Présentation de l'analyse des journaux
Ce document explique comment Google Security Operations analyse les journaux bruts au format UDM (Unified Data Model).
Google SecOps peut recevoir des données de journaux provenant des sources d'ingestion suivantes :
- Transférer Google SecOps
- Flux de l'API Chronicle
- API d'ingestion Chronicle
- Partenaire technologique tiers
En général, les clients envoient les données sous forme de journaux bruts d'origine. Google SecOps identifie de manière unique l'appareil qui a généré les journaux à l'aide de LogType. LogType identifie les deux éléments suivants :
- le fournisseur et l'appareil qui ont généré le journal, tels que Cisco Firewall, Linux DHCP Server ou Bro DNS.
- l'analyseur qui convertit le journal brut en UDM structuré. Il existe une relation un à un entre un analyseur et un LogType. Chaque analyseur convertit les données reçues par un seul LogType.
Google SecOps fournit un ensemble d'analyseurs par défaut qui lisent les journaux bruts d'origine et génèrent des enregistrements UDM structurés à l'aide des données du journal brut d'origine. Google SecOps gère ces analyseurs. Les clients peuvent également définir des instructions de mappage de données personnalisées en créant un analyseur spécifique.
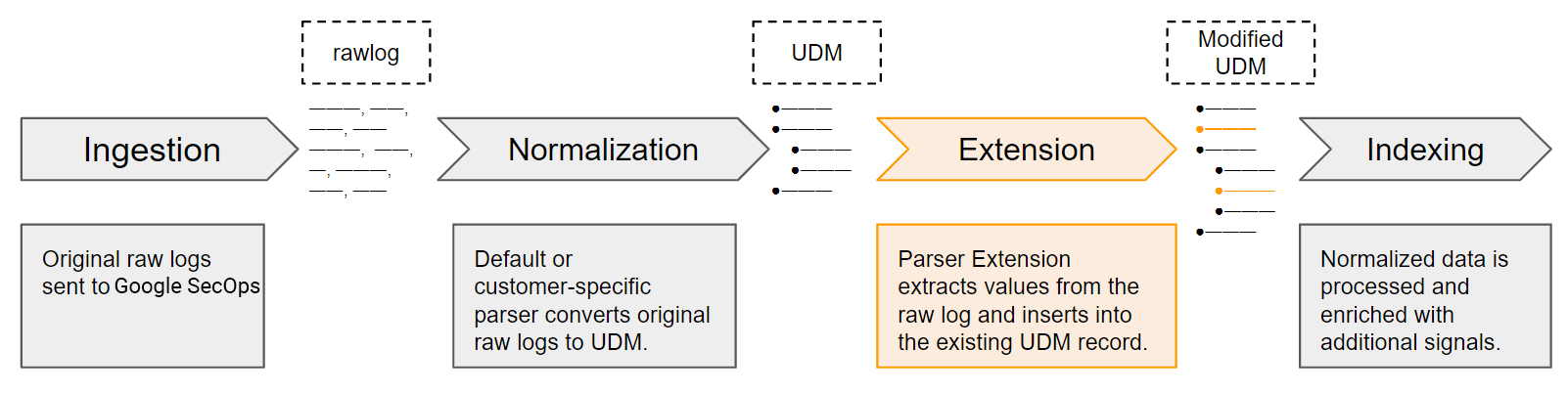
L'analyseur contient des instructions de mappage de données. Il définit la façon dont les données sont mappées du journal brut d'origine à un ou plusieurs champs de la structure de données UDM.
S'il n'y a pas d'erreur d'analyse, Google SecOps crée un enregistrement structuré UDM à l'aide des données du journal brut. Le processus de conversion d'un journal brut en enregistrement UDM est appelé normalisation.
Un analyseur par défaut peut mapper un sous-ensemble de valeurs principales à partir du journal brut. En règle générale, ces champs principaux sont les plus importants pour fournir des insights sur la sécurité dans Google SecOps. Les valeurs non mappées restent dans le journal brut, mais ne sont pas stockées dans l'enregistrement UDM.
Un client peut également utiliser l'API Ingestion pour envoyer des données au format UDM structuré.
