从 Oracle 迁移到 BigQuery
本文档提供有关从 Oracle 迁移到 BigQuery 的概要指南。其中介绍了基本架构差异,并提出了从 Oracle RDBMS(包括 Exadata)上运行的数据仓库和数据集市迁移到 BigQuery 的建议方法。本文档同时适用于 Exadata、ExaCC 和 Oracle Autonomous Data Warehouse,因为它们使用兼容的 Oracle 软件。
本文档适用于希望从 Oracle 迁移到 BigQuery 并解决迁移过程中的技术挑战的企业架构师、DBA、应用开发者和 IT 安全专业人员。
您还可以使用批量 SQL 转换来批量迁移 SQL 脚本,或使用交互式 SQL 转换来转换临时查询。两个预览版的工具都支持 Oracle SQL、PL/SQL 和 Exadata。
迁移前
为确保数据仓库迁移成功,请在项目时间轴的早期阶段开始规划迁移策略。如需了解如何系统地规划迁移工作,请参阅迁移的内容和方式:迁移框架。
BigQuery 容量规划
在后台,BigQuery 中的分析吞吐量以槽为单位衡量。BigQuery 槽是执行 SQL 查询所需的 Google 专有的计算容量单位。
BigQuery 会在执行时不断计算查询所需的槽数,但会根据公平调度器为查询分配槽。
为 BigQuery 槽进行容量规划时,您可以选择以下定价模式:
按需价格:在按需价格模式下,BigQuery 按处理的字节数(数据大小)收费,因此您只需为运行的查询付费。如需详细了解 BigQuery 如何确定数据大小,请参阅数据大小计算。由于槽决定了底层计算容量,因此您可以根据所需的槽数(而不是处理的字节数)来支付 BigQuery 使用费。默认情况下, Google Cloud 项目的槽数上限为 2,000。
基于容量的价格:使用基于容量的价格,您可以购买 BigQuery 槽预留(至少 100 个),而无需为运行的查询处理的字节数付费。我们建议为企业数据仓库工作负载提供基于容量的价格,这些工作负载通常可以看到许多具有可预测消耗的并发报告和提取-加载-转换 (ELT) 查询。
为了帮助估算槽,我们建议您设置使用 Cloud Monitoring 监控 BigQuery 和使用 BigQuery 分析审核日志。许多客户会使用 Looker Studio(例如,请参阅 Looker Studio 信息中心的开源示例)、Looker 或 Tableau 作为前端,用于直观呈现 BigQuery 审核日志数据,尤其是针对跨查询和项目的槽使用量。您还可以使用 BigQuery 的系统表数据来监控作业和预留的槽利用率。如需查看示例,请参阅 Looker Studio 信息中心的开源示例。
定期监控和分析槽利用率可帮助您估算组织在 Google Cloud上发展时所需的总槽数。
例如,假设您最初预留 4,000 个 BigQuery 槽以同时运行 100 个中等复杂度查询。如果您发现查询的执行计划中的等待时间较长,并且您的信息中心显示槽利用率较高,则可能表示您需要额外的 BigQuery 槽来支持工作负载。如果您想通过每年或三年承诺自行购买槽,则可以使用 Google Cloud 控制台或 bq 命令行工具开始使用 BigQuery 预留。
如果您对当前方案和上述选项有任何疑问,请与您的销售代表联系。
Google Cloud中的安全性
以下部分介绍了常见的 Oracle 安全控制措施,以及如何确保数据仓库在 Google Cloud环境中受到保护。
Identity and Access Management (IAM)
Oracle 提供用户、权限、角色和个人资料来管理资源访问权限。
BigQuery 使用 IAM 来管理资源访问权限,并提供对资源和操作的集中访问权限管理。BigQuery 中提供的资源类型包括组织、项目、数据集、表和视图。在 IAM 政策层次结构中,数据集是项目的子资源。表从其所属的数据集继承权限。
如需授予对某项资源的访问权限,请为用户、群组或服务账号分配一个或多个角色。组织和项目角色会影响运行作业或管理项目的能力,而数据集角色则会影响访问或修改项目内数据的能力。
IAM 提供以下类型的角色:
- 预定义角色旨在为常见使用场景和访问权限控制模式提供支持。预定义角色针对特定服务提供精细访问权限,并由 Google Cloud管理。
基本角色包括 Owner、Editor 和 Viewer 角色。
自定义角色根据用户指定的权限列表提供精细访问权限。
如果您向某用户同时分配了预定义角色和基本角色,则授予的权限是每个角色所拥有权限的并集。
行级安全性
Oracle Label Security (OLS) 允许逐行限制数据访问。行级安全性的一个典型用例是限制销售人员对其管理的账号的访问权限。通过实现行级安全性,您可以获得精细的访问权限控制。
如需在 BigQuery 中实现行级安全性,您可以使用授权视图和行级访问权限政策。如需详细了解如何设计和实现这些政策,请参阅 BigQuery 行级安全性简介。
全盘加密
Oracle 为静态数据和传输加密提供透明数据加密 (TDE) 和网络加密。TDE 需要“高级安全”选项,该选项需要单独许可。
默认情况下,无论来源或其他任何条件如何,BigQuery 都会加密所有静态和传输中数据,并且此功能无法关闭。如果用户希望在 Cloud Key Management Service 中控制和管理密钥加密密钥,则 BigQuery 还支持客户管理的加密密钥 (CMEK)。如需详细了解 Google Cloud的加密,请参阅默认静态加密和传输加密。
数据遮盖和隐去
Oracle 在 Real Application Testing 中使用数据遮盖以及数据隐去,让您可以遮盖(隐去)应用发出的查询返回的数据。
BigQuery 支持列级动态数据遮盖。您可以使用数据遮盖功能来有选择地针对某些用户组对列数据进行遮盖,但仍然允许他们访问该列。
