibile, un recupero point-in-time all'ultimo backup differenziale evita di doverlo ripristinare completamente dall'ultimo backup completo, come descritto in Ripristina un database SQL Server a un momento specifico (modello di recupero completo). Questo scenario riduce lo sforzo e il tempo durante il quale il nuovo gruppo di disponibilità principale non è protetto.
Best practice per la produzione
Questa soluzione non specifica se le istanze SQL Server nei gruppi di disponibilità Always On sono istanze autonome o del cluster di failover. Il tipo di istanze da utilizzare deve essere deciso prima dell'implementazione.
Fino a quando un nuovo gruppo di disponibilità Always On secondario non è operativo dopo un failover, esiste un momento in cui il DR non è protetto. Devi configurare un terzo gruppo di disponibilità Always On in una terza regione.
Inoltre, devi implementare il monitoraggio per assicurarti che eventuali errori o guasti vengano rilevati. Il monitoraggio non rientra nell'ambito di questo documento, ma è essenziale per una soluzione di disaster recovery funzionante.
Passaggi successivi
- Configurazione dei gruppi di disponibilità Always On di SQL Server.
- Deployment di un gruppo di disponibilità SQL Server 2016 Always On con più subnet su Compute Engine.
- Configurazione delle istanze del cluster di failover SQL Server.
- Esecuzione del clustering di failover di Windows Server.
- Come attivare Cloud Logging, Cloud Monitoring ed Error Reporting per le app .NET
- Installazione dell'agente Cloud Monitoring.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.