Personnaliser l'analyse des données ingérées
Google SecOps fournit les fonctionnalités suivantes qui permettent aux clients de personnaliser l'analyse des données de journaux d'origine entrantes.
- Analyseurs spécifiques aux clients : les clients créent une configuration d'analyseur personnalisé pour un type de journal spécifique qui répond à leurs exigences spécifiques. Un analyseur spécifique au client remplace l'analyseur par défaut pour le LogType spécifique. Pour en savoir plus, consultez Gérer les analyseurs prédéfinis et personnalisés.
- Extensions de l'analyseur : les clients peuvent ajouter des instructions de mappage personnalisées en plus de la configuration de l'analyseur par défaut. Chaque client peut créer son propre ensemble unique d'instructions de mappage personnalisé. Ces instructions de mappage définissent comment extraire et transformer des champs supplémentaires des journaux bruts d'origine en champs UDM. Une extension d'analyseur ne remplace pas l'analyseur par défaut ni celui spécifique au client.
Exemple utilisant un journal de proxy Web Squid
Cette section fournit un exemple de journal de proxy Web Squid et décrit comment les valeurs sont mappées à un enregistrement UDM. Pour obtenir la description de tous les champs du schéma UDM, consultez la liste des champs UDM.
L'exemple de journal de proxy Web Squid contient des valeurs séparées par des espaces. Chaque enregistrement représente un événement et stocke les données suivantes : code temporel, durée, client, code/état du résultat, octets transmis, méthode de requête, URL, utilisateur, code hiérarchique et type de contenu. Dans cet exemple, les champs suivants sont extraits et mappés dans un enregistrement UDM : heure, client, état du résultat, octets, méthode de requête et URL.
1588059648.129 23 192.168.23.4 TCP_HIT/200 904 GET www.google.com/images/sunlogo.png - HIER_DIRECT/203.0.113.52 image/jpeg

Lorsque vous comparez ces structures, notez que seul un sous-ensemble des données de journaux d'origine est inclus dans l'enregistrement UDM. Certains champs sont obligatoires, d'autres sont facultatifs. De plus, seules certaines sections de l'enregistrement UDM contiennent des données. Si l'analyseur ne mappe pas les données du journal d'origine à l'enregistrement UDM, vous ne verrez pas cette section de l'enregistrement UDM dans Google SecOps.

La section metadata stocke l'horodatage de l'événement. Notez que la valeur a été convertie du format EPOCH au format RFC 3339. Cette conversion est facultative. L'horodatage peut être stocké au format EPOCH, avec un prétraitement pour séparer les parties secondes et millisecondes dans des champs distincts.
Le champ metadata.event_type stocke la valeur NETWORK_HTTP, qui est une valeur énumérée identifiant le type d'événement. La valeur de metadata.event_type détermine quels champs UDM supplémentaires sont obligatoires ou facultatifs. Les valeurs product_name et vendor_name contiennent des descriptions claires de l'appareil qui a enregistré le journal d'origine.
Le metadata.event_type d'un enregistrement d'événement UDM n'est pas le même que le log_type défini lors de l'ingestion de données à l'aide de l'API Ingestion. Ces deux attributs stockent des informations différentes.
La section network contient les valeurs de l'événement de journal d'origine. Dans cet exemple, notez que la valeur d'état du journal d'origine a été analysée à partir du champ "code/état du résultat" avant d'être écrite dans l'enregistrement UDM. Seul le result_code
était inclus dans l'enregistrement UDM.

La section principal stocke les informations sur le client à partir du journal d'origine. La section target stocke à la fois l'URL complète et l'adresse IP.
La section security_result stocke l'une des valeurs enum pour représenter l'action enregistrée dans le journal d'origine.
Il s'agit de l'enregistrement UDM au format JSON. Notez que seules les sections contenant des données sont incluses. Les sections src, observer, intermediary, about et extensions ne sont pas incluses.