您可以使用敏感数据保护来识别和遮盖 BigQuery 上的敏感个人身份信息 (PII)。
BigQuery 与 Oracle 比较
本部分介绍 BigQuery 和 Oracle 之间的主要区别。这些亮点可帮助您确定迁移障碍和规划所需更改。
系统架构
Oracle 和 BigQuery 的主要区别之一是 BigQuery 是一个无服务器云 EDW,具有单独的存储空间和计算层,可基于查询的需求进行扩缩。鉴于 BigQuery 属于无服务器产品的性质,您不会受到硬件决策的限制;而是您可以通过预留为您的查询和用户请求更多资源。BigQuery 也不需要配置底层软件和基础架构,例如操作系统 (OS)、网络系统和存储系统(包括扩缩和高可用性)。BigQuery 负责扩缩、管理和行政操作。下图展示了 BigQuery 存储层次结构。
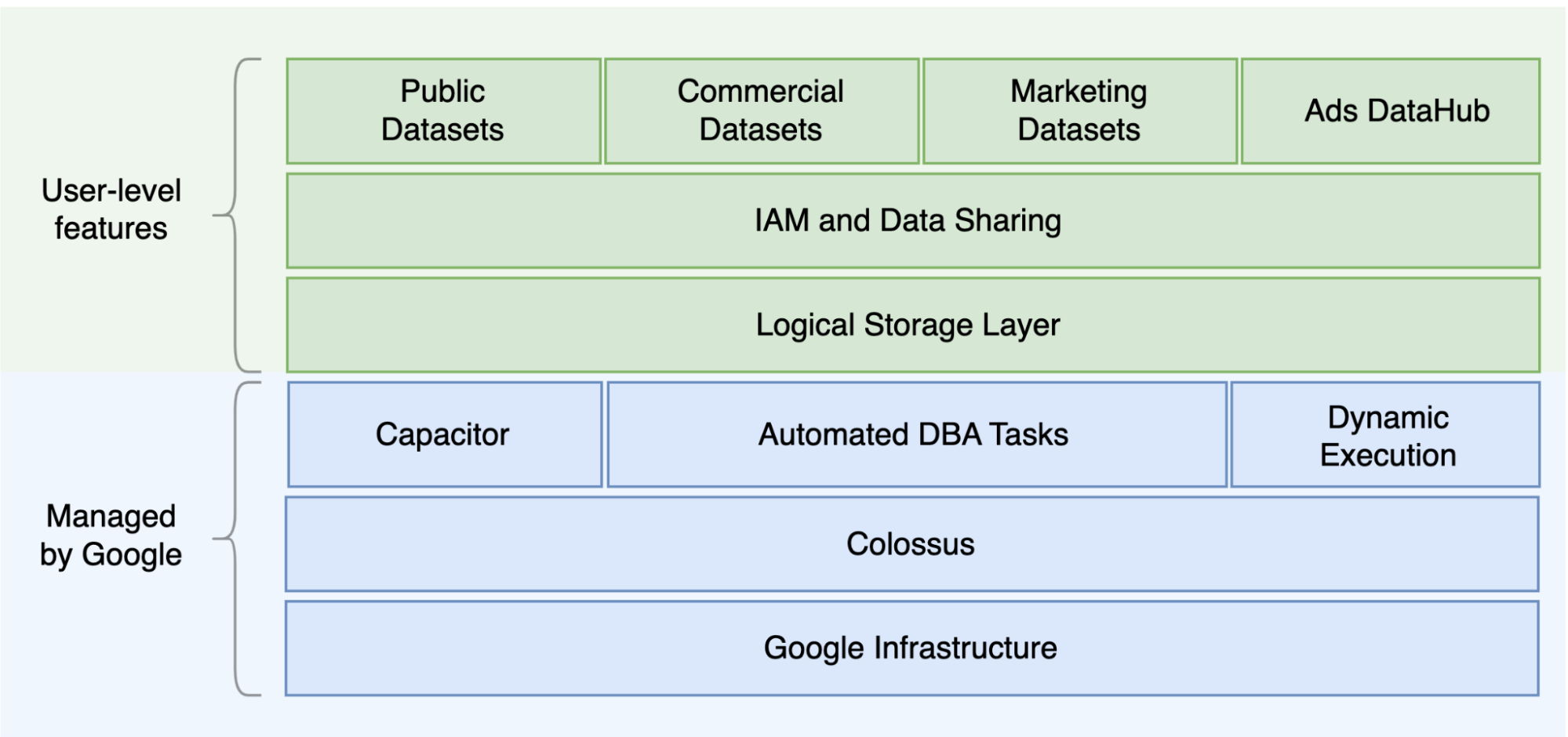
了解底层存储和查询处理架构(例如存储(Colossus)与查询执行(Dremel)之间的分离,以及Google Cloud 如何分配资源 [Borg])有助于了解行为差异,并优化查询性能和成本效益。如需了解详情,请参阅 BigQuery、Oracle 和 Exadata 的参考系统架构。
数据和存储架构
数据和存储结构是任何数据分析系统的重要部分,因为它会影响查询性能、费用、可扩缩性和效率。
BigQuery 将数据存储和计算分开,并将数据存储在 Colossus 中,其中数据以列式格式(称为 Capacitor)进行压缩和存储。
BigQuery 会直接使用压缩数据进行操作,而不使用 Capacitor 进行解压缩。BigQuery 提供数据集作为最高抽象层,来组织对表的访问权限(如上图所示)。架构和标签可用于进一步整理表。BigQuery 提供分区来提高查询性能和费用以及管理信息生命周期。存储资源在您使用它们时进行分配,并在您移除数据或删除表时释放。
Oracle 使用按分段组织的 Oracle 块格式以行格式存储数据。架构(归用户所有)用于组织表和其他数据库对象。从 Oracle 12c 开始,多租户用于在一个数据库实例中创建可插入数据库,以便进一步隔离。分区用于改进查询性能和信息生命周期操作。Oracle 为独立和 Real Application Clusters (RAC) 数据库(如 ASM、操作系统文件系统和集群文件系统)提供了多种存储选项。
Exadata 在存储单元服务器中提供优化的存储基础架构,并允许 Oracle 服务器使用 ASM 透明地访问此数据。Exadata 提供 Hybrid Columnar Compression (HCC) 选项,使得用户能够压缩表和分区。
Oracle 需要预先预配存储空间容量、仔细调整大小和自动递增分段、数据文件和表空间上的配置。
查询执行和性能
BigQuery 可管理性能并在查询级别进行扩缩,从而最大限度地提升费用性能。BigQuery 使用多种优化,例如:
BigQuery 在加载数据时收集列统计信息,并包括诊断查询计划和时间信息。查询资源根据查询类型和复杂度进行分配。每个查询使用一定数量的槽,槽是包含一定数量 CPU 和 RAM 的计算单元。
Oracle 提供数据统计信息收集作业。数据库优化器使用统计信息提供最优执行计划。可能需要索引以执行快速行查询和联接操作。Oracle 还提供内存中列存储区,以便进行内存分析。Exadata 提供多项性能改进,例如单元智能扫描、存储索引、闪存缓存以及存储服务器和数据库服务器之间的 InfiniBand 连接。Real Application Clusters (RAC) 可用于使用相同的底层存储来实现服务器高可用性和扩缩数据库 CPU 密集型应用。
使用 Oracle 优化查询性能需要仔细考虑这些选项和数据库参数。Oracle 提供了多种工具,例如 Active Session History (ASH)、Automatic Database Diagnostic Monitor (ADDM)、Automatic Workload Repository (AWR) 报告、SQL 监控和 Tuning Advisor,以及 Undo 和 Memory Tuning Advisors 以调整性能。
敏捷分析
在 BigQuery 中,您可以启用不同的项目、用户和群组以查询不同项目中的数据集。通过分离查询执行,自主团队可以在自己的项目中正常工作,而不会影响其他用户和项目(通过将槽配额和查询结算与其他项目以及托管数据集的项目分离开来)。
高可用性、备份和灾难恢复
Oracle 提供 Data Guard 作为灾难恢复和数据库复制解决方案。可以配置 Real Application Clusters (RAC) 以实现服务器可用性。 可以配置 Recovery Manager (RMAN) 备份以用于数据库和归档日志备份,也可以用于还原和恢复操作。闪回数据库功能可用于数据库闪回,以将数据库快退到特定时间点。撤消表空间会保存表快照。可以使用闪回查询和“as of”查询子句查询旧快照,具体取决于之前完成的 DML/DDL 操作和撤消保留设置。在 Oracle 中,数据库的整体完整性应在基于系统元数据、撤消和对应的表空间的表空间中进行管理,因为强一致性对于 Oracle 备份非常重要,恢复过程应包含完整的主数据。如果 Oracle 不需要时间点恢复,则可以在表架构级层安排导出操作。
BigQuery 是完全代管式,并且与传统的数据库系统不同,它具有完整的备份功能。您无需考虑服务器、存储故障、系统错误和物理数据损坏。BigQuery 会根据数据集位置在不同数据中心之间复制数据,以最大限度地提高可靠性和可用性。BigQuery 多区域功能可跨不同区域复制数据,并防止区域内的单个可用区不可用。BigQuery 单区域功能可跨同一区域内的不同可用区复制数据。
借助 BigQuery,您可以使用时间旅行查询过去七天的表的历史快照,并在两天内恢复已删除的表。您可以通过使用快照语法 (dataset.table@timestamp) 来复制已删除的表(以便还原该表)。您可以导出 BigQuery 表中的数据以满足额外的备份需求,例如从意外用户操作中恢复。一贯用于现有数据仓库 (DWH) 系统的成熟备份策略和时间表可用于备份。
批量操作和快照技术允许 BigQuery 使用不同的备份策略,因此您无需频繁导出未更改的表和分区。在加载或 ETL 操作完成后,一个分区或表的导出备份就足够了。为了降低备份费用,您可以将导出文件存储在 Cloud Storage Nearline Storage 或 Coldline Storage 并定义生命周期政策在一定时间后删除文件,具体取决于数据保留要求。
缓存
BigQuery 提供每个用户的缓存,如果数据未更改,查询结果会缓存大约 24 小时。如果从缓存中检索结果,则查询不会产生任何费用。
Oracle 为数据和查询结果提供多种缓存,例如缓冲区缓存、结果缓存、Exadata Flash 缓存和内存中列存储区。
连接
BigQuery 会处理连接管理,不需要您进行任何服务器端配置。BigQuery 提供 JDBC 和 ODBC 驱动程序。您可以使用 Google Cloud 控制台或 bq command-line tool 进行交互式查询。您可以使用 REST API 和客户端库以程序化方式与 BigQuery 进行交互。您可以直接连接 Google 表格与 BigQuery,并使用 ODBC 和 JDBC 驱动程序连接到 Excel。如果您要查找桌面客户端,可以使用 DBeaver 等免费工具。
Oracle 提供了监听器、服务、服务处理程序、多个配置和调节参数以及共享和专用服务器来处理数据库连接。Oracle 提供 JDBC、JDBC Thin、ODBC 驱动程序、Oracle 客户端和 TNS连接。RAC 配置需要扫描监听器、扫描 IP 地址和扫描名称。
价格和许可
Oracle 需要数据库许可和支持费用,具体取决于用于下列各项的核心数量:数据库版本和数据库选项,例如 RAC、多租户、Active Data Guard、分区、内存中、Real Application Testing、GoldenGate 以及 Spatial and Graph。
BigQuery 根据存储、查询和流式插入使用情况提供灵活的价格选项。BigQuery 为需要在特定区域预测费用和槽容量的客户提供了基于容量的价格模式。用于流式插入和加载的槽不计入项目槽容量。如需决定要为数据仓库购买的槽数,请参阅 BigQuery 容量规划。
对于存储时间超过 90 天的未修改数据,BigQuery 还会自动将存储费用减半。
标签
BigQuery 数据集、表和视图可以使用键值对添加标签。标签可用于区分存储费用和内部退款。
监控和审核日志记录
Oracle 提供不同级别和种类数据库审核选项、审核保险柜和数据库防火墙功能,它们需要单独许可。Oracle 提供 Enterprise Manager 进行数据库监控。
对于 BigQuery,Cloud Audit Logs 同时用于数据访问日志和审核日志(默认处于启用状态)。数据访问日志保留 30 天,其他系统事件和管理员活动日志保留 400 天。如果需要更长的保留时间,您可以将日志导出到 BigQuery、Cloud Storage 或 Pub/Sub,如 Google Cloud中的安全日志分析中所述。如果需要与现有突发事件监控工具集成,则 Pub/Sub 可用于导出,而且应在现有工具上进行自定义开发,以从 Pub/Sub 中读取日志。
审核日志包括所有 API 调用、查询语句和作业状态。您可以使用 Cloud Monitoring 来监控槽分配、查询中扫描和存储的字节数以及其他 BigQuery 指标。BigQuery 查询计划和时间轴可用于分析查询阶段和性能。
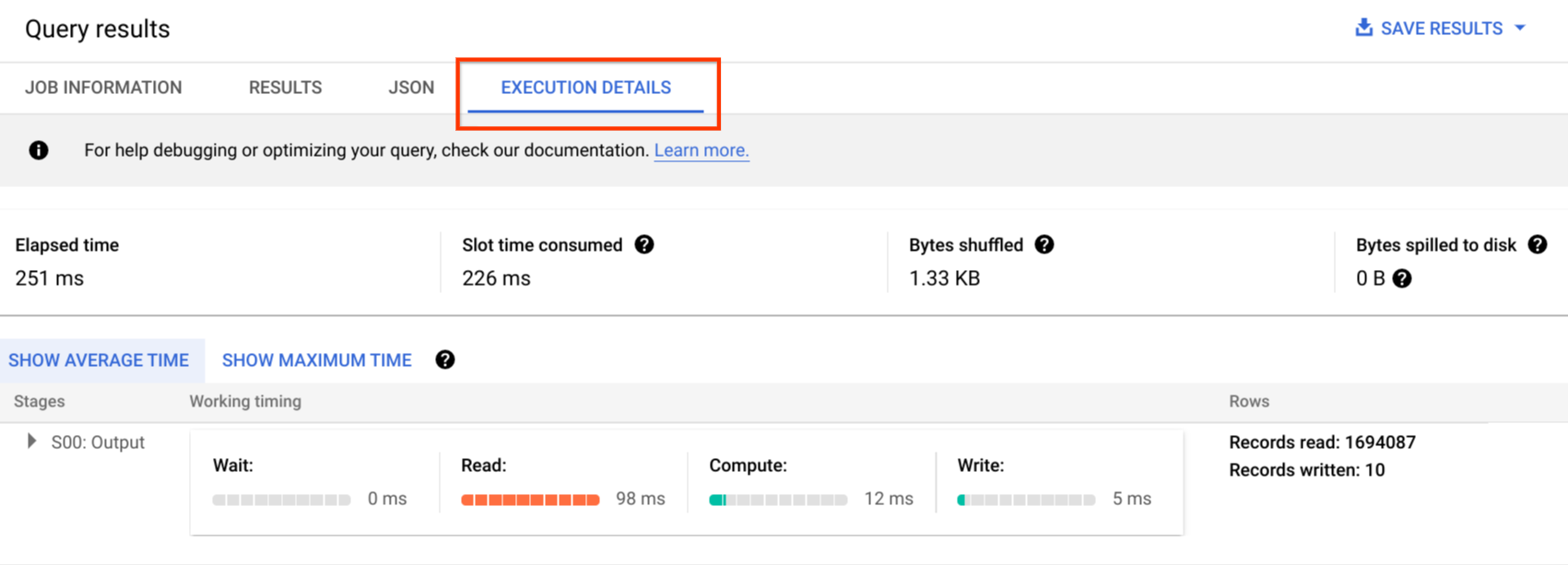
您可以使用错误消息表来排查查询作业和 API 错误。如需区分每个查询或作业的槽分配,您可以使用此实用程序,它对于使用基于槽容量的价格并且将项目分布在多个团队中的客户非常有用。
维护、升级和版本
BigQuery 是一项全托管式服务,无需您执行任何维护或升级。BigQuery 不提供不同的版本。升级是持续的,不需要停机或系统性能。如需了解详情,请参阅版本说明。
Oracle 和 Exadata 需要您执行数据库和底层基础架构级修补、升级和维护。Oracle 有许多版本,我们计划每年发布一个新的主要版本。虽然新版本具有向后兼容性,但查询性能、上下文和功能可以更改。
可能有一些应用需要特定版本,例如 10g、11g 或 12c。主要的数据库升级需要仔细规划和测试。从不同版本迁移可能包括在查询子句和数据库对象方面的不同技术转换需求。
工作负载
Oracle Exadata 支持混合工作负载,包括 OLTP 工作负载。BigQuery 专为分析而设计,不用于处理 OLTP 工作负载。应将使用同一 Oracle 的 OLTP 工作负载迁移到Google Cloud中的 Cloud SQL、Spanner 或 Firestore。Oracle 提供了其他选项,例如 Advanced Analytics 和 Spatial and Graph。这些工作负载可能需要重写,以便迁移到 BigQuery。如需了解详情,请参阅迁移 Oracle 选项。
参数和设置
Oracle 提供并需要许多参数,这些参数要在操作系统、数据库、RAC、ASM 和监听器级别进行配置和调整,以用于不同的工作负载和应用。BigQuery 是一项全托管式服务,无需您配置任何初始化参数。
限制和配额
Oracle 根据基础架构、硬件容量、参数、软件版本和许可实施了硬性限制和软性限制。BigQuery 对特定操作和对象有配额和限制。
BigQuery 预配