{
"metadata": {
"event_timestamp": "2020-04-28T07:40:48.129Z",
"event_type": "NETWORK_HTTP",
"product_name": "Squid Proxy",
"vendor_name": "Squid"
},
"principal": {
"ip": "192.168.23.4"
},
"target": {
"url": "www.google.com/images/sunlogo.png",
"ip": "203.0.113.52"
},
"network": {
"http": {
"method": "GET",
"response_code": 200,
"received_bytes": 904
}
},
"security_result": {
"action": "UNKNOWN_ACTION"
}
}
Étapes dans les instructions du parseur
Les instructions de mappage des données dans un analyseur suivent un modèle commun, comme suit :
- Analyser et extraire les données du journal d'origine.
- Manipulez les données extraites. Cela inclut l'utilisation d'une logique conditionnelle pour analyser sélectivement les valeurs, convertir les types de données, remplacer les sous-chaînes dans une valeur, convertir en majuscules ou en minuscules, etc.
- Attribuez des valeurs aux champs UDM.
- Sortez l'enregistrement UDM mappé vers la clé @output.
Analyser et extraire des données du journal d'origine
Définir l'instruction de filtre
L'instruction filter est la première instruction de l'ensemble d'instructions d'analyse.
Toutes les instructions d'analyse supplémentaires sont contenues dans l'instruction filter.
filter {
}
Initialiser les variables qui stockeront les valeurs extraites
Dans l'instruction filter, initialisez les variables intermédiaires que l'analyseur utilisera pour stocker les valeurs extraites du journal.
Ces variables sont utilisées chaque fois qu'un journal individuel est analysé. La valeur de chaque variable intermédiaire sera définie sur un ou plusieurs champs UDM plus loin dans les instructions d'analyse.
mutate {
replace => {
"event.idm.read_only_udm.metadata.product_name" => "Webproxy"
"event.idm.read_only_udm.metadata.vendor_name" => "Squid"
"not_valid_log" => "false"
"when" => ""
"srcip" => ""
"action" => ""
"username" => ""
"url" => ""
"tgtip" => ""
"method" => ""
}
}
Extraire des valeurs individuelles du journal
Google SecOps fournit un ensemble de filtres basés sur Logstash pour extraire des champs à partir des fichiers journaux d'origine. Selon le format du journal, vous utilisez un ou plusieurs filtres d'extraction pour extraire toutes les données du journal. Si la chaîne est :
- Pour le format JSON natif, la syntaxe de l'analyseur est semblable à celle du filtre JSON, qui est compatible avec les journaux au format JSON. Le format JSON imbriqué n'est pas accepté.
- Le format XML et la syntaxe de l'analyseur sont semblables au filtre XML, qui accepte les journaux au format XML.
- Pour les paires clé/valeur, la syntaxe de l'analyseur est semblable au filtre Kv, qui accepte les messages au format clé/valeur.
- Le format CSV et la syntaxe de l'analyseur sont semblables au filtre CSV, qui est compatible avec les messages au format CSV.
- Pour tous les autres formats, la syntaxe de l'analyseur est semblable au filtre GROK avec les modèles GROK intégrés . Il utilise des instructions d'extraction de style Regex.
Google SecOps fournit un sous-ensemble des fonctionnalités disponibles dans chaque filtre. Google SecOps fournit également une syntaxe de mappage de données personnalisée qui n'est pas disponible dans les filtres. Consultez la documentation de référence sur la syntaxe de l'analyseur pour obtenir une description des fonctionnalités compatibles et des fonctions personnalisées.
En reprenant l'exemple de journal de proxy Web Squid, l'instruction d'extraction de données suivante inclut une combinaison de la syntaxe Grok de Logstash et d'expressions régulières.
L'instruction d'extraction suivante stocke les valeurs dans les variables intermédiaires suivantes :
whensrcipactionreturnCodesizemethodusernameurltgtip
Cette instruction utilise également le mot clé overwrite pour stocker les valeurs extraites dans chaque variable. Si le processus d'extraction renvoie une erreur, l'instruction on_error définit not_valid_log sur True.