BigQuery 是一个平台即服务 (PaaS) 和 Cloud 大规模并行处理数据仓库。在 Google 管理后端时,它的容量会扩缩,而无需用户进行任何干预。因此,与许多 RDBMS 系统不同,BigQuery 不需要您在使用之前预配资源。BigQuery 会根据您的使用规律动态分配存储资源和查询资源。 存储资源在您使用它们时进行分配,并在您移除数据或删除表时释放。查询资源根据查询类型和复杂度进行分配。 每个查询都使用槽。使用最终公平性调度程序,因此在短期内,某些查询可能会获得更高份额的槽,但调度器最终会纠正这种情况。
在传统虚拟机术语中,BigQuery 可提供以下两个两者的等效项目:
- 按秒计费
- 每秒扩缩
为了完成此任务,BigQuery 会执行以下操作:
- 保留大量资源,以避免快速扩缩。
- 使用多租户资源可即时一次性分配大数据块,并且几秒钟即可完成。
- 通过规模经济,经济高效地向用户分配资源。
- 您只需为运行的作业(而不是部署的资源)付费,因此您只需为使用的资源付费。
如需详细了解价格,请参阅了解 BigQuery 快速扩缩和简单价格。
架构迁移
为了将数据从 Oracle 迁移到 BigQuery,您必须知道 Oracle 数据类型和 BigQuery 映射。
Oracle 数据类型和 BigQuery 映射
Oracle 数据类型与 BigQuery 数据类型不同。如需详细了解 BigQuery 数据类型,请参阅官方文档。
如需查看 Oracle 和 BigQuery 数据类型之间的详细比较,请参阅 Oracle SQL 转换指南。
索引
在许多分析工作负载中,使用列式表而不是行存储。这大幅增加了基于列的操作,并避免了使用索引进行批量分析。BigQuery 还会以列式格式存储数据,因此在 BigQuery 中不需要索引。如果分析工作负载需要单个较小的基于行的访问权限,则 Bigtable 是更好的替代方案。如果工作负载需要采用高度关系一致性进行事务处理,则 Spanner 或 Cloud SQL 是更好的替代方案。
总而言之,在 BigQuery 中进行批量分析不需要也不提供索引。可以使用分区或聚类。如需详细了解如何调整和改善 BigQuery 中的查询性能,请参阅优化查询性能简介。
视图
与 Oracle 类似,BigQuery 允许创建自定义视图。但是,BigQuery 中的视图不支持 DML 语句。
具体化视图
具体化视图通常用于缩短一次写入多次读取类型报告和工作负载的报告渲染时间。
Oracle 提供了具体化视图以提高视图性能,只需创建和维护表来保存查询结果数据集即可。您可以通过两种方式刷新 Oracle 中的具体化视图:提交时和按需。
BigQuery 中也提供了具体化视图功能。BigQuery 利用来自具体化视图的预计算结果,并尽可能只从基表中读取增量更改以计算最新结果。
Looker Studio 或其他现代 BI 工具中的缓存功能还可以提高性能,并且无需重新运行同一查询,从而节省费用。
表分区
表分区在 Oracle 数据仓库中广泛使用。与 Oracle 相比,BigQuery 不支持分层分区。
BigQuery 实现三种类型的表分区,允许查询根据分区列指定谓词过滤条件,以减少扫描的数据量。
如需详细了解 BigQuery 中分区表的限制和配额,请参阅分区表简介。
如果 BigQuery 限制影响迁移的数据库的功能,请考虑使用分片而不是分区。
此外,BigQuery 不支持 EXCHANGE PARTITION、SPLIT PARTITION,也无法将非分区表转换为分区表。
聚簇
聚簇可帮助您高效地整理和检索存储在经常一起访问的多个列中的数据。但是,Oracle 和 BigQuery 具有不同的聚簇效果。在 BigQuery 中,如果表通常针对特定列进行过滤和聚合,请使用聚簇。对于从 Oracle 迁移列表分区或按索引组织的表,可以考虑使用聚簇功能。
临时表
临时表通常用于 Oracle ETL 流水线。临时表在用户会话期间保存数据。此数据会在会话结束时自动删除。
BigQuery 使用临时表来缓存未写入永久表的查询结果。查询完成后,临时表最多存在 24 小时。这些表在特殊数据集中创建并随机命名。您还可以创建临时表供自己来使用。如需了解详情,请参阅临时表。
外部表
与 Oracle 类似,BigQuery 允许您查询外部数据源。BigQuery 支持直接从外部数据源查询数据,包括:
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google 云端硬盘
数据建模
星型或雪花型数据模型可以高效地用于分析存储,通常用于 Oracle Exadata 上的数据仓库。
反规范化表消除了费用高昂的联接操作,并且在大多数情况下,可在 BigQuery 中提供更好的分析性能。BigQuery 还支持星型和雪花型数据模型。如需详细了解 BigQuery 上数据仓库设计,请参阅设计架构。
行格式与列格式以及服务器限制与无服务器
Oracle 使用表行存储在数据块中的行格式,因此根据特定列的过滤和聚合,提取分析查询的块中不需要的列。
Oracle 具有完全共享的架构,并将固定的硬件资源依赖项(例如内存和存储空间)分配给服务器。这是搭建许多数据建模技术的两大主力;这些技术不断发展,旨在提高分析查询的存储效率和性能。星型和雪花型架构以及数据保险柜建模是其中之一。
BigQuery 使用列式格式来存储数据,并且没有固定的存储空间和内存限制。此架构使您可以根据读取和业务需求进一步反规范化和设计架构,从而降低复杂程度并提高灵活性、可扩缩性和性能。
反规范化
关系型数据库标准化的主要目标之一是减少数据冗余。虽然此模型最适合使用行格式的关系型数据库,但数据反规范化更适用于列式数据库。如需详细了解 BigQuery 中的数据反规范化和其他查询优化策略的优势,请参阅反规范化。
展平现有架构的技巧
BigQuery 技术利用列式数据访问和处理、内存中存储和分布式处理的组合来提供高质量的查询性能。
设计 BigQuery DWH 架构时,较之使用多个 DWH 维度表,在平面表结构中创建事实表(将所有维度表整合为事实表中的单个记录)更适合存储利用率。除了利用率较低之外,在 BigQuery 中使用平面表会导致 JOIN 使用量减少。下图展示了展平架构的示例。
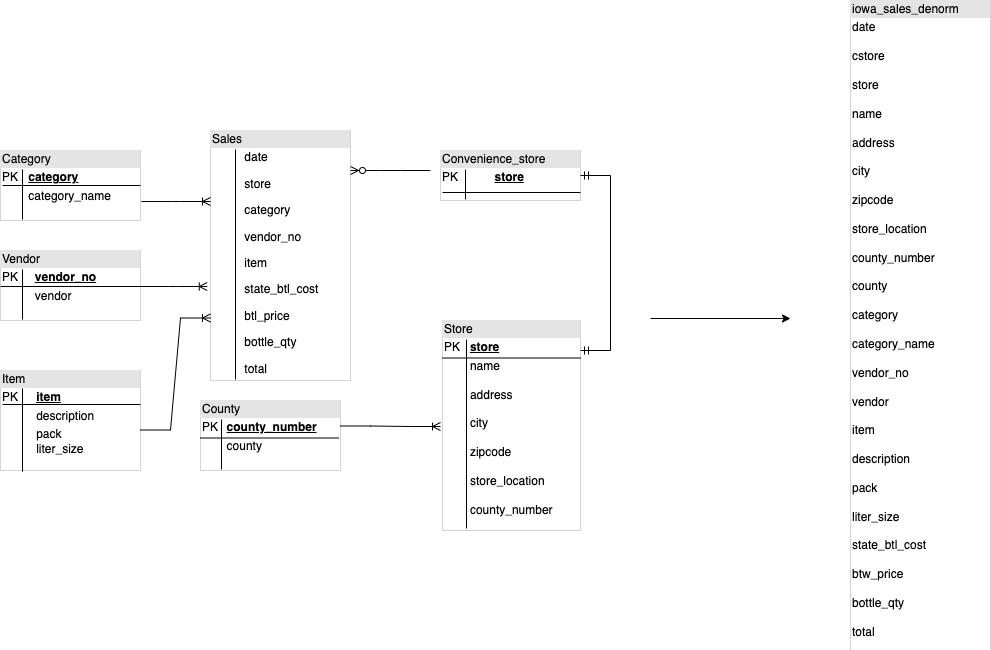
展平星型架构的示例
图 1 展示了一个虚构的销售数据库,其中包含四个表:
- 订单/销售额表(事实表)
- 员工表
- 位置表
- 客户表
销售额表的主键是 OrderNum,其中还包含其他三个表的外键。
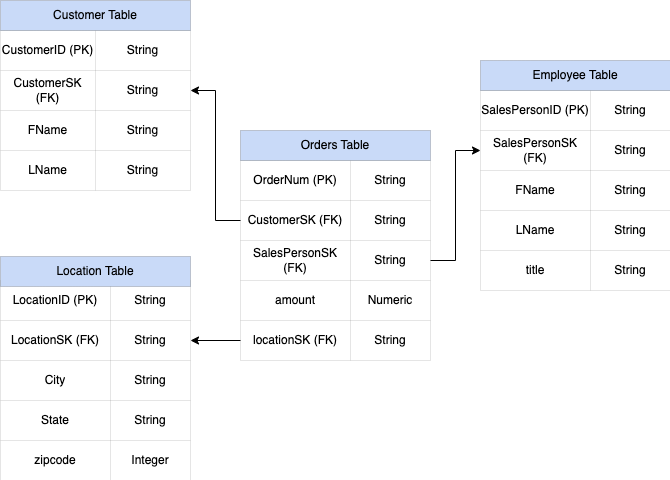
图 1:星型架构中的销售数据示例
样本数据
订单/事实表内容
| OrderNum | CustomerID | SalesPersonID | amount | Location |
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
员工表内容
| SalesPersonID | FName | LName | title |
| 1 | Alex | Smith | 销售助理 |
| 4 | Lisa | Doe | 销售助理 |
| 12 | John | Doe | 销售助理 |
客户表内容
| CustomerID | FName | LName |
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
位置表内容
| Location | city | city | city |
| 18 | Bronx | NY | 10452 |
| 26 | Mountain View | CA | 90210 |
| 27 | 芝加哥 | IL | 60613 |
查询以使用 LEFT OUTER JOIN 展平数据
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
展平数据的输出
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | amount | Location | city | state | zipcode |
| O-1 | 1234 | Amanda | Lee | 12 | John | Doe | 234.22 | 18 | Bronx | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | 芝加哥 | IL | 60613 |
| O-3 | 12 | John | Doe | 14.66 | 18 | Bronx | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Doe | 182.00 | 26 | 山
视图 |
CA | 90210 |
嵌套和重复字段
为了通过关系型架构(例如保存维度表和事实表的星型和雪花型架构)设计和创建 DWH 架构,BigQuery 提供了嵌套和重复字段功能。因此,关系的保留方式与关系规范化(或部分规范化)DWH 架构类似,而不会影响性能。如需了解详情,请参阅性能最佳做法。
为了更好地了解嵌套和重复字段的实现,请查看 CUSTOMERS 表和 ORDER/SALES 表的简单关系架构。它们是两个不同的表,每个实体对应一个表,而定义关系时,使用主键和外键等键作为使用 JOIN 进行查询时表之间的关联。借助 BigQuery 嵌套和重复字段,您可以在单个表中保留实体之间的相同关系。这可以通过包含所有客户数据来实现,而订单数据是针对每个客户的嵌套的。如需了解详情,请参阅指定嵌套和重复的列。
如需将平面结构转换为嵌套或重复的架构,请按如下所示嵌套字段:
- 将
CustomerID、FName、LName嵌套到名为Customer的新字段中。 - 将
SalesPersonID、FName、LName嵌套到名为Salesperson的新字段中。 - 将
LocationID、city、state、zip code嵌套到名为Location的新字段中。
OrderNum 和 amount 字段不是嵌套字段,因为它们表示唯一元素。
您需要使架构足够灵活,以允许每个订单拥有多个客户:主要客户和次要客户。客户字段被标记为重复。生成的架构如图 2 所示,它说明了嵌套的字段和重复的字段。
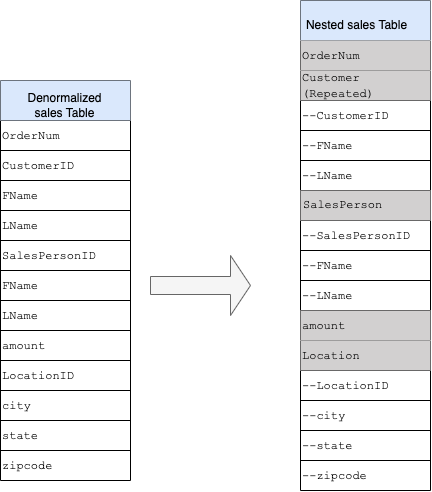
图 2:嵌套结构的逻辑表示
在某些情况下,使用嵌套和重复字段进行反规范化不会提高性能。如需详细了解限制,请参阅指定表架构中嵌套和重复的列。
代理键
常见做法是标识表中具有唯一键的行。Oracle 通常使用序列来创建这些密钥。在 BigQuery 中,您可以使用 row_number 和 partition by 函数创建代理密钥。如需了解详情,请参阅 BigQuery 和代理键:一种实际的方法。
跟踪更改和历史记录
在规划 BigQuery DWH 迁移时,请考虑缓慢变化维度 (SCD) 的概念。一般来说,术语 SCD 描述了在维度表中进行更改(DML 操作)的过程。
出于多种原因,传统数据仓库使用不同类型来处理数据更改,并且将历史数据保存在缓慢变化的维度中。前面讨论的硬件限制和效率要求需要使用这些类型。由于该存储比计算更便宜,并且可无限扩缩,因此如果使用数据冗余和重复可以让 BigQuery 加快查询速度,则建议使用。您可以使用数据快照技术,将整个数据加载到新的每日分区中。
特定于角色和特定于用户的视图
如果用户属于不同的团队,并且应该只能看到所需的记录和结果,请使用特定于角色的视图和特定于用户的视图。
BigQuery 支持列级安全性和行级安全性。列级安全性通过政策标记或基于类型的数据分类,提供针对敏感列的细化访问权限。行级安全性,可让您过滤数据,并在符合用户条件时启用对表中特定行的访问权限。