grok {
match => {
"message" => [
"%{NUMBER:when}\\s+\\d+\\s%{SYSLOGHOST:srcip} %{WORD:action}\\/%{NUMBER:returnCode} %{NUMBER:size} %{WORD:method} (?P<url>\\S+) (?P<username>.*?) %{WORD}\\/(?P<tgtip>\\S+).*"
]
}
overwrite => ["when","srcip","action","returnCode","size","method","url","username","tgtip"]
on_error => "not_valid_log"
}
Manipuler et transformer les valeurs extraites
Google SecOps exploite les fonctionnalités du plug-in de filtre mutate de Logstash pour permettre la manipulation des valeurs extraites du journal d'origine. Google SecOps fournit un sous-ensemble des fonctionnalités disponibles dans le plug-in. Consultez la syntaxe de l'analyseur pour obtenir une description des fonctionnalités compatibles et des fonctions personnalisées, telles que :
- convertir des valeurs en un autre type de données ;
- remplacer les valeurs dans la chaîne ;
- fusionner deux tableaux ou ajouter une chaîne à un tableau. Les valeurs de chaîne sont converties en tableau avant la fusion.
- convertir en minuscules ou en majuscules.
Cette section fournit des exemples de transformation de données basés sur le journal du proxy Web Squid présenté précédemment.
Transformer le code temporel de l'événement
Tous les événements stockés en tant qu'enregistrement UDM doivent comporter un code temporel. Cet exemple vérifie si une valeur pour les données a été extraite du journal. Il utilise ensuite la fonction de date Grok pour faire correspondre la valeur au format d'heure UNIX.
if [when] != "" {
date {
match => [
"when", "UNIX"
]
}
}
Transformer la valeur username
L'exemple d'instruction suivant convertit la valeur de la variable username en minuscules.
mutate {
lowercase => [ "username"]
}
Transformer la valeur action
L'exemple suivant évalue la valeur de la variable intermédiaire action et la remplace par ALLOW, BLOCK ou UNKNOWN_ACTION, qui sont des valeurs valides pour le champ UDM security_result.action. Le champ security_result.action UDM est un type énuméré qui ne stocke que des valeurs spécifiques.
if ([action] == "TCP_DENIED" or [action] == "TCP_MISS" or [action] == "Denied" or [action] == "denied" or [action] == "Dropped") {
mutate {
replace => {
"action" => "BLOCK"
}
}
} else if ([action] == "TCP_TUNNEL" or [action] == "Accessed" or [action] == "Built" or [action] == "Retrieved" or [action] == "Stored") {
mutate {
replace => {
"action" => "ALLOW"
}
}
} else {
mutate {
replace => {
"action" => "UNKNOWN_ACTION" }
}
}
Transformer l'adresse IP cible
L'exemple suivant vérifie la présence d'une valeur dans la variable intermédiaire tgtip.
Si une valeur est trouvée, elle est associée à un modèle d'adresse IP à l'aide d'un modèle Grok prédéfini. En cas d'erreur de correspondance entre la valeur et un modèle d'adresse IP, la fonction on_error définit la propriété not_valid_tgtip sur True. Si la correspondance est établie, la propriété not_valid_tgtip n'est pas définie.
if [tgtip] not in [ "","-" ] {
grok {
match => {
"tgtip" => [ "%{IP:tgtip}" ]
}
overwrite => ["tgtip"]
on_error => "not_valid_tgtip"
}
Modifier le type de données de returnCode et de size
L'exemple suivant convertit la valeur de la variable size en uinteger et celle de la variable returnCode en integer. Cette étape est obligatoire, car la variable size sera enregistrée dans le champ UDM network.received_bytes, qui stocke un type de données int64. La variable returnCode sera enregistrée dans le champ UDM network.http.response_code, qui stocke un type de données int32.
mutate {
convert => {
"returnCode" => "integer"
"size" => "uinteger"
}
}
Attribuer des valeurs aux champs UDM dans un événement
Une fois les valeurs extraites et prétraitées, attribuez-les aux champs d'un enregistrement d'événement UDM. Vous pouvez attribuer des valeurs extraites et des valeurs statiques à un champ UDM.
Si vous renseignez event.disambiguation_key, assurez-vous que ce champ est unique pour chaque événement généré pour le journal donné. Si deux événements différents ont le même disambiguation_key, cela entraînera un comportement inattendu dans le système.
Les exemples d'analyseur de cette section s'appuient sur l'exemple de journal de proxy Web Squid précédent.