数据迁移
本部分介绍从 Oracle 到 BigQuery 的数据迁移,包括初始加载、变更数据捕获 (CDC) 和 ETL/ELT 工具和方法。
迁移活动
建议通过确定适当的迁移使用场景分阶段执行迁移。您可以使用多种工具和服务将数据从 Oracle 迁移到 Google Cloud。虽然此列表并不详尽,但确实可让您了解迁移工作的规模和范围。
从 Oracle 导出数据:如需了解详情,请参阅初始加载和从 Oracle 到 BigQuery 的 CDC 和流式提取。ETL 工具可用于初始加载。
数据暂存(在 Cloud Storage 中):对于从 Oracle 导出的数据,Cloud Storage 是推荐的着陆区(暂存区域)。Cloud Storage 旨在快速、灵活地提取结构化或非结构化数据。
ETL 流程:如需了解详情,请参阅 ETL/ELT 迁移。
将数据直接加载到 BigQuery 中:您可以直接从 Cloud Storage、Dataflow 或实时流式传输将数据加载到 BigQuery 中。如果需要数据转换,请使用 Dataflow。
初始加载
将初始数据从现有 Oracle 数据仓库迁移到 BigQuery 可能与增量 ETL/ELT 流水线不同,具体取决于数据大小和网络带宽。如果数据大小为几个 TB 级,则可以使用相同的 ETL/ELT 流水线。
如果数据达到几 TB,则转储数据并使用 gcloud storage 进行转移比使用类似 JdbcIO 的编程数据库提取方法更高效。因为程序化方法可能需要进行更精细的性能调整。如果数据大小超过数 TB,且数据存储在云或在线存储空间(例如 Amazon Simple Storage Service (Amazon S3)),请考虑使用 BigQuery Data Transfer Service。对于大规模转移(尤其是在网络带宽有限的情况下进行的转移),Transfer Appliances 是一个有用的选项。
初始加载的限制
在规划数据迁移时,请考虑以下事项:
- Oracle DWH 数据大小:架构的源大小对于选择的数据转移方法的权重很大,尤其是在数据大小较大(TB 级或更高)的情况下。当数据大小相对较小时,数据转移过程可以用较少的步骤完成。处理大规模数据大小会使整个过程更复杂。
停机时间:决定是否将停机时间迁移到 BigQuery 非常重要。为减少停机时间,您可以批量加载稳定的历史数据,并使用 CDC 解决方案来满足转移过程中发生的更改。
价格:在某些情况下,您可能需要第三方集成工具(例如 ETL 或复制工具),这些工具需要额外的许可。
初始数据转移(批处理)
使用批处理方法进行的数据传输表明数据会在单个进程中一致地导出(例如,将 Oracle DWH 架构数据导出到 CSV、Avro 或 Parquet 文件或者导入到 Cloud Storage),以在 BigQuery 上创建数据集。ETL/ELT 迁移中介绍的所有 ETL 工具和概念都可用于初始加载。
如果您不想使用 ETL/ELT 工具进行初始加载,您可以编写自定义脚本来将数据导出到文件(CSV、Avro 或 Parquet),并使用 gcloud storage、BigQuery Data Transfer Service 或 Transfer Appliance 将数据上传到 Cloud Storage。如需详细了解如何调整大型数据转移和转移选项,请参阅转移大型数据集。然后,将数据从 Cloud Storage 加载到 BigQuery。
Cloud Storage 非常适合处理数据的初始着陆。Cloud Storage 是一项高度可用且耐用的对象存储服务,文件数量不受限制,并且您只需为使用的存储空间付费。该服务经过优化,可与其他 BigQuery 和 Dataflow 等 Google Cloud 服务搭配使用。
CDC 和从 Oracle 到 BigQuery 的流式注入
您可以通过多种方式从 Oracle 捕获已更改的数据。每种选项各有利弊,主要涉及对源系统的性能影响、开发和配置要求以及价格和许可。
基于日志的 CDC
Oracle GoldenGate 是 Oracle 推荐用于提取重做日志的日志工具,您可以使用 GoldenGate for Big Data 将日志流式传输到 BigQuery。GoldenGate 需要按 CPU 的许可。如需了解价格,请参阅 Oracle 技术全球价格表。如果 Oracle GoldenGate for Big Data 可用(如果已获取许可),则使用 GoldenGate 可能有助于创建数据流水线来转移数据(初始加载),然后同步所有数据修改。
Oracle XStream
Oracle 将每次提交都存储在重做日志文件中,并且这些重做文件可用于 CDC。Oracle XStream Out 基于 LogMiner 构建,由 Debezium 等第三方工具(从版本 0.8 开始)提供,或者通过多种工具提供商业服务指定为 Striim。即使不安装和使用 GoldenGate,使用 XStream API 也需要购买 Oracle GoldenGate 的许可。XStream 使您能够在 Oracle 和其他软件之间高效传播 Streams 消息。
Oracle LogMiner
LogMiner 无需特殊许可。您可以使用 Debezium 社区连接器中的 LogMiner 选项。它还可以通过 Attunity、Striim 或 StreamSets 等工具购买。LogMiner 可能会对非常活跃的源数据库产生一些性能影响,当更改量(重做的大小)超过每小时 10 GB 时,应谨慎使用,具体取决于服务器的 CPU、内存以及 I/O 容量和利用率。
基于 SQL 的 CDC