Enregistrer le code temporel de l'événement
Chaque enregistrement d'événement UDM doit avoir une valeur définie pour le champ UDM metadata.event_timestamp. L'exemple suivant enregistre le code temporel de l'événement extrait du journal dans la variable intégrée @timestamp. Par défaut, Google Security Operations enregistre cette information dans le champ metadata.event_timestamp de l'UDM.
mutate {
rename => {
"when" => "timestamp"
}
}
Définir le type d'événement
Chaque enregistrement d'événement UDM doit avoir une valeur définie pour le champ UDM metadata.event_type. Ce champ est un type énuméré. La valeur de ce champ détermine les champs UDM supplémentaires qui doivent être renseignés pour que l'enregistrement UDM soit enregistré.
Le processus d'analyse et de normalisation échouera si l'un des champs obligatoires ne contient pas de données valides.
replace => {
"event.idm.read_only_udm.metadata.event_type" => "NETWORK_HTTP"
}
}
Enregistrez les valeurs username et method à l'aide de l'instruction replace.
Les valeurs des champs intermédiaires username et method sont des chaînes. L'exemple suivant vérifie si une valeur valide existe et, si c'est le cas, stocke la valeur username dans le champ UDM principal.user.userid et la valeur method dans le champ UDM network.http.method.
if [username] not in [ "-" ,"" ] {
mutate {
replace => {
"event.idm.read_only_udm.principal.user.userid" => "%{username}"
}
}
}
if [method] != "" {
mutate {
replace => {
"event.idm.read_only_udm.network.http.method" => "%{method}"
}
}
}
Enregistrer le action dans le champ UDM security_result.action
Dans la section précédente, la valeur de la variable intermédiaire action a été évaluée et transformée en l'une des valeurs standards du champ UDM security_result.action.
Les champs UDM security_result et action stockent un tableau d'éléments. Vous devez donc suivre une approche légèrement différente lorsque vous enregistrez cette valeur.
Tout d'abord, enregistrez la valeur transformée dans un champ security_result.action intermédiaire. Le champ security_result est un parent du champ action.
mutate {
merge => {
"security_result.action" => "action"
}
}
Ensuite, enregistrez le champ intermédiaire security_result.action dans le champ UDM security_result. Le champ UDM security_result stocke un tableau d'éléments. La valeur est donc ajoutée à ce champ.
# save the security_result field
mutate {
merge => {
"event.idm.read_only_udm.security_result" => "security_result"
}
}
Stockez l'adresse IP cible et l'adresse IP source à l'aide de l'instruction merge.
Stockez les valeurs suivantes dans l'enregistrement d'événement UDM :
- Valeur de la variable intermédiaire
srcipdans le champ UDMprincipal.ip. - Valeur de la variable intermédiaire
tgtipdans le champ UDMtarget.ip.
Les champs UDM principal.ip et target.ip stockent un tableau d'éléments. Les valeurs sont donc ajoutées à chaque champ.
Les exemples suivants illustrent différentes approches pour enregistrer ces valeurs.
Lors de l'étape de transformation, la variable intermédiaire tgtip a été associée à une adresse IP à l'aide d'un modèle Grok prédéfini. L'exemple d'instruction suivant vérifie si la propriété not_valid_tgtip est définie sur "true", ce qui indique que la valeur tgtip n'a pas pu être associée à un modèle d'adresse IP. Si la valeur est "false", elle enregistre la valeur tgtip dans le champ UDM target.ip.
if ![not_valid_tgtip] {
mutate {
merge => {
"event.idm.read_only_udm.target.ip" => "tgtip"
}
}
}
La variable intermédiaire srcip n'a pas été transformée. L'instruction suivante vérifie si une valeur a été extraite du journal d'origine et, le cas échéant, l'enregistre dans le champ UDM principal.ip.
if [srcip] != "" {
mutate {
merge => {
"event.idm.read_only_udm.principal.ip" => "srcip"
}
}
}
Enregistrer url, returnCode et size à l'aide de l'instruction rename
L'exemple d'instruction suivant stocke les valeurs à l'aide de l'instruction rename :
- La variable
urlest enregistrée dans le champ UDMtarget.url. - La variable intermédiaire
returnCodeest enregistrée dans le champ UDMnetwork.http.response_code. - La variable intermédiaire
sizeest enregistrée dans le champ UDMnetwork.received_bytes.
mutate {
rename => {
"url" => "event.idm.read_only_udm.target.url"
"returnCode" => "event.idm.read_only_udm.network.http.response_code"
"size" => "event.idm.read_only_udm.network.received_bytes"
}
}
Lier l'enregistrement UDM à la sortie
L'instruction finale du mappage de données génère les données traitées dans un enregistrement d'événement UDM.
mutate {
merge => {
"@output" => "event"
}
}
Code complet de l'analyseur
Voici l'exemple de code complet de l'analyseur. L'ordre des instructions ne correspond pas à celui des sections précédentes de ce document, mais le résultat est le même.
filter {
# initialize variables
mutate {
replace => {
"event.idm.read_only_udm.metadata.product_name" => "Webproxy"
"event.idm.read_only_udm.metadata.vendor_name" => "Squid"
"not_valid_log" => "false"
"when" => ""
"srcip" => ""
"action" => ""
"username" => ""
"url" => ""
"tgtip" => ""
"method" => ""
}
}
# Extract fields from the raw log.
grok {
match => {
"message" => [
"%{NUMBER:when}\\s+\\d+\\s%{SYSLOGHOST:srcip} %{WORD:action}\\/%{NUMBER:returnCode} %{NUMBER:size} %{WORD:method} (?P<url>\\S+) (?P<username>.*?) %{WORD}\\/(?P<tgtip>\\S+).*"
]
}
overwrite => ["when","srcip","action","returnCode","size","method","url","username","tgtip"]
on_error => "not_valid_log"
}
# Parse event timestamp
if [when] != "" {
date {
match => [
"when", "UNIX"
]
}
}
# Save the value in "when" to the event timestamp
mutate {
rename => {
"when" => "timestamp"
}
}
# Transform and save username
if [username] not in [ "-" ,"" ] {
mutate {
lowercase => [ "username"]
}
}
mutate {
replace => {
"event.idm.read_only_udm.principal.user.userid" => "%{username}"
}
}
if ([action] == "TCP_DENIED" or [action] == "TCP_MISS" or [action] == "Denied" or [action] == "denied" or [action] == "Dropped") {
mutate {
replace => {
"action" => "BLOCK"
}
}
} else if ([action] == "TCP_TUNNEL" or [action] == "Accessed" or [action] == "Built" or [action] == "Retrieved" or [action] == "Stored") {
mutate {
replace => {
"action" => "ALLOW"
}
}
} else {
mutate {
replace => {
"action" => "UNKNOWN_ACTION" }
}
}
# save transformed value to an intermediary field
mutate {
merge => {
"security_result.action" => "action"
}
}
# save the security_result field
mutate {
merge => {
"event.idm.read_only_udm.security_result" => "security_result"
}
}
# check for presence of target ip. Extract and store target IP address.
if [tgtip] not in [ "","-" ] {
grok {
match => {
"tgtip" => [ "%{IP:tgtip}" ]
}
overwrite => ["tgtip"]
on_error => "not_valid_tgtip"
}
# store target IP address
if ![not_valid_tgtip] {
mutate {
merge => {
"event.idm.read_only_udm.target.ip" => "tgtip"
}
}
}
}
# convert the returnCode and size to integer data type
mutate {
convert => {
"returnCode" => "integer"
"size" => "uinteger"
}
}
# save url, returnCode, and size
mutate {
rename => {
"url" => "event.idm.read_only_udm.target.url"
"returnCode" => "event.idm.read_only_udm.network.http.response_code"
"size" => "event.idm.read_only_udm.network.received_bytes"
}
# set the event type to NETWORK_HTTP
replace => {
"event.idm.read_only_udm.metadata.event_type" => "NETWORK_HTTP"
}
}
# validate and set source IP address
if [srcip] != "" {
mutate {
merge => {
"event.idm.read_only_udm.principal.ip" => "srcip"
}
}
}
# save event to @output
mutate {
merge => {
"@output" => "event"
}
}
} #end of filter
Vous avez encore besoin d'aide ? Obtenez des réponses de membres de la communauté et de professionnels Google SecOps.