这是增量 ETL 方法,其中 SQL 查询会根据单调递增的键和包含上次修改或插入日期的时间戳列不断轮询源表是否有任何更改。如果没有单调递增的键,则使用具有较小精度(秒)的时间戳列(修改日期)可能会导致重复记录或丢失数据,具体取决于数量和比较运算符,例如 > 或 >=。
如需克服此类问题,您可以在时间戳列中使用更高的精度,例如六个小数位(微秒,这是 BigQuery 支持的最大精度),也可以在 ETL/ELT 中添加重复信息删除任务(具体取决于业务密钥和数据特征)。
键或时间戳列上应该有索引,以获得更好的提取性能并减少对源数据库的影响。删除操作是此方法的挑战,因为应在源应用中以软删除方式(例如放置已删除标志和更新 last_modified_date)进行处理。替代解决方案是使用触发器在另一个表中记录这些操作。
触发器
可以在源表上创建数据库触发器,以将更改记录到影子日志表中。日志表可以保存整个行以跟踪每个列更改,或者只能保留具有操作类型(插入、更新或删除)的主键。然后,您可以使用基于 SQL 的 CDC 中介绍的基于 SQL 的方法捕获已更改的数据。如果存储了整行,则使用触发器可能会影响事务性能并使单行 DML 操作延迟时间翻倍。仅存储主键可以减少此开销,但在这种情况下,在基于 SQL 的提取中需要使用具有原始表的 JOIN 操作,这会错过中间更改。
ETL/ELT 迁移
在 Google Cloud上处理 ETL/ELT 的可能性有很多。关于特定 ETL 工作负载转换的技术指导不在本文档的讨论范围内。您可以考虑直接原样迁移方法,或根据费用和时间等限制条件重新设计数据集成平台的架构。如需详细了解如何将数据流水线迁移到 Google Cloud 以及许多其他迁移概念,请参阅迁移数据流水线。 Google Cloud
直接原样迁移方法
如果您的现有平台支持 BigQuery,并且您希望继续使用现有数据集成工具:
- 您可以保持 ETL/ELT 平台不变,并在 ETL/ELT 作业中使用 BigQuery 更改必要的存储阶段。
- 如果您还想将 ETL/ELT 平台迁移到 Google Cloud ,您可以询问您的供应商,了解他们的工具是否获得 Google Cloud许可,如果是,您可以在 Compute Engine 上安装它或检查 Google Cloud Marketplace。
如需了解数据集成解决方案提供商,请参阅 BigQuery 合作伙伴。
重新设计 ETL/ELT 平台的架构
如果您想要重新设计数据流水线的架构,我们强烈建议您使用 Google Cloud 服务。
Cloud Data Fusion
Cloud Data Fusion 是 Google Cloud 上的一个代管式 CDAP,它提供一个直观的界面,其中含有用于完成拖放和流水线开发等任务的许多插件。 Google Cloud Cloud Data Fusion 可用于从许多不同类型的源系统捕获数据,并提供批量复制和流式复制功能。Cloud Data Fusion 或 Oracle 插件可用于从 Oracle 捕获数据。BigQuery 插件可用于将数据加载到 BigQuery 并处理架构更新。
源插件和接收器插件上都未定义输出架构,并且在源插件中也使用 select * from 来复制新列。
您可以使用 Cloud Data Fusion Wrangle 功能进行数据清理和准备。
Dataflow
Dataflow 是一个无服务器数据处理平台,可以自动扩缩以及批量和流式数据处理。对于想要编写数据流水线以及要将相同的代码用于流式和批量工作负载的 Python 和 Java 开发者来说,Dataflow 是一个不错的选择。使用 JDBC to BigQuery 模板从 Oracle 或其他关系型数据库中提取数据,并将数据加载到 BigQuery 中。
Cloud Composer
Cloud Composer 是 Google Cloud 基于 Apache Airflow 构建的全代管式工作流编排服务。您可以编写、安排和监控跨越多个云环境和本地数据中心的流水线。Cloud Composer 提供了运算符和贡献,可以运行多云技术用于多种使用场景,包括提取、加载和转换 (ELT) 和 REST API 调用。
Cloud Composer 使用有向无环图 (DAG) 来安排和编排工作流。如需了解常规 Airflow 概念,请参阅 Airflow Apache 概念。如需详细了解 DAG,请参阅编写 DAG(工作流)。如需查看 Apache Airflow 的 ETL 最佳做法示例,请参阅使用 Airflow 文档站点的 ETL 最佳操作。您可以将此示例中的 Hive 运算符替换为 BigQuery 运算符,这些概念同样适用。
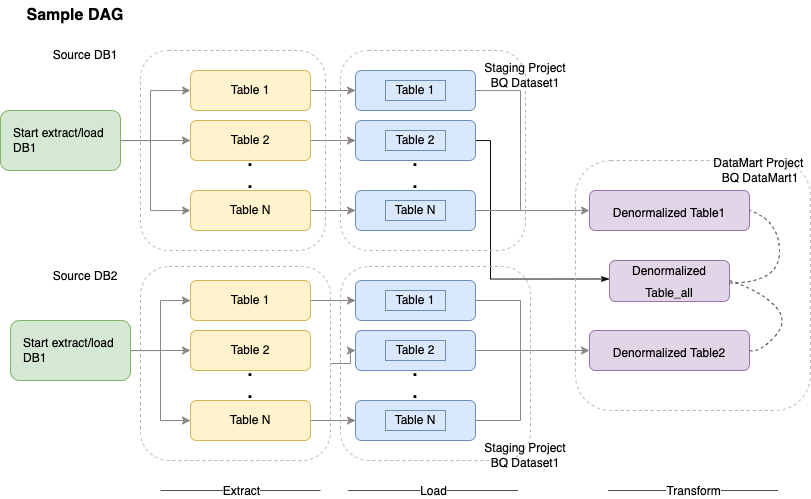
以下示例代码是上图示例 DAG 的概要部分:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
上述代码仅供演示之用,不能按原样使用。
Dataprep by Trifacta
Dataprep 是一项数据服务,让您可以直观地探索、清理和准备结构化数据及非结构化数据,以备分析、报告和机器学习之用。您可以将源数据导出为 JSON 或 CSV 文件,使用 Dataprep 转换数据,然后使用 Dataflow 加载数据。如需查看示例,请参阅使用 Dataflow 和 Dataprep 将 Oracle 数据 (ETL) 迁移到 BigQuery。
Dataproc
Dataproc 是一项 Google 管理的 Hadoop 服务。您可以使用 Sqoop 将数据从 Oracle 和许多关系型数据库作为 Avro 文件导出到 Cloud Storage,然后可以使用 bq tool 将 Avro 文件加载到 BigQuery 中。非常常见的做法是安装 ETL 工具(如 Hadoop 上的 CDAP),这些工具使用 JDBC 提取数据,并使用 Apache Spark 或 MapReduce 对数据进行转换。
用于数据迁移的合作伙伴工具
提取、转换和加载 (ETL) 领域有多家供应商。Informatica、Talend、Matillion、Infoworks、Stitch、Fivetran 和 Striim 等 ETL 市场领导者都与 BigQuery 和 Oracle 深度集成,并可帮助提取、转换、加载数据和管理处理工作流。
ETL 工具已存在多年。一些组织发现利用现有的 ETL 脚本投资十分方便。我们的一些关键合作伙伴解决方案包含在 BigQuery 合作伙伴网站上。了解何时应选择合作伙伴工具而不是Google Cloud 内置实用程序,取决于您的当前基础架构以及您的 IT 团队使用 Java 或 Python 代码开发数据流水线的熟练程度。
商业智能 (BI) 工具迁移
BigQuery 支持一套灵活的商业智能 (BI) 解决方案,您可以将它们用于报告和分析。如需详细了解 BI 工具迁移和 BigQuery 集成,请参阅 BigQuery 分析概览。
查询 (SQL) 转换
BigQuery 的 GoogleSQL 符合 SQL 2011 标准,并且具有支持查询嵌套和重复数据的扩展。所有符合 ANSI 要求的 SQL 函数和运算符都只需进行少量修改即可使用。如需查看 Oracle 和 BigQuery SQL 语法与函数之间的详细比较,请参阅 Oracle 到 BigQuery 的 SQL 转换参考。
使用批量 SQL 转换来批量迁移 SQL 代码,或使用交互式 SQL 转换来转换临时查询。
迁移 Oracle 选项
本部分介绍转换使用 Oracle Data Mining、R 和 Spatial and Graph 功能的应用的架构建议和参考。
Oracle Advanced Analytics 选项
Oracle 提供了 Advanced Analytics 选项用于数据挖掘、基本机器学习 (ML) 算法和 R 使用。Advanced Analytics 选项需要许可。从 Google 开发环境到大规模生产环境,您可以从 Google AI/机器学习产品的完整列表中进行选择。
Oracle R Enterprise
Oracle R Enterprise (ORE) 是 Oracle Advanced Analytics 选项的一个组件,可让开源 R 统计编程语言与 Oracle 数据库集成。在标准 ORE 部署中,R 安装在 Oracle 服务器上。
对于超大量数据或仓储方法,将 R 与 BigQuery 集成是理想的选择。您可以使用开源 bigrquery R 库将 R 与 BigQuery 集成。
Google 已与 RStudio 携手合作,共同为用户提供业界尖端工具。RStudio 可用于在 TensorFlow 中访问 BigQuery 拟合模型中的数 TB 级数据,并使用 AI Platform 大规模运行机器学习模型。在 Google Cloud中,可以在 Compute Engine 上大规模安装 R。
Oracle Data Mining
通过 Oracle Advanced Analytics 选项的组件 Oracle Data Mining (ODM),开发者可以使用 Oracle PL/Oracle SQL Developer 构建机器学习模型。
借助 BigQuery ML,开发者可以运行许多不同类型的模型,例如线性回归、二元逻辑回归、多类别逻辑回归、k-means 聚类以及 TensorFlow 模型导入。如需了解详情,请参阅 BigQuery ML 简介。
转换 ODM 作业可能需要重写代码。您可以从综合的 Google AI 产品中进行选择,例如:BigQuery ML、AI API(Speech-to-Text、Text-to-Speech、Dialogflow、Cloud Translation、Cloud Natural Language API、Cloud Vision、Timeseries Insights API等)或 Vertex AI。
Vertex AI Workbench 可用作数据科学家的开发环境,Vertex AI Training 可用于大规模运行训练和给工作负载评分。
Spatial and Graph 选项
Oracle 提供 Spatial and Graph 选项,用于查询几何图形和图表,并且需要此选项的许可。您可以在 BigQuery 中使用几何图形函数,而无需支付额外费用或许可,还可以使用 Google Cloud中的其他图表数据库。
空间
BigQuery 提供地理空间分析函数和数据类型。如需了解详情,请参阅使用地理空间分析数据。Oracle 空间数据类型和函数可以转换为 BigQuery 标准 SQL 中的地理位置函数。地理位置函数不会在标准 BigQuery 价格的基础上增加费用。
图表
JanusGraph 是一种开源图表数据库解决方案,可以使用 Bigtable 作为存储后端。如需了解详情,请参阅使用 Bigtable 在 GKE 上运行 JanusGraph。
Neo4j 是另一个图表数据库解决方案,以在 Google Kubernetes Engine (GKE) 上运行的 Google Cloud 服务形式提供。
Oracle Application Express
Oracle Application Express (APEX) 应用是 Oracle 独有的,需要重写。您可以使用 Looker Studio 或 BI 引擎开发报告和数据可视化功能,在 AppSheet 上使用 Cloud SQL,无需编写代码即可开发应用级功能(例如创建和修改行)。
后续步骤
- 了解如何优化工作负载以优化整体性能和降低费用。
- 了解如何优化 BigQuery 存储。
- 如需了解 BigQuery 更新,请参阅版本说明。
- 参考 Oracle SQL 转换指